Nginx基础入门篇
Nginx基础入门篇
- 1.Nginx 的优势
-
- 1.1发展趋势
- 1.2Logo
- 1.3简介
- 1.4反代图示
- 1.5Nginx的web优势:(高并发、IO多路复用、epoll、异步、非阻塞)
- 2.HTTP 协议详解
-
- 2.1HTTP
- 2.2URL
- 2.3HTTP protocol 概述
- 2.4HTTP headers
- 3.Nginx 部署YUM
-
- 3.1官网链接
- 3.2Nginx版本类型
- 3.3配置YUM源
- 3.4安装
- 4.Nginx 配置文件
- 5.Nginx 编译参数
- 6.Nginx 基础配置
-
- 6.1观察主配置文件
- 6.2观察默认虚拟主机配置文件
- 6.3启动一个新的虚拟主机
- 7.Nginx 日志Log
-
- 7.1日志配置
- 7.2日志轮转/切割
- 7.3日志分析
- 8.Nginx WEB模块
-
- 8.1随机主页
- 8.2替换模块
- 8.3文件读取
- 8.4文件压缩
- 8.5页面缓存
- 8.6防盗链
- 8.7连接状态
- 9.Nginx 访问限制
- 10.Nginx 访问控制
-
- 10.1基于主机(IP)
- 10.2基于用户(username&password)
1.Nginx 的优势
1.1发展趋势


1.2Logo

1.3简介
Nginx (engine x) 是一个高性能的HTTP(解决C10k的问题)和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。
1.4反代图示
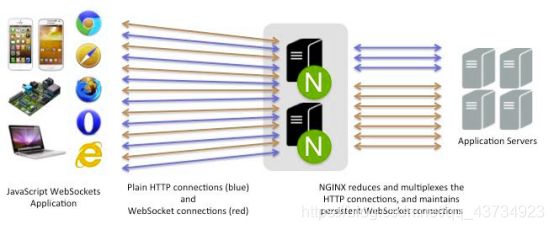
1.5Nginx的web优势:(高并发、IO多路复用、epoll、异步、非阻塞)
Ⅰ.IO多路复用:
1.理论方法:
- 最传统的多进程并发模型(没进来一个新的I/O流会分配一个新的进程管理)
- I/O多路复用(单个线程,通过记录跟踪每个I/O流(sock)的状态,来同时管理多个I/O流。)能尽量多的提高服务器的吞吐能力。
- 在同一个线程里面,通过拨开关的方式,来同时传输多个I/O流。
2.技术类型:
- select:
• select是第一个实现 (1983 左右在BSD里面实现的)。
• select 被实现以后,很快就暴露出了很多问题。
• select 会修改传入的参数数组,这个对于一个需要调用很多次的函数,是非常不友好的。
• select 如果任何一个sock(I/O stream)出现了数据,select 仅仅会返回,但是并不会告诉你是那个sock上有数据,于是你只能自己一个一个的找,10几个sock可能还好,要是几万的sock每次都找一遍…
• select 只能监视1024个链接。
• select 不是线程安全的,如果你把一个sock加入到select, 然后突然另外一个线程发现,这个sock不用,要收回,这个select 不支持的,如果你丧心病狂的竟然关掉这个sock, select的标准行为是不可预测的
- poll:
• 于是14年以后(1997年)一帮人又实现了poll, poll 修复了select的很多问题,比如 poll 去掉了1024个链接的限制,于是要多少链接呢, 你开心就好。
• poll 从设计上来说,不再修改传入数组,不过这个要看你的平台了,所以行走江湖,还是小心为妙。
• 其实拖14年那么久也不是效率问题, 而是那个时代的硬件实在太弱,一台服务器处理1千多个链接简直就是神一样的存在了,select很长段时间已经满足需求。
• 但是poll仍然不是线程安全的, 这就意味着,不管服务器有多强悍,你也只能在一个线程里面处理一组I/O流。
你当然可以那多进程来配合了,不过然后你就有了多进程的各种问题。
- epoll:
• 于是5年以后, 在2002, 大神 Davide Libenzi 实现了epoll.
epoll 可以说是I/O 多路复用最新的一个实现,epoll 修复了poll 和select绝大部分问题, 比如:
• epoll 现在是线程安全的。
• epoll 现在不仅告诉你sock组里面数据,还会告诉你具体哪个sock有数据,你不用自己去找了。• 特点:异步、非阻塞
$ pstree |grep nginx
|-+= 81666 root nginx: master process nginx
| |— 82500 nobody nginx: worker process
| — 82501 nobody nginx: worker process
1个master进程,2个work进程• 每进来一个request,会有一个worker进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发request,并等待请求返回。那么,这个处理的worker不会这么一直等着,他会在发送完请求后,注册一个事件:“如果upstream返回了,告诉我一声,我再接着干”。于是他就休息去了。这就是异步。此时,如果再有request 进来,他就可以很快再按这种方式处理。这就是非阻塞和IO多路复用。而一旦上游服务器返回了,就会触发这个事件,worker才会来接手,这个request才会接着往下走。这就是异步回调。
Ⅱ.时分多路复用
- CPU时钟/中断设计
Ⅲ.频分多路复用
- ADSL
2.HTTP 协议详解
2.1HTTP
HTTP --Hyper Text Transfer Protocol,超文本传输协议,是一种建立在TCP上的无状态连接,整个基本的工作流程是客户端发送一个HTTP请求,说明客户端想要访问的资源和请求的动作,服务端收到请求之后,服务端开始处理请求,并根据请求做出相应的动作访问服务器资源,最后通过发送HTTP响应把结果返回给客户端。其中一个请求的开始到一个响应的结束称为事务,当一个事物结束后还会在服务端添加一条日志条目。
2.2URL
Ⅰ.官方解释链接
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/Identifying_resources_on_the_Web
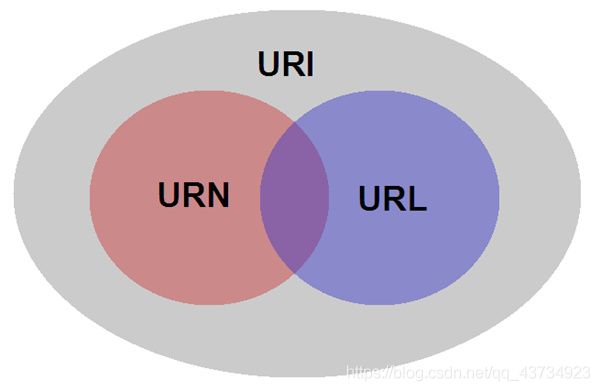
Ⅱ.URI
- 简介:统一资源标识符(Uniform Resource Identifier,或URI)
HTTP 请求的内容通称为”资源“。”资源“这一概念非常宽泛,它可以是你能够想到的格式。每个资源都由一个 (URI) 来进行标识。URL即统一资源定位符,它是 URI 的一种。一份文档,一张图片,或所有其他。URI包含URL,URN。
- URL:统一资源定位符(Uniform Resource Locator,或URL)
URL用于定位,也被称为网页地址。
URL 由多个必须或可选的组件构成。下面给出了一个复杂的 URL:
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
- URN
URN 是另一种形式的 URI,它通过特定命名空间中的唯一名称来标识资源。
URN仅用于命名,而不指定地址。用于标识唯一书目的ISBN系统是一个典型的URN使用范例。
例如,ISBN 0486275574(urn:isbn:0-486-27557-4)无二义性地标识出莎士比亚的戏剧《罗密欧与朱丽叶》的某一特定版本。
Ⅲ.三者关系图
通过下面的例子(源自 Wikipedia),我们可以很好地理解URN 和 URL之间的区别。如果是一个人,我们会想到他的姓名和住址。URL类似于住址,它告诉你一种寻找目标的方式(在这个例子中,是通过街道地址找到一个人)。要知道,上述定义同时也是一个URI。
相对地,我们可以把一个人的名字看作是URN;因此可以用URN来唯一标识一个实体。由于可能存在同名(姓氏也相同)的情况,所以更准确地说,人名这个例子并不是十分恰当。更为恰当的是书籍的ISBN码和产品在系统内的序列号,尽管没有告诉你用什么方式或者到什么地方去找到目标,但是你有足够的信息来检索到它。
- 关于URL:
URL是URI的一种,不仅标识了Web 资源,还指定了操作或者获取方式,同时指出了主要访问机制和网络位置。
- 关于URN:
URN是URI的一种,用特定命名空间的名字标识资源。使用URN可以在不知道其网络位置及访问方式的情况下讨论资源。
现在,如果到Web上去看一下,你会找出很多例子,这比其他东西更容易让人困惑。我只展示一个例子,非常简单清楚地告诉你在互联网中URI 、URL和URN之间的不同。
我们一起来看下面这个虚构的例子。
这是一个URI:“http://bitpoetry.io/posts/hello.html#intro”
“http://”是定义如何访问资源的方式。
“bitpoetry.io/posts/hello.html”是资源存放的位置。
“#intro”是资源。
URL是URI的一个子集,告诉我们访问网络位置的方式。在我们的例子中,URL应该如下所示:“http://bitpoetry.io/posts/hello.html”URN是URI的子集,包括名字(给定的命名空间内),但是不包括访问方式,如下所示:
“bitpoetry.io/posts/hello.html#intro”就是这样。现在你应该能够辨别出URL和URN之间的不同。如果你忘记了这篇文章的内容,至少要记住一件事:URI可以被分为URL、URN或两者的组合。如果你一直使用URI这个术语,就不会有错。
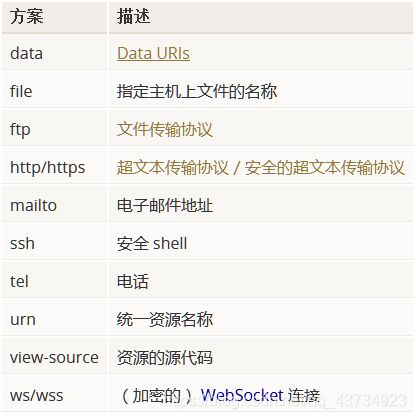
Ⅳ.统一自愿标识符的语法(URL)
1.协议
“http://” 告诉浏览器使用何种协议。对于大部分 Web 资源,通常使用 HTTP 协议或其安全版本,HTTPS 协议。
另外,浏览器也知道如何处理其他协议。例如, “mailto:” 协议指示浏览器打开邮件客户端;“ftp:”协议指示浏览器处理文件传输。
2.主机
www.example.com 既是一个域名,也代表管理该域名的机构。它指示了需要向网络上的哪一台主机发起请
求。当然,也可以直接向主机的 IP address 地址发起请求。但直接使用 IP 地址的场景并不常见。3.端口
:80 是端口。它表示用于访问 Web 服务器上资源的技术“门”。如果访问的该 Web 服务器使用HTTP协议的标准
端口(HTTP为80,HTTPS为443)授予对其资源的访问权限,则通常省略此部分。否则端口就是 URI 必须的部分。4.路径
/path/to/myfile.html 是 Web 服务器上资源的路径。在 Web 的早期,类似这样的路径表示 Web 服务器上的物理文件位置。现在,它主要是由没有任何物理实体的 Web 服务器抽象处理而成的。
5.查询
?key1=value1&key2=value2 是提供给 Web 服务器的额外参数。这些参数是用 & 符号分隔的键/值对列表。Web 服务器可以在将资源返回给用户之前使用这些参数来执行额外的操作。每个 Web 服务器都有自己的参数规则,想知道特定 Web 服务器如何处理参数的唯一可靠方法是询问该 Web 服务器所有者。
6.片段
#SomewhereInTheDocument 是资源本身的某一部分的一个锚点。锚点代表资源内的一种“书签”,它给予浏览器显示位于该“加书签”点的内容的指示。 例如,在HTML文档上,浏览器将滚动到定义锚点的那个点上;在视频或音频文档上,浏览器将转到锚点代表的那个时间。值得注意的是 # 号后面的部分,也称为片段标识符,永远不会与请求一起发送到服务器。
7.示例
https://developer.mozilla.org/en-US/docs/Learn
[email protected]:mdn/browser-compat-data.git
ftp://example.org/resource.txt






2.3HTTP protocol 概述
Ⅰ.官方链接
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Overview
Ⅱ.知识点
1.概述
- 图示
我们获得的图像,影音,广告都是由web服务器 get而来。
- 概览
HTTP是一种能够获取如 HTML 这样的网络资源的通讯协议。它是 Web 上数据交换的基础,是一种client-server 协议,也就是说请求通常是由像浏览器这样的接受方发起的。一个完整的web文档是由不同的子文档重新组建而成的,像是文本、布局描述、图片、视频、脚本等等。
HTTP被设计于上20世纪90年代初期,是一种可扩展性的协议。它是应用层的协议,虽然理论上它可以通过任何可靠的传输协议来发送,但是它还是通过TCP,或者是TLS-加密的TCP连接来发送。因为它很好的扩展性,时至今日它不仅被用来传输超文本文档,还用来传输图片、视频或者向服务器发送如HTML表单这样的信息。HTTP还可以根据网页需求,来获取部分web文档的内容来更新网页。
- requests
客户端和服务端通过交换各自的消息来进行交互。通常由像浏览器这样的客户端发出的消息叫做requests,那么被服务端回应的消息就叫做 responses。
2.组件系统
HTTP是一个client-server协议:请求通过一个实体被发出,实体也就是用户代理。大多数情况下,这个用户代理都是指浏览器,当然它也可能是任何东西,比如一个爬取网页来生成和维护搜索引擎索引的机器。
每一个发送到服务器的请求,都会被服务器处理并且返回一个消息,也就是response。在client与server之间,还有许许多多的被称为proxies的实体,他们的作用与表现各不相同,比如有些是网关,还有些是caches等。
- 客户端:user-agent
严格意义来说,user-agent就是任何能够为用户发起行为的工具。但实际上,这个角色通常都是由浏览器来扮演。对于发起请求来说,浏览器总是作为发起一个请求的实体。
要渲染出一个网页,浏览器首先要发送第一个请求来获取这个页面的HTML文档,再解析它并根据文档中的资源信息发送其他的请求来获取脚本信息,或者CSS来进行页面布局渲染,还有一些其它的页面资源(如图片和视频等)。然后,它把这些资源结合到一起,展现出来一个完整的文档,也就是网页。打开一个网页后,浏览器还可以根据脚本内容来获取更多的资源来更新网页。
一个网页就是一个超文本文档,也就是说有一部分显示的文本可能是链接,启动它(通常是鼠标的点击)就可以获取一个新的网页。网页使得用户可以控制它的user-agent来导航Web。浏览器来负责翻译HTTP请求的命令,并翻译HTTP的返回消息让用户能明白返回消息的内容。
- Web服务端
在上述通信过程的另一端,就是一个Web Server来服务并提供客户端请求的文档。Server只是虚拟意义上:它可以是许多共同分担负载(负载平衡)的一组服务器组成的计算机群,也可以是一种复杂的软件,通过向其他计算机发起请求来获取部分或全部资源的软件。
- Proxies
在浏览器和服务器之间,有许多计算机和其他设备转发了HTTP的消息。因为Web栈层次结构的原因,它们大多数都出现在传输层、网络层和物理层上,对于HTTP的应用层来说就是透明的(虽然它们可能会对应用层的性能有重要影响)。而还有一部分表现在应用层上的,就叫做proxies了。Proxies既可以表现得透明,又可以不透明(看请求是否通过它们)。
3.报文
- 请求
• 一个HTTP的method,经常是由一个动词像GET, POST 或者一个名词像OPTIONS,HEAD来定义客户端的动
作行为的。通常客户端的操作都是获取资源(用GET方法)或者发送一个HTML form表单的值(用POST方法),
虽然在一些情况下也会有其他的操作。
• 要获取的资源的路径,通常是上下文中就很明显的元素资源的URL,它没有protocol (http://),domain(developer.mozilla.org),或是TCP的port(HTTP是80端口)。
• HTTP协议的版本号。
• 为服务端表达其他信息的可选择性的headers。
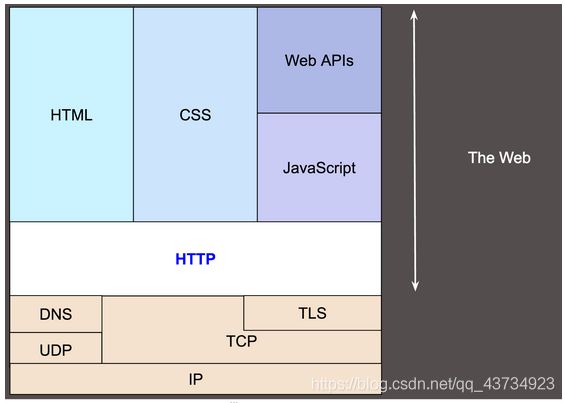
- 回应
• HTTP的版本号。
• 一个状态码(status code),来告知对应的请求发送成功或失败,以及失败的原因。
• 一个状态信息,这个信息是非权威的状态码描述信息,也就是说可以由服务端自行设定的。
• HTTP headers,与请求的很像。
• 可选的,但是比在请求报文中更加常见地包含获取资源的body。



2.4HTTP headers
Ⅰ.实验分析http报头信息
Ⅱ.目的
- wget下载一个源码包,分析HTTP头部的信息。
- 通过wget -d选项,学习HTTP头部字段信息。
- 了解http通信原理,为后期优化打下基础。
Ⅲ.执行下载
[root@localhost ~]# wget -d http://nginx.org/download/nginx-1.12.1.tar.gzⅣ.分析Debug信息
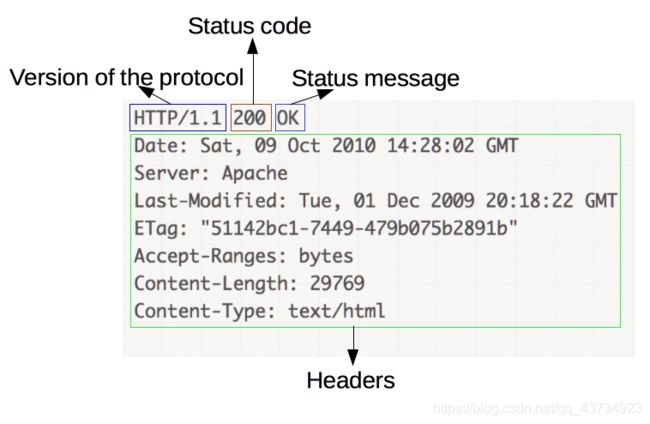
DEBUG output created by Wget 1.14 on linux-gnu. ---request begin--- 请求开始 GET /download/nginx-1.12.1.tar.gz HTTP/1.1 动作下载 页面地址 HTTP版本 User-Agent: Wget/1.14 (linux-gnu) 代理程序:wget/版本 Accept: */* 接收的类型:任何类型 Host: nginx.org 目标主机:nginx.org Connection: Keep-Alive 链接类型:启动长连接 ---request end--- 请求结束 HTTP request sent, awaiting response... 发送请求中 ---response begin--- 响应开始 HTTP/1.1 200 OK 协议版本 状态码 结果 Server: nginx/1.13.3 服务器版本 Date: Fri, 06 Oct 2017 09:05:15 GMT 相应时间 Content-Type: application/octet-stream 接收应用类型:字节流(软件类) Content-Length: 981093 文档大小 Last-Modified: Tue, 11 Jul 2017 15:45:09 GMT 资源最后修改的时间(stat文件即可查看) Connection: keep-alive 长连接开启 Keep-Alive: timeout=15 长连接有效期 ETag: "5964f285-ef865" 校验值 Accept-Ranges: bytes 接收范围:字节的范围 ---response end--- 200 OK Registered socket 3 for persistent reuse. Length: 981093 (958K) [application/octet-stream] Saving to: 'nginx-1.12.1.tar.gz'Ⅴ.相关资料
HTTP/1.1 HTTP协议版本1.1; 200 OK 响应的状态码是200,即正常返回数据,不同场景会有其它如2xx、3xx、4xx、5xx; Server 服务器软件是Nginx,版本是1.13.3; Date 从服务器获取该资源时间,时间差8小时,时区不同; Content-Type 响应的数据类型,这里的资源是文件,则是application/octet-stream了,其它还有图片, 视频、json、html、xml、css等; Content-Length response body的长度,也就是源码包的字节大小; Last-Modified 即下载的文件在服务器端最后修改的时间; Connection keep-alive Nginx开启了TCP长连接; ETag ETag HTTP响应头是资源的特定版本的标识符。 这可以让缓存更高效,并节省带宽,因为如果内容没有改变,Web服务器不需要发送完整的响应; Accept-Ranges 响应头 Accept-Range 标识自身支持范围请求,字段值用于定义范围请求的单位。 206 Partial Content Accept-Ranges 告诉我们服务器是否支持指定范围请求及哪种类型的分段请求,这里是byte Content-Range 告诉我们在整个返回体中本部分的字节位置,我们请求的是图片的前100字节
