Pytorch学习笔记(二)自用
涉及资源
1.官网DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ
2.莫烦python 个人网站 、 b站视频、参考代码、强化学习
3.函数搜索:https://pytorch.org/docs/stable/index.html
系列学习笔记:
Pytorch学习笔记(一)
Pytorch学习笔记(二)
Pytorch学习笔记(三)
本周学习内容:
pytorch实现CNN分类器,识别MNIST数据集
以CNN为例,实现GPU加速
pytorch实现RNN分类器,识别MNIST数据集
pytorch实现RNN回归,用sin去拟合cos
pytorch实现自编码
pytorch实现DQN,模拟小车顶棍子
pytorch实现GAN,画曲线
环境配置:
python=3.7; torch=1.6.0; torchvision=0.7.0
6、CNN
import os
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
# hyper para
EPOCH = 1
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = False
### 1.Mnist digits dataset
# trainning data
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data;False test data
transform=torchvision.transforms.ToTensor(), # Converts Image (0-255)变成(0-1)
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
'''print(train_data.train_data.size()) # [60000, 28, 28]
print(train_data.train_labels.size()) # [60000]
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')# 第一张图
plt.title('%i' % train_data.train_labels[0])
plt.show()'''
# pick 2000 testing data
test_data = torchvision.datasets.MNIST(
root='./mnist/',
train=False
)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
### 2.define CNN
class CNN(nn.Module): # 继承torch的模块
def __init__(self):
super(CNN, self).__init__() # 调用父类的初始化
self.conv1 = nn.Sequential( # 一个典型层包含三级 卷积 激活 池化
nn.Conv2d(
in_channels=1, # input height(彩色图为3,灰度图为1)
out_channels=16, # n_filters,同时扫描某一区域的16个不同的特征
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # padding=(kernel_size-1)/2 if stride=1;补0以提取边缘特征
), # --> (16, 28, 28)
nn.ReLU(), # 非线性化 # --> (16, 28, 28)
nn.MaxPool2d(kernel_size=2),# --> (16, 14, 14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),# --> (32, 14, 14)
nn.ReLU(), # 非线性化 # --> (32, 14, 14)
nn.MaxPool2d(2),# --> (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x): # 前向传递,搭建神经网络,x = inputData
x = self.conv1(x)
x = self.conv2(x) # -->(batch, 32, 7, 7)
x = x.view(x.size(0), -1) # -->(batch, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
print(cnn)
### 3.define loss + optimizer
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
# Data Loader for easy mini-batch , the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True,
)
# following function (plot_with_labels) is for visualization, can be ignored if not interested
from matplotlib import cm
try: from sklearn.manifold import TSNE; HAS_SK = True
except: HAS_SK = False; print('Please install sklearn for layer visualization')
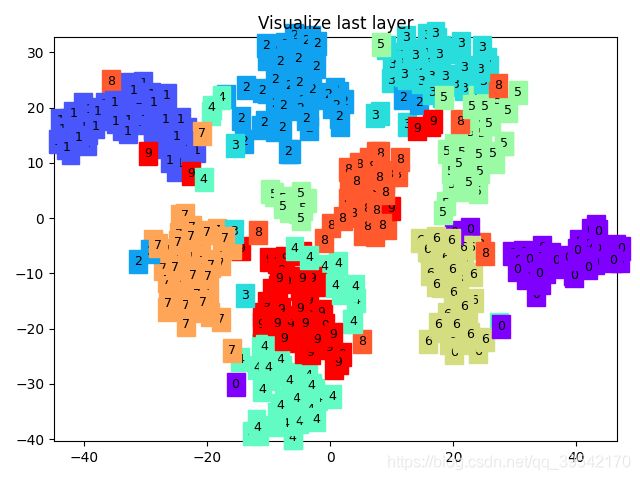
def plot_with_labels(lowDWeights, labels):
plt.cla()
X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
for x, y, s in zip(X, Y, labels):
c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
plt.ion()
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
if HAS_SK:
# Visualization of trained flatten layer (T-SNE)
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 500
low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
labels = test_y.numpy()[:plot_only]
plot_with_labels(low_dim_embs, labels)
plt.ioff()
# print 10 predictions from test data
test_output, _ = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
该代码有点问题,我再看看。11.22更:def forward 整体要前移4格
print(cnn)
CNN( (conv1): Sequential(
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (out): Linear(in_features=1568,
out_features=10, bias=True) )
prediction number & real number
[7 2 1 0 4 1 4 9 5 9]
[7 2 1 0 4 1 4 9 5 9]
7、RNN_classifier
import torch
from torch import nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# Hyper Parameters
EPOCH = 1
BATCH_SIZE = 64
TIME_STEP = 28 # rnn time step / image height # 输入多少次
INPUT_SIZE = 28 # rnn input size / image width # 每一次输入多少
LR = 0.01 # learning rate
DOWNLOAD_MNIST = False # set to True if haven't download the data
