【Python】开发笔记
【Python】开发笔记
- 1. 开发工具篇
-
- 1)前言
- 2)Vscode
- 3)Pycharm
- 4)Visual Studio
- 5)Jupyter Lab/Jupyter Notebook
- 6)Anaconda(集成工具)
- 2. Python篇
-
- 1)个人认为的重点
-
- (1)前言
- (2)个人总结
-
- 【0】杂谈
-
- 1. 与C++异同
- 2. 编码
- 【1】函数
-
- 1. 形参中冒号的使用
- 【2】语法
-
- 1. with 管理上下文
- 2. 标识符
- 3. 命令行控制
- 4. 数据类型
- 5. File & OS
- 6. DATE
- 7. 异常处理
- 2)机制
-
- (1)线程(thread)和进程(multiprocess)
-
- 【1】线程(threading)
-
- 1. 线程函数
- 2. 线程的使用
- 3. 多线程执行
- 4. 线程交互执行
- 5. 线程锁
- 【2】进程(multiprocess)
-
- 1. 进程函数
- 2. 多进程的使用
- 【3】线程池、进程池
-
- 1. 线程池 ThreadPool
- 2. 线程池 ThreadPoolExecutor
- 3. 进程池 ProcessPool
- 4. 进程池 ProcessPoolExecutor
- (2)socket通信例程
-
- 【1】章节概览
- 【2】通信详解
- 【3】socket 传输图片的问题
- (3)数据挖掘
-
- 【1】爬虫
- 3. 服务器部署篇
-
- 1)ubuntu系统部署
-
- (1)系统安装
- (2)问题解决
- 2)linux系统自学
近日接触了一个python使用socket与阿里云服务器建立通信的项目,开发过程中查阅了很多资料,也总结了python使用过程中自己对开发工具、python语言中的一些心得,为方便展示,也方便自己以后查阅,因此写下此文。
1. 开发工具篇
1)前言
要致富,先修路,在进行开发前,习得一件得心应手的工具是十分必要的。对于年龄22岁,开发经验20年的大佬来说,或许本人的学习总结十分浅显,不过个人希望将自己学习IDE过程中的一些经验分享出来,不积跬步无以至千里。
2)Vscode
- 认识vscode 和我如何使用
- git及ssh远程开发
- 皮肤推荐
3)Pycharm
- 认识Pycharm
4)Visual Studio
- 认识Visual Studio
- 讲一件兄弟Dve C++
5)Jupyter Lab/Jupyter Notebook
- 认识JL/JN
- 使用它进行简单的环境配置
6)Anaconda(集成工具)
-
Anaconda 有什么用
Anaconda(官方网站)就是可以便捷获取包且对包能够进行管理,同时对环境可以统一管理的发行版本。Anaconda包含了conda、Python在内的超过180个科学包及其依赖项。
如果日常工作或学习并不必要使用1,000多个库,那么可以考虑安装Miniconda(图形界面下载及命令行安装请戳),这里不过多介绍Miniconda的安装及使用。 -
Anaconda、conda、pip、virtualenv的区别
① Anaconda
Anaconda是一个包含180+的科学包及其依赖项的发行版本。其包含的科学包包括:conda, numpy, scipy, ipython notebook等。
② conda
conda是包及其依赖项和环境的管理工具。适用语言:Python, R, Ruby, Lua, Scala, Java, JavaScript, C/C++, FORTRAN。
适用平台:Windows, macOS, Linux
用途:
快速安装、运行和升级包及其依赖项。
在计算机中便捷地创建、保存、加载和切换环境。
如果你需要的包要求不同版本的Python,你无需切换到不同的环境,因为conda同样是一个环境管理器。仅需要几条命令,你可以创建一个完全独立的环境来运行不同的Python版本,同时继续在你常规的环境中使用你常用的Python版本。——conda官方网站conda为Python项目而创造,但可适用于上述的多种语言。
conda包和环境管理器包含于Anaconda的所有版本当中。
③ pip
pip是用于安装和管理软件包的包管理器。pip编写语言:Python。
Python中默认安装的版本:
Python 2.7.9及后续版本:默认安装,命令为pip
Python 3.4及后续版本:默认安装,命令为pip3
pip名称的由来:pip采用的是递归缩写进行命名的。其名字被普遍认为来源于2处:“Pip installs Packages”(“pip安装包”)
“Pip installs Python”(“pip安装Python”)④ virtualenv
virtualenv:用于创建一个独立的Python环境的工具。解决问题:
当一个程序需要使用Python 2.7版本,而另一个程序需要使用Python 3.6版本,如何同时使用这两个程序?
如果将所有程序都安装在系统下的默认路径,如:/usr/lib/python2.7/site-packages,当不小心升级了本不该升级的程序时,将会对其他的程序造成影响。
如果想要安装程序并在程序运行时对其库或库的版本进行修改,都会导致程序的中断。
在共享主机时,无法在全局site-packages目录中安装包。
virtualenv将会为它自己的安装目录创建一个环境,这并不与其他virtualenv环境共享库;同时也可以选择性地不连接已安装的全局库。
⑤ pip 与 conda 比较
→ 依赖项检查
pip:
不一定会展示所需其他依赖包。
安装包时或许会直接忽略依赖项而安装,仅在结果中提示错误。
conda:
列出所需其他依赖包。
安装包时自动安装其依赖项。
可以便捷地在包的不同版本中自由切换。
→ 环境管理
pip:维护多个环境难度较大。
conda:比较方便地在不同环境之间进行切换,环境管理较为简单。
→ 对系统自带Python的影响
pip:在系统自带Python中包的更新/回退版本/卸载将影响其他程序。
conda:不会影响系统自带Python。
→ 适用语言
pip:仅适用于Python。
conda:适用于Python, R, Ruby, Lua, Scala, Java, JavaScript, C/C++, FORTRAN。
⑥ conda与pip、virtualenv的关系
conda结合了pip和virtualenv的功能。作者:Raxxie
链接:https://www.jianshu.com/p/62f155eb6ac5
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。Anaconda介绍、安装及使用教程
-
Anaconda(conda)问题解决
-
创建虚拟环境失败
Solving environment: done
问题描述:输入conda create -n myenv python=3.7 pandas jupyter seaborn scikit-learn keras pytorch pillow创建虚拟环境,但是由于网络/源的问题,导致几个包报HTTP0的错误,再次执行该语句,仅仅停在Collecting package metadata (repodata.json): done Solving environment: done,之后便无法创建环境,输入conda info --envs,显示只有base环境。
问题解决:输入conda clean --all,清除之前未完成conda安装的包即可正常创建环境。conda创建虚拟环境不报错,但创建不成功
-
Anaconda Navigator启动界面卡住,闪退的解决
问题描述:在打开Anaconda Navigator时,启动界面卡住,并闪退。
问题解决:打开anaconda prompt,输入以下代码进行重置conda update anaconda-navigator anaconda-navigator --reset conda update anaconda-client conda update -f anaconda-client anaconda-navigator #命令行启动NavigatorAnaconda Navigator启动界面卡住,闪退的解决
-
2. Python篇
1)个人认为的重点
(1)前言
介绍完开发工具后,相信大家已经建立了属于自己的开发环境。关于这门语言的学习,互联网上关于Python有着许多经典的教程,比如链接: 菜鸟教程,Python的官方开发文档。在学习或者使用之余经常查阅,实在不懂的到csdn、baidu、stackflow、github上查找答案,基本上可以解决99%的问题,所以多做多问还是学习必不可少的一部分(对我个人也是)。
(2)个人总结
【0】杂谈
1. 与C++异同
无编译,面向对象
2. 编码
- ASCII:1B 英文
- GBK:2B 中文
- Unicode:2-4B 万文
- UTF-32\16\8:Unicode Transformation Format
UTF-8:英文1B,欧文2B,东亚文3B
中国windows:GBK
Python:UTF-8 编码
python中指定编码
# coding=utf-8
# -*- coding:utf-8 -*-
# -*- coding=utf-8 -*-
【1】函数
1. 形参中冒号的使用
- 形参中冒号的使用
t1:TreeNode中的冒号“:”是用来限制t1的传入类型def mergeTrees(t1: TreeNode, t2: TreeNode) -> TreeNode:
末尾的 -> 则表示函数最后的返回应该是TreeNode类型的
【2】语法
1. with 管理上下文
-
with 管理上下文
两大主体:
- enter:初始化
- exit:退出
关键作用:简化try….except….finally的处理流程
详细来说:with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
with open('d:\\xxx.txt') as fp: print fp.read()with语句最关键的地方在于被求值对象必须有__enter__()和__exit__()这两个方法,那我们就可以通过自己实现这两方法来自定义with语句处理异常。
查询
opened()函数的源码class opened(object): def __init__(self,filename): self.handle=open(filename) print "Resource:%s"%filename def __enter__(self): print "[enter%s]: Allocate resource."%self.handle return self.handle#可以返回不同的对象 def __exit__(self,exc_type,exc_value,exc_trackback): print "[Exit %s]: Free resource." %self.handle if exc_trackback is None: print "[Exit %s]:Exited without exception."%self.handle self.handle.close() else: print "[Exit %s]: Exited with exception raised."%self.handle return False # 可以省略,缺省的None也是被看做是Falsepython中with的用法