3.Nginx 部署YUM
3.1官网链接
http://www.nginx.org
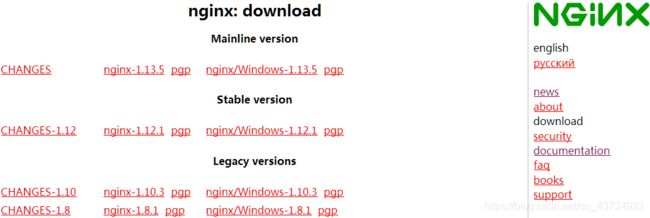
3.2Nginx版本类型
- Mainline version: 主线版,即开发版
- Stable version: 最新稳定版,生产环境上建议使用的版本
- Legacy versions: 遗留的老版本的稳定版
3.3配置YUM源
- 官网帮助手册教程
http://nginx.org/en/linux_packages.html#RHEL-CentOS
3.4安装
--- 安装前的环境问题,关闭firewalld和selinux ---
[root@ocalhost ~]# yum -y install nginx
[root@ocalhost ~]# systemctl start nginx
[root@ocalhost ~]# systemctl enable nginx
[root@ocalhost ~]# nginx -V
#查看安装附带的功能模块
- 测试
4.Nginx 配置文件
- 查看所有nginx文件
[root@ocalhost ~]# rpm -ql nginx
/etc/logrotate.d/nginx
日志轮转
/etc/nginx/nginx.conf
总配置文件
/etc/nginx/conf.d
子配置文件夹
/etc/nginx/conf.d/default.conf
默认的网站配置文件
/etc/nginx/fastcgi_params
动态网站模块文件-python,php所需的相关变量
/etc/nginx/scgi_params
/etc/nginx/uwsgi_params
/etc/nginx/koi-utf
字符集,文件编码
/etc/nginx/win-utf
/etc/ngin/koi-win
/etc/nginx/mime.types
文件关联程序,网站文件类型和相关处理程序
/etc/nginx/modules
模块文件夹,第三方模块
/etc/sysconfig/nginx
# Configuration file for the nginx service.
NGINX=/usr/sbin/nginx
CONFFILE=/etc/nginx/nginx.conf
/etc/sysconfig/nginx-debug
# Configuration file for the nginx-debug service.
NGINX=/usr/sbin/nginx-debug
CONFFILE=/etc/nginx/nginx.conf
LOCKFILE=/var/lock/subsys/nginx-debug
/usr/lib/systemd/system/nginx-debug.service
nginx调试程序启动脚本
/usr/lib/systemd/system/nginx.service
服务脚本
/usr/sbin/nginx
主程序
/usr/sbin/nginx-debug
nginx调试程序
/usr/share/doc/nginx-1.12.1
文档
/usr/share/doc/nginx-1.12.1/COPYRIGHT
/usr/share/man/man8/nginx.8.gz
man手册
/usr/share/nginx
/usr/share/nginx/html
/usr/share/nginx/html/50x.html
/usr/share/nginx/html/index.html
默认主页
/var/cache/nginx
缓存各种
# ls /var/cache/nginx
client_temp fastcgi_temp proxy_temp scgi_temp uwsgi_temp
/var/log/nginx
日志文件夹
# ls /var/log/nginx
access.log error.log
/usr/lib64/nginx
Nginx模块目录
5.Nginx 编译参数
[root@localhost ~]# nginx -v
nginx version: nginx/1.14.1
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-28) (GCC)
built with OpenSSL 1.0.2k-fips 26 Jan 2017
TLS SNI support enabled
configure arguments:
配置参数./configure --help查询帮助
--prefix=/etc/nginx
安装路径
--sbin-path=/usr/sbin/nginx
程序文件
--modules-path=/usr/lib64/nginx/modules
模块路径
---conf-path=/etc/nginx/nginx.conf
主配置文件
--error-log-path=/var/log/nginx/error.log
错误日志
--http-log-path=/var/log/nginx/access.log
访问日志
--pid-path=/var/run/nginx.pid
程序id
--lock-path=/var/run/nginx.lock
所路径防止重复启动nginx
--httpd-client-body-temp-path=/var/cache/nginx/client_temp
缓存
--httpd-proxy-temp-path/var/cache/nginx/proxy_temp
代理缓存
--http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp
php缓存
--http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp
python缓存
--http-scgi-temp-path=/var/cache/nginx/scgi_temp
--with-compat
启动动态模块兼容性
--user=nginx
用户
--group=nginx
组
--with-file-aio
使用nginx的aio特性会大大提高性能,比如图片站的特点是大量的读io操作,nginx aio不用等待每次io的结果,有助于并发处理大量io和提高nginx处理效率。
aio的优点就是能够同时提交多个io请求给内核,然后直接由内核的io调度算法去处理这些请求(directio)。
这样的话,内核就有可能执行一些合并,节约了读取文件的处理时间。
就是异步非阻塞
--with-threads
多线程模块
----------------------------------------------------------
--with-http_addition_module
响应之前或者之后追加文本内容,比如想在站点底部追加一个js广告或者新增的css样式
nginx配置addition
配置nginx.conf
server {
listen 80;
server_name www.ttlsa.com;
root /data/site/www.ttlsa.com;
location / {
add_before_body /2013/10/header.html;
add_after_body /2013/10/footer.html;
}
}
测试
以下三个文件,对应请求的主体文件和add_before_body、add_after_body对应的内容
# cat /data/site/test.ttlsa.com/2013/10/20131001_add.html
I am title<<span class="token operator">/</span>title>
<<span class="token operator">/</span>head>
<body>
ngx_http_addition_module
<<span class="token operator">/</span>body>
<<span class="token operator">/</span>html>
<span class="token comment"># cat /data/site/test.ttlsa.com/2013/10/header.html </span>
I am header<span class="token operator">!</span>
<span class="token comment"># cat /data/site/test.ttlsa.com/2013/10/footer.html </span>
footer <span class="token operator">-</span> ttlsa
访问结果如下,可以看到20131001_add<span class="token punctuation">.</span>html的顶部和底部分别嵌入了子请求header<span class="token punctuation">.</span>html和footer的内容。
<span class="token comment"># curl test.ttlsa.com/2013/10/20131001_add.html </span>
I am header<span class="token operator">!</span>
<html>
<head>
<title>I am title<<span class="token operator">/</span>title>
<<span class="token operator">/</span>head>
<body>
ngx_http_addition_module
<<span class="token operator">/</span>body>
<<span class="token operator">/</span>html>
footer <span class="token operator">-</span> ttlsa
<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">-</span>
<span class="token operator">--</span>with<span class="token operator">-</span>http_auth_request_module
认证模块
<span class="token operator">--</span>with<span class="token operator">-</span>http_dav_module
增加上传PUT<span class="token punctuation">,</span>DELETE<span class="token punctuation">,</span>MKCOL:创建集合<span class="token punctuation">,</span><span class="token function">COPY</span>和<span class="token function">MOVE</span>方法默认情况下为关闭
<span class="token operator">--</span>with<span class="token operator">-</span>http_flv_module
NGINX 添加MP4、FLV视频支持模块
<span class="token operator">--</span>with<span class="token operator">-</span>http_gunzip_module
压缩模块
<span class="token operator">--</span>with<span class="token operator">-</span>http_mp4_module
<span class="token operator">--</span>with<span class="token operator">-</span>http_random_index_module
mginx显示随机主页模块
<span class="token operator">--</span>with<span class="token operator">-</span>http_realip_module
mginx获取真实ip模块
<span class="token operator">--</span>with<span class="token operator">-</span>http_secure_link_module
nginx安全下载模块
<span class="token operator">--</span>with<span class="token operator">-</span>http_slice_module
nginx中文文档
<span class="token operator">--</span>with<span class="token operator">-</span>http_ssl_module
安全模块
<span class="token operator">--</span>with<span class="token operator">-</span>http_stub_status_module
访问状态
<span class="token operator">--</span>with<span class="token operator">-</span>http_sub_module
nginx替换网站响应内容
<span class="token operator">--</span>with<span class="token operator">-</span>http_v2_module
<span class="token operator">--</span>with<span class="token operator">-</span>mail
邮件客户端
<span class="token operator">--</span>with<span class="token operator">-</span>mail_ssl_module
<span class="token operator">--</span>with<span class="token operator">-</span>stream
负载均衡模块。nginx从1<span class="token punctuation">.</span>9<span class="token punctuation">.</span>0开始,新增加了一个stream模块,用来实现四层协议的转发、代理或者负载均衡等。
<span class="token operator">--</span>with<span class="token operator">-</span>stream_reaip_module
<span class="token operator">--</span>with<span class="token operator">-</span>stream_ssl_module
<span class="token operator">--</span>with<span class="token operator">-</span>stream_ssl_preread_module
<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>CPU优化参数<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>
<span class="token operator">--</span>with<span class="token operator">-</span>cc<span class="token operator">-</span>opt=<span class="token string">'-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --
param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fPIC'</span>
<span class="token operator">--</span>with<span class="token operator">-</span>ld<span class="token operator">-</span>opt=<span class="token string">'-Wl,-z,relro -Wl,-z,now -pie'</span>
<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">-</span>
</code></pre>
<h1>6.Nginx 基础配置</h1>
<h2>6.1观察主配置文件</h2>
<ul>
<li>分类</li>
</ul>
<blockquote>
<p>CoreModule 核心模块(进程数等)</p>
<p>EventsModule 事件驱动模块(工作模式等)</p>
<p>HttpCoreModule http内核模块(文档程序类型,配置文件等)</p>
</blockquote>
<ul>
<li>模块功能</li>
</ul>
<blockquote>
<p> 1、全局/核心块:配置影响nginx全局的指令。一般有运行nginx服务器的用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process数等。</p>
<p> 2、events块:配置影响nginx服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。</p>
<p> 3、http块:可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type定义,日志自定义,是否使用sendfile传输文件,连接超时时间,单连接请求数等。</p>
<p> 4、server块:配置虚拟主机的相关参数,一个http中可以有多个server。</p>
<p> 5、location块:配置请求的路由,以及各种页面的处理情况。</p>
</blockquote>
<ul>
<li>主配置文件解析</li>
</ul>
<pre><code class="prism language-powershell">user nginx
运行nginx程序的独立账号
worker_processes 1<span class="token punctuation">;</span>
启动的worker进程数量(CPU数量一致或auto)
error_log <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>run<span class="token operator">/</span>nginx<span class="token operator">/</span>error<span class="token punctuation">.</span>log warn<span class="token punctuation">;</span>
错误日志存放位置
pid <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>run<span class="token operator">/</span>nginx<span class="token punctuation">.</span>pid<span class="token punctuation">;</span>
events <span class="token punctuation">{
</span>
事件
use epoll
事件驱动模型epoll【默认】,事件驱动模型分类:<span class="token function">select</span><span class="token punctuation">|</span>poll<span class="token punctuation">|</span>kqueue<span class="token punctuation">|</span>epoll<span class="token punctuation">|</span>resig<span class="token punctuation">|</span><span class="token operator">/</span>dev<span class="token operator">/</span>poll<span class="token punctuation">|</span>eventport
worker_connections 10240<span class="token punctuation">;</span>
每个worker进程允许处理的最大连接数,例如10240,65535
<span class="token punctuation">}</span>
http <span class="token punctuation">{
</span>
include <span class="token operator">/</span>etc<span class="token operator">/</span>nginx<span class="token operator">/</span>mime<span class="token punctuation">.</span>types<span class="token punctuation">;</span>
文档和程序的关联记录
default_type application<span class="token operator">/</span>octet<span class="token operator">-</span>stream<span class="token punctuation">;</span>
字节流处理方式
log_format main <span class="token string">'$remote_addr - $remove_user [$time_local] "$request"'</span>
<span class="token string">'$status $body_bytes_sent "$http_refer"'</span>
<span class="token string">'"$http_user_agent" "$http_x_forwarded_for"'</span><span class="token punctuation">;</span>
日志格式
access_log <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>log<span class="token operator">/</span>nginx<span class="token operator">/</span>access<span class="token punctuation">.</span>log main<span class="token punctuation">;</span>
sendfile on<span class="token punctuation">;</span>
优化参数,高效传输文件的模式
Nginx高级篇sendfile配置:
sendfile: 设置为on表示启动高效传输文件的模式。sendfile可以让Nginx在传输文件时直接在磁盘和tcp socket之间传输数据。
如果这个参数不开启,会先在用户空间(Nginx进程空间)申请一个buffer,用read函数把数据从磁盘读到cache,
再从cache读取到用户空间的buffer,再用<span class="token function">write</span>函数把数据从用户空间的buffer写入到内核的buffer,最后到tcp socket。
开启这个参数后可以让数据不用经过用户buffer。
<span class="token comment">#tcp_nopush on;</span>
优化参数,也就是说tcp_nopush = on 会设置调用tcp_cork方法,这个也是默认的,结果就是数据包不会马上传送出去,
等到数据包最大时,一次性的传输出去,这样有助于解决网络堵塞。
keepalive_timeout 65<span class="token punctuation">;</span>
优化参数,长连接
<span class="token comment">#gzip on;</span>
压缩参数
include <span class="token operator">/</span>etc<span class="token operator">/</span>nginx<span class="token operator">/</span>conf<span class="token punctuation">.</span>d/<span class="token operator">*</span><span class="token punctuation">.</span>conf
包含子配置文件夹
<span class="token punctuation">}</span>
</code></pre>
<h2>6.2观察默认虚拟主机配置文件</h2>
<pre><code class="prism language-powershell"><span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/default.conf</span>
server<span class="token punctuation">{
</span>
默认网站配置文件
listen 80<span class="token punctuation">;</span>
监听端口
server_name localhost<span class="token punctuation">;</span>
FQDN:全限定域名
<span class="token comment">#charset koi8-r;</span>
网页字符类型
<span class="token comment">#access_log /var/log/nginx/host.access.log main;</span>
日志
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
root <span class="token operator">/</span>usr<span class="token operator">/</span>share<span class="token operator">/</span>nginx<span class="token operator">/</span>html<span class="token punctuation">;</span>
主目录
index index<span class="token punctuation">.</span>html index<span class="token punctuation">.</span>htm<span class="token punctuation">;</span>
默认主页名
<span class="token punctuation">}</span>
<span class="token comment">#error_page 404 /404.html;</span>
错误页面
<span class="token comment"># redirect server error pages to the static page /50x.html</span>
error_page 500 502 503 504 <span class="token operator">/</span>50x<span class="token punctuation">.</span>html<span class="token punctuation">;</span>
错误页面
location = <span class="token operator">/</span>50<span class="token punctuation">.</span>html<span class="token punctuation">;</span>
错误页面
root <span class="token operator">/</span>usr<span class="token operator">/</span>share<span class="token operator">/</span>nginx<span class="token operator">/</span>html<span class="token punctuation">;</span>
错误页面主目录
<span class="token punctuation">}</span>
<span class="token comment"># proxy the PHP scripts to Apache listening on 127.0.0.1:80</span>
代理设置
<span class="token comment">#location ~ \.php${
</span>
<span class="token comment"># proxy_pass http://127.0.0.1;</span>
<span class="token comment">#}</span>
<span class="token comment"># pass the PHP scripts tp FastCGI server listening on 127.0.0.1:9000</span>
动态网站设置
<span class="token comment">#location ~ \.php${
</span>
<span class="token comment"># root html;</span>
<span class="token comment"># fastcgi_pass 127.0.0.1:9000;</span>
<span class="token comment"># fastcgi_index ondex.php</span>
<span class="token comment"># fastcgi_param SCRIPT_FILENAME /scrpts$fastcgi_script_name;</span>
<span class="token comment"># incule fastcgi_params;</span>
<span class="token comment">#}</span>
<span class="token comment"># deny access to .htaccess files, if Apache's document root</span>
访问控制部分
<span class="token comment">#concurs with nginx's one</span>
<span class="token comment">#location ~ /\.ht{
</span>
<span class="token comment"># deny all;</span>
<span class="token comment">#}</span>
<span class="token punctuation">}</span>
</code></pre>
<h2>6.3启动一个新的虚拟主机</h2>
<ul>
<li>1.配置文件</li>
</ul>
<pre><code class="prism language-powershell"><span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/jslinux.conf</span>
server<span class="token punctuation">{
</span>
listen 80<span class="token punctuation">;</span>
server_name jslinux<span class="token punctuation">.</span>com<span class="token punctuation">;</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
root <span class="token operator">/</span>jslinux<span class="token punctuation">;</span>
index index<span class="token punctuation">.</span>html<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>
server 虚拟主机
listen 监听端口
server_name 服务器名称
location 网站目录设置
root 网站主目录在本地的路径
index 主页文件名
http<span class="token punctuation">{
</span><span class="token punctuation">}</span> 是整个服务器,所有虚拟主机的设置。
server<span class="token punctuation">{
</span><span class="token punctuation">}</span>是某一个虚拟主机的设置
location<span class="token punctuation">{
</span><span class="token punctuation">}</span> 是某一个页面的设置。
<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># mkdir /jslinux</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /jslinux/index.html</span>
2020zz<span class="token operator">-</span>js<br <span class="token operator">/</span>>
cloud compting
</code></pre>
<ul>
<li>2.重启服务</li>
</ul>
<pre><code class="prism language-powershell"><span class="token namespace">[root@localhost ~]</span><span class="token comment"># systemctl restart nginx</span>
</code></pre>
<ul>
<li>3.本地域名解析和访问</li>
</ul>
<blockquote>
<p><a href="http://img.e-com-net.com/image/info8/f54b088731fa43aeb35bd80258cd3a7b.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f54b088731fa43aeb35bd80258cd3a7b.jpg" alt="Nginx基础入门篇_第19张图片" width="490" height="136" style="border:1px solid black;"></a></p>
</blockquote>
<h1>7.Nginx 日志Log</h1>
<h2>7.1日志配置</h2>
<ul>
<li>日志模块</li>
</ul>
<blockquote>
<p><strong>Ⅰ.官方文档</strong></p>
<p>http://nginx.org/en/docs/http/ngx_http_log_module.html</p>
<p><strong>Ⅱ.日志模块名称</strong></p>
<p>ngx_http_log_module</p>
</blockquote>
<ul>
<li>相关指令</li>
</ul>
<pre><code class="prism language-powershell">log_format
日志格式
access_log
访问日志
error_log
错误日志
open_log_file_cache
语法如下:
open_log_file_cache max=N <span class="token namespace">[inactive=time]</span> <span class="token namespace">[mim_uses=N]</span> <span class="token namespace">[valid=time]</span> <span class="token punctuation">|</span> off
该指令默认是禁止的,等同于:
open_log_file_cache off<span class="token punctuation">;</span>
open_log_file_cache 指令的各项参数说明如下:
