python之初识爬虫下篇
** ***python之初识爬虫下篇*****
自从上次写了一个简易的小脚本之后,就在写其他方面的东西了,昨天无意间翻出来运行了下我之前写的,发现是这样的
 之前的不能用了,那就改一下吧
之前的不能用了,那就改一下吧
对之前的各个点打印出来和以前对比,发现
 之前的是这样的。。。
之前的是这样的。。。
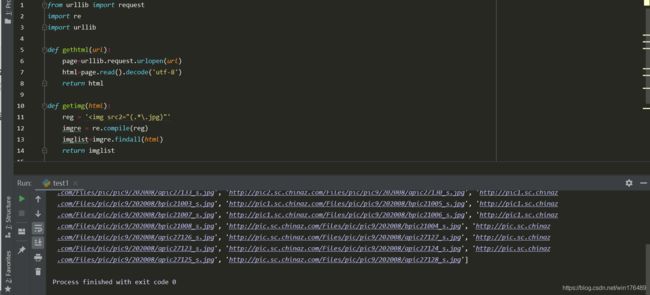
问题发现了,再写一个url拼接就OK
最终代码如下
from urllib import request
import re
import urllib
import os
from urllib import parse
def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8')
print(html)
return html
def geturls(html):
pa='
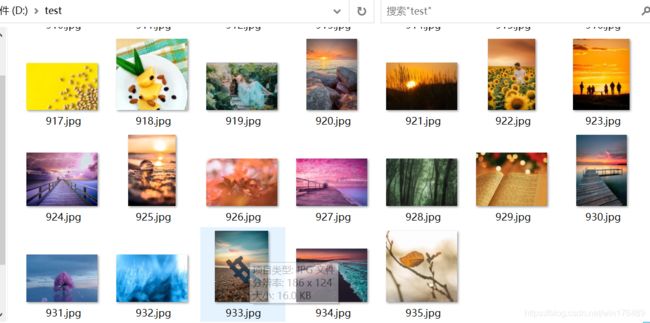
注:此代码仅作为学习交流使用