2. 标识符
下划线:
_function() # 类属性
__function() # 私有成员
__function__() # 构造函数
3. 命令行控制
Python的OptionParser模块
Python 之ConfigParser模块
4. 数据类型
- String:用[]读取;string函数:endwith\ find\ format\ join\ stripe\replace\ partition\maketrans\ split\translate
- List:用[]读取;List函数:append\del\len\ pop\sort\count\ extend
- Tuple:只读
- Dictionary:用{}读取;字典函数
- Set:
5. File & OS
Python3 File(文件) 方法
Python3 OS 文件/目录方法
-
FILE:操作文件、文件内容
open\close\write\read\tell\seek\rename\removepython.file对象-
file.open(file, mode='r', buffering=-1, encoding=None)
关于file.open()函数的更多参数,请访问Python3 File(文件) 方法 -
file.close() -
file.flush()刷新文件内部缓冲,直接将内部缓冲区的数据立刻写入文件,不需等待输出缓冲区写入 -
file.write()'a'写入字符串; 'wb'写入二进制文本(需要encode()); -
file.read() -
file.readline()读取整行 -
file.writelines()写入字符串列表,换行须自己加入\n -
file.fileno()返回文件描述符 -
file.isatty()是否连接到终端设备 -
file.seek(offset[, whence])设置文件读取指针,并会影响read()函数的读取顺序
whence:可选,默认值为 0。给 offset 定义一个参数,表示要从哪个位置开始偏移;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。f = open('workfile', 'rb+') f.write(b'0123456789abcdef') 16 f.seek(5) # 移动到文件的第六个字节 5 f.read(1) b'5' f.seek(-3, 2) # 移动到文件倒数第三个字节 13 f.read(1) b'd' -
file.tell()返回文件读取指针的位置 -
file.truncate()返回截断后的文件程序例程
# 打开文件 fo = open("runoob.txt", "r") print ("文件名为: ", fo.name) for line in fo.readlines(): #依次读取每行 line = line.strip() #去掉每行头尾空白 print ("读取的数据为: %s" % (line)) # 关闭文件 fo.close()
-
-
OS:操作目录、权限、属性
mkdir\chdir\getcwd\rmdir路径的格式规范(LINUX 系统不同)
# 在路径前面加r,即保持字符原始值的意思。 sys.path.append(r'c:\Users\mshacxiang\VScode_project\web_ddt') # 替换为双反斜杠 sys.path.append('c:\\Users\\mshacxiang\\VScode_project\\web_ddt') # 替换为正斜杠 sys.path.append('c:/Users/mshacxiang/VScode_project/web_ddt')获取指定路径下所有文件的绝对路径
关键函数:
os.walk()、os.path.join()、os.path.splitext()import os def get_file_path_by_name(file_dir): ''' 获取指定路径下所有文件的绝对路径 :param file_dir: :return: ''' L = [] for root, dirs, files in os.walk(file_dir): # 获取所有文件 for file in files: # 遍历所有文件名 if os.path.splitext(file)[1] == '.*': L.append(os.path.join(root, file)) # 拼接处绝对路径并放入列表 print('总文件数目:', len(L)) return L print(get_file_path_by_name(r'D:\vsproject\pyhelloworld\1216'))关键函数:
os.listdir()、os.path.isdir()、os.path.joindir()import os l = [] def listdir(path, list_name): # 传入存储的list for file in os.listdir(path): file_path = os.path.join(path, file) # 自动迭代子文件夹 if os.path.isdir(file_path): listdir(file_path, list_name) # 将子文件压入列表 else: list_name.append(file_path) return l print(listdir(r'D:\vsproject\pyhelloworld\1216', l))相对路径的操作
关键函数:
os.getcwd()、string.rstrip()、os.chdir()、os.path.isfileimport os print(os.getcwd()) # 结果 # D:\vsproject\pyhelloworld print(os.getcwd()) os.chdir(r'D:\vsproject\pyhelloworld\1216') print(os.getcwd()) # D:\vsproject\pyhelloworld # D:\vsproject\pyhelloworld\1216import os l = [] def lookfile(PATH, l): file = os.listdir(PATH) #获取路径下文件夹和文件 # print(file) for i in file: ret=os.path.join(PATH, i) if os.path.isdir(ret): print(i) lookfile(ret, l) elif os.path.isfile(ret): l.append(ret) return l os.chdir(r'D:\vsproject\pyhelloworld\DataBase') for listname in lookfile(os.getcwd(), l): print(listname) """ 结果 D:\vsproject\pyhelloworld\DataBase\demo_create_tabel.py D:\vsproject\pyhelloworld\DataBase\demo_mysql_order.py D:\vsproject\pyhelloworld\DataBase\demo_mysql_test.py D:\vsproject\pyhelloworld\DataBase\demo_mysql_work.py D:\vsproject\pyhelloworld\DataBase\demo_mywork.py D:\vsproject\pyhelloworld\DataBase\demo_pymysql_test.py D:\vsproject\pyhelloworld\DataBase\Server_mysql_pic.py D:\vsproject\pyhelloworld\DataBase\tempCodeRunnerFile.py """分离扩展名
import os print(os.path.exists(os.getcwd())) print(os.path.isabs(os.getcwd())) # 是否绝对路径 print(os.path.split(os.getcwd())) print(os.path.splitext(os.getcwd())) # 分离扩展名 filename = r"D:\vsproject\pyhelloworld\DataBase\demo_create_tabel.py" print(os.path.dirname(filename)) # 获取路径名 print(os.path.basename(filename)) # 获取文件名 print(os.path.getsize(filename)) # 获取文件大小 """ 结果 True True ('D:\\vsproject', 'pyhelloworld') ('D:\\vsproject\\pyhelloworld', '') D:\vsproject\pyhelloworld\DataBase demo_create_tabel.py 784 """对一个文件下,所有文件,重命名,去取文件命中指定字符
# -*- coding: utf-8 -*- """ 对一个文件下,所有文件,重命名,去取文件命中指定字符 """ import os in_path0='F:\\迅雷下载' in_dirtyStr=['阳光电影www.ygdy8.com.','.BD.720p','语中字'] #需要清理的字符 os.chdir(in_path0) print(os.getcwd()) #======== list0 = os.listdir() for line in list0: if os.path.isfile(line): line0 = str(line) # 去除指定字符 for i in in_dirtyStr: line = line.replace(i,'') print(line0,line) os.rename(line0,line)os.linesep字符串给出当前平台使用的行终止符
if __name__ == '__main__': wd=os.getcwd() filetest = open (wd+'/lw/waston.txt', 'r+',encoding='utf-8') print(filetest.read()) # 不用\n 如果使用os.linesep filetest.write ("\n") while 1: newline = input("Enter a line word(',' to quit):") if newline != ",": filetest.write ('%s%s' % (newline, os.linesep)) else: break filetest.close ()未完成
# 运行shell命令: os.system() # 读取和设置环境变量: os.getenv() os.putenv() # 给出当前平台使用的行终止符: os.linesep() # 创建多级目录: os.makedirs(r“c:\python\test”) # 创建单个目录: os.mkdir(“test”) # 获取文件属性: os.stat(file) # 修改文件权限与时间戳: os.chmod(file)python相对路径的指定
python学习之一 OS 文件夹的操作和文件操作
python文件、文件夹操作OS模块
6. DATE
Python3 日期和时间
时间
import time