max: 设置缓存中的最大文件描述符数量。如果超过设置的最大文件描述符数量,则采用LRU <span class="token punctuation">(</span>Least Recently Used<span class="token punctuation">)</span>算法清除<span class="token string">"较不常使用的文件描述符"</span>。
LRU <span class="token punctuation">(</span>Least Recently Used<span class="token punctuation">)</span>算法的基本概念是:当内存缓冲区剩余的可用空间不够时,缓冲区尽可能地先保留使用者最常使用的数据,将最近未使用的数据移出内存,腾出空间来加载另外的数据。
inactive:
设置一个时间,如果在设置的时间内没有使用此文件描述符,则自动删除此描述符。此参数为可选参数,默认的时间为10秒钟。
min_uses:
在参数 inactive 指定的时间范围内,如果日志文件超过被使用的次数,则将该日志文件的描述符记入缓存。默认次数为1。
valid:
设置多长时间检查一次,看一看变量指定的日志文件路径与文件名是否仍然存在。默认时间为60秒。
off:
禁止使用缓存。
open_log_file_cache
指令的设置示例如下:
open_log_file_cache max=1000 inactive=20s min_uses=2 valid=1m<span class="token punctuation">;</span>
</code></pre>
<ul>
<li>日志的格式和命令(log_format)</li>
</ul>
<p>Ⅰ.简介</p>
<blockquote>
<p>Nginx有非常灵活的日志记录模式。每个级别的配置可以有各自独立的访问日志。日志格式通过log_format命令定义。</p>
</blockquote>
<p>Ⅱ.语法</p>
<pre><code class="prism language-powershell">Syntax:log_format name <span class="token namespace">[escape=default | json]</span> string <span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">;</span>
name 表示格式名称
string 表示定义的格式
</code></pre>
<p>Ⅲ.默认值</p>
<pre><code class="prism language-powershell">Default: log_format combined <span class="token string">"..."</span><span class="token punctuation">;</span>
log_format 有默认的无需设置的combined日志格式,相当于apache的combined日志格式
</code></pre>
<p>Ⅳ.环境</p>
<blockquote>
<p>Context:http</p>
<p>网站代理LB</p>
<p>全局和局部</p>
<p>代理服务器的日志格式不同</p>
<p> 如果Nginx位于负载均衡器,squid,nginx反向代理之后,web服务器无法直接获取到客户端真实的IP地址。<br> $remote_addr获取的是反向代理的IP地址。反向代理服务器在转发请求的http头信息中,可以增加X-Forwarded-For信息,用来记录客户端IP地址和客户端请求的服务器地址。</p>
</blockquote>
<pre><code class="prism language-powershell">nginx代理服务器日志格式如下:
log_format porxy <span class="token string">'$http_x_forwarded_for - $remote_user [$time_local] '</span>
<span class="token string">' "$request" $status $body_bytes_sent '</span>
<span class="token string">' "$http_referer" "$http_user_agent" '</span><span class="token punctuation">;</span>
</code></pre>
<p>Ⅴ.定义设置位置</p>
<pre><code class="prism language-powershell"><span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim/etc/nginx/nginx.conf</span>
</code></pre>
<blockquote>
<p>日志部分配置</p>
</blockquote>
<p><a href="http://img.e-com-net.com/image/info8/75568ff734ef4fa3a29e85786fae1958.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/75568ff734ef4fa3a29e85786fae1958.jpg" alt="Nginx基础入门篇_第20张图片" width="650" height="111" style="border:1px solid black;"></a></p>
<blockquote>
<p>日志格式允许包含的变量</p>
</blockquote>
<pre><code class="prism language-powershell"><span class="token variable">$remote_addr</span>
远程地址:记录客户端的IP地址
<span class="token variable">$remote_user</span>
远程用户:记录客户端用户名称
<span class="token punctuation">[</span><span class="token variable">$time_local</span><span class="token punctuation">]</span>
本地时间:服务器自身时间
<span class="token variable">$request</span>
<span class="token string">"GET /1.html HTTP/1.1"</span>
<span class="token string">"GET /index.html HTTP/1.1"</span>
请求:记录请求的URL和HTTP协议
<span class="token variable">$status</span>
状态:记录请求状态,常见的http状态码200<span class="token operator">/</span>404<span class="token operator">/</span>503<span class="token operator">/</span>100<span class="token operator">/</span>301<span class="token operator">/</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>
<span class="token variable">$body_bytes_sent</span>
发送客户端的字节数,不包括相应的大小
<span class="token variable">$http_referer</span>
记录从哪个页面链接访问过来的(超链接)
<span class="token variable">$http_user_agent</span>
记录客户端浏览器相关信息
<span class="token variable">$http_x_forwarded_for</span>
代理IP
old
<span class="token variable">$request_length</span>
请求的长度(包括请求行,请求头和请求正文)
<span class="token variable">$request_time</span>
请求处理时间,单位为秒,精度毫秒;从读入客户端的第一个字节开始,直到把最后一个字符发送给客户端后进行日志写入为止。
<span class="token variable">$time_iso8601</span>
ISO8601标准格式下的本地时间
<span class="token variable">$bytes_sent</span>
发送给客户端的总字节数(可在主配置文件中,增加此项观察)
<span class="token variable">$mesc</span>
日志写入时间。单位为秒,精度是毫秒。
</code></pre>
<blockquote>
<p>总有一个404提示</p>
</blockquote>
<p><a href="http://img.e-com-net.com/image/info8/eca66453bfdc4d21acb7f8317126bd18.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/eca66453bfdc4d21acb7f8317126bd18.jpg" alt="在这里插入图片描述" width="650" height="61"></a></p>
<pre><code class="prism language-powershell">favicon<span class="token punctuation">.</span>ico文件是浏览器收藏网址时显示的图标,当第一次访问页面时,浏览器会自动发起请求获取页面的favicon<span class="token punctuation">.</span>ico文件。
当<span class="token operator">/</span>favicon<span class="token punctuation">.</span>ico文件不存在时,服务器会记录404日志。
127<span class="token punctuation">.</span>0<span class="token punctuation">.</span>0<span class="token punctuation">.</span>1 <span class="token operator">-</span> <span class="token operator">-</span> <span class="token punctuation">[</span>26<span class="token operator">/</span>Jul<span class="token operator">/</span>2015:22:25:07 <span class="token operator">+</span>0800<span class="token punctuation">]</span> “GET <span class="token operator">/</span>favicon<span class="token punctuation">.</span>ico HTTP<span class="token operator">/</span>1<span class="token punctuation">.</span>1” 404 168 “<span class="token operator">-</span>” “Mozilla<span class="token operator">/</span>5<span class="token punctuation">.</span>0 <span class="token punctuation">(</span>Macintosh<span class="token punctuation">;</span> Intel Mac OS X 10<span class="token punctuation">.</span>10<span class="token punctuation">;</span> <span class="token function">rv</span>:36<span class="token punctuation">.</span>0<span class="token punctuation">)</span> Gecko<span class="token operator">/</span>20100101 Firefox<span class="token operator">/</span>36<span class="token punctuation">.</span>0” “<span class="token operator">-</span>”
127<span class="token punctuation">.</span>0<span class="token punctuation">.</span>0<span class="token punctuation">.</span>1 <span class="token operator">-</span> <span class="token operator">-</span> <span class="token punctuation">[</span>26<span class="token operator">/</span>Jul<span class="token operator">/</span>2015:22:25:07 <span class="token operator">+</span>0800<span class="token punctuation">]</span> “GET <span class="token operator">/</span>favicon<span class="token punctuation">.</span>ico HTTP<span class="token operator">/</span>1<span class="token punctuation">.</span>1” 404 168 “<span class="token operator">-</span>” “Mozilla<span class="token operator">/</span>5<span class="token punctuation">.</span>0 <span class="token punctuation">(</span>Macintosh<span class="token punctuation">;</span> Intel Mac OS X 10<span class="token punctuation">.</span>10<span class="token punctuation">;</span> <span class="token function">rv</span>:36<span class="token punctuation">.</span>0<span class="token punctuation">)</span> Gecko<span class="token operator">/</span>20100101 Firefox<span class="token operator">/</span>36<span class="token punctuation">.</span>0” “<span class="token operator">-</span>“
</code></pre>
<blockquote>
<p>解决办法</p>
</blockquote>
<pre><code class="prism language-powershell">当一个站点没有设置favicon<span class="token punctuation">.</span>ico时,access<span class="token punctuation">.</span>log会记录了大量favicon<span class="token punctuation">.</span>ico 404信息。
这样有两个缺点:
1<span class="token punctuation">.</span>使access<span class="token punctuation">.</span>log文件变大,记录很多没有用的数据。
2<span class="token punctuation">.</span>因为大部分是favicon<span class="token punctuation">.</span>ico 404信息,当要查看信息时,会影响搜寻效率。
解决方法如下:
在nginx的配置中加入
location = <span class="token operator">/</span>favicon<span class="token punctuation">.</span>ico <span class="token punctuation">{
</span>
log_not_found off<span class="token punctuation">;</span>
access_log off<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
以上配置说明:
location = <span class="token operator">/</span>favicon<span class="token punctuation">.</span>ico 表示当访问<span class="token operator">/</span>favicon<span class="token punctuation">.</span>ico时,
log_not_found off 关闭日志
access_log off 不记录在access<span class="token punctuation">.</span>log
完整配置如下:
server <span class="token punctuation">{
</span>
listen 80<span class="token punctuation">;</span>
server_name fdipzone<span class="token punctuation">.</span>com<span class="token punctuation">;</span>
root <span class="token operator">/</span>Users<span class="token operator">/</span>fdipzone<span class="token operator">/</span>home<span class="token punctuation">;</span>
access_log <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>log<span class="token operator">/</span>nginx<span class="token operator">/</span>access<span class="token punctuation">.</span>log main<span class="token punctuation">;</span>
error_log <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>log<span class="token operator">/</span>nginx<span class="token operator">/</span>error<span class="token punctuation">.</span>log debug<span class="token punctuation">;</span>
location = <span class="token operator">/</span>favicon<span class="token punctuation">.</span>ico <span class="token punctuation">{
</span>
log_not_found off<span class="token punctuation">;</span>
access_log off<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
index index<span class="token punctuation">.</span>html index<span class="token punctuation">.</span>htm index<span class="token punctuation">.</span>php<span class="token punctuation">;</span>
include <span class="token operator">/</span>usr<span class="token operator">/</span>local<span class="token operator">/</span>etc<span class="token operator">/</span>nginx<span class="token operator">/</span>conf<span class="token punctuation">.</span>d<span class="token operator">/</span>php<span class="token operator">-</span>fpm<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
</code></pre>
<p>Ⅵ.提示</p>
<ul>
<li>访问日志和错误日志</li>
</ul>
<pre><code class="prism language-powershell">access_log
error_log
案例:
access_log:
某条日志记录:
192<span class="token punctuation">.</span>168<span class="token punctuation">.</span>100<span class="token punctuation">.</span>254 <span class="token operator">-</span> <span class="token operator">-</span> <span class="token punctuation">[</span>17<span class="token operator">/</span>Sep<span class="token operator">/</span>2020:14:45:59 <span class="token operator">+</span>0800<span class="token punctuation">]</span> <span class="token string">"GET /nginx-logo.png HTTP/1.1"</span> 200 368 <span class="token string">"http://192.168.100.10/"</span> <span class="token string">"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0"</span> <span class="token string">"-"</span>
<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>
某条日志记录含义:
192<span class="token punctuation">.</span> 远程主机IP
<span class="token operator">-</span> <span class="token operator">-</span> 用户
<span class="token punctuation">[</span>2020<span class="token punctuation">]</span>时间
get获得,下载,还有post提交。
<span class="token operator">/</span>nginx<span class="token operator">-</span>logo<span class="token punctuation">.</span>png 下载图片
http版本
状态码 什么结果。对,还是错
200 状态码信息 368 请求的资源大小
引用自哪个连接,主页http:<span class="token operator">/</span><span class="token operator">/</span>192<span class="token punctuation">.</span>168<span class="token punctuation">.</span>100<span class="token punctuation">.</span>10<span class="token operator">/</span>
Mozilla 5<span class="token punctuation">.</span>0浏览器的版本
Windows NT 客户端系统类型
<span class="token operator">-</span>远程客户端主机地址 (请看官方注释)
<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>-<span class="token operator">--</span>
error_log:
个性化404:
1<span class="token punctuation">.</span>修改配置文件
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># /etc/nginx/nginx.conf</span>
http <span class="token punctuation">{
</span>
error_page 404 <span class="token operator">/</span>404<span class="token punctuation">.</span>html<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># /etc/nginx/conf.d/jslinux.conf</span>
server<span class="token punctuation">{
</span>
location = <span class="token operator">/</span>404<span class="token punctuation">.</span>html <span class="token punctuation">{
</span>
root <span class="token operator">/</span>jslinux<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># systemctl restart nginx</span>
2<span class="token punctuation">.</span>创建错误反馈页面
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /xuleilinux/404.html</span>
3<span class="token punctuation">.</span>访问
访问不存在的页面
4<span class="token punctuation">.</span>查看404日志
观察404页面的现象
</code></pre>
<ul>
<li>日志缓存</li>
</ul>
<pre><code class="prism language-powershell">1<span class="token punctuation">.</span>简介:
大量访问到来时,对于每一条日志记录,都将是先打开文件,再写入日志,然后关闭<span class="token punctuation">.</span>占用了系统的IO<span class="token punctuation">,</span>与业务无关。
可以使用open_log_file_cache来设置
2<span class="token punctuation">.</span>Syntax:
open_log_file_cache max=1000 inactive=20s min_uses=3 valid=1m<span class="token punctuation">;</span>
max 1000 指的是日志文件的FD,最大的缓存数量为1000。超了怎么办,看下面
min_users 3 20秒内小于3次访问的FD,就给你清掉,结合inactive 20s 的时间。
valid 1m 检查周期为1分钟。
总结:缓存最多1000个,到了极限<span class="token punctuation">,</span>每分钟开始清除掉 20秒内小于3次的文件FD<span class="token punctuation">.</span>
3<span class="token punctuation">.</span>Default:
open_log_file_cache off<span class="token punctuation">;</span>
4<span class="token punctuation">.</span>Context:
http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> locatition
http<span class="token punctuation">{
</span><span class="token punctuation">}</span> 将整个服务器所有网站,所有页面的日志进行缓存
server<span class="token punctuation">{
</span><span class="token punctuation">}</span> 将某一个网站的所有页面日志,进行缓存
location<span class="token punctuation">{
</span><span class="token punctuation">}</span>某一个页面的日志,进行缓存
</code></pre>
<h2>7.2日志轮转/切割</h2>
<ul>
<li>前言</li>
</ul>
<pre><code class="prism language-powershell">Nginx安装,会默认启动日志轮转。
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># rpm -ql nginx | grep log</span>
<span class="token operator">/</span>etc<span class="token operator">/</span>logrotate<span class="token punctuation">.</span>d<span class="token operator">/</span>nginx
<span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>log<span class="token operator">/</span>nginx
</code></pre>
<ul>
<li>观察</li>
</ul>
<pre><code class="prism language-powershell"><span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/logrotate.d/nginx</span>
vim <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>log<span class="token operator">/</span>nginx/<span class="token operator">*</span>log<span class="token punctuation">{
</span>
待切割的日志
create 0644 nginx nginx
创建新的日志文件,属主属组
daily
每天轮转
rotate 10
保留最后10份日志
missingok
丢失不提示
notifempty
空文件不转存
compress
压缩
sharedscripts
运行脚本
postratate
<span class="token operator">/</span>bin<span class="token operator">/</span><span class="token function">kill</span> <span class="token operator">-</span>USR1 `<span class="token function">cat</span> <span class="token operator">/</span>run<span class="token operator">/</span>nginx<span class="token punctuation">.</span>pid 2><span class="token operator">/</span>dev<span class="token operator">/</span>null` 2><span class="token operator">/</span>dev<span class="token operator">/</span>null <span class="token punctuation">|</span><span class="token punctuation">|</span> true
USR1亦通常被用来告知应用程序重载配置文件;
例如,向Apache HTTP服务器发送一个USR1信号将导致以下步骤的发生:
停止接受新的连接,等待当前连接停止,重新载入配置文件,重新打开日志文件,重启服务器,从而实现相对平滑的不关机的更改。
endscripts
<span class="token punctuation">}</span>
测试
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># logrotate -f /etc/logrotate.conf</span>
手动轮转
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># ls -l /var/log/nginx</span>
查看日志轮转文件
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># watch -n1 ls -l /var/log/nginx/</span>
动态查看
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># ps aux | grep nginx</span>
62589
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># ls -l /proc/62589/fd</span>
查看日志轮转的目录位置
</code></pre>
<ul>
<li>轮转语句</li>
</ul>
<pre><code class="prism language-powershell">轮转指令
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># /usr/sbin/logrotate -s /var/lib/logrotate/logrotate.status /etc/logrotate.conf</span>
</code></pre>
<ul>
<li>切割原理回顾(扩展)</li>
</ul>
<pre><code class="prism language-powershell">1<span class="token punctuation">.</span>cron每小时呼唤一次anacron
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/cron.hourly/0anacron</span>
2<span class="token punctuation">.</span>anacrontab以天,周,月循环往复
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/anacrontab </span>
3<span class="token punctuation">.</span>天循环
