深度强化学习CS285-Lec16 Transfer Learning in RL
Transfer Learning 与 Distributed RL
- 概述
- 一、迁移学习与多任务学习
-
- 1.1 术语
- 1.2 Forward Transfer
-
- 1.2.1 Hope for the best
- 1.2.2 Fine-tune on the new task
- 1.2.3 Randomize Source Domain
- 1.2.4 Domain Adaptation
- 1.2.5 Forward Transfer Summary
- 1.3 Multi-task Transfer
-
- 1.3.1 MBRL
- 1.3.2 Model Distillation
- 1.3.3 Contextual Policies
- 1.3.4 Modular Policy Network
- 1.4 总结
- 一些论文资料
- 后记
概述
本文主要是RL中的迁移学习(transfer Learning)、多任务学习( Multi-task Learning)、分布式系统(Distributed Systems)
- 之前关注的是single agent在single task中怎么train的好,现在关注的是single agent如何在multi-task中迅速train好
- 缩短训练时间,引入多样性(diversity or variety)到agent的探索与利用使性能更好的分布式训练
关于Transfer Learning:
- Transfer prior tasks to learn new tasks more quickly :利用可能多个tasks的经验获得的policy、representation vector、Q-value、Model,去花式辅助new task。
- Train on source task so as to do better on target task:在一个Source task中train一下,然后直接用在Target task上使用,如Fine-tune、Source domain randomization
- Randomization of source task:在Source task上加入干扰、多样化,使其robust,再transfer到target task
- Multi-task transfer:在多个任务上训练,transfer到一个新任务上
- Contextual policies:将多个任务处理成特征向量,然后使policy condition on it
- Modular policies:对一个Policy的Network各部分,人为模块化,使网络中的结构Modular,具备特定功能
一、迁移学习与多任务学习
1.1 术语
- RL中一个task为一个MDP, M D P = { S , A , R , γ , T } MDP=\{S,A,R,\gamma,T\} MDP={ S,A,R,γ,T}
- Source Task与Target Task的关系定义了X-shot Learning

- Knowledge指的是RL算法中习得的结构对象:
- Policy :哪些动作potential better?
- Q Function:哪些状态 or 动作 更好?
- Models :dynamics model描述的是否准确?
- Features:能否提供一个好的representation vector?
1.2 Forward Transfer
定义:在一个Source Task中train,transfer到一个new task
1.2.1 Hope for the best
在一个Source Task,即一个Source MDP中Train一个Policy,然后直接在New Task中尝试。
如:
在Robotics的虚拟仿真环境中训练得一个Policy,直接在现实的Robotics中使用,然后Hope for the best,确实有的还是work的~
1.2.2 Fine-tune on the new task
设定:Source Task与Target Task都fixed的前提下
从CV任务中出发,在ImageNet中取下具备图像特征的Representation ,然后在downstream tasks中Fine-tune,这种在RL中是否可行呢?
- 首先Fine-tune的对象应该是policy or Value Function
- 其次,Source task与new task的不同之处是不一样的MDP,意味着同样的state映射的action可能不一样,Value也可能不同,则Policy在Source Task中已经比较deterministic了,即low-entropy policy,而Value在Source Task中就比较Specialized了,该如何像ImageNet中找一个共同的representation然后给new tasks进行Fine-tune呢?
- 解决方法便是Lec14-15中推导出来的Soft Optimal Framework,利用了Entropy regularised的Objective,对Optimal Behavior进行了建模,可以调整Entropy权重~,啥意思呢?
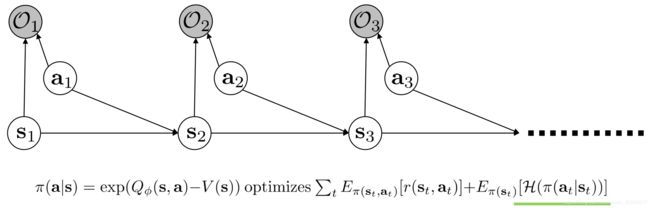
举一个Fine-tune的例子:
如上图,Source Task的目标是到一个交叉的地方即Source Task,使用Entropy Regularised 的Policy进行训练即MERL,得一个Soft Optimal Policy,该Policy尽可能的Diverse,尽可能地在完成Source Task的同时具备High-Entropy。
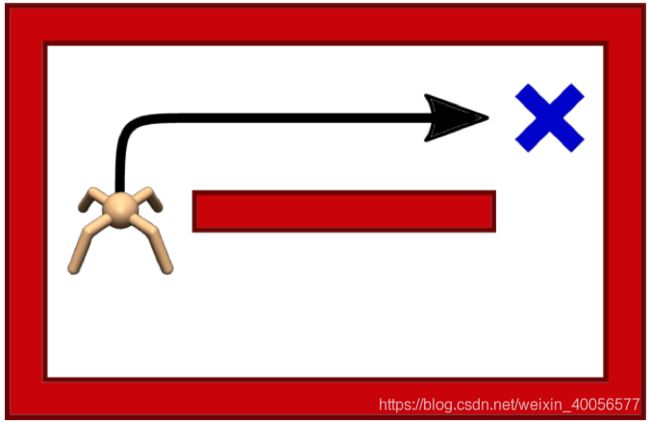
如下图,Target Task的目标同样是到一个交叉的地方,但由于环境改变了有一个block,即与Source Task的MDP不同,具体而言是Target Task的MDP中Transition dynamics model发生了改变。然后将Source Task中的Soft Optimal Policy迁移到More Restricted的Target Task中再Fine-Tune时会work,因为Soft Optimal Policy的High Entropy有机会探索到另一个solution。
如果是对于DDPG、PPO等,会因为在Source Task中探索到比较短,较为deterministic的policy(往上走)而在Target Task中走向block而reach不同任务目标。