import calendar
ticks = time.time()
print ("当前时间戳为:", ticks)
# 获取当前时间
localtime = time.localtime(time.time())
print ("本地时间为 :", localtime)
# 获取格式化的时间
localtime = time.asctime( time.localtime(time.time()) )
print ("本地时间为 :", localtime)
# 格式化成2016-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 格式化成Sat Mar 28 22:24:24 2016形式
print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y")))
"""
当前时间戳为: 1608728612.9450793
本地时间为 : time.struct_time(tm_year=2020, tm_mon=12, tm_mday=23, tm_hour=21, tm_min=3, tm_sec=32, tm_wday=2, tm_yday=358, tm_isdst=0)
本地时间为 : Wed Dec 23 21:03:32 2020
2020-12-23 21:03:32
2020-12-23 21:03:32
Wed Dec 23 21:03:32 2020
1459175064.0
"""
日历
import calendar
cal = calendar.month(2020, 12)
print ("以下输出2020年12月份的日历:")
print (cal)
perf_counter 进度条实例
import time
scale = 50
print("执行开始".center(scale//2,"-")) # .center() 控制输出的样式,宽度为 25//2,即 22,汉字居中,两侧填充 -
start = time.perf_counter() # 调用一次 perf_counter(),从计算机系统里随机选一个时间点A,计算其距离当前时间点B1有多少秒。当第二次调用该函数时,默认从第一次调用的时间点A算起,距离当前时间点B2有多少秒。两个函数取差,即实现从时间点B1到B2的计时功能。
for i in range(scale+1):
a = '*' * i # i 个长度的 * 符号
b = '.' * (scale-i) # scale-i) 个长度的 . 符号。符号 * 和 . 总长度为50
c = (i/scale)*100 # 显示当前进度,百分之多少
dur = time.perf_counter() - start # 计时,计算进度条走到某一百分比的用时
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end='') # \r用来在每次输出完成后,将光标移至行首,这样保证进度条始终在同一行输出,即在一行不断刷新的效果;{:^3.0f},输出格式为居中,占3位,小数点后0位,浮点型数,对应输出的数为c;{},对应输出的数为a;{},对应输出的数为b;{:.2f},输出有两位小数的浮点数,对应输出的数为dur;end='',用来保证不换行,不加这句默认换行。
time.sleep(0.1) # 在输出下一个百分之几的进度前,停止0.1秒
print("\n"+"执行结果".center(scale//2,'-'))
综合例程
import time
import calendar
"""
时间元组(年、月、日、时、分、秒、一周的第几日、一年的第几日、夏令时)
一周的第几日: 0-6
一年的第几日: 1-366
夏令时: -1, 0, 1
"""
"""
python中时间日期格式化符号:
------------------------------------
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称 # 乱码
%% %号本身
"""
# (1)当前时间戳
# 1538271871.226226
time.time()
# (2)时间戳 → 时间元组,默认为当前时间
# time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=9, tm_min=4, tm_sec=1, tm_wday=6, tm_yday=246, tm_isdst=0)
time.localtime()
time.localtime(1538271871.226226)
# (3)时间戳 → 可视化时间
# time.ctime(时间戳),默认为当前时间
time.ctime(1538271871.226226)
# (4)时间元组 → 时间戳
# 1538271871
time.mktime((2018, 9, 30, 9, 44, 31, 6, 273, 0))
# (5)时间元组 → 可视化时间
# time.asctime(时间元组),默认为当前时间
time.asctime()
time.asctime((2018, 9, 30, 9, 44, 31, 6, 273, 0))
time.asctime(time.localtime(1538271871.226226))
# (6)时间元组 → 可视化时间(定制)
# time.strftime(要转换成的格式,时间元组)
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# (7)可视化时间(定制) → 时间元祖
# time.strptime(时间字符串,时间格式)
print(time.strptime('2018-9-30 11:32:23', '%Y-%m-%d %H:%M:%S'))
# (8)浮点数秒数,用于衡量不同程序的耗时,前后两次调用的时间差
time.clock()
时间命名文件名
import os
import time
import datetime
rootDir = "I:/1/"
dic={
}
for dirName,subDirs,fileList in os.walk(rootDir):
print(dirName)
for fn in fileList:
fnpath=dirName+fn
st = os.stat(fnpath)
mode, ino, dev, nlink, uid, gid, size, atime, mtime, ctime = st
# print mtime
t=time.ctime(mtime)
d_from_t = datetime.datetime.fromtimestamp(mtime)
dic[fnpath]=d_from_t.strftime('%Y-%m-%d%H:%M:%S')
# print fnpath+"- last modified:", d_from_t.strftime('%Y-%m-%d %H:%M:%S')
pass
for x in dic:
# p=os.path.splitext(x)[0]
p=os.path.dirname(os.path.abspath(x))
ext=os.path.splitext(x)[1]
# tpath=p+"/"+dic[x]+ext
# print tpath
# print os.path.dirname(os.path.abspath(p))
nname=os.path.join(rootDir,dic[x]+ext)
# print p,ext
print("os.rename('"+x+"','"+nname+"'')")
os.rename(x,nname)
pass
按文件存取时间顺序列出目录
import os
DIR = "/home/serho/workspace/lisp"
def compare(x, y):
stat_x = os.stat(DIR + "/" + x)
stat_y = os.stat(DIR + "/" + y)
if stat_x.st_ctime < stat_y.st_ctime:
return -1
elif stat_x.st_ctime > stat_y.st_ctime:
return 1
else:
return 0
iterms = os.listdir(DIR)
iterms.sort(compare)
for iterm in iterms:
print(iterm)
7. 异常处理
三个结构:
- try…except…
- try…finally…
- raise 触发异常
2)机制
(1)线程(thread)和进程(multiprocess)
在学习线程和进程前,建议可以先了解以下概念:并行和并发、并发的解决(队列、缓冲区、争抢、垂直扩展、水平扩展、消息中间件)——Python 多线程 进程与线程相关概念 (一)
【1】线程(threading)
线程是操作系统进行调度的最小单位,每个进程至少有一个线程,同一个进程内的线程可以共享进程的资源,每一个线程拥有自己独立的堆栈。线程具有以下状态:ready、running、blocked、terminated。其具有以下状态转换:
1. 线程函数
- 线程函数
# 线程支持库
import threading
# 父类
threading.Thread(group,target,name,args,kwargs)
'''
group:线程组,可无视
target:目标函数
name:线程
args:输入参数,须为tuple格式,如果只有一个参数,须加一个`,`,以免报错
kwargs:输入关键参数
'''
threading.current_thread() #返回当前线程对象
threading.current_thread().name #线程名,只是一个标识符,可以使用getName()、setName()获取和运行时重命名。
threading.current_thread().ident #线程ID,非0整数。线程启动后才会有ID,否则为None。线程退出,此ID依旧可以访问。此ID可以重复使用
threading.current_thread().is_alive() #返回线程是否存活,布尔值,True或False。
threading.main_thread() #返回主线程对象
threading.active_count() #返回处于Active状态的线程个数
threading.enumerate() #返回所有存活的线程的列表,不包括已经终止的线程和未启动的线程
threading.get_ident() #返回当前线程的ID,非0整数
2. 线程的使用
- 线程的使用
有两种方法:
(1).实例Thread()对象
import threading
import time
# 自定义目标函数,测试线程
def tstart(arg):
time.sleep(0.5)
print("%s running...." % arg)
if __name__ == '__main__':
t1 = threading.Thread(target=tstart, args=('This is thread 1',))
t2 = threading.Thread(target=tstart, args=('This is thread 2',))
t1.start()
t2.start()
print("This is main function")
显示结果如下
This is main function
This is thread 2 running....