# Mnist digital dataset
train_data = dsets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST, # download it if you don't have it
)
'''# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
plt.imshow(train_data.train_data[2].numpy(), cmap='gray')
plt.title('%i' % train_data.train_labels[0])
plt.show()'''
# Data Loader for easy mini-batch return in training
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# convert test data into Variable, pick 2000 samples to speed up testing
test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
test_x = test_data.test_data.type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
test_y = test_data.test_labels.numpy()[:2000] # covert to numpy array
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # long short term memory 效果更好一点
input_size=INPUT_SIZE,
hidden_size=128,
num_layers=2,
batch_first=True, # 把batch放在第一个维度 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(128, 10) # 输出为10
def forward(self, x):
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size) # hidden state,一个分线程,一个主线程
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state
out = self.out(r_out[:, -1, :]) # choose r_out at the last time step
return out
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader): # gives batch data
b_x = x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
output = rnn(b_x) # rnn output
loss = loss_func(output, y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output = rnn(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
# print 10 predictions from test data
test_output = rnn(test_x[:10].view(-1, 28, 28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')
print(rnn)
RNN(
(rnn): LSTM(28, 128, num_layers=2, batch_first=True)
(out): Linear(in_features=128, out_features=10, bias=True)
)
prediction number & real number
[7 2 1 0 4 1 4 9 8 9]
[7 2 1 0 4 1 4 9 5 9]
8、RNN_regressior
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
# Hyper Parameters
TIME_STEP = 10 # rnn time step # 输入多少次
INPUT_SIZE = 1 # rnn input size # 每一次输入多少
LR = 0.01 # learning rate
# show data
steps = np.linspace(0, np.pi * 2, 100, dtype=np.float32) # float32 for converting torch FloatTensor
x_np = np.sin(steps)
y_np = np.cos(steps)
plt.plot(steps, y_np, 'r-', label='target (cos)')
plt.plot(steps, x_np, 'b-', label='input (sin)')
plt.legend(loc='best')
plt.show()
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=INPUT_SIZE,
hidden_size=32, # hidden_state有多少个神经元
num_layers=2, # 原文是1
batch_first=True, # batch是否处在第一个 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(32, 1) # 输入为32, 输出为10
def forward(self, x, h_state):
# x (batch, time_step, input_size)
# h_state (n_layers, batch, hidden_size)
# r_out (batch, time_step, hidden_size)
r_out, h_state = self.rnn(x, h_state) # 一个batch内的h_state是隐式传递的,上一个classifier代码批量放入28条
outs = self.out(r_out)
return outs, h_state
# for time_step in range(r_out.size(1)): # calculate output for each time step
# outs.append(self.out(r_out[:, time_step, :]))
# return torch.stack(outs, dim=1), h_state
# instead, for simplicity, you can replace above codes by follows
# r_out = r_out.view(-1, 32)
# outs = self.out(r_out)
# outs = outs.view(-1, TIME_STEP, 1)
# return outs, h_state
# or even simpler, since nn.Linear can accept inputs of any dimension
# and returns outputs with same dimension except for the last
# outs = self.out(r_out)
# return outs
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
h_state = None # for initial hidden state 最初为全0
plt.figure(1, figsize=(12, 5))
plt.ion() # continuously plot
for step in range(100):
start, end = step * np.pi, (step + 1) * np.pi # time range
# use sin predicts cos
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32,
endpoint=False) # float32 for converting torch FloatTensor
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # 加维度 # shape (batch, time_step, input_size),其中batch维度为1