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/cron.daily/logrotate</span>
4<span class="token punctuation">.</span>立刻循环<span class="token operator">/</span>手动轮转
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># /usr/sbin/logrotate -s /var/lib/logrotate/logrotate.status /etc/logrotate.conf</span>
5<span class="token punctuation">.</span>anacron当天的时间戳
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /var/spool/anacron/cron.daily</span>
20200920
6<span class="token punctuation">.</span>anacron循环后的时间戳
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /var/lib/logrotate/logrotate.status</span>
<span class="token string">"/var/log/nginx/host.404.log"</span> 2020<span class="token operator">-</span>09<span class="token operator">-</span>20<span class="token operator">-</span>20:8:56
根据该时间确定是否轮转。
</code></pre>
<h2>7.3日志分析</h2>
<pre><code class="prism language-powershell">日志格式<span class="token operator">/</span>日志条目
常用字段:
<span class="token variable">$remote_addr</span> <span class="token variable">$1</span>
远程客户端地址
<span class="token variable">$time_local</span> <span class="token variable">$4</span>
本地时间
<span class="token variable">$status</span> <span class="token variable">$9</span>
状态码
<span class="token variable">$body_bytes_sent</span> <span class="token variable">$10</span>
请求体积
案例样本:
1<span class="token punctuation">.</span>统计2017年9月5日 PV量
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | wc -l</span>
1260
8点<span class="token operator">-</span>9点
方法1:
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017:08' js.log | wc -l</span>
方法2:
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># awk '$4>="[05/Sep/2017:08:00:00" && $4<="[05/Sep/2017:09:00:00" {print $0}' js.log | wc -l</span>
2<span class="token punctuation">.</span>统计2017年9月5日 一天内访问最多的10个IP(IP top10)
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{ ips[$1]++ } END{for(i in ips){print i,ips[i]} }'| sort -k2 -rn | head -n10</span>
182<span class="token punctuation">.</span>140<span class="token punctuation">.</span>217<span class="token punctuation">.</span>111 138
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>122 95
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>124 84
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>59 73
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>101 73
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>62 62
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>60 56
58<span class="token punctuation">.</span>216<span class="token punctuation">.</span>107<span class="token punctuation">.</span>23 52
119<span class="token punctuation">.</span>147<span class="token punctuation">.</span>33<span class="token punctuation">.</span>22 50
121<span class="token punctuation">.</span>31<span class="token punctuation">.</span>30<span class="token punctuation">.</span>169 42
3<span class="token punctuation">.</span>统计2017年9月5日 访问大于100次的IP
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{ ips[$1]++ } END{for(i in ips){if(ips[i]>100){print i,ips[i]}}}' | sort -k2 -rn | head -n10</span>
182<span class="token punctuation">.</span>140<span class="token punctuation">.</span>217<span class="token punctuation">.</span>111 138
4<span class="token punctuation">.</span>统计2017年9月5日 访问最多的10个页面(<span class="token variable">$request</span> top10)
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{urls[$7]++} END{for(i in urls){print i,urls[i]}}' | sort -k2 -rn | head -n10</span>
<span class="token operator">/</span> 60
<span class="token operator">/</span>img<span class="token operator">/</span>banner_btn<span class="token punctuation">.</span>png 41
<span class="token operator">/</span>js<span class="token operator">/</span>jquery<span class="token operator">-</span>1<span class="token punctuation">.</span>8<span class="token punctuation">.</span>3<span class="token punctuation">.</span>min<span class="token punctuation">.</span>js 23
<span class="token operator">/</span>img<span class="token operator">/</span>kbxx_bg<span class="token punctuation">.</span>png 21
<span class="token operator">/</span>css<span class="token operator">/</span>cd_index<span class="token punctuation">.</span>css 21
<span class="token operator">/</span>d<span class="token operator">/</span>file<span class="token operator">/</span>works<span class="token operator">/</span>2017<span class="token operator">-</span>04<span class="token operator">-</span>28<span class="token operator">/</span>afed3f12498e47572f7a31dad04c4717<span class="token punctuation">.</span>jpg 20
<span class="token operator">/</span>js<span class="token operator">/</span>ymcore<span class="token punctuation">.</span>js 19
<span class="token operator">/</span>img<span class="token operator">/</span>ico<span class="token punctuation">.</span>png 18
<span class="token operator">/</span>img<span class="token operator">/</span>huanglaoshi<span class="token punctuation">.</span>jpg 17
<span class="token operator">/</span>e<span class="token operator">/</span>admin<span class="token operator">/</span>DoTimeRepage<span class="token punctuation">.</span>php 17
5<span class="token punctuation">.</span>统计2017年9月5日 每个URL访问内容大小(<span class="token variable">$body_bytes_sent</span>)
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{ urls[$7]++; size[$7]+=$10} END{for(i in urls){print i,urls[i],size[i]}}'| sort -k2 -rn | head -n10</span>
<span class="token operator">/</span> 44 4040481
<span class="token operator">/</span>e<span class="token operator">/</span>admin<span class="token operator">/</span>DoTimeRepage<span class="token punctuation">.</span>php 34 5372
<span class="token operator">/</span>skin<span class="token operator">/</span>sz<span class="token operator">/</span>js<span class="token operator">/</span>minkh<span class="token punctuation">.</span>php 25 678973
<span class="token operator">/</span>js<span class="token operator">/</span>jquery<span class="token operator">-</span>1<span class="token punctuation">.</span>11<span class="token punctuation">.</span>3<span class="token punctuation">.</span>min<span class="token punctuation">.</span>js 25 75026
<span class="token operator">/</span>skin<span class="token operator">/</span>sz<span class="token operator">/</span>js<span class="token operator">/</span>page<span class="token operator">/</span>jquery<span class="token operator">-</span>1<span class="token punctuation">.</span>4<span class="token punctuation">.</span>2<span class="token punctuation">.</span>min<span class="token punctuation">.</span>js 22 173642
<span class="token operator">/</span>skin<span class="token operator">/</span>sz<span class="token operator">/</span>js<span class="token operator">/</span>page<span class="token operator">/</span>ready<span class="token punctuation">.</span>js 21 1906
<span class="token operator">/</span>skin<span class="token operator">/</span>sz<span class="token operator">/</span>js<span class="token operator">/</span>table<span class="token punctuation">.</span>js 19 3312
<span class="token operator">/</span>skin<span class="token operator">/</span>sz<span class="token operator">/</span>js<span class="token operator">/</span>page<span class="token operator">/</span>core<span class="token punctuation">.</span>js 18 10184
<span class="token operator">/</span>img<span class="token operator">/</span>sz_home<span class="token operator">/</span>sz_js<span class="token punctuation">.</span>png 16 42120
<span class="token operator">/</span>img<span class="token operator">/</span>kbxx_bg<span class="token punctuation">.</span>png 16 7818
6<span class="token punctuation">.</span>统计2017年9月5日 每个IP访问状态码(<span class="token variable">$status</span>)
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{ip_code[$1" "$9]++} END{for(i in ip_code){print i,ip_code[i]} }' | sort -k1 -rn | head -n10</span>
220<span class="token punctuation">.</span>112<span class="token punctuation">.</span>25<span class="token punctuation">.</span>173 304 1
220<span class="token punctuation">.</span>112<span class="token punctuation">.</span>25<span class="token punctuation">.</span>173 200 30
183<span class="token punctuation">.</span>214<span class="token punctuation">.</span>128<span class="token punctuation">.</span>195 304 18
183<span class="token punctuation">.</span>214<span class="token punctuation">.</span>128<span class="token punctuation">.</span>195 200 10
183<span class="token punctuation">.</span>214<span class="token punctuation">.</span>128<span class="token punctuation">.</span>152 200 10
183<span class="token punctuation">.</span>214<span class="token punctuation">.</span>128<span class="token punctuation">.</span>142 304 18
183<span class="token punctuation">.</span>214<span class="token punctuation">.</span>128<span class="token punctuation">.</span>142 200 5
182<span class="token punctuation">.</span>140<span class="token punctuation">.</span>217<span class="token punctuation">.</span>111 404 7
182<span class="token punctuation">.</span>140<span class="token punctuation">.</span>217<span class="token punctuation">.</span>111 304 109
182<span class="token punctuation">.</span>140<span class="token punctuation">.</span>217<span class="token punctuation">.</span>111 200 22
7<span class="token punctuation">.</span>统计2017年9月5日 每个IP的访问状态为404及出现次数(<span class="token variable">$status</span>)
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '$9=="404"{ccc[$1" "$9]++} END{for(i in ccc){print i,ccc[i]}}' | sort -k3 -rn</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{if($9="404"){ip_code[$1" "$9]++}} END{for(i in ip_code){print i,ip_code[i]}}'</span>
58<span class="token punctuation">.</span>216<span class="token punctuation">.</span>107<span class="token punctuation">.</span>21 404 5
139<span class="token punctuation">.</span>215<span class="token punctuation">.</span>203<span class="token punctuation">.</span>174 404 67
125<span class="token punctuation">.</span>211<span class="token punctuation">.</span>204<span class="token punctuation">.</span>174 404 10
58<span class="token punctuation">.</span>216<span class="token punctuation">.</span>107<span class="token punctuation">.</span>22 404 25
106<span class="token punctuation">.</span>117<span class="token punctuation">.</span>249<span class="token punctuation">.</span>12 404 6
<span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>
8<span class="token punctuation">.</span>统计前一分钟的PV量
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># date=$(date -d '-1 minute' +%d/%b/%Y:%H:%M);awk -v date=$date '$0 ~ date {i++} END{print i}' js.log</span>
shell中的变量在awk程序中无法使用,因为在执行AWK时,是一个新的进程去处理的,因此就需要<span class="token operator">-</span>v来向awk程序中传参数了。
比如在shell程序中有一个变量a=15,在awk程序中直接使用变量a是不行的,而用awk <span class="token operator">-</span>v b=a,这样在AWK程序中就可以使用变量b也就相当于使用a。
9<span class="token punctuation">.</span>统计2017年9月5日 8:30<span class="token operator">-</span>9:00每个IP出现404状态码的数量
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># awk '$4>="[05/Sep/2017:08:30:00" && $4<="[05/Sep/2017:09:00:00" {if($9="404"){ip_code[$1" "$9]++}} END{for(i in ip_code){print i,ip_code[i]}}' js.log </span>
121<span class="token punctuation">.</span>31<span class="token punctuation">.</span>30<span class="token punctuation">.</span>169 404 2
183<span class="token punctuation">.</span>214<span class="token punctuation">.</span>128<span class="token punctuation">.</span>152 404 10
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>101 404 1
119<span class="token punctuation">.</span>147<span class="token punctuation">.</span>33<span class="token punctuation">.</span>19 404 1
58<span class="token punctuation">.</span>250<span class="token punctuation">.</span>143<span class="token punctuation">.</span>116 404 2
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>59 404 1
121<span class="token punctuation">.</span>29<span class="token punctuation">.</span>54<span class="token punctuation">.</span>60 404 1
10<span class="token punctuation">.</span>统计2017年9月5日 各种状态码数量
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{code[$9]++} END{for(i in code){print i,code[i]}}'</span>
301 1
304 821
200 625
404 290
405 1
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{code[$9]++} END{for(i in code){print i,code[i]}}'</span>
301 1
304 821
200 625
404 290
405 1
百分比
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># grep '05/Sep/2017' js.log | awk '{code[$9]++;total++} END{for(i in code){printf i" ";printf code[i]"\t";printf "%.2f",code[i]/total*100;print "%"}}'</span>
301 1 0<span class="token punctuation">.</span>06<span class="token operator">%</span>
304 821 47<span class="token punctuation">.</span>24<span class="token operator">%</span>
200 625 35<span class="token punctuation">.</span>96<span class="token operator">%</span>
404 290 16<span class="token punctuation">.</span>69<span class="token operator">%</span>
405 1 0<span class="token punctuation">.</span>06<span class="token operator">%</span>
</code></pre>
<h1>8.Nginx WEB模块</h1>
<h2>8.1随机主页</h2>
<pre><code class="prism language-powershell">微更新:
将主页设置成随机页面,是一种微调更新机制
random_index_module
启动随机主页:
1<span class="token punctuation">.</span>创建主页目录
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># mkdir /app</span>
2<span class="token punctuation">.</span>创建多个目录
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># touch /app/{blue.html,green.html,red.html,.yellow.html}</span>
在不同的页面书写不同的内容,例如
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /app/green.html</span>
<html>
<head>
<title>green color<<span class="token operator">/</span>title>
<<span class="token operator">/</span>head>
<body style=<span class="token string">"background-color:green"</span>>
<h1>green color<span class="token operator">!</span><<span class="token operator">/</span>h1>
<<span class="token operator">/</span>body>
<<span class="token operator">/</span>html>
3<span class="token punctuation">.</span>启动随机主页
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/default.conf</span>
server<span class="token punctuation">{
</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
<span class="token comment">#root /usr/share/nginx/html;</span>
<span class="token comment">#index index.html index.htm;</span>
root <span class="token operator">/</span>app<span class="token punctuation">;</span>
random_index on<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
完成该试验后,请注释掉该功能。避免影响其他实验。
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># systemctl restart nginx</span>
刷新主页,观察变化。
4<span class="token punctuation">.</span>注意隐藏文件不会被随机选取(即<span class="token punctuation">.</span>yellow<span class="token punctuation">.</span>html)
</code></pre>
<h2>8.2替换模块</h2>
<ul>
<li>模块</li>
</ul>
<pre><code class="prism language-powershell">统称:
sub_module
网页内容替换:
如果我们用模板生成网站的时候,因为疏漏或者别的原因造成代码不如意,但是此时因为文件数量巨大,不方便全部重新生成。
那么这个时候我们就可以用此模块来暂时实现纠错。另一方面,我们也可以利用这个实现服务器端文字过滤的效果。
启动替换:
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/default.conf</span>
启动nginx默认页面
server <span class="token punctuation">{
</span>
在server<span class="token punctuation">{
</span>下面插入
sub_filter nginx <span class="token string">'jslinux'</span><span class="token punctuation">;</span>
sub_filter_once on<span class="token punctuation">;</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
root <span class="token operator">/</span>usr<span class="token operator">/</span>share<span class="token operator">/</span>nginx<span class="token operator">/</span>html<span class="token punctuation">;</span>
index index<span class="token punctuation">.</span>html index<span class="token punctuation">.</span>htm<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
替换模块 将nginx替换成jslinux
单次替换 开启
重启服务,测试页面
1<span class="token punctuation">.</span>只替换了一处。
2<span class="token punctuation">.</span>将单次替换关闭,再次刷新页面,即可看见全文替换。
sub_filter_once off
</code></pre>
<h2>8.3文件读取</h2>
<pre><code class="prism language-powershell">模块统称:
ngx_http_core_module
语法:
Syntax: sendfile on <span class="token punctuation">|</span> off<span class="token punctuation">;</span>
Default: sendfile on<span class="token punctuation">;</span>
Context: http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location<span class="token punctuation">,</span> <span class="token keyword">if</span> in location
Syntax: tcp_nopush on <span class="token punctuation">|</span> off<span class="token punctuation">;</span>
Default: tcp_nopush off<span class="token punctuation">;</span>
Context: http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location
Syntax: tcp_nodelay on <span class="token punctuation">|</span> off<span class="token punctuation">;</span>