This is thread 1 running....
作者个人理解:线程的执行从主线程开始,在答应main function 后同时调用两个子线程thread 1 和thread 2 ,此处print顺序随机,并没有规律性。
(2).继承Thread()对象,并重写run()函数
import threading
import time
class CustomThread(threading.Thread):
def __init__(self, thread_name):
# step 1: call base __init__ function
super(CustomThread, self).__init__(name=thread_name)
self._tname = thread_name
def run(self):
# step 2: overide run function
time.sleep(0.5)
print("This is %s running...." % self._tname)
if __name__ == "__main__":
t1 = CustomThread("thread 1")
t2 = CustomThread("thread 2")
t1.start()
t2.start()
print("This is main function")
此处新建CustomThread()类,它继承自threading.Thread()父类,在新建使用的过程中,我们重写了以下两个函数:
def __init__(self, thread_name):
# step 1: call base __init__ function
super(CustomThread, self).__init__(name=thread_name)
self._tname = thread_name
def run(self):
# step 2: overide run function
time.sleep(0.5)
print("This is %s running...." % self._tname)
谈一谈自己的理解,在__init__(self, thread_name)中super(CustomThread, self).__init__(name=thread_name)函数,此处为python2.x写法,在python3.x中可直接写成super().__init__(name=thread_name),这里的作用是调用父类threading.Thread()中的__init__()函数,这种调用在这个简单的案例中看似没有特点,但是在多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题,详情请浏览python-super()函数解析,在此不过多赘述。
3. 多线程执行
- 多线程执行
在多线程执行过程中可以使用的函数
listen(n):n代表排队数量,即服务器拒绝连接,操作系统可以挂起的最大连接数量
start():主线程中调用此函数来启动子线程,注意此刻主线程和子线程同时运行,当主线程完成后不会立即结束,等待子线程结束(这里的结束可以是正常结束,也可以是抛出异常结束)
join():主线程中调用join()方法,那么主线程必须等待子线程完全执行完毕后才可执行join()后的语句,相当于单线程顺序执行
run():启动子线程,但是会阻塞主线程和其他线程
start()和run()方法的区别
- 在一个线程中同时使用
start()和run(),会先运行start()方法,再运行run()方法。(本质上是start()函数调用了run()函数) start()执行LIFO-后进先出,同时启动新的子进程ID,run()执行时阻塞其它线程,直到完成后再继续其它操作,但是都工作在主线程,没有启动新线程,因此run()方法仅仅是普通函数调用。
因此启用多线程,请使用start()方法
join()方法的作用
- 主线程需要等待子线程执行完成之后再结束,此时需要在
start()后使用join()方法
4. 线程交互执行
- 线程交互执行
以下内容转载自Python 多线程 线程安全、daemon简介 (四)
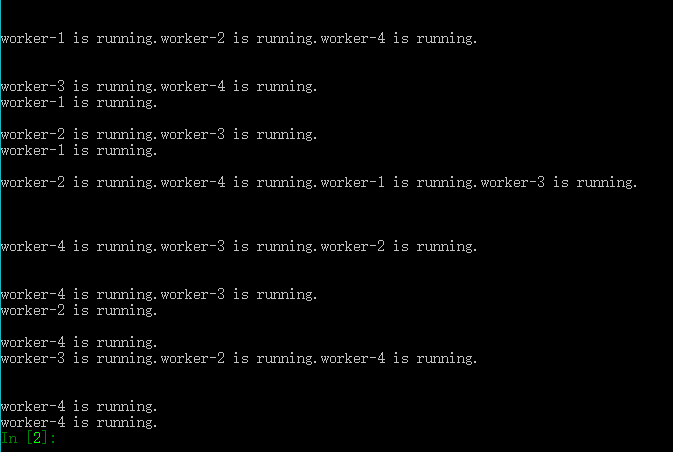
print函数分为打印字符串和打印换行,这里部分字符串粘成一行,说明print拼接换行符前被其它线程打断,因此线程不安全。
为了解决线程安全的问题,以下方法可以被采用
- 在print中直接打印
\n - logging模块(分级输出)(摘自本链接和Python 模块 logging模块、Logger类)
- 最泛用的方法——daemon
在构造新线程时,设置daemon作为线程的属性(注意拼写DAEMON,作者本人常写出DEAMON)- None:等同父线程的daemon值
- True:父线程退出该线程也退出
- False:父线程必须等待该线程执行完毕
import threading
import time
def foo():
for i in range(3):
print('i={},foo thread daemon is {}'.format(i,threading.current_thread().isDaemon()))
time.sleep(1)
t = threading.Thread(target=foo,daemon=False)
t.start()
print("Main thread daemon is {}".format(threading.current_thread().isDaemon()))
print("Main Thread Exit.")
运行结果:
i=0,foo thread daemon is False
Main thread daemon is False
Main Thread Exit.
i=1,foo thread daemon is False
i=2,foo thread daemon is False
isDaemon()返回当前线程的daemon值
线程交互执行,Join(),Daemon :
1、join ()方法:主线程A中,创建了子线程B,并且在主线程A中调用了B.join(),那么,主线程A会在调用的地方等待,直到子线程B完成操作后,才可以接着往下执行,那么在调用这个线程时可以使用被调用线程的join方法。
2、setDaemon()方法。主线程A中,创建了子线程B,并且在主线程A中调用了B.setDaemon(),这个的意思是,把主线程A设置为守护线程,这时候,要是主线程A执行结束了,就不管子线程B是否完成,一并和主线程A退出.这就是setDaemon方法的含义,这基本和join是相反的。此外,还有个要特别注意的:必须在start() 方法调用之前设置,如果不设置为守护线程,程序会被无限挂起。
5. 线程锁
- 线程锁
线程同步:解决多线程争抢同一资源的情况,使线程能够协作工作。
-
Lock
线程中设置,其它试图获取锁的线程将被阻塞。acquire(blocking=True,timeout=-1) ''' blocking:True时,给线程加锁,其它线程不可重用,False时,不阻塞其它线程使用锁对象。 timeout:阻塞超时时间 ''' release() ''' 释放锁 '''下面展示一个锁的例子:
未加锁
#不使用Lock锁的例子 import logging import threading import time logging.basicConfig(level=logging.INFO) # 10 -> 100cups cups = [] lock = threading.Lock() def worker(lock:threading.Lock,task=100): while True: count = len(cups) time.sleep(0.1) if count >= task: break logging.info(count) cups.append(1) logging.info("{} make 1........ ".format(threading.current_thread().name)) logging.info("{} ending=======".format(len(cups))) for x in range(10): threading.Thread(target=worker,args=(lock,100)).start() INFO:root:Thread-7 make 1........ INFO:root:93 INFO:root:Thread-8 make 1........ INFO:root:94 INFO:root:Thread-2 make 1........ INFO:root:95 INFO:root:Thread-3 make 1........ INFO:root:96 INFO:root:Thread-5 make 1........ INFO:root:98 INFO:root:Thread-6 make 1........ INFO:root:98 INFO:root:107 ending======= INFO:root:Thread-4 make 1........ INFO:root:108 ending======= INFO:root:108 ending======= INFO:root:108 ending======= INFO:root:108 ending======= INFO:root:108 ending======= INFO:root:108 ending======= INFO:root:108 ending======= INFO:root:108 ending======= INFO:root:108 ending=======加锁
#Lock import logging import threading import time logging.basicConfig(level=logging.INFO) # 10 -> 100cups cups = [] lock = threading.Lock() def worker(lock:threading.Lock,task=100): while True: if lock.acquire(False): count = len(cups) time.sleep(0.1) if count >= task: lock.release() break logging.info(count) cups.append(1) lock.release() logging.info("{} make 1........ ".format(threading.current_thread().name)) logging.info("{} ending=======".format(len(cups))) for x in range(10): threading.Thread(target=worker,args=(lock,100)).start() NFO:root:Thread-2 make 1........ INFO:root:87 INFO:root:Thread-1 make 1........ INFO:root:88 INFO:root:Thread-6 make 1........ INFO:root:89 INFO:root:Thread-8 make 1........ INFO:root:90 INFO:root:Thread-2 make 1........ INFO:root:91 INFO:root:Thread-6 make 1........ INFO:root:92 INFO:root:Thread-9 make 1........ INFO:root:93 INFO:root:Thread-2 make 1........ INFO:root:94 INFO:root:Thread-8 make 1........ INFO:root:95 INFO:root:Thread-3 make 1........ INFO:root:96 INFO:root:Thread-9 make 1........ INFO:root:97 INFO:root:Thread-3 make 1........ INFO:root:98 INFO:root:Thread-6 make 1........ INFO:root:99 INFO:root:Thread-3 make 1........ INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending======= INFO:root:100 ending=======可以看到在计数的前后分别写入了
lock.acquire(False)和lock.release()实现锁的机制,这里加锁前后最大的区别在于,在计数时加锁实现单线程的运行,如果此处不加锁,在99时,10个线程将全部开始运行,最终将会输出结果109,结果并非我们程序设计所想的,因此此处用锁实现单线程运行。不过性能有所下降