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
prediction, h_state = rnn(x, h_state) # rnn output
# !! next step is important !!
h_state = h_state.data # repack the hidden state, break the connection from last iteration
loss = loss_func(prediction, y) # calculate loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
# plotting
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.draw();
plt.pause(0.05)
plt.ioff()
plt.show()
print(rnn)
RNN(
(rnn): RNN(1, 32, num_layers=2, batch_first=True)
(out): Linear(in_features=32, out_features=1, bias=True)
)
9、autoencoder
无监督算法
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
import numpy as np
# hyper para
EPOCH = 5
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = False
N_TEST_IMG = 5
# trainning data
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data;False test data
transform=torchvision.transforms.ToTensor(), # Converts Image (0-255)变成(0-1)
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
print(train_data.train_data.size()) # [60000, 28, 28]
print(train_data.train_labels.size()) # [60000]
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')# 第一张图
plt.title('%i' % train_data.train_labels[0])
plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
class AutoEncoder(nn.Module): # 继承torch的模块
def __init__(self):
super(AutoEncoder, self).__init__() # 调用父类的初始化
self.encoder = nn.Sequential(
nn.Linear(28*28, 128), # 放在128隐藏层中
nn.Tanh(), # 激活
nn.Linear(128, 64),
nn.Tanh(),
nn.Linear(64, 12),# 继续压缩
nn.Tanh(),
nn.Linear(12, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(), # 激活
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128), # 继续解压
nn.Tanh(),
nn.Linear(128, 28*28),
nn.Sigmoid() # data在训练的时候压缩到为[0,1],所以输出值压缩到[0,1]
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
autoencoder = AutoEncoder()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
loss_func = nn.MSELoss()
# initialize figure
f, a = plt.subplots(2, N_TEST_IMG, figsize=(5, 2))
plt.ion() # continuously plot
# original data (first row) for viewing
view_data = train_data.train_data[:N_TEST_IMG].view(-1, 28*28).type(torch.FloatTensor)/255.
for i in range(N_TEST_IMG):
a[0][i].imshow(np.reshape(view_data.data.numpy()[i], (28, 28)), cmap='gray'); a[0][i].set_xticks(()); a[0][i].set_yticks(())
# 开始训练
for epoch in range(EPOCH):
for step, (x, b_label) in enumerate(train_loader):
b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28)
b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28), 实际上用到的还是 x数据
encoded, decoded = autoencoder(b_x)
loss = loss_func(decoded, b_y) # 解压后与原图进行比较
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 100 == 0:
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy())
# plotting decoded image (second row)
_, decoded_data = autoencoder(view_data)
# print(view_data)
for i in range(N_TEST_IMG):
a[1][i].clear()
a[1][i].imshow(np.reshape(decoded_data.data.numpy()[i], (28, 28)), cmap='gray')
a[1][i].set_xticks(())
a[1][i].set_yticks(())
plt.draw()
plt.pause(0.05)
plt.ioff()
plt.show()
# 用手写数字数据来压缩再解压图片
# 然后用压缩的特征进行非监督分类
# visualize in 3D plot
view_data = train_data.train_data[:200].view(-1, 28*28).type(torch.FloatTensor)/255.