Default: tcp_nodelay on<span class="token punctuation">;</span>
Context: http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location
</code></pre>
<ul>
<li>原理介绍</li>
</ul>
<blockquote>
<ul>
<li>sendfile</li>
</ul>
<p>未使用sendfile() 的传统网络传输过程:</p>
<p>硬盘 >> kernel buffer >> user buffer>> kernel socket buffer >>协议栈</p>
<p><a href="http://img.e-com-net.com/image/info8/0819b8f4a9384e1b8d33682694b4ad24.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/0819b8f4a9384e1b8d33682694b4ad24.jpg" alt="Nginx基础入门篇_第21张图片" width="580" height="352" style="border:1px solid black;"></a></p>
<p>使用 sendfile() 来进行网络传输的过程:</p>
<p>硬盘 >> kernel buffer (快速拷贝到kernelsocket buffer) >>协议栈<br> sendfile() 不但能减少切换次数而且还能减少拷贝次数。</p>
<ul>
<li>tcp_nopush</li>
</ul>
<p>未使用tcp_nopush()网络资源浪费:</p>
<p>应用程序每产生一次操作就会发送一个包,而典型情况下一个包会拥有一个字节的数据以及40个字节长的包头,于是产生4000%的过载,很轻易地就能令网络发生拥塞。同时也浪费资源。</p>
<p>使用tcp_nopush()网络传输效率提升:</p>
<p>当包累计到一定大小后再发送。</p>
<ul>
<li>tcp_nodelay</li>
</ul>
<p>开启或关闭nginx使用TCP_NODELAY选项的功能。 这个选项仅在将连接转变为长连接的时候才被启用。<br> TCP_NODELAY是禁用Nagle算法,即数据包立即发送出去。<br> 由于Nagle和DelayedACK的原因,数据包的确认信息需要积攒到两个时才发送,长连接情况下,奇数包会造成延时40ms,所以tcp_nodelay会将ack立刻发出去。 如果不在长连接时,可以关闭此模块,因为ack会被立刻发出去。</p>
</blockquote>
<ul>
<li>启用模块</li>
</ul>
<pre><code class="prism language-powershell">location <span class="token operator">/</span>video<span class="token operator">/</span> <span class="token punctuation">{
</span>
sendfile on<span class="token punctuation">;</span>
tcp_nopush on<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
默认启动,无需验证
</code></pre>
<h2>8.4文件压缩</h2>
<ul>
<li>原理介绍</li>
</ul>
<blockquote>
<p>启动该模块,使文件传输前进行压缩,提升传输效率。</p>
</blockquote>
<ul>
<li>模块</li>
</ul>
<pre><code class="prism language-powershell">ngx_http_gzip_module
语法:
Syntax: gzip on <span class="token punctuation">|</span> off<span class="token punctuation">;</span>
Default: gzip off<span class="token punctuation">;</span>
Context: http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location<span class="token punctuation">,</span> <span class="token keyword">if</span> in location
Syntax: gzip_comp_level level<span class="token punctuation">;</span>
Default: gzip_comp_level 1<span class="token punctuation">;</span><span class="token punctuation">(</span>1~9<span class="token punctuation">)</span>
Context: http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location
Syntax: gzip_http_version 1<span class="token punctuation">.</span>0 <span class="token punctuation">|</span> 1<span class="token punctuation">.</span>1<span class="token punctuation">;</span>
Default: gzip_http_version 1<span class="token punctuation">.</span>1<span class="token punctuation">;</span>
Context: http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location
</code></pre>
<ul>
<li>启用模块</li>
</ul>
<blockquote>
<p>1.观察未压缩传输</p>
<p>拷贝图片至网站主目录<br> <a href="http://img.e-com-net.com/image/info8/bcafb815a0194946afaac6fdfbe58e45.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/bcafb815a0194946afaac6fdfbe58e45.jpg" alt="在这里插入图片描述" width="650" height="95"></a></p>
<p>拷贝tar包至网站主目录(压缩包的后缀使用.html)</p>
<p><a href="http://img.e-com-net.com/image/info8/f92f95c385454b5aa3d0527500d7a9d3.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f92f95c385454b5aa3d0527500d7a9d3.jpg" alt="Nginx基础入门篇_第22张图片" width="650" height="106" style="border:1px solid black;"></a></p>
<p>拷贝文本至网站主目录</p>
<p><a href="http://img.e-com-net.com/image/info8/dd052a6e1e5d4845a1916442332371e9.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/dd052a6e1e5d4845a1916442332371e9.jpg" alt="在这里插入图片描述" width="650" height="92"></a></p>
<p>通过浏览器下载文件并观察下载后大小。</p>
<p>2.启用压缩功能</p>
<pre><code class="prism language-powershell">http <span class="token punctuation">{
</span>
<span class="token comment"># 在http标签中启动该功能</span>
gzip on<span class="token punctuation">;</span>
gzip_http_version 1<span class="token punctuation">.</span>1<span class="token punctuation">;</span>
gzip_comp_level 2<span class="token punctuation">;</span>
gzip_types text<span class="token operator">/</span>plain application<span class="token operator">/</span>javascript application<span class="token operator">/</span>x<span class="token operator">-</span>javascript text<span class="token operator">/</span>css application<span class="token operator">/</span>xml text<span class="token operator">/</span>javascript application<span class="token operator">/</span>x<span class="token operator">-</span>httpd<span class="token operator">-</span>php image<span class="token operator">/</span>jpeg image<span class="token operator">/</span>gif image<span class="token operator">/</span>png<span class="token punctuation">;</span>
gzip_static on<span class="token punctuation">;</span>
gzip_static on<span class="token punctuation">;</span>
<span class="token comment"># nginx对于静态文件的处理模块</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># systemctl restart nginx</span>
</code></pre>
<p>3.观察压缩传输</p>
<blockquote>
<p>注意缓存<br> 压缩包和图片类对象本身已经自带压缩功能。所以压缩比例较小低。<br> 文本类对象在压缩试验中,压缩比例体现优越。<br> 再通过浏览器下载文件并观察下载后大小。</p>
</blockquote>
</blockquote>
<h2>8.5页面缓存</h2>
<ul>
<li>模块</li>
</ul>
<pre><code class="prism language-powershell">ngx_http_headers_module
expires起到控制页面缓存的作用,合理的配置expires可以减少很多服务器的请求要配置expires,可以在http段中或者server段中或者location段中加入。
Nginx<span class="token punctuation">(</span>expires 缓存减轻服务端压力<span class="token punctuation">)</span>,
</code></pre>
<ul>
<li>语法</li>
</ul>
<pre><code class="prism language-powershell">Syntax: expires <span class="token namespace">[modified]</span> time<span class="token punctuation">;</span>
expires epoch <span class="token punctuation">|</span> max <span class="token punctuation">|</span> off<span class="token punctuation">;</span>
Default: expires off<span class="token punctuation">;</span>
Context: http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location<span class="token punctuation">,</span> <span class="token keyword">if</span> in location
epoch:指定“Expires”的值为 1 January<span class="token punctuation">,</span>1970<span class="token punctuation">,</span>00:00:01 GMT
max:指定“Expires”的值为10年。
<span class="token operator">-</span>1:指定“Expires”的值为当前服务器时间<span class="token operator">-</span>1s,即永远过期。
off:不修改“Expires”和<span class="token string">"Cache-Control"</span>的值
</code></pre>
<ul>
<li>原理简介</li>
</ul>
<blockquote>
<p>无缓存,每次访问服务器,均是全文传输。<br> 开启缓存可以加速浏览网站。</p>
</blockquote>
<ul>
<li>启用缓存</li>
</ul>
<p>Ⅰ.观察浏览器缓存</p>
<blockquote>
<p>1.开启浏览器缓存,浏览页面。(默认)</p>
<p>第一次返回状态码200.页面对象全文传输<br> 第二次返回状态304.页面对象部分传输</p>
<p>2.禁用缓存,浏览页面。</p>
<p>返回码200.全文传输<br> 理解浏览器缓存作用</p>
<p>3.解析缓存原理</p>
<p><a href="http://img.e-com-net.com/image/info8/e8d5aa3bd59b47d9ab4cff3f1bc6300e.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/e8d5aa3bd59b47d9ab4cff3f1bc6300e.jpg" alt="Nginx基础入门篇_第23张图片" width="554" height="528" style="border:1px solid black;"></a></p>
</blockquote>
<p>Ⅱ.理解nginx服务器缓存</p>
<blockquote>
<p>4.开启服务器缓存模块</p>
</blockquote>
<pre><code class="prism language-powershell"><span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/nginx.conf</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
root <span class="token operator">/</span>usr<span class="token operator">/</span>share<span class="token operator">/</span>nginx<span class="token operator">/</span>html
index index<span class="token punctuation">.</span>html index<span class="token punctuation">.</span>htm<span class="token punctuation">;</span>
expires 24h<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
</code></pre>
<blockquote>
<p>5.再次浏览页面,观察响应头中出现的服务器回复的缓存时间</p>
<p><a href="http://img.e-com-net.com/image/info8/07573adf97c54aa19e34464c5665a4e3.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/07573adf97c54aa19e34464c5665a4e3.jpg" alt="Nginx基础入门篇_第24张图片" width="456" height="409" style="border:1px solid black;"></a></p>
<p>6.理解nginx服务器启动缓存时间,加速浏览。<br> 缺点是时效性降低。</p>
</blockquote>
<h2>8.6防盗链</h2>
<ul>
<li>模块</li>
</ul>
<pre><code class="prism language-powershell">ngx_http_referer_module
</code></pre>
<ul>
<li>语法</li>
</ul>
<pre><code class="prism language-powershell">Syntax: valid_referers none <span class="token punctuation">|</span> blocked <span class="token punctuation">|</span> server_names <span class="token punctuation">|</span> string <span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">;</span>
Default: —
Context: server<span class="token punctuation">,</span> location
</code></pre>
<ul>
<li>日志原理介绍</li>
</ul>
<pre><code class="prism language-powershell">log_format main <span class="token string">'$remote_addr - $remote_user [$time_local] "$request" '</span>
<span class="token string">'$status $body_bytes_sent "$http_referer" '</span>
<span class="token string">'"$http_user_agent" "$http_x_forwarded_for"'</span><span class="token punctuation">;</span>
</code></pre>
<blockquote>
<p>日志格式中的http_referer是记录,访问点引用的URL。也就是超链接的上一级地址。<br> 通过这段地址,可以发现一种网络行为——盗链。非法盗链会影响站点的正常访问。<br> 通过http_referer模块可以控制这一点。防止非法盗链现象。</p>
</blockquote>
<ul>
<li>启动防盗链(展现盗链现象,启动防盗链)</li>
</ul>
<pre><code class="prism language-powershell">1<span class="token punctuation">.</span>搭建一个a<span class="token punctuation">.</span>com网站
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/a.com.conf</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /a.com/index.html</span>
<img src=<span class="token string">'1.jpg'</span> <span class="token operator">/</span>>
注意要将1<span class="token punctuation">.</span>jpg图片拷贝至网站主目录。
分离a<span class="token punctuation">.</span>com日志
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/nginx.conf</span>
access_log <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>log<span class="token operator">/</span>nginx<span class="token operator">/</span>access<span class="token punctuation">.</span>log main<span class="token punctuation">;</span>
放到a<span class="token punctuation">.</span>com<span class="token punctuation">.</span>conf
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/a.com.conf</span>
access_log <span class="token operator">/</span><span class="token keyword">var</span><span class="token operator">/</span>log<span class="token operator">/</span>nginx<span class="token operator">/</span>a<span class="token punctuation">.</span>com<span class="token punctuation">.</span>access<span class="token punctuation">.</span>log main<span class="token punctuation">;</span>
重启nginx
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># systemctl restart nginx</span>
2<span class="token punctuation">.</span>搭建一个b<span class="token punctuation">.</span>com网站
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/b.com.conf</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /b.com/index.html</span>
<img src=<span class="token string">'http://a.com/1.jpg'</span> <span class="token operator">/</span>>
盗用链接,用A网站的域名或地址
注意b网站主目录中,根本没有图片。
分离日志,重启nginx
3<span class="token punctuation">.</span>访问两个网站页面。均能正常显示图片。
4<span class="token punctuation">.</span>注意b<span class="token punctuation">.</span>com网站的日志
日志正常
192<span class="token punctuation">.</span>168<span class="token punctuation">.</span>36<span class="token punctuation">.</span>154 <span class="token operator">-</span> <span class="token operator">-</span> <span class="token punctuation">[</span>20<span class="token operator">/</span>Sep<span class="token operator">/</span>2020:15:10:27 <span class="token operator">+</span>0800<span class="token punctuation">]</span> <span class="token string">"GET / HTTP/1.1"</span> 200 42 <span class="token string">"-"</span> <span class="token string">"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0"</span> <span class="token string">"-"</span>
5<span class="token punctuation">.</span>注意a<span class="token punctuation">.</span>com网站的日志
日志不正常,日志莫名其妙的产生,观察referer字段,发现被盗链。
192<span class="token punctuation">.</span>168<span class="token punctuation">.</span>36<span class="token punctuation">.</span>154 <span class="token operator">-</span> <span class="token operator">-</span> <span class="token punctuation">[</span>20<span class="token operator">/</span>Sep<span class="token operator">/</span>2020:15:10:27 <span class="token operator">+</span>0800<span class="token punctuation">]</span> <span class="token string">"GET /1.jpg HTTP/1.1"</span> 200 1635350 <span class="token string">"http://192.168.100.20/"</span> <span class="token string">"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0"</span>
6<span class="token punctuation">.</span>启动a<span class="token punctuation">.</span>com防盗链功能
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/a.com.conf</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
root <span class="token operator">/</span>a<span class="token punctuation">.</span>com<span class="token punctuation">;</span>
index index<span class="token punctuation">.</span>html index<span class="token punctuation">.</span>htm<span class="token punctuation">;</span>
valid_referers none blocked <span class="token operator">*</span><span class="token punctuation">.</span>a<span class="token punctuation">.</span>com<span class="token punctuation">;</span>
<span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token variable">$invalid_referer</span><span class="token punctuation">)</span> <span class="token punctuation">{
</span>
<span class="token keyword">return</span> 403<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># systemctl restart nginx</span>
7<span class="token punctuation">.</span>再次访问b<span class="token punctuation">.</span>com网站,盗链失败。
8<span class="token punctuation">.</span>如果希望某些网站能够使用(盗链)资源
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/a.com.conf</span>
测试
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
root <span class="token operator">/</span>a<span class="token punctuation">.</span>com<span class="token punctuation">;</span>
index index<span class="token punctuation">.</span>html index<span class="token punctuation">.</span>htm<span class="token punctuation">;</span>
valid_referers none blocked <span class="token operator">*</span><span class="token punctuation">.</span>a<span class="token punctuation">.</span>com a<span class="token punctuation">.</span>com server_name 192<span class="token punctuation">.</span>168<span class="token punctuation">.</span>36<span class="token punctuation">.</span><span class="token operator">*</span> b<span class="token punctuation">.</span>com<span class="token punctuation">;</span>
<span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token variable">$invalid_referer</span><span class="token punctuation">)</span> <span class="token punctuation">{
</span>
<span class="token keyword">return</span> 403<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
9<span class="token punctuation">.</span>再次盗链,合法盗链成功。
</code></pre>
<h2>8.7连接状态</h2>
<pre><code class="prism language-powershell">stub_status_module
展示用户和nginx链接数量信息
查询模块是否安装
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># nginx -V 2>&1 | grep stub_status</span>
启动状态模块
1<span class="token punctuation">.</span>访问默认站点的状态模块
http:<span class="token operator">/</span><span class="token operator">/</span>192<span class="token punctuation">.</span>168<span class="token punctuation">.</span>36<span class="token punctuation">.</span>154<span class="token operator">/</span>nginx_status
显示404页面,未启用
2<span class="token punctuation">.</span>配置装填模块
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/default.conf</span>
server<span class="token punctuation">{
</span>
location <span class="token operator">/</span>nginx_status<span class="token punctuation">{
</span>
stub_status<span class="token punctuation">;</span>
allow all<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
3<span class="token punctuation">.</span>重启服务再次访问
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># systemctl restart nginx</span>
4<span class="token punctuation">.</span>观察连接数和请求数
Active connections: 1
当前活动的连接数
server accepts handled requests
服务器接收处理的请求
17 17 24
17 总连接数connection(TCP)
17 成功的连接数connection(TCP) 失败连接=总连接<span class="token operator">-</span>成功连接
24 总共处理的请求数requests(HTTP)
connection 连接数,tcp连接
request http请求,GET<span class="token operator">/</span>POST<span class="token operator">/</span>DELETE<span class="token operator">/</span>UPLOAD
Reading: 0 Writing: 1 Waiting: 0
Reading: 0 读取客户端Header的信息数,请求头
Writing: 1 返回给客户端Header的信息数,响应头
Waiting: 0 等待的请求数,开启了keeplive
</code></pre>
<ul>
<li>关于链接的问题</li>
</ul>
<blockquote>
<p>Ⅰ.什么是链接</p>
<ul>
<li>OSI封装回顾</li>
</ul>
<p><a href="http://img.e-com-net.com/image/info8/c8c9aec2fb5d455a82d13f12ec09fca0.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/c8c9aec2fb5d455a82d13f12ec09fca0.jpg" alt="Nginx基础入门篇_第25张图片" width="650" height="336" style="border:1px solid black;"></a></p>
<ul>
<li>TCP封装结构</li>