关于True 和False:true 时,线程的执行顺序为0-9循环执行(继承for循环语句的顺序),而false 时,线程的执行顺序将被打乱,在这里作者的理解是:锁的机制分为两部分,第一部分申请锁,第二部分使用锁,true表示阻止其它线程获取锁,false则允许,因此这样造成了true机制下线程的排队现象,false机制下线程争抢执行,当然每一时刻只有一个线程在运行。锁的应用场景:独占锁:锁适用于访问和修改同一个共享资源的时候,即读写同一个资源的时候。共享锁:如果共享资源是不可变的值时,所有线程每一次读取它都是同一样的值,这样的情况就不需要锁。死锁解决办法:
- 使用 try…except…finally 语句处理异常、保证锁的释放
- with 语句上下文管理,锁对象支持上下文管理。只要实现了__enter__和__exit__魔术方法的对象都支持上下文管理。
锁导致线程阻塞解决方法:
-
使用非阻塞锁,就是acquire(false)
#非阻塞锁 import threading,logging,time FORMAT = '%(asctime)s\t [%(threadName)s,%(thread)d] %(message)s' logging.basicConfig(level=logging.INFO,format=FORMAT) def worker(tasks): for task in tasks: time.sleep(0.01) if task.lock.acquire(False): #False非阻塞 当某个线程得到锁时显示begin,未得到显示is logging.info('{} {} begin to start'.format(threading.current_thread().name,task.name)) else: logging.info('{} {} is working'.format(threading.current_thread().name,task.name)) class Task: # 创建类函数Task,初始化name和lock对象 def __init__(self,name): self.name = name self.lock = threading.Lock() tasks = [Task('task={}'.format(t)) for t in range(5)] for i in range(3): # 创建3个线程对象并开启 t = threading.Thread(target=worker,name='worker-{}'.format(i),args=(tasks,)) t.start() 2020-12-14 20:19:29,384 [worker-2,13508] worker-2 task=0 begin to start 2020-12-14 20:19:29,384 [worker-1,3340] worker-1 task=0 is working 2020-12-14 20:19:29,384 [worker-0,9680] worker-0 task=0 is working 2020-12-14 20:19:29,396 [worker-0,9680] worker-0 task=1 begin to start 2020-12-14 20:19:29,396 [worker-1,3340] worker-1 task=1 is working 2020-12-14 20:19:29,396 [worker-2,13508] worker-2 task=1 is working 2020-12-14 20:19:29,410 [worker-0,9680] worker-0 task=2 begin to start 2020-12-14 20:19:29,411 [worker-1,3340] worker-1 task=2 is working 2020-12-14 20:19:29,411 [worker-2,13508] worker-2 task=2 is working 2020-12-14 20:19:29,421 [worker-0,9680] worker-0 task=3 begin to start 2020-12-14 20:19:29,422 [worker-1,3340] worker-1 task=3 is working 2020-12-14 20:19:29,422 [worker-2,13508] worker-2 task=3 is working 2020-12-14 20:19:29,438 [worker-0,9680] worker-0 task=4 begin to start 2020-12-14 20:19:29,439 [worker-2,13508] worker-2 task=4 is working 2020-12-14 20:19:29,439 [worker-1,3340] worker-1 task=4 is working由此可见,本方法可以解决线程阻塞问题,注意线程运行的时间,不过在线程-n获得锁时,此时本线程独自运行0.01s,当运行完成后,另外两个线程同时运行,然后进入下一个循环。
Python 多线程 Lock、阻塞锁、非阻塞锁 (八)
-
RLock
可重入锁,作用有点类似非阻塞锁lock = threading.RLock() ret = lock.acquire() lock.release()Python 多线程 RLock可重入锁 (九)
-
Condition
采用通知机制,常用于生产者消费者模型中,解决生产者消费者速度匹配的问题,直白点就是匹配数据输入和数据接收的速度。# 数据生产端 with self.cond: self.data = data self.cond.notify_all() #通知所有waiter # 数据接收端 with self.cond: self.cond.wait() #无限等待 logging.info(self.data) #消费#Condition 先生成后消费,1对1 import threading,random,logging # 自定义log 格式 logging.basicConfig(level=logging.INFO,format="%(thread)d %(threadName)s %(message)s") class Dispatcher: def __init__(self): self.data = 0 self.event = threading.Event() self.cond = threading.Condition() def produce(self): for i in range(100): data = random.randint(1,100) logging.info(self.data) with self.cond: self.data = data # 相应1个cond等待 self.cond.notify(1) # self.cond.notify_all() self.event.wait(1) def custom(self): while True: with self.cond: self.cond.wait() logging.info(self.data) self.event.wait(0.5) d = Dispatcher() p = threading.Thread(target=d.produce,name='produce') c = threading.Thread(target=d.custom,name='c') c1 = threading.Thread(target=d.custom,name='c1') p.start() e = threading.Event() e.wait(3) c1.start() c.start() 运行结果: 7520 produce 0 7520 produce 78 7520 produce 88 7520 produce 14 7520 produce 83 2508 c1 86 7520 produce 86 1136 c 79 7520 produce 79 2508 c1 77 7520 produce 77 1136 c 47 7520 produce 47 2508 c1 76 7520 produce 76 1136 c 69Python 多线程 Condition (十)
-
Barrier
应用场景:
并发初始化
所有线程都必须初始化完成后,才能继续工作,例如运行前加载数据,检查,如果这些工作没完成就不能正常工作运行。
10个线程做10种工作准备,每个线程负责一种工作,只有10个线程都完成后,才能继续工作,先完成的要等待后完成的线程。
例如,启动一个程序,需要先加载磁盘文件、缓存预热、初始化连接池等工作,这些工作可以齐头并进,不过只有都满足了,程序才能继续向后执行。假设数据库链接失败,则初始化工作失败,就要abort,栅栏broken,所有线程收到异常退出。Python 多线程 Barrier (十一)
-
信号量 Semaphore
信号量,信号量对象内部维护一个倒计数器,每一次acquire都会减1,当acquire方法发现计数为0就阻塞请求的线程,直到其它线程对信号量release后,计数大于0,恢复阻塞的线程。sem = threading.Semaphore(2) # 信号量设置为2,允许并发数为2,因此服务器只能允许两个线程进行accept(),其余线程均阻塞在信号量上。 with sem:常见error
RuntimeError: threads can only be started once 线程退出,程序中再次启动线程便会抛出此异常其它资料
Python 多线程 threading.local类 (六)
Python 多线程 Timer定时器/延迟执行、Event事件 (七)
【2】进程(multiprocess)
进程是系统进行资源分配和调度的基本单位,是一个或多个线程的集合,在操作系统中,每个进程在内存中相对独立的,进程间不可以随便的共享数据。
1. 进程函数
-
进程函数
fork
import os # 注意,fork函数,只在Unix/Linux/Mac上运行,windows不可以 pid = os.fork() if pid == 0: print('哈哈1') else: print('哈哈2')程序执行到os.fork()时,操作系统会创建一个新的进程(子进程),然后复制父进程的所有信息到子进程中
然后父进程和子进程都会从fork()函数中得到一个返回值,在子进程中这个值一定是0,而父进程中是子进程的 id号multiprocessing
import os import time from multiprocessing import Process def run_proc(name): print('子进程运行中,name%s,pin=%d...'%(name,os.getpid())) time.sleep(10) print('子进程已经结束') if __name__=='__main__': print('父进程%d.'%os.getpid()) p=Process(target=run_proc,args=('test',)) print('子进程将要执行') p.start()通过start()开启了子进程之后,主进程会等待子进程执行完才结束
Pool
#coding=utf-8 from multiprocessing import Pool import os, time, random def worker(msg): print("%s开始执行,进程号为%d"%(msg, os.getpid())) time.sleep(1) print "%s执行完毕"%(msg) if __name__ == '__main__': po = Pool(3) # 定义一个进程池,最大进程数3 for i in range(10): # Pool.apply_async(要调用的目标,(传递给目标的参数元祖,)) # 每次循环将会用空闲出来的子进程去调用目标 po.apply_async(worker, (i,)) print("----start----") po.close() # 关闭进程池,关闭后po不再接收新的请求 po.join() # 等待po中所有子进程执行完成,必须放在close语句之后 print("-----end-----")
2. 多进程的使用
-
多进程的使用
多进程案例多进程复制文件夹下的文件