encoded_data, _ = autoencoder(view_data)
fig = plt.figure(2); ax = Axes3D(fig)
X, Y, Z = encoded_data.data[:, 0].numpy(), encoded_data.data[:, 1].numpy(), encoded_data.data[:, 2].numpy()
values = train_data.train_labels[:200].numpy()
for x, y, z, s in zip(X, Y, Z, values):
c = cm.rainbow(int(255*s/9)); ax.text(x, y, z, s, backgroundcolor=c)
ax.set_xlim(X.min(), X.max()); ax.set_ylim(Y.min(), Y.max()); ax.set_zlim(Z.min(), Z.max())
plt.show()
原图 & 压缩再解压图片(不知道为啥解压图片无法显示,我再看看)

用压缩的特征进行非监督分类

10、DQN
属于强化学习,深度学习的可以走了
强化学习学习资源:https://my.oschina.net/u/876354/blog/1614879
https://www.bilibili.com/video/av16921335?zw
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
# Hyper Parameters
BATCH_SIZE = 32
LR = 0.01
EPSILON = 0.9 # greedy policy
GAMMA = 0.9 # reward discount
TARGET_REPLACE_ITER = 100 # target update frequency
MEMORY_CAPACITY = 2000
env = gym.make('CartPole-v0') # 导入实验模拟场所
env = env.unwrapped
N_ACTIONS = env.action_space.n
N_STATES = env.observation_space.shape[0]
ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample().shape # to confirm the shape
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__() # 调用父类的初始化
self.fc1 = nn.Linear(N_STATES, 50) # 第一层, 输入观测值,输出动作的价值
self.fc1.weight.data.normal_(0, 0.1) # 随机生成正态分布的初始参数,会有更好的效果
self.out = nn.Linear(50, N_ACTIONS)
self.out.weight.data.normal_(0, 0.1)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x) # 激励函数
actions_value = self.out(x) # 有左右两个action
return actions_value
class DQN(object):
def __init__(self):
self.eval_net, self.target_net = Net(), Net() # 两个神经网络结构相同,但参数不同
self.learn_step_counter = 0 # for target updating,记录学习到多少步
self.memory_counter = 0 # for storing memory,记录记忆库位置
self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory, 初始化记忆库
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self, x): # 如90%概率按以往经验选最优解, 10%概率去探索其他
x = torch.unsqueeze(torch.FloatTensor(x), 0)
# input only one sample
if np.random.uniform() < EPSILON: # greedy
actions_value = self.eval_net.forward(x)
action = torch.max(actions_value, 1)[1].data.numpy()
action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # return the argmax index, 选取最大价值
else: # random ,在数据库中选取其他的动作
action = np.random.randint(0, N_ACTIONS)
action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
return action
def store_transition(self, s, a, r, s_): # 存储 # (state action reward 下一个state 记忆库)
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % MEMORY_CAPACITY # 超出后覆盖老记忆
self.memory[index, :] = transition
self.memory_counter += 1
def learn(self): # 学习存储好的记忆
# target parameter update
if self.learn_step_counter % TARGET_REPLACE_ITER == 0: # 隔TARGET_REPLACE_ITER更新一次, val_net参数赋值到target_net中;eval每次都更新
self.target_net.load_state_dict(self.eval_net.state_dict()) #
self.learn_step_counter += 1
# sample batch transitions
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE) # 在记忆库中随机抽取,BATCH_SIZE=32 个记忆
b_memory = self.memory[sample_index, :]
b_s = torch.FloatTensor(b_memory[:, :N_STATES]) # 拆开+打包记忆
b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES + 1].astype(int))
b_r = torch.FloatTensor(b_memory[:, N_STATES + 1:N_STATES + 2])