</ul>
<p><a href="http://img.e-com-net.com/image/info8/422aacab35a147d5b5e003bf5867b17c.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/422aacab35a147d5b5e003bf5867b17c.jpg" alt="Nginx基础入门篇_第26张图片" width="650" height="321" style="border:1px solid black;"></a></p>
<ul>
<li>TCP三次握手</li>
</ul>
<p><a href="http://img.e-com-net.com/image/info8/abbf5edb6f17419b87b4d8da7bcf39d9.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/abbf5edb6f17419b87b4d8da7bcf39d9.jpg" alt="Nginx基础入门篇_第27张图片" width="500" height="385" style="border:1px solid black;"></a></p>
<p>1、第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c)。此时客户端处于 SYN_Send 状态。</p>
<p>2、第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s),同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。</p>
<p>3、第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 establised 状态。</p>
<p>4、服务器收到 ACK 报文之后,也处于 establised 状态,此时,双方以建立起了链接。</p>
<ul>
<li>TCP四次挥手/四次断开</li>
</ul>
<p><a href="http://img.e-com-net.com/image/info8/f52427d6853c4e71b88b74aedb67783b.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f52427d6853c4e71b88b74aedb67783b.jpg" alt="Nginx基础入门篇_第28张图片" width="636" height="394" style="border:1px solid black;"></a></p>
<p>1、第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态。</p>
<p>2、第二次握手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 + 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态。</p>
<p>3、第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。</p>
<p>4、第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 + 1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态。</p>
<p>5、服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。</p>
<ul>
<li>TCP机制</li>
</ul>
<p>1.四大计时器:</p>
<p>2.重传计时器(Retransmission)</p>
<p> 为了防止数据报丢失,当TCP发送一个报文时,就启动重传计时器,有2种情况:<br> 若在计时器超时之前收到了特定报文的确认,则撤消这个计时器;<br> 特定数据报在计时器超时前没有收到确认,则重传该数据报,并把计时器复位;</p>
<p>3.持久计时器(Persistence)</p>
<p> 在流量控制中提到死锁现象。要解开死锁,TCP为每一个连接使用一个持久计时器。当发送端TCP接收到rwnd=0的确认时,就启动持久计时器,当计时器截止时间到时,发送端TCP需要发送一个特殊的报文,叫做探测报文。该报文只有1字节,有序号,但无需确认。探测报文提醒接收端TCP:确认已丢失,必须重传。持久计时器截止时间设置为重传时间的数值,但是,如果没有收到从接收端回来的响应,则需要发送另外一个探测报文,并将持久计时器的值加倍和复位。如果结果和上面一样,发送端继续发送探测报文,直到其截止时间增大到阈值(通常为60s)为止。在这以后,发送端每60s发送一个探测报文,直到窗口重新打开;</p>
<p>4.保活计时器(keep-alive)</p>
<p> 在某些实现中要使用keeplive timer来防止两个TCP之间出现长时间的空闲,比如客户端打开了服务器端的连接,传送了一些数据,然后就保持静默了,也许该客户端除了故障,在这种情况下,这个连接就永远处于打开状态。保活计时器的解决方法为,当服务器端收到客户端的信息时,就把计时器复位,超时通常设置2小时。若服务器2小时还没有收到客户的信息,就发送探测报文。若发送10个同样的报文(每个相隔75s)还没有收到响应,就认为客户端出了故障,终止这个连接。</p>
<p>5.时间等待(time-wait)</p>
<p> 如果最后一个ACK报文丢失了,那么服务器TCP(它为最后的FIN设置了计时器)以为它的FIN丢失了,因而重传。</p>
<ul>
<li>TCP流控/拥塞管理</li>
</ul>
<p>1.原理</p>
<p> 接收端处理数据的速度是有限的,如果发送方的速度太快,就会把缓冲区u打满。这个时候如果继续发送数据,就会导致丢包等一系列连锁反应。</p>
<p> 所以TCP支持根据接收端能力来决定发送端的发送速度。这个机制叫做流控制。</p>
<p>2.窗口大小</p>
<p> (接收端向发送端主机通知自己可以接受数据的大小,这个大小限制就叫做窗口大小)</p>
<p>Ⅱ.什么是请求</p>
<p> 一次HTTP查询</p>
<p>Ⅲ.keepalived</p>
<p> 长连接设置:</p>
<p> Httpd守护进程,一般都提供了keep-alive timeout时间设置参数。比如nginx的keepalive_timeout,和Apache的KeepAliveTimeout。这个keepalive_timout时间值意味着:一个http产生的tcp连接在传送完最后一个响应后,还需要hold住 keepalive_timeout秒后,才开始关闭这个连接。当httpd守护进程发送完一个响应后,理应马上主动关闭相应的tcp连接,设置 keepalive_timeout后,httpd守护进程会想说:”再等等吧,看看浏览器还有没有请求过来”,这一等,便是 keepalive_timeout时间。如果守护进程在这个等待的时间里,一直没有收到浏览发过来http请求,则关闭这个http连接。</p>
<p>Ⅳ.关闭长连接</p>
<p><a href="http://img.e-com-net.com/image/info8/090cb045f0c84ec7a35c293361eff206.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/090cb045f0c84ec7a35c293361eff206.png" alt="在这里插入图片描述" width="332" height="100"></a></p>
<p>Ⅴ.再次刷新状态观察</p>
</blockquote>
<h1>9.Nginx 访问限制</h1>
<pre><code class="prism language-powershell">ngx_http_limit_req_module
启动请求频率限制
1<span class="token punctuation">.</span>测试未限制情况下的访问(压测工具)
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># yum install -y httpd-tools</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># ab -n 100 -c 10 http://127.0.0.1/</span>
2<span class="token punctuation">.</span>启动限制
定义:
limit_req_zone <span class="token variable">$binary_remote_addr</span> zone=req_zone:10m rate=1r<span class="token operator">/</span>s<span class="token punctuation">;</span>
限制请求 二进制地址 限制策略的名称 占用10M空间 允许每秒1次请求
引用:
limit_req zone=req_zone<span class="token punctuation">;</span>
引用 限制策略的名称
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/nginx.conf</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/default.conf</span>
<span class="token comment">#主配置</span>
http <span class="token punctuation">{
</span>
limit_req_zone <span class="token variable">$binary_remote_addr</span> zone=req_zone:10m rate=1r<span class="token operator">/</span>s<span class="token punctuation">;</span>
<span class="token comment">#定义</span>
<span class="token comment">#子配置</span>
server <span class="token punctuation">{
</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
root <span class="token operator">/</span>usr<span class="token operator">/</span>share<span class="token operator">/</span>nginx<span class="token operator">/</span>html<span class="token punctuation">;</span>
index index<span class="token punctuation">.</span>html index<span class="token punctuation">.</span>htm<span class="token punctuation">;</span>
limit_req zone=req_zone<span class="token punctuation">;</span>
<span class="token comment">#引用限制</span>
<span class="token comment">#limit_req zone=req_zone burst=5;</span>
<span class="token comment">#引用限制,但是令牌桶有5个。有延迟。速度慢</span>
<span class="token comment">#limit_req zone=req_zone burst=5 nodelay;</span>
<span class="token comment">#引用限制,但是令牌桶有5个。无延迟。速度快</span>
<span class="token comment">#burst=5 表示最大延迟请求数量不大于5。如果太过多的请求被限制延迟是不需要的,这时需要使用nodelay参数,服务器会立刻返回503状态码。 </span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
3<span class="token punctuation">.</span>重启服务,并测试
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># yum install -y httpd-tools</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># ab -n 100 -c 10 http://jslinux.com/</span>
This is ApacheBench<span class="token punctuation">,</span> Version 2<span class="token punctuation">.</span>3 <<span class="token variable">$Revision</span>: 1430300 $>
Benchmarking localhost <span class="token punctuation">(</span>be patient<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>done
Server Software: nginx<span class="token operator">/</span>1<span class="token punctuation">.</span>12<span class="token punctuation">.</span>1
Server Hostname: jslinx<span class="token punctuation">.</span>com
Server Port: 80
Document Path: <span class="token operator">/</span>
Document Length: 671 bytes
Concurrency Level: 10
Time taken <span class="token keyword">for</span> tests: 0<span class="token punctuation">.</span>006 seconds
Complete requests: 100
Failed requests: 99 失败的请求
<span class="token punctuation">(</span>Connect: 0<span class="token punctuation">,</span> Receive: 0<span class="token punctuation">,</span> Length: 99<span class="token punctuation">,</span> Exceptions: 0<span class="token punctuation">)</span>
<span class="token function">Write</span> errors: 0
Non<span class="token operator">-</span>2xx responses: 99 有问题的相应。
Total transferred: 73273 bytes
HTML transferred: 53834 bytes
Requests per second: 16131<span class="token punctuation">.</span>63 <span class="token punctuation">[</span><span class="token comment">#/sec] (mean)</span>
Time per request: 0<span class="token punctuation">.</span>620 <span class="token namespace">[ms]</span> <span class="token punctuation">(</span>mean<span class="token punctuation">)</span>
Time per request: 0<span class="token punctuation">.</span>062 <span class="token namespace">[ms]</span> <span class="token punctuation">(</span>mean<span class="token punctuation">,</span> across all concurrent requests<span class="token punctuation">)</span>
Transfer rate: 11543<span class="token punctuation">.</span>10 <span class="token namespace">[Kbytes/sec]</span> received
4<span class="token punctuation">.</span>观察错误日志
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># tail -f /var/log/nginx/error.log</span>
2020<span class="token operator">/</span>09<span class="token operator">/</span>20 20:05:08 <span class="token namespace">[error]</span> 23287<span class="token comment">#23287: *720 limiting requests, excess: 5.109 by zone "req_zone", client: 27.216.240.201, server: localhost, request: "GET / HTTP/1.0", host: "jslinux.com"</span>
由于限制请求导致。limiting requests
</code></pre>
<pre><code class="prism language-powershell">ngx_http_limit_conn_module
通过IP地址,限制链接(TCP)。但是实验环境无法测试<span class="token punctuation">.</span>
1<span class="token punctuation">.</span>启动连接频率限制
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/nginx.conf</span>
http <span class="token punctuation">{
</span>
limit_conn_zone <span class="token variable">$binary_remote_addr</span> zone=conn_zone:10m<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
server <span class="token punctuation">{
</span>
location <span class="token operator">/</span> <span class="token punctuation">{
</span>
<span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>
limit_conn conn_zone 1<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
单个IP,同时只允许有一个tcp连接
</code></pre>
<blockquote>
<p>limit_conn_zone:全局定义限制对象(IP),存储区限制空间(10M)字节 .</p>
<p>limit_conn:该指令指定每个给定键值的最大同时连接数,当超过这个数字时返回503(Service )错误。如(同一IP同一时间只允许有2个连接):</p>
<p>客户端的IP地址作为键。注意,这里使用的是 binary_remote_addr 变量,而不是 remote_addr 变量。<br> remote_addr变量的长度为7字节到15字节,而存储状态在32位平台中占用32字节或64字节,在64位平台中占用64字节。<br> binary_remote_addr变量的长度是固定的4字节,存储状态在32位平台中占用32字节或64字节,在64位平台中占用64字节。<br> 1M共享空间可以保存3.2万个32位的状态,1.6万个64位的状态。<br> 如果共享内存空间被耗尽,服务器将会对后续所有的请求返回 503 (Service Temporarily Unavailable) 错误。</p>
<p>limit_conn_zone $binary_remote_addr zone=conn_zone:10m模块开启对单个ip、单个会话同时存在的连接数的限制。这里定义一个记录区conn_zone,conn_zone的总容量是10m,该记录区针对于变量 $binary_remote_add生效,这里是针对单个IP生效。该模块只是一个定义,配置在http配置段,需要配合limit_conn指令使用才生效, limit_conn conn_zone 1表示该location段使用conn_zone定义的 limit_conn_zone ,对单个IP限制同时存在一个连接。</p>
</blockquote>
<pre><code class="prism language-powershell">2<span class="token punctuation">.</span>测试
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># yum install -y httpd-tools</span>
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># ab -n 100 -c 10 http://jslinux/</span>
This is ApacheBench<span class="token punctuation">,</span> Version 2<span class="token punctuation">.</span>3 <<span class="token variable">$Revision</span>: 1430300 $>
Benchmarking localhost <span class="token punctuation">(</span>be patient<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>done
Server Software: nginx<span class="token operator">/</span>1<span class="token punctuation">.</span>12<span class="token punctuation">.</span>1
Server Hostname: jslinux<span class="token punctuation">.</span>com
Server Port: 80
Document Path: <span class="token operator">/</span>
Document Length: 671 bytes 文档长度
Concurrency Level: 10 当前并发数
Time taken <span class="token keyword">for</span> tests: 0<span class="token punctuation">.</span>006 seconds 消耗总时间
Complete requests: 100 完成请求数
Failed requests: 0 失败请求数
<span class="token function">Write</span> errors: 0
Total transferred: 90400 bytes 总的传输大小
HTML transferred: 67100 bytes http传输大小
Requests per second: 15873<span class="token punctuation">.</span>02 <span class="token punctuation">[</span><span class="token comment">#/sec] (mean) 每秒钟处理多少个请求。</span>
3<span class="token punctuation">.</span>效果不明显
4<span class="token punctuation">.</span>了解不同的网站压力测试工具
</code></pre>
<h1>10.Nginx 访问控制</h1>
<h2>10.1基于主机(IP)</h2>
<pre><code class="prism language-powershell">module:
ngx_http_access_module
Directives:
allow 允许某些主机
deny 拒绝某些主机
Syntax:
allow address <span class="token punctuation">|</span> CIDR <span class="token punctuation">|</span> unix: <span class="token punctuation">|</span> all<span class="token punctuation">;</span>
Context:
http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location<span class="token punctuation">,</span> limit_except
启动控制:
1<span class="token punctuation">.</span>限制主机访问
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/default.conf</span>
server <span class="token punctuation">{
</span>
allow 10<span class="token punctuation">.</span>18<span class="token punctuation">.</span>45<span class="token punctuation">.</span>65<span class="token punctuation">;</span> <span class="token comment">#真机ip</span>
allow 10<span class="token punctuation">.</span>18<span class="token punctuation">.</span>45<span class="token punctuation">.</span>181<span class="token punctuation">;</span>
deny all<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
2<span class="token punctuation">.</span>测试
服务器无法访问
</code></pre>
<h2>10.2基于用户(username&password)</h2>
<pre><code class="prism language-powershell">module:
ngx_http_auth_basic_module
Syntax:
方法1:Syntax: auth_basic string <span class="token punctuation">|</span> off<span class="token punctuation">;</span>
方法2:Syntax: auth_basic_user_file file<span class="token punctuation">;</span>
Context:
http<span class="token punctuation">,</span> server<span class="token punctuation">,</span> location<span class="token punctuation">,</span> limit_except
启用控制:
1<span class="token punctuation">.</span>建立认证文件
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># yum install -y httpd-tools</span>
生成秘钥的工具是由apache提供
<span class="token namespace">[root@localhost ~]</span><span class="token comment">#htpasswd -cm /etc/nginx/conf.d/passwd user1</span>
会话密码
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># htpasswd -m /etc/nginx/conf.d/passwd user2</span>
会话密码
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># cat /etc/nginx/conf.d/passwd</span>
观察口令文件是否生成。已生成
user1:<span class="token variable">$apr1</span><span class="token variable">$UE</span><span class="token operator">/</span>tLtDM<span class="token variable">$nVm686kAMYb</span><span class="token operator">/</span>ArqQDUi8U<span class="token operator">/</span>
user2:<span class="token variable">$apr1</span><span class="token variable">$bmn0E</span><span class="token operator">/</span>gK<span class="token variable">$enkXKb2V5uFvUy9wdIHlP</span><span class="token punctuation">.</span>
2<span class="token punctuation">.</span>启动认证
<span class="token namespace">[root@localhost ~]</span><span class="token comment"># vim /etc/nginx/conf.d/default.conf</span>
server <span class="token punctuation">{
</span>
auth_basic <span class="token string">"nginx access test!"</span><span class="token punctuation">;</span>
<span class="token comment">#提示消息</span>
auth_basic_user_file <span class="token operator">/</span>etc<span class="token operator">/</span>nginx<span class="token operator">/</span>conf<span class="token punctuation">.</span>d<span class="token operator">/</span>passwd<span class="token punctuation">;</span>
<span class="token comment">#引用认证文件</span>
<span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>
<span class="token punctuation">}</span>
3<span class="token punctuation">.</span>重启并验证
</code></pre>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1349258277233438720"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(nginx,linux,服务器,运维)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1943211667491975168.htm"
title="从实践到自动化:现代运维管理的转型与挑战" target="_blank">从实践到自动化:现代运维管理的转型与挑战</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>从实践到自动化:现代运维管理的转型与挑战在信息化快速发展的今天,企业IT系统的稳定性、可用性和安全性已成为衡量公司竞争力的重要因素之一。运维(IT运维)管理作为确保企业IT系统健康、稳定运行的关键职能,一直是企业技术团队关注的重点。然而,随着业务的复杂化、用户需求的变化以及技术的不断创新,传统的运维方式已逐渐无法满足企业对于高效、高可用、高安全的需求。如何提升运维效率、减少人为错误、提高运维系统的</div>
</li>
<li><a href="/article/1943209150150406144.htm"
title="RK35xx cpu无法调频的可能原因" target="_blank">RK35xx cpu无法调频的可能原因</a>
<span class="text-muted"></span>
<div>RK35xxcpu无法调频的可能原因1、开发环境2、问题描述3、问题解析3.1收集log信息3.2分析问题4、验证5、结论1、开发环境芯片型号:rk3568kernel版本:linux4.192、问题描述用户想动态调控CPU的频率,正常来说,在系统目录/sys/devices/system/cpu/cpu0/cpufreq/下是可以进行动态调频的;不正常的情况下就是没有/sys/devices/s</div>
</li>
<li><a href="/article/1943208015704420352.htm"
title="Ubuntu 与 Windows 实现文件夹共享" target="_blank">Ubuntu 与 Windows 实现文件夹共享</a>
<span class="text-muted">懒羊羊大王呀</span>
<a class="tag" taget="_blank" href="/search/Linux/1.htm">Linux</a><a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a><a class="tag" taget="_blank" href="/search/Linux/1.htm">Linux</a><a class="tag" taget="_blank" href="/search/Samba/1.htm">Samba</a><a class="tag" taget="_blank" href="/search/%E6%96%87%E4%BB%B6%E5%A4%B9%E5%85%B1%E4%BA%AB/1.htm">文件夹共享</a>
<div>Ubuntu20.04与Windows实现文件夹共享Linux中Samba的下载与配置sudoupdateapt#更新工具包sudoaptinstallsamba#下载Sambasudocp/etc/samba/smb.conf/etc/samba/smb.conf.bak#尽量备份一下sudovim/etc/samba/smb.conf#修改配置文件#添加以下内容,其中[shared]#共享文件</div>
</li>
<li><a href="/article/1943195659540688896.htm"
title="全栈运维的“诅咒”与“荣光”:为什么“万金油”工程师是项目成功的隐藏MVP?" target="_blank">全栈运维的“诅咒”与“荣光”:为什么“万金油”工程师是项目成功的隐藏MVP?</a>