#coding=utf-8 import os from multiprocessing import Pool def copyFileTask(name, oldFolderName, newFolderName): # 完成copy一个文件的功能 fr = open(oldFolderName+"/"+name, 'rb+') fw = open(newFolderName+"/"+name, 'wb+') str = fr.read(1024 * 5) while (str != ''): fw.write(str) str = fr.read(1024 * 5) fr.close() fw.close() def main(): # 获取要copy的文件夹名字 oldFolderName = raw_input('请输入文件夹名字:') # 创建一个文件夹 newFolderName = oldFolderName+'-复件'.decode('utf-8').encode('gbk') os.mkdir(newFolderName) #获取old文件夹里面所有文件的名字 fileNames = os.listdir(oldFolderName) #使用多进程的方式copy原文件夹所有内容到新的文件夹中 pool = Pool(5) for name in fileNames: pool.apply_async(copyFileTask, (name, oldFolderName, newFolderName)) pool.close() pool.join() if __name__ == '__main__': main()并行多进程计算
#=========多进程、真正的并行、适用于CPU计算密集型=============== import multiprocessing import datetime def calc(i): sum = 0 for _ in range(100000000): sum += 1 # print(i,sum) if __name__ == "__main__": start = datetime.datetime.now() lst = [] for i in range(5): p = multiprocessing.Process(target=calc,args=(i,),name='p-{}'.format(i)) p.start() lst.append(p) for p in lst: p.join() delta = (datetime.datetime.now() - start).total_seconds() print(delta)Python中的线程和进程
Python 多线程 multiprocessing、多进程、工作进程池 (十四)
【3】线程池、进程池
在使用线程池、进程池之前,请确保安装threadpool模块
pip install threadpool
将使用以下模块
线程池使用
import threadpool
from concurrent.futures import ThreadPoolExecutor
进程池使用
from concurrent.futures import ProcessPoolExecutor
多进程、多线程的选择
- CPU密集型——多进程
CPython中使用到了GIL,多线程的时候锁相互竞争,且多核优势不能发挥,Python多进程效率更高。 - IO密集型——多线程
适合是用多线程,减少IO序列化开销。且在IO等待的时候,切换到其它线程继续执行,效率不错。
应用:
请求/应答模型:WEB应用中常见的处理模型
master启动多个worker工作进程,一般和CPU数目相同。
worker工作进程中启动多线程,提高并发处理能力。worker处理用户的请求,往往需要等待数据。
这就是nginx工作模式。
特性:
- 线程不是越多越好,会涉及cpu上下文的切换(会把上一次的记录保存)
- 进程比线程消耗资源,进程相当于一个工厂,工厂里有很多人,里面的人共同享受着福利资源,一个进程里默认只有一个主线程,比如:开启程序是进程,里面执行的是线程,线程只是一个进程创建多个人同时去工作。
- 协程:一个线程,一个进程做多个任务,使用进程中一个线程去做多个任务,微线程
- GIL全局解释器锁:保证同一时刻只有一个线程被cpu调度
1. 线程池 ThreadPool
-
线程池 threadpool
未使用线程池import time def sayhello(str): print "Hello ",str time.sleep(2) name_list =['xiaozi','aa','bb','cc'] start_time = time.time() for i in range(len(name_list)): sayhello(name_list[i]) print '%d second'% (time.time()-start_time)使用线程池
import time import threadpool def sayhello(str): print("Hello ",str) time.sleep(2) name_list =['xiaozi','aa','bb','cc'] start_time = time.time() pool = threadpool.ThreadPool(10) requests = threadpool.makeRequests(sayhello, name_list) [pool.putRequest(req) for req in requests] pool.wait() print('%d second'% (time.time()-start_time))显示结果
Hello Hello Hello Hello aabbxiaozicc 2 secondprint 字符串粘连问题请参考本章2.-2)-(1)-【1】-4.线程交互执行
使用线程池时核心是以下语句:# 定义线程池以及最大线程数 pool = threadpool.ThreadPool(10) # 创建多线程函数、参数和[回调函数] requests = threadpool.makeRequests(sayhello, name_list) # 将允许的多线程请求req 一个个扔进线程池 [pool.putRequest(req) for req in requests] # 等待所有线程完成 pool.wait()
2. 线程池 ThreadPoolExecutor
-
线程池 ThreadPoolExecutor
- 使用 with 语句 ,通过 ThreadPoolExecutor 构造实例,同时传入 max_workers 参数来设置线程池中最多能同时运行的线程数目。
- 使用 submit 函数来提交线程需要执行的任务到线程池中,并返回该任务的句柄(类似于文件、画图),注意 submit() 不是阻塞的,而是立即返回。
- 通过使用 done() 方法判断该任务是否结束。上面的例子可以看出,提交任务后立即判断任务状态,显示四个任务都未完成。在延时2.5后,task1 和 task2 执行完毕,task3 仍在执行中。
- 使用 result() 方法可以获取任务的返回值,但是该方法会阻塞当前主线程,只有等到线程任务完成后,result() 方法的阻塞才会被解除。
如果程序不希望直接调用 result() 方法阻塞线程,则可通过 Future 的 add_done_callback() 方法来添加回调函数,即添加result()函数,该回调函数形如 fn(future)。当线程任务完成后,程序会自动触发该回调函数,并将对应的 Future 对象作为参数传给该回调函数。
def test(value1, value2=None): print("%s threading is printed %s, %s"%(threading.current_thread().name, value1, value2)) time.sleep(2) return 'finished' def test_result(future): print(future.result()) if __name__ == "__main__": import numpy as np from concurrent.futures import ThreadPoolExecutor threadPool = ThreadPoolExecutor(max_workers=4, thread_name_prefix="test_") for i in range(0,10): future = threadPool.submit(test, i,i+1) # 使用回调函数调用结果展示 future.add_done_callback(test_result) # print(future.result()) threadPool.shutdown(wait=True) print('main finished') 结果 test__0 threading is printed 0, 1 test__1 threading is printed 1, 2 test__2 threading is printed 2, 3 test__3 threading is printed 3, 4 finished finished finished test__2 threading is printed 5, 6finishedtest__0 threading is printed 4, 5test__1 threading is printed 6, 7 test__3 threading is printed 7, 8 finished finishedtest__2 threading is printed 8, 9finished test__1 threading is printed 9, 10 finished finished finished main finished- 当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
# coding: utf-8 from concurrent.futures import ThreadPoolExecutor import time def spider(page): time.sleep(page) print(f"crawl task{page} finished") return page with ThreadPoolExecutor(max_workers=5) as t: # 创建一个最大容纳数量为5的线程池 task1 = t.submit(spider, 1) task2 = t.submit(spider, 2) # 通过submit提交执行的函数到线程池中 task3 = t.submit(spider, 3) print(f"task1: {task1.done()}") # 通过done来判断线程是否完成 print(f"task2: {task2.done()}") print(f"task3: {task3.done()}") time.sleep(2.5) print(f"task1: {task1.done()}") print(f"task2: {task2.done()}") print(f"task3: {task3.done()}") print(task1.result()) # 通过result来获取返回值 t.shutdown(wait=True)wait(fs, timeout=2.5, return_when=ALL_COMPLETED\FIRST_COMPLETED)
all_task = [t.submit(spider, page) for page in range(1, 5)]
wait 函数表示返回结果的条件from concurrent.futures import ThreadPoolExecutor, wait, FIRST_COMPLETED, ALL_COMPLETED import time def spider(page): time.sleep(page) print(f"crawl task{page} finished") return page with ThreadPoolExecutor(max_workers=5) as t: all_task = [t.submit(spider, page) for page in range(1, 5)] wait(all_task, return_when=FIRST_COMPLETED) print('finished') print(wait(all_task, timeout=2.5))map(fn, *iterables, timeout=None)
for result in executor.map(spider, [2, 3, 1, 4]):
map 函数表示将序列中每个元素都执行同一个函数import time from concurrent.futures import ThreadPoolExecutor def spider(page): time.sleep(page) return page start = time.time() executor = ThreadPoolExecutor(max_workers=4) i = 1 for result in executor.map(spider, [2, 3, 1, 4]): print("task{}:{}".format(i, result)) i += 1as_completedpython线程池 ThreadPoolExecutor 的用法及实战