b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
# q_eval w.r.t the action in experience
q_eval = self.eval_net(b_s).gather(1, b_a) # Q估计 # shape (batch, 1)
q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate,因为q_next不希望更新
q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # Q现实 # shape (batch, 1),套入参数更新公式
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
dqn = DQN()
print('\nCollecting experience。。。。。')
for i_episode in range(400):
s = env.reset() # s代表state # 得到环境反馈
ep_r = 0
while True:
env.render() # 环境渲染
a = dqn.choose_action(s) # 根据状态来采取行为
# take action
s_, r, done, info = env.step(a) # 环境根据采取的行为进行反馈
# modify the reward,改一下小车车的细节
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r = r1 + r2
dqn.store_transition(s, a, r, s_) # dqn存储反馈
ep_r += r
if dqn.memory_counter > MEMORY_CAPACITY:
dqn.learn()
if done:
print('Ep: ', i_episode,'| Ep_r: ', round(ep_r, 2))
if done:
break
s = s_
学习顶棍子

11、GAN
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# Hyper Parameters
BATCH_SIZE = 64
LR_G = 0.0001 # learning rate for generator
LR_D = 0.0001 # learning rate for discriminator
N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
# show our beautiful painting range
plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
plt.legend(loc='upper right')
plt.show()
def artist_works( ):
a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
paintings = a * np.power(PAINT_POINTS, 2) + (a-1)
paintings = torch.from_numpy(paintings).float()
return paintings
G = nn.Sequential(
nn.Linear(N_IDEAS, 128),
nn.ReLU(),
nn.Linear(128, ART_COMPONENTS), # 用随机灵感画出一幅画
)
D = nn.Sequential(
nn.Linear(ART_COMPONENTS, 128),
nn.ReLU(),
nn.Linear(128, 1), # 判别接到的画是不是artist
nn.Sigmoid(), # 百分比
)
# 优化
opt_D = torch.optim.Adam(D.parameters(), lr=LR_D)
opt_G = torch.optim.Adam(G.parameters(), lr=LR_G)
plt.ion() # something about continuous plotting
# 学习
for step in range(10000):
artist_paintings = artist_works() # real painting from artist
G_ideas = torch.randn(BATCH_SIZE, N_IDEAS, requires_grad=True) # random ideas\n
G_paintings = G(G_ideas) # fake painting from G (random ideas)
prob_artist1 = D(G_paintings) # D try to reduce this prob
prob_artist0 = D(artist_paintings) # D try to increase this prob
G_loss = torch.mean(torch.log(1. - prob_artist1))
opt_G.zero_grad()
G_loss.backward()
opt_G.step()
prob_artist1 = D(G_paintings.detach()) # D try to reduce this prob
D_loss = - torch.mean(torch.log(prob_artist0) + torch.log(1. - prob_artist1)) # 交叉熵
opt_D.zero_grad()
D_loss.backward(retain_graph=True) # reusing computational graph,使得出错概率最小,判断更准确
opt_D.step()
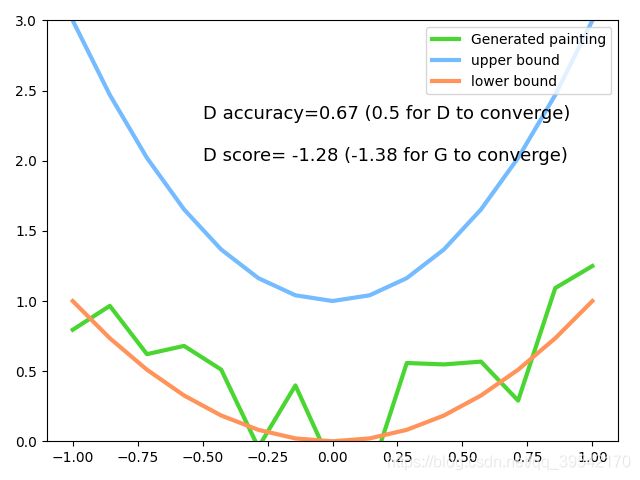
if step % 50 == 0: # plotting
plt.cla()
plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='Generated painting', )
plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
plt.text(-.5, 2.3, 'D accuracy=%.2f (0.5 for D to converge)' % prob_artist0.data.numpy().mean(),
fontdict={
'size': 13})
plt.text(-.5, 2, 'D score= %.2f (-1.38 for G to converge)' % -D_loss.data.numpy(), fontdict={
'size': 13})
plt.ylim((0, 3));
plt.legend(loc='upper right', fontsize=10);
plt.draw();
plt.pause(0.01)
plt.ioff()
plt.show()
刚开始
结束