<span class="text-muted">云原生水神</span>
<a class="tag" taget="_blank" href="/search/%E8%81%8C%E4%B8%9A%E5%8F%91%E5%B1%95/1.htm">职业发展</a><a class="tag" taget="_blank" href="/search/%E7%B3%BB%E7%BB%9F%E8%BF%90%E7%BB%B4/1.htm">系统运维</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>大家好,今天,我们来聊一个特殊且至关重要的群体:运维工程师。特别是那些在项目制中,以一己之力扛起一个或多个产品生死的“全能战士”。你是否就是其中一员?你的技能树上点亮了:操作系统、网络协议、mysql与Redis中间件、Docker与K8s容器化、Ansible与Terraform自动化、Go/Python工具开发、Prometheus监控体系、opentelemetry可视化,甚至要负责信息安全</div>
</li>
<li><a href="/article/1943195028985802752.htm"
title="Nginx中如何配置WebSocket代理?" target="_blank">Nginx中如何配置WebSocket代理?</a>
<span class="text-muted">m0_74824025</span>
<a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0%E8%B7%AF%E7%BA%BF/1.htm">学习路线</a><a class="tag" taget="_blank" href="/search/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4/1.htm">阿里巴巴</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/websocket/1.htm">websocket</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>Nginx可以配置为WebSocket代理,将WebSocket连接从客户端转发到后端服务器。以下是如何在Nginx中配置WebSocket代理的详细步骤和示例配置。1.安装Nginx确保你已经安装了Nginx。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallnginx2.配置WebSocket代理编辑Nginx配置文件,通常位于/et</div>
</li>
<li><a href="/article/1943192003466555392.htm"
title="Nginx代理websocket连接" target="_blank">Nginx代理websocket连接</a>
<span class="text-muted">为什么要做囚徒</span>
<a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/websocket/1.htm">websocket</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>文章目录Nginx代理websocket连接1.引言2.为什么需要Nginx代理WebSocket3.Nginx代理WebSocket的实现步骤步骤1:确保Nginx支持WebSocket步骤2:修改Nginx配置文件步骤3:重启Nginx服务步骤4:验证配置Nginx代理websocket连接1.引言WebSocket是一种在单个TCP连接上进行全双工通讯的协议,它在Web应用程序中提供了实时通</div>
</li>
<li><a href="/article/1943188348906565632.htm"
title="达梦数据库linux环境实时主备搭建过程" target="_blank">达梦数据库linux环境实时主备搭建过程</a>
<span class="text-muted">张晓杰^.^</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a>
<div>一.数据准备:1.安装单机1.1创建用户和组groupadd-g12349dinstalluseradd-u12345-gdinstall-m-d/home/dmdba-s/bin/bashdmdbapasswddmdba1.2创建文件dmsoft:存放DMInstall.bin和key/home/dmdba/dmdbms:存放数据库的安装目录/data:实例目录/data/dmarch:存放归档</div>
</li>
<li><a href="/article/1943186457556480000.htm"
title="[达梦数据库]达梦单节点安装" target="_blank">[达梦数据库]达梦单节点安装</a>
<span class="text-muted"></span>
<div>1环境配置1.1查看软硬件信息查看cpu信息:[root@localhost~]#lscpu[root@localhost~]#cat/proc/cpuinfo注意:特别是国产cpu,龙芯、飞腾查看内存信息:[root@localhost~]#free-m注意:数据库内存要至少1G,linuxswap分区一般是物理内存的1.5倍查看硬盘、分区信息[root@localhost~]#fdisk-l[</div>
</li>
<li><a href="/article/1943186205483003904.htm"
title="Linux 系统定时任务" target="_blank">Linux 系统定时任务</a>
<span class="text-muted">平凡的梦</span>
<a class="tag" taget="_blank" href="/search/Linux/1.htm">Linux</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>在Linux中,定时任务通常通过cron服务来管理。cron是一个基于时间的任务调度程序,允许用户在特定的时间间隔执行命令或脚本。以下是关于Linux定时任务的一些基本信息和操作指南:cron基础cron表(crontab)crontab文件是用来定义定时任务的配置文件。每个用户(包括系统用户)都可以有自己的crontab文件。crontab语法每个crontab文件包含若干行,每行代表一个定时任</div>
</li>
<li><a href="/article/1943185575397879808.htm"
title="Linux 定时任务" target="_blank">Linux 定时任务</a>
<span class="text-muted"></span>
<div>实现linux定时任务有:cron、anacron、at等,这里主要介绍cron服务。名词解释:cron是服务名称,crond是后台进程,crontab则是定制好的计划任务表。软件包安装:要使用cron服务,先要安装vixie-cron软件包和crontabs软件包,两个软件包作用如下:vixie-cron软件包是cron的主程序。crontabs软件包是用来安装、卸装、或列举用来驱动cron守护</div>
</li>
<li><a href="/article/1943184315047276544.htm"
title="linux 定时任务" target="_blank">linux 定时任务</a>
<span class="text-muted">小小小欣</span>
<div>crontab-e0*/1***/usr/bin/curlhttp://manage.baicmotorsales.com/Lists/clueData每一小时访问一次这个方法servicecrondrestart重启任务crontab-l查看定时任务tail-f/var/log/cron查看任务日志</div>
</li>
<li><a href="/article/1943182675078606848.htm"
title="如何解决小程序发布之后不能访问任何请求的问题?" target="_blank">如何解决小程序发布之后不能访问任何请求的问题?</a>
<span class="text-muted">嘉琪001</span>
<a class="tag" taget="_blank" href="/search/%E5%B0%8F%E7%A8%8B%E5%BA%8F/1.htm">小程序</a><a class="tag" taget="_blank" href="/search/apache/1.htm">apache</a><a class="tag" taget="_blank" href="/search/php/1.htm">php</a>
<div>(1)域名白名单设置不正确:小程序需要在微信公众平台后台请求域名添加到request合法域名白名单中,否则无法发送请求,确保所有域名添加到白名单中服务器SSL/HTTPS配置问题:小程序要求必须使用HTTPS协议进行网络请求,如果服务器没有配置好SSL证书,就无法访问,跨域问题:在服务器配置好CORS的跨域策略接口权限限制:如果请求是像某个特定的接口发送,确保你在小程序后台设置了相应接口权限有些接</div>
</li>
<li><a href="/article/1943182547538210816.htm"
title="第5章 Linux用户及权限管理" target="_blank">第5章 Linux用户及权限管理</a>
<span class="text-muted">lihuhelihu</span>
<a class="tag" taget="_blank" href="/search/Linux%E8%BF%90%E7%BB%B4%E5%AD%A6%E4%B9%A0/1.htm">Linux运维学习</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/unix/1.htm">unix</a><a class="tag" taget="_blank" href="/search/centos/1.htm">centos</a><a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4%E5%BC%80%E5%8F%91/1.htm">运维开发</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a>
<div>Linux是一个多用户的操作系统,引入用户,可以更加方便管理Linux服务器,系统默认需要以一个用户的身份登入,而且在系统上启动进程也需要以一个用户身份去运行,用户可以限制某些进程对特定资源的权限控制。本章介绍Linux系统如何管理创建、删除、修改用户角色、用户权限配置、组权限配置及特殊权限深入剖析。5.1Linux用户及组Linux操作系统对多用户的管理,是非常繁琐的,所以用组的概念来管理用户就</div>
</li>
<li><a href="/article/1943178515046264832.htm"
title="Selenium使用指南" target="_blank">Selenium使用指南</a>
<span class="text-muted"></span>
<div>点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快Selenium是网页应用中最流行的自动化测试工具,可以用来做自动化测试或者浏览器爬虫等。官网地址为:相对于另外一款web自动化测试工具QTP来说有如下优点:免费开源轻量级,不同语言只需要一个体积很小的依赖包支持多种系统,包括Windows,Mac,Linux支持多种浏览器,包括Chrome,FireFox,IE,safari,opera</div>
</li>
<li><a href="/article/1943175617759473664.htm"
title="【Python进阶】Python网络协议与套接字编程:构建客户端和服务器" target="_blank">【Python进阶】Python网络协议与套接字编程:构建客户端和服务器</a>
<span class="text-muted"></span>
<div>1、网络通信基础与网络协议1.1网络通信模型概述网络通信是信息时代基石,它如同现实世界中的邮递系统,将数据从一处传递到另一处。其中,OSI七层模型与TCP/IP四层或五层模型是理解和构建网络通信的基础。1.1.1OSI七层模型与TCP/IP四层/五层模型OSI(开放系统互连)参考模型提出了七层结构,从物理层到应用层,每一层都有其特定的功能和职责,例如物理层关注的是信号如何在介质上传输,而应用层则处</div>
</li>
<li><a href="/article/1943173605189808128.htm"
title="使用ENO将您的JSON对象生成HTML显示" target="_blank">使用ENO将您的JSON对象生成HTML显示</a>
<span class="text-muted">土族程序员</span>
<a class="tag" taget="_blank" href="/search/json/1.htm">json</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/eno/1.htm">eno</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>ENO是简单易用,性能卓越,自由灵活开源的WEB前端组件;实现JSON与HTML互操作的JavaScript函数库。没有任何其它依赖,足够轻量。WEBPackNPM工程安装。npminstall@joyzl/eno然后在JS中引用import"@joyzl/eno";将JS实体对象填充到表单假设有一个如下的HTML表单TYPE1TYPE2通过以下代码将实体对象,设置到表单中,实体对象可以从服务器请</div>
</li>
<li><a href="/article/1943166418824523776.htm"
title="初识.git文件泄露" target="_blank">初识.git文件泄露</a>
<span class="text-muted">wyjcxyyy</span>
<a class="tag" taget="_blank" href="/search/git/1.htm">git</a>
<div>.git文件泄露当在一个空目录执行gitinit时,Git会创建一个.git目录。这个目录包含所有的Git存储和操作的对象。如果想备份或复制一个版本库,只需把这个目录拷贝至另一处就可以了这是一种常见的安全漏洞,指的是网站的.git目录被意外暴露在公网上,导致攻击者可以通过访问.git目录获取网站的源代码、版本历史、配置文件等敏感信息。这种漏洞通常是由于服务器配置不当或开发人员的疏忽导致的。如何检测</div>
</li>
<li><a href="/article/1943162636753498112.htm"
title="Python 网络爬虫的基本流程及 robots 协议详解" target="_blank">Python 网络爬虫的基本流程及 robots 协议详解</a>
<span class="text-muted">女码农的重启</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/1.htm">网络爬虫</a><a class="tag" taget="_blank" href="/search/JAVA/1.htm">JAVA</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>数据驱动的时代,网络爬虫作为高效获取互联网信息的工具,其规范化开发离不开对基本流程的掌握和对robots协议的遵守。本文将系统梳理Python网络爬虫的核心流程,并深入解读robots协议的重要性及实践规范。一、Python网络爬虫的基本流程Python网络爬虫的工作过程可分为四个核心阶段,每个阶段环环相扣,共同构成数据采集的完整链路。1.1发起网络请求这是爬虫与目标服务器交互的第一步,通过发送H</div>
</li>
<li><a href="/article/1943162508252606464.htm"
title="【Linux | 网络】socket编程 - 使用UDP实现服务端向客户端提供简单的服务" target="_blank">【Linux | 网络】socket编程 - 使用UDP实现服务端向客户端提供简单的服务</a>
<span class="text-muted">是阿建吖!</span>
<a class="tag" taget="_blank" href="/search/%E3%80%90%E7%BD%91%E7%BB%9C%E3%80%91/1.htm">【网络】</a><a class="tag" taget="_blank" href="/search/%E3%80%90Linux%E3%80%91/1.htm">【Linux】</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/udp/1.htm">udp</a>
<div>目录一、UdpServerSever(客户端发送信息,服务端直接返回信息)1.1Comm.hpp(公共数据)1.2Log.hpp(日志)1.3InetAddr.hpp(管理sockaddr_in相关信息)1.4NoCopy.hpp(防拷贝)1.5UdpServer.hpp(服务端封装)1.6Main.cpp(服务端)1.7UdpClient.cpp(客户端)二、UdpServerExecute(客</div>
</li>
<li><a href="/article/1943162381018394624.htm"
title="2025 Next.js项目提前编译并在服务器" target="_blank">2025 Next.js项目提前编译并在服务器</a>
<span class="text-muted">风吹落叶花飘荡</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>要让一个Next.js项目提前编译并在服务器上运行,可以按照以下步骤操作:1.本地构建项目首先在开发环境中完成构建:#安装依赖pnpminstall#生产环境构建(生成优化版本)npmrunbuild这会生成:.next/目录(包含编译后的应用)public/目录(静态资源)node_modules/(生产依赖)2.准备部署文件需要上传到服务器的文件:.next/public/package.js</div>
</li>
<li><a href="/article/1943160993592963072.htm"
title="linux 安装docker并部署Dify" target="_blank">linux 安装docker并部署Dify</a>
<span class="text-muted">Samale、随风</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>环境:腾讯云Centos9Stream1.安装dockeryuminstalldocker#yuminstalldocker失败Error:Errordownloadingpackages:netavark-2:1.15.1-1.el9.x86_64:Cannotdownload,allmirrorswerealreadytriedwithoutsuccess#UpdateandCleanYumC</div>
</li>
<li><a href="/article/1943160867201806336.htm"
title="异物检测的计算机视觉算法技术路线" target="_blank">异物检测的计算机视觉算法技术路线</a>
<span class="text-muted">思绪漂移</span>
<a class="tag" taget="_blank" href="/search/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89/1.htm">计算机视觉</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>异物检测的计算机视觉算法技术路线在现代智能监测系统中,异物检测有着其必要性和运维重要性,通过计算机视觉算法,可以实时识别各种异常物体,为设备安全运行提供有力保障。本文将介绍异物检测的主要技术路线。一、分类识别适应场景分类识别技术主要适用于已知目标类别的异物检测场景。在运维环境中,这类场景包括:固定区域内的障碍物监测(如轨道区域的石块、工具、动物等)关键部件的异物附着检测(如固定装置上的杂物)安全通</div>
</li>
<li><a href="/article/1943160363382009856.htm"
title="基于Clangd索引Linux内核源代码,提供跳转和补全" target="_blank">基于Clangd索引Linux内核源代码,提供跳转和补全</a>
<span class="text-muted">yann_qu</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E5%86%85%E6%A0%B8/1.htm">内核</a><a class="tag" taget="_blank" href="/search/LSP/1.htm">LSP</a><a class="tag" taget="_blank" href="/search/VSCode/1.htm">VSCode</a><a class="tag" taget="_blank" href="/search/Neovim/1.htm">Neovim</a><a class="tag" taget="_blank" href="/search/Vim/1.htm">Vim</a>
<div>基于Clangd索引Linux内核源代码,提供跳转和补全适用于Neovim、Vim、VSCode等支持LSP的编辑器。1操作示例1.1操作环境操作系统:Ubuntu20.04inwsl2编辑器:VSCodeLSP:Clangd内核版本:longterm5.15.1451.2准备工作由于gcc和clang并非完全兼容,使用gcc编译后生成的compile_commands.json中可能包含clan</div>
</li>
<li><a href="/article/1943159984908988416.htm"
title="构建你的AI应用开发平台:如何在Ubuntu上使用Docker部署Dify" target="_blank">构建你的AI应用开发平台:如何在Ubuntu上使用Docker部署Dify</a>
<span class="text-muted">kaixin_啊啊</span>
<a class="tag" taget="_blank" href="/search/%E5%95%86%E4%B8%9A%E5%90%88%E4%BD%9C/1.htm">商业合作</a><a class="tag" taget="_blank" href="/search/cpolar/1.htm">cpolar</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a><a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a>
<div>文章目录前言1.Docker部署Dify2.本地访问Dify3.Ubuntu安装Cpolar4.配置公网地址5.远程访问6.固定Cpolar公网地址7.固定地址访问前言本文主要介绍如何在LinuxUbuntu系统使用Docker快速部署大语言模型应用开发平台Dify,并结合cpolar内网穿透工具实现公网环境远程访问本地Dify服务!Dify是一款开源的大语言模型(LLM)应用开发平台。它融合了后</div>
</li>
<li><a href="/article/1943158473588011008.htm"
title="基于Live555实现简单RTSP服务器" target="_blank">基于Live555实现简单RTSP服务器</a>
<span class="text-muted">Zsy_05131068</span>
<a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a><a class="tag" taget="_blank" href="/search/qt/1.htm">qt</a>
<div>编译Live555本人使用Qt5.14.2编译Live555pro文件添加子模块include(UsageEnvironment/UsageEnvironment.pri)include(groupsock/groupsock.pri)include(BasicUsageEnvironment/BasicUsageEnvironment.pri)include(liveMedia/liveMedi</div>
</li>
<li><a href="/article/1943152923185836032.htm"
title="高压电缆护层电流监测系统的技术实现" target="_blank">高压电缆护层电流监测系统的技术实现</a>
<span class="text-muted">李子圆圆</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>目录文章目录概要高精度电流监测的技术实现多级预警机制的构建逻辑极端环境下的稳定运行技术远程运维的技术支撑概要高压电缆护层作为电力传输的关键防护结构,其接地电流的异常变化是判断设备状态的重要指标。TLKS-PLGD高压电缆护层电流监测系统通过传感器技术与智能算法的结合,构建了一套完整的电缆安全监测方案。高精度电流监测的技术实现高精度电流监测的技术实现护层电流监测的核心在于数据采集的精准性。该系统采用</div>
</li>
<li><a href="/article/1943151033807073280.htm"
title="【Linux | 网络】socket编程 - 使用TCP实现服务端向客户端提供简单的服务" target="_blank">【Linux | 网络】socket编程 - 使用TCP实现服务端向客户端提供简单的服务</a>
<span class="text-muted">是阿建吖!</span>
<a class="tag" taget="_blank" href="/search/%E3%80%90%E7%BD%91%E7%BB%9C%E3%80%91/1.htm">【网络】</a><a class="tag" taget="_blank" href="/search/%E3%80%90Linux%E3%80%91/1.htm">【Linux】</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/tcp%2Fip/1.htm">tcp/ip</a>
<div>目录一、Comm.hpp(公共数据)二、Log.hpp(日志)三、InetAddr.hpp(管理sockaddr_in相关信息)四、NoCopy.hpp(防拷贝)五、Lockguard.hpp(自动管理锁)六、Thread.hpp(封装线程)七、ThreadPool.hpp(线程池)八、dict.txt(配置文件、简单字典)九、Translate.hpp(提供翻译服务)十、Daemon.hpp(使</div>
</li>
<li><a href="/article/1943148009663557632.htm"
title="构建安全密码存储策略:核心原则与最佳实践" target="_blank">构建安全密码存储策略:核心原则与最佳实践</a>
<span class="text-muted">weixin_47233946</span>
<a class="tag" taget="_blank" href="/search/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8/1.htm">信息安全</a><a class="tag" taget="_blank" href="/search/%E5%AE%89%E5%85%A8/1.htm">安全</a>
<div>密码是用户身份认证的第一道防线,其存储安全性直接关系到用户隐私和企业信誉。近年来频发的数据泄露事件揭示了密码管理的关键性。本文将深入探讨从加密算法到系统性防护的完整密码存储方案,帮助开发者构建企业级安全防御体系。一、密码存储基本准则绝对禁止明文存储:即使采用数据库加密措施,直接存储用户原始密码仍存在不可逆泄露风险。运维人员权限滥用或备份文件泄露都可能成为突破口。加密≠安全:AES等对称加密存在密钥</div>
</li>
<li><a href="/article/1943144230612430848.htm"
title="Linux文件权限管理" target="_blank">Linux文件权限管理</a>
<span class="text-muted">IT摆渡者</span>
<a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>Linux文件权限管理:告别777,掌握核心操作在Linux系统中,文件权限是保障系统安全的基础。不少运维新手图省事,动辄给文件设置777权限,这其实隐藏着巨大安全风险。本文带你快速掌握Linux文件权限的核心知识与实用操作,摆脱对777的依赖。一、文件权限基础概念Linux通过"用户类别+权限类型"实现权限管控,核心要素包括:•三类用户:拥有者(user)、用户组(group)、其他用户(oth</div>
</li>
<li><a href="/article/1943140198061764608.htm"
title="linux-权限管理" target="_blank">linux-权限管理</a>
<span class="text-muted"></span>
<div>linux-权限管理一、权限的基本类型二、权限的表示方式1.字符形式(rwx)2.数字形式三、权限管理常用命令1.chmod2.chown3.chgrp四、隐藏权限1.lsattr2.chattr五、权限掩码六、特别权限位1.suid2.sgid3.StickyBit七、权限委托1.授权用户2.授权组里的用户3.使用命令别名授权八、ACL1.getfacl2.setfacl总结一、权限的基本类型读</div>
</li>
<li><a href="/article/86.htm"
title="linux系统服务器下jsp传参数乱码" target="_blank">linux系统服务器下jsp传参数乱码</a>
<span class="text-muted">3213213333332132</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jsp/1.htm">jsp</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a><a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a>
<div>在一次解决乱码问题中, 发现jsp在windows下用js原生的方法进行编码没有问题,但是到了linux下就有问题, escape,encodeURI,encodeURIComponent等都解决不了问题
但是我想了下既然原生的方法不行,我用el标签的方式对中文参数进行加密解密总该可以吧。于是用了java的java.net.URLDecoder,结果还是乱码,最后在绝望之际,用了下面的方法解决了</div>
</li>
<li><a href="/article/213.htm"
title="Spring 注解区别以及应用" target="_blank">Spring 注解区别以及应用</a>
<span class="text-muted">BlueSkator</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a>
<div>1. @Autowired
@Autowired是根据类型进行自动装配的。如果当Spring上下文中存在不止一个UserDao类型的bean,或者不存在UserDao类型的bean,会抛出 BeanCreationException异常,这时可以通过在该属性上再加一个@Qualifier注解来声明唯一的id解决问题。
2. @Qualifier
当spring中存在至少一个匹</div>
</li>
<li><a href="/article/340.htm"
title="printf和sprintf的应用" target="_blank">printf和sprintf的应用</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/sprintf/1.htm">sprintf</a><a class="tag" taget="_blank" href="/search/printf/1.htm">printf</a>
<div><?php
printf('b: %b <br>c: %c <br>d: %d <bf>f: %f', 80,80, 80, 80);
echo '<br />';
printf('%0.2f <br>%+d <br>%0.2f <br>', 8, 8, 1235.456);
printf('th</div>
</li>
<li><a href="/article/467.htm"
title="config.getInitParameter" target="_blank">config.getInitParameter</a>
<span class="text-muted">171815164</span>
<a class="tag" taget="_blank" href="/search/parameter/1.htm">parameter</a>
<div>web.xml
<servlet>
<servlet-name>servlet1</servlet-name>
<jsp-file>/index.jsp</jsp-file>
<init-param>
<param-name>str</param-name>
</div>
</li>
<li><a href="/article/594.htm"
title="Ant标签详解--基础操作" target="_blank">Ant标签详解--基础操作</a>
<span class="text-muted">g21121</span>
<a class="tag" taget="_blank" href="/search/ant/1.htm">ant</a>
<div> Ant的一些核心概念:
build.xml:构建文件是以XML 文件来描述的,默认构建文件名为build.xml。 project:每个构建文</div>
</li>
<li><a href="/article/721.htm"
title="[简单]代码片段_数据合并" target="_blank">[简单]代码片段_数据合并</a>
<span class="text-muted">53873039oycg</span>
<a class="tag" taget="_blank" href="/search/%E4%BB%A3%E7%A0%81/1.htm">代码</a>
<div> 合并规则:删除家长phone为空的记录,若一个家长对应多个孩子,保留一条家长记录,家长id修改为phone,对应关系也要修改。
代码如下:
</div>
</li>
<li><a href="/article/848.htm"
title="java 通信技术" target="_blank">java 通信技术</a>
<span class="text-muted">云端月影</span>
<a class="tag" taget="_blank" href="/search/Java+%E8%BF%9C%E7%A8%8B%E9%80%9A%E4%BF%A1%E6%8A%80%E6%9C%AF/1.htm">Java 远程通信技术</a>
<div>在分布式服务框架中,一个最基础的问题就是远程服务是怎么通讯的,在Java领域中有很多可实现远程通讯的技术,例如:RMI、MINA、ESB、Burlap、Hessian、SOAP、EJB和JMS等,这些名词之间到底是些什么关系呢,它们背后到底是基于什么原理实现的呢,了解这些是实现分布式服务框架的基础知识,而如果在性能上有高的要求的话,那深入了解这些技术背后的机制就是必须的了,在这篇blog中我们将来</div>
</li>
<li><a href="/article/975.htm"
title="string与StringBuilder 性能差距到底有多大" target="_blank">string与StringBuilder 性能差距到底有多大</a>
<span class="text-muted">aijuans</span>
<div>
之前也看过一些对string与StringBuilder的性能分析,总感觉这个应该对整体性能不会产生多大的影响,所以就一直没有关注这块!