python ThreadPoolExecutor线程池
python3 - concurrent.futures模块 - 进程池&线程池
3. 进程池 ProcessPool
参考本章2.-2)-(1)-【2】-1. 进程函数-Pool
4. 进程池 ProcessPoolExecutor
-
同步调用方式:一边执行语句,立刻取得结果
# -*- coding:utf-8 -*- # 方式一、同步调用方式:提交任务,原地等待任务执行结束,拿到任务返回结果。再执行下一行代码会导致任务串行执行 # 进程池的两种任务提交方式 import datetime from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import current_thread import time, random, os import requests def task(name): print('%s %s is running'%(name,os.getpid())) #print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")) if __name__ == '__main__': p=ProcessPoolExecutor(4) #设置进程池内进程数 for i in range(10): #同步调用方式,调用和等值 obj = p.submit(task,"进程pid:")#传参方式(任务名,参数),参数使用位置或者关键字参数 res =obj.result() p.shutdown(wait=True) #关闭进程池的入口,等待池内任务运行结束 print("主") -
异步提交方式:执行语句,不获取结果
# 异步调用 + 回调函数 :解决耦合,但速度慢 from concurrent.futures import ProcessPoolExecutor import time, os import requests def get(url): print('%s GET %s' % (os.getpid(), url)) time.sleep(3) response = requests.get(url) if response.status_code == 200: res = response.text else: res = '下载失败' return res def parse(future): time.sleep(1) # 传入的是个对象,获取返回值 需要进行result操作 res = future.result() print('%s 解析结果为%s' % (os.getpid(), len(res))) if __name__ == '__main__': urls = [ 'https://www.baidu.com', 'https://www.sina.com.cn', 'https://www.tmall.com', 'https://www.jd.com', 'https://www.python.org', 'https://www.openstack.org', 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.baidu.com', ] p = ProcessPoolExecutor(9) start = time.time() for url in urls: future = p.submit(get, url) # 模块内的回调函数方法,parse会使用future对象的返回值,对象返回值是执行任务的返回值 future.add_done_callback(parse) p.shutdown(wait=True) print('完成时间', time.time() - start) ''' 3960 GET https://www.baidu.com 14320 GET https://www.sina.com.cn 1644 GET https://www.tmall.com 196 GET https://www.jd.com 13512 GET https://www.python.org 7356 GET https://www.openstack.org 14952 GET https://www.baidu.com 9528 GET https://www.baidu.com 11940 GET https://www.baidu.com 15292 解析结果为233360 15292 解析结果为108543 15292 解析结果为2443 15292 解析结果为2443 15292 解析结果为2443 15292 解析结果为2443 15292 解析结果为569140 15292 解析结果为48821 15292 解析结果为65099 完成时间 14.311698913574219 '''ThreadPoolExecutor线程池和ProcessPoolExecutor进程池
(2)socket通信例程
- 先来一个简单的demo
服务端
import socket
# 建立一个服务端
server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind(('0.0.0.0', 18888)) #绑定要监听的端口
server.listen(5) #开始监听 表示可以使用五个链接排队
while True:# conn就是客户端链接过来而在服务端为期生成的一个链接实例
conn,addr = server.accept() #等待链接,多个链接的时候就会出现问题,其实返回了两个值
print(conn,addr)
while True:
try:
data = conn.recv(1024) #接收数据
print('recive:',data.decode()) #打印接收到的数据
conn.send(data.upper()) #然后再发送数据
except ConnectionResetError as e:
print('关闭了正在占线的链接!')
break
conn.close()
客户端
import socket# 客户端 发送一个数据,再接收一个数据
client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #声明socket类型,同时生成链接对象
client.connect(('10.49.33.80',8888)) #建立一个链接,连接到本地的6969端口
while True:
# addr = client.accept()
# print '连接地址:', addr
msg = '欢迎访问菜鸟教程!' #strip默认取出字符串的头尾空格
client.send(msg.encode('utf-8')) #发送一条信息 python3 只接收btye流
data = client.recv(1024) #接收一个信息,并指定接收的大小 为1024字节
print('recv:',data.decode()) #输出我接收的信息
client.close() #关闭这个链接
socket 中最主要的是accept-connect 和send-recv 这两组函数的连接,其中accept-connect 负责两台主机之间的连接,send-recv负责连接完成后主机间数据的收发。
【1】章节概览
- 网络数据、网络错误
编码-解码
封帧-引用
socket.shutdown()的用法 - 服务器架构
单线程服务器
多线程和多进程服务器
异步服务器 - 缓存与消息队列
socket缓冲区解释
消息队列
散列和分区
Memcached
【2】通信详解
-
串口通信
-
多线程通信
-
多进程通信
-
Queue
-
pipe
-
Manager
Python中的线程和进程
-
函数详解
- makefile
特点:和普通的socket 通信对象相比,makefile 对象更侧重于I/O类型的对象,等到以后有空的时候再进行更新。
参考资料:
Python 网络编程 makefile (三)
***socket常用方法和makefile使用(面试会考)
- makefile
-
缓冲区
-
socket的缓冲区机制
每个
socket被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
write()/send()并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由 TCP 协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是 TCP 协议负责的事情。
TCP 协议独立于write()/send()函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。read()/recv()函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。SEND 写入TCP 发送TCP 接收RECV 读取SEND 写入TCP 发送TCP 接收RECV 读取socket主机缓冲区网络通信缓冲区socket从机归根结底:
write/send/read/recv这些函数只对缓冲区进行控制,独立于 TCP 协议之外。
这些 I/O 缓冲区特性可整理如下:
1. I/O 缓冲区在每个 TCP 套接字中单独存在;(1个TCP对应1个I/O缓冲区)
2. I/O 缓冲区在创建套接字时自动生成;
3. 即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
4. 关闭套接字将丢失输入缓冲区中的数据。 -
对文件的控制
当然,受限于网络环境还有设备的问题,缓冲区有几率存在积压数据没有被发送出去的情况。
此时我们需要考虑python 中关于文件操作的函数:
python.file对象file.open(file, mode='r', buffering=-1, encoding=None)
关于file.open()函数的更多参数,请访问Python3 File(文件) 方法file.close()file.flush()刷新文件内部缓冲,直接将内部缓冲区的数据立刻写入文件,不需等待输出缓冲区写入file.write()file.read()file.readline()读取整行file.writelines()写入字符串列表,换行须自己加入\nfile.fileno()返回文件描述符file.isatty()是否连接到终端设备file.seek(offset[, whence])设置文件读取指针,并会影响read()函数的读取顺序
whence:可选,默认值为 0。给 offset 定义一个参数,表示要从哪个位置开始偏移;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。
f = open('workfile', 'rb+') f.write(b'0123456789abcdef') 16 f.seek(5) # 移动到文件的第六个字节 5 f.read(1) b'5' f.seek(-3, 2) # 移动到文件倒数第三个字节 13 f.read(1) b'd'file.tell()返回文件读取指针的位置file.truncate()返回截断后的文件
程序例程
# 打开文件 fo = open("runoob.txt", "r") print ("文件名为: ", fo.name) for line in fo.readlines(): #依次读取每行 line = line.strip() #去掉每行头尾空白 print ("读取的数据为: %s" % (line)) # 关闭文件 fo.close()
【3】socket 传输图片的问题
以下是作者参考其它博客的传输图片例程
服务端
fileinfo_size = struct.calcsize('32si')
buf = server.recv(fileinfo_size)
if buf:
filename, filesize = struct.unpack('32si', buf)
fn = filename.strip(b'\00')
fn = fn.decode()
print('file name is {0}, filesize if {1}'.format(str(fn), filesize))
recvd_size = 0 # 定义已接收文件的大小
# 存储在该脚本所在目录下面
fp = open('./' + str(filename), 'wb')
print('pic start receiving...')
# 将分批次传输的二进制流依次写入到文件
while not recvd_size == filesize:
if filesize - recvd_size > 1024:
data = conn.recv(1024)
recvd_size += len(data)
else:
data = conn.recv(filesize - recvd_size)
recvd_size = filesize
fp.write(data)
fp.close()
程序分别两个部分,第一部分解开struct包头文件,获取filename和filesize,第二部分是一个循环,终止条件是已接收图片大小等于客户端图片大小(详见客户端代码,引入了python struct 的概念并制作包头文件),这里定义一次接收的大小为1024字节(这个也是socket 通信的限制),因此if 剩余大小大于1024字节,执行接收1024字节;else 剩余大小小于1024字节,则接收剩下长度,并将已接收大小设置为客户端图片大小(这里着重强调,至于原因底下说)。
客户端
filepath = 'camera.jpg'
# 判断是否为文件
if os.path.isfile(filepath):
# 定义定义文件信息。32s表示文件名为32bytes长,i表示一个int或log文件类型(Windows中i为4个字节,Linux中i为8个字节),在此为文件大小
fileinfo_size = struct.calcsize('32si')
# 定义文件头信息,包含文件名和文件大小
fhead = struct.pack('32si', os.path.basename(filepath).encode('utf-8'), os.stat(filepath).st_size)
# 发送文件名称与文件大小
socket.send(fhead)
# 将传输文件以二进制的形式分多次上传至服务器
fp = open(filepath, 'rb')
while 1:
data = fp.read(1024)
if not data:
print('{0} file send over...'.format(os.path.basename(filepath)))
break
socket.send(data)
# 关闭当期的套接字对象
socket.close()
还是两部分,第一部分建立包头文件,请自行参考struct的用法,第二部分建立fp 文件对象读取图片,然后使用while 循环重复读取并发送图片流直至全部发送完成。
结果
Traceback (most recent call last):
File "d:\vsproject\pyhelloworld\success\1216\Serverimprove.py", line 127, in <module>
main()
File "d:\vsproject\pyhelloworld\success\1216\Serverimprove.py", line 124, in main
t0.run()
File "D:\Users\18120\Anaconda3\lib\threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "d:\vsproject\pyhelloworld\success\1216\Serverimprove.py", line 61, in servergps
dataname, filesize = struct.unpack('32si', data)
struct.error: unpack requires a buffer of 36 bytes
服务端接收包头文件时发生错误,这里经过读者的定位发现,上一张图片服务端没有接收完全,导致部分数据挺在缓冲区,被下一张图片接收包头文件的recv()接收,导致这里的data 是图片数据而非包头文件数据。
数据示例
# 错误数据1
b"\x85\x97v\x00\xa0\xcb\x8fJV\xb7c\xfc'\xdb\x8aT\xb4=X~t\x92H\x0f\xff\xd9camera93.jpg\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xeb\n\x01\x00"
# 错误数据2
b'\xa8q\xb6\xa2j\xc4{x\xddQ\x1f\x97\xadM\xbf\x1c\x01Ls\x91\xc9\xe4P\xec\x1a\x08\xae\x0f&\x95]\t\xc3q\xefP3\xf9m\xb4\x0e;\xd3\xc3\x02\x03z\xd3\xb5\xb5\r\xb5&\x1c\x9f\x96\xa4\x8eLeNq\xdf\x15]X\x92\x05<>\xc3S\xa3\x1139#\x1b\xb23\xc54\xe7\xad&\xf0\xc74\xe0Gq@\x0c\x01\xbb\xd2\xee\xe8\xb4\xaeT\x1f\x94\xf1H\x0eW#\xd3\x9akT1\xdea-\x9ct\x18\xe9Ry\xe3\x1c\n\x85I$\xe6\x85}\xa7\x00\xf7\xe2\x85kY\x81d\x1e\xf4\xc3>0q\xd7\xde\x98er88\xe2\xa2rs\x8a\x94\xbb\x88\xff\xd9'
# 正确数据 正好符合32si结构可以解包
b'camera92.jpg\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x007\x1c\x01\x00'
找到原因后我们得知道怎么修改,回到上面所说的,else 剩余大小小于1024字节,则接收剩下长度,并将已接收大小设置为客户端图片大小(这里着重强调)
while not recvd_size == filesize:
if filesize - recvd_size > 1024:
data = conn.recv(1024)
recvd_size += len(data)
else:
data = conn.recv(filesize - recvd_size)
recvd_size = filesize
fp.write(data)
fp.close()
假设一张图片大小总共7521字节,当前接收6144字节
倒数第二次按理接收1024字节(达到7168字节) ,然而缓冲区只有436个字节,只能接收436个字节,此时服务端接收6580字节
最后一次只有941字节长度,进行最终传输,然而只接收588字节(达到7168字节),并终止传输,并将大小设置为客户端图片大小
这里服务端明显的睁眼说瞎话,明明没有接收完图片可是还设置了实际图片的大小,因此我们只要修改这一个错误的行为即可,以下是修改后的成功代码
while not recvd_size == filesize:
if filesize - recvd_size > 1024:
data = server.recv(1024)
recvd_size += len(data)
else:
data = server.recv(filesize - recvd_size)
recvd_size += len(data)
fp.write(data)
fp.close()
另外可以参考:
socket传输图片底部失真
问题解决~
(3)数据挖掘
【1】爬虫
多线程爬虫
# coding: utf-8
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
import json
from requests import adapters
from proxy import get_proxies
headers = {
"Host": "splcgk.court.gov.cn",
"Origin": "https://splcgk.court.gov.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
"Referer": "https://splcgk.court.gov.cn/gzfwww/ktgg",
}
url = "https://splcgk.court.gov.cn/gzfwww/ktgglist?pageNo=1"
def spider(page):
data = {
"bt": "",
"fydw": "",
"pageNum": page,
}
for _ in range(5):
try:
response = requests.post(url, headers=headers, data=data, proxies=get_proxies())
json_data = response.json()
except (json.JSONDecodeError, adapters.SSLError):
continue
else:
break
else:
return {
}
return json_data
def main():
with ThreadPoolExecutor(max_workers=8) as t:
obj_list = []
begin = time.time()
for page in range(1, 15):
obj = t.submit(spider, page)
obj_list.append(obj)
for future in as_completed(obj_list):
data = future.result()
print(data)
print('*' * 50)
times = time.time() - begin
print(times)
if __name__ == "__main__":
main()
将多线程函数改成单线程函数
def single():
begin = time.time()
for page in range(1, 15):
data = spider(page)
print(data)
print('*' * 50)
times = time.time() - begin
print(times)
if __name__ == "__main__":
single()
python线程池 ThreadPoolExecutor 的用法及实战
3. 服务器部署篇
1)ubuntu系统部署
(1)系统安装
等到有新的电脑了自己新装一下,然后记录安装过程。
(2)问题解决
参考作者博客:【Linux鸟哥笔记】20-启动流程、模块管理与Loader
2)linux系统自学
参考作者博客:Ubuntu16.04 使用心得