由于学程序初期最先接触的string拼接,所以就一直没改变过自己的习惯!
</div>
</li>
<li><a href="/article/1102.htm"
title="今天碰到 java.util.ConcurrentModificationException 异常" target="_blank">今天碰到 java.util.ConcurrentModificationException 异常</a>
<span class="text-muted">antonyup_2006</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%A4%9A%E7%BA%BF%E7%A8%8B/1.htm">多线程</a><a class="tag" taget="_blank" href="/search/%E5%B7%A5%E4%BD%9C/1.htm">工作</a><a class="tag" taget="_blank" href="/search/IBM/1.htm">IBM</a>
<div>今天改bug,其中有个实现是要对map进行循环,然后有删除操作,代码如下:
Iterator<ListItem> iter = ItemMap.keySet.iterator();
while(iter.hasNext()){
ListItem it = iter.next();
//...一些逻辑操作
ItemMap.remove(it);
}
结果运行报Con</div>
</li>
<li><a href="/article/1229.htm"
title="PL/SQL的类型和JDBC操作数据库" target="_blank">PL/SQL的类型和JDBC操作数据库</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/PL%2FSQL%E8%A1%A8/1.htm">PL/SQL表</a><a class="tag" taget="_blank" href="/search/%E6%A0%87%E9%87%8F%E7%B1%BB%E5%9E%8B/1.htm">标量类型</a><a class="tag" taget="_blank" href="/search/%E6%B8%B8%E6%A0%87/1.htm">游标</a><a class="tag" taget="_blank" href="/search/PL%2FSQL%E8%AE%B0%E5%BD%95/1.htm">PL/SQL记录</a>
<div>PL/SQL的标量类型:
字符,数字,时间,布尔,%type五中类型的
--标量:数据库中预定义类型的变量
--定义一个变长字符串
v_ename varchar2(10);
--定义一个小数,范围 -9999.99~9999.99
v_sal number(6,2);
--定义一个小数并给一个初始值为5.4 :=是pl/sql的赋值号
</div>
</li>
<li><a href="/article/1356.htm"
title="Mockito:一个强大的用于 Java 开发的模拟测试框架实例" target="_blank">Mockito:一个强大的用于 Java 开发的模拟测试框架实例</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/mockito/1.htm">mockito</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95/1.htm">单元测试</a>
<div>Mockito框架:
Mockito是一个基于MIT协议的开源java测试框架。 Mockito区别于其他模拟框架的地方主要是允许开发者在没有建立“预期”时验证被测系统的行为。对于mock对象的一个评价是测试系统的测</div>
</li>
<li><a href="/article/1483.htm"
title="精通Oracle10编程SQL(10)处理例外" target="_blank">精通Oracle10编程SQL(10)处理例外</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/plsql/1.htm">plsql</a>
<div>/*
*处理例外
*/
--例外简介
--处理例外-传递例外
declare
v_ename emp.ename%TYPE;
begin
SELECT ename INTO v_ename FROM emp
where empno=&no;
dbms_output.put_line('雇员名:'||v_ename);
exceptio</div>
</li>
<li><a href="/article/1610.htm"
title="【Java】Java执行远程机器上Linux命令" target="_blank">【Java】Java执行远程机器上Linux命令</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/linux%E5%91%BD%E4%BB%A4/1.htm">linux命令</a>
<div>Java使用ethz通过ssh2执行远程机器Linux上命令,
封装定义Linux机器的环境信息
package com.tom;
import java.io.File;
public class Env {
private String hostaddr; //Linux机器的IP地址
private Integer po</div>
</li>
<li><a href="/article/1737.htm"
title="java通信之Socket通信基础" target="_blank">java通信之Socket通信基础</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/socket/1.htm">socket</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE/1.htm">网络协议</a>
<div>正处于网络环境下的两个程序,它们之间通过一个交互的连接来实现数据通信。每一个连接的通信端叫做一个Socket。一个完整的Socket通信程序应该包含以下几个步骤:
①创建Socket;
②打开连接到Socket的输入输出流;
④按照一定的协议对Socket进行读写操作;
④关闭Socket。
Socket通信分两部分:服务器端和客户端。服务器端必须优先启动,然后等待soc</div>
</li>
<li><a href="/article/1864.htm"
title="angular.bind" target="_blank">angular.bind</a>
<span class="text-muted">boyitech</span>
<a class="tag" taget="_blank" href="/search/AngularJS/1.htm">AngularJS</a><a class="tag" taget="_blank" href="/search/angular.bind/1.htm">angular.bind</a><a class="tag" taget="_blank" href="/search/AngularJS+API/1.htm">AngularJS API</a><a class="tag" taget="_blank" href="/search/bind/1.htm">bind</a>
<div>angular.bind 描述: 上下文,函数以及参数动态绑定,返回值为绑定之后的函数. 其中args是可选的动态参数,self在fn中使用this调用。 使用方法: angular.bind(se</div>
</li>
<li><a href="/article/1991.htm"
title="java-13个坏人和13个好人站成一圈,数到7就从圈里面踢出一个来,要求把所有坏人都给踢出来,所有好人都留在圈里。请找出初始时坏人站的位置。" target="_blank">java-13个坏人和13个好人站成一圈,数到7就从圈里面踢出一个来,要求把所有坏人都给踢出来,所有好人都留在圈里。请找出初始时坏人站的位置。</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>
import java.util.ArrayList;
import java.util.List;
public class KickOutBadGuys {
/**
* 题目:13个坏人和13个好人站成一圈,数到7就从圈里面踢出一个来,要求把所有坏人都给踢出来,所有好人都留在圈里。请找出初始时坏人站的位置。
* Maybe you can find out </div>
</li>
<li><a href="/article/2118.htm"
title="Redis.conf配置文件及相关项说明(自查备用)" target="_blank">Redis.conf配置文件及相关项说明(自查备用)</a>
<span class="text-muted">Kai_Ge</span>
<a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a>
<div> Redis.conf配置文件及相关项说明
# Redis configuration file example
# Note on units: when memory size is needed, it is possible to specifiy
# it in the usual form of 1k 5GB 4M and so forth:
#
</div>
</li>
<li><a href="/article/2245.htm"
title="[强人工智能]实现大规模拓扑分析是实现强人工智能的前奏" target="_blank">[强人工智能]实现大规模拓扑分析是实现强人工智能的前奏</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>
真不好意思,各位朋友...博客再次更新...
节点数量太少,网络的分析和处理能力肯定不足,在面对机器人控制的需求方面,显得力不从心....
但是,节点数太多,对拓扑数据处理的要求又很高,设计目标也很高,实现起来难度颇大...
</div>
</li>
<li><a href="/article/2372.htm"
title="记录一些常用的函数" target="_blank">记录一些常用的函数</a>
<span class="text-muted">dai_lm</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>
public static String convertInputStreamToString(InputStream is) {
StringBuilder result = new StringBuilder();
if (is != null)
try {
InputStreamReader inputReader = new InputStreamRead</div>
</li>
<li><a href="/article/2499.htm"
title="Hadoop中小规模集群的并行计算缺陷" target="_blank">Hadoop中小规模集群的并行计算缺陷</a>
<span class="text-muted">datamachine</span>
<a class="tag" taget="_blank" href="/search/mapreduce/1.htm">mapreduce</a><a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a><a class="tag" taget="_blank" href="/search/%E5%B9%B6%E8%A1%8C%E8%AE%A1%E7%AE%97/1.htm">并行计算</a>
<div>注:写这篇文章的初衷是因为Hadoop炒得有点太热,很多用户现有数据规模并不适用于Hadoop,但迫于扩容压力和去IOE(Hadoop的廉价扩展的确非常有吸引力)而尝试。尝试永远是件正确的事儿,但有时候不用太突进,可以调优或调需求,发挥现有系统的最大效用为上策。
-----------------------------------------------------------------</div>
</li>
<li><a href="/article/2626.htm"
title="小学4年级英语单词背诵第二课" target="_blank">小学4年级英语单词背诵第二课</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/english/1.htm">english</a><a class="tag" taget="_blank" href="/search/word/1.htm">word</a>
<div>egg 蛋
twenty 二十
any 任何
well 健康的,好
twelve 十二
farm 农场
every 每一个
back 向后,回
fast 快速的
whose 谁的
much 许多
flower 花
watch 手表
very 非常,很
sport 运动
Chinese 中国的
</div>
</li>
<li><a href="/article/2753.htm"
title="自己实践了github的webhooks, linux上面的权限需要注意" target="_blank">自己实践了github的webhooks, linux上面的权限需要注意</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/github/1.htm">github</a><a class="tag" taget="_blank" href="/search/webhook/1.htm">webhook</a>
<div>环境, 阿里云服务器
1. 本地创建项目, push到github服务器上面
2. 生成www用户的密钥
sudo -u www ssh-keygen -t rsa -C "xxx@xx.com"
3. 将密钥添加到github帐号的SSH_KEYS里面
3. 用www用户执行克隆, 源使</div>
</li>
<li><a href="/article/2880.htm"
title="Java冒泡排序" target="_blank">Java冒泡排序</a>
<span class="text-muted">蕃薯耀</span>
<a class="tag" taget="_blank" href="/search/%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F/1.htm">冒泡排序</a><a class="tag" taget="_blank" href="/search/Java%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F/1.htm">Java冒泡排序</a><a class="tag" taget="_blank" href="/search/Java%E6%8E%92%E5%BA%8F/1.htm">Java排序</a>
<div>冒泡排序
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年6月23日 10:40:14 星期二
http://fanshuyao.iteye.com/</div>
</li>
<li><a href="/article/3007.htm"
title="Excle读取数据转换为实体List【基于apache-poi】" target="_blank">Excle读取数据转换为实体List【基于apache-poi】</a>
<span class="text-muted">hanqunfeng</span>
<a class="tag" taget="_blank" href="/search/apache/1.htm">apache</a>
<div>1.依赖apache-poi
2.支持xls和xlsx
3.支持按属性名称绑定数据值
4.支持从指定行、列开始读取
5.支持同时读取多个sheet
6.具体使用方式参见org.cpframework.utils.excelreader.CP_ExcelReaderUtilTest.java
比如:
Str</div>
</li>
<li><a href="/article/3134.htm"
title="3个处于草稿阶段的Javascript API介绍" target="_blank">3个处于草稿阶段的Javascript API介绍</a>
<span class="text-muted">jackyrong</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>原文:
http://www.sitepoint.com/3-new-javascript-apis-may-want-follow/?utm_source=html5weekly&utm_medium=email
本文中,介绍3个仍然处于草稿阶段,但应该值得关注的Javascript API.
1) Web Alarm API
&</div>
</li>
<li><a href="/article/3261.htm"
title="6个创建Web应用程序的高效PHP框架" target="_blank">6个创建Web应用程序的高效PHP框架</a>
<span class="text-muted">lampcy</span>
<a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/%E6%A1%86%E6%9E%B6/1.htm">框架</a><a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a>
<div>以下是创建Web应用程序的PHP框架,有coder bay网站整理推荐:
1. CakePHP
CakePHP是一个PHP快速开发框架,它提供了一个用于开发、维护和部署应用程序的可扩展体系。CakePHP使用了众所周知的设计模式,如MVC和ORM,降低了开发成本,并减少了开发人员写代码的工作量。
2. CodeIgniter
CodeIgniter是一个非常小且功能强大的PHP框架,适合需</div>
</li>
<li><a href="/article/3388.htm"
title="评"救市后中国股市新乱象泛起"谣言" target="_blank">评"救市后中国股市新乱象泛起"谣言</a>
<span class="text-muted">nannan408</span>
<div>首先来看百度百家一位易姓作者的新闻:
三个多星期来股市持续暴跌,跌得投资者及上市公司都处于极度的恐慌和焦虑中,都要寻找自保及规避风险的方式。面对股市之危机,政府突然进入市场救市,希望以此来重建市场信心,以此来扭转股市持续暴跌的预期。而政府进入市场后,由于市场运作方式发生了巨大变化,投资者及上市公司为了自保及为了应对这种变化,中国股市新的乱象也自然产生。
首先,中国股市这两天</div>
</li>
<li><a href="/article/3515.htm"
title="页面全屏遮罩的实现 方式" target="_blank">页面全屏遮罩的实现 方式</a>
<span class="text-muted">Rainbow702</span>
<a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/%E9%81%AE%E7%BD%A9/1.htm">遮罩</a><a class="tag" taget="_blank" href="/search/mask/1.htm">mask</a>
<div>之前做了一个页面,在点击了某个按钮之后,要求页面出现一个全屏遮罩,一开始使用了position:absolute来实现的。当时因为画面大小是固定的,不可以resize的,所以,没有发现问题。
最近用了同样的做法做了一个遮罩,但是画面是可以进行resize的,所以就发现了一个问题,当画面被reisze到浏览器出现了滚动条的时候,就发现,用absolute 的做法是有问题的。后来改成fixed定位就</div>
</li>
<li><a href="/article/3642.htm"
title="关于angularjs的点滴" target="_blank">关于angularjs的点滴</a>
<span class="text-muted">tntxia</span>
<a class="tag" taget="_blank" href="/search/AngularJS/1.htm">AngularJS</a>
<div>
angular是一个新兴的JS框架,和以往的框架不同的事,Angularjs更注重于js的建模,管理,同时也提供大量的组件帮助用户组建商业化程序,是一种值得研究的JS框架。
Angularjs使我们可以使用MVC的模式来写JS。Angularjs现在由谷歌来维护。
这里我们来简单的探讨一下它的应用。
首先使用Angularjs我</div>
</li>
<li><a href="/article/3769.htm"
title="Nutz--->>反复新建ioc容器的后果" target="_blank">Nutz--->>反复新建ioc容器的后果</a>
<span class="text-muted">xiaoxiao1992428</span>
<a class="tag" taget="_blank" href="/search/DAO/1.htm">DAO</a><a class="tag" taget="_blank" href="/search/mvc/1.htm">mvc</a><a class="tag" taget="_blank" href="/search/IOC/1.htm">IOC</a><a class="tag" taget="_blank" href="/search/nutz/1.htm">nutz</a>
<div>问题:
public class DaoZ {
public static Dao dao() { // 每当需要使用dao的时候就取一次
Ioc ioc = new NutIoc(new JsonLoader("dao.js"));
return ioc.get(</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html><script data-cfasync="false" src="/cdn-cgi/scripts/5c5dd728/cloudflare-static/email-decode.min.js"></script>