Fine-Tune小总结:利用Soft Optimal Policy在General、Less Restrictive的Source Task上训练一个High Entropy的Soft Optimal Policy,再在Restricted、Specialized的Target Task上Fine-Tune(Fine-Tune的过程即减少Entropy的过程)
1.2.3 Randomize Source Domain
设定:Source Task可以Design,而Target Task比较难的情况下
比较适用于Sim2Real的场景,Motivation是在Source Domain中训练时看到的Diversity越多,则transfer到Target Domain后会越稳定(有点与Ensemble Learning、Adversarial Training的思想类似)
- 变动一些Stimulator中的物理参数

EPOpt: Learning Robust Neural Network Policies Using Model Ensembles 2017 ICLR - System Identification

输入一定阶段的历史信息 { x t − h , u t − h , x t − h + 1 , u t − h + 1 , ⋯ , x t − 1 , u t − 1 } \{x_{t-h},u_{t-h},x_{t-h+1},u_{t-h+1},\cdots,x_{t-1},u_{t-1}\} { xt−h,ut−h,xt−h+1,ut−h+1,⋯,xt−1,ut−1}
与当前 x t x_t xt确定系统可能的参数 u u u即(system Indentification),如质量等物理参数,再根据由policy映射得到一个动作 u t u_t ut,然后在环境中执行得到下一状态的反馈 x t + 1 x_{t+1} xt+1。具体看论文Preparing for the Unknown: Learning a Universal Policy with Online System Identification
Preparing for the Unknown: Learning a Universal Policy with Online System Identification 2017 RSS - Dynamics Randomization

MBRL中利用多个不同的Dynamics得到多个Dynamics Model,引入noise进行Randomization,再将其Combine或者Ensemble到一个Dynamics Model中,具体看论文
Sim-to-Real Transfer of Robotic Control with Dynamics Randomization 2018 ICRA - Domain Randomization

在State上进行Domain Randomization,通过CNN对Image进行处理后输出一个速度Command,将在Simulated Randomized的仿真环境中Train好Policy后,结合CNN在现实环境中进行飞行
CAD2RL: Real Single-Image Flight without a Single Real Image 2017 RSS - Manipulation Randomization

Domain randomization for transferring deep neural networks from simulation to the real world 2017 IROS
这篇文章有意思的是在于:只要你在stimulator中增加足够的variability,reality gap只不过是stimulator的另一个variant
1.2.4 Domain Adaptation
目前为止,问题的设定
- Fine-Tune针对fixed的Source Task与Target Task
- Source Domain Randomization针对Flexible的Source Task与Fixed的Target Task,从而可以Design Source Task
- Domain Adaptation则是可以获取一些Target Domain的Knowledge,将Source Domain Adapt到Target Domain
- Adapting Visuomotor Representations with Weak Pairwise Constraints 2016 CVPR

一开始的Superviesed Domain Adaptation是将Simulated Image和真实的Image进行人工配对,形成pairs of aligned image,进行有监督训练,形成Source Domain到Target Domain的一个映射。
这篇文章的Motivation就是使用Fully Unsupervised Adaptation去掉人工配对这麻烦的一步,具体而言是无监督中的minimized discrepancy,在不同domains的feature distribution中减小discrepancy,达到Weak Pairwise Constraints的样本。
批判一下:引入无监督去掉该领域中的部分人工操作(人工配对)来灌水
- GraspGAN:Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping 2018 ICRA
有点像把2016的GAIL进行Domain Randomized了一下…把GAN imitation Learning的表述变成了Domain Adaptation,稍微不同的是,GraspGAN有Randomized 抓取的对象,使给它一个新抓取对象,它也能实现抓取的效果~毕竟Diversity就给在了抓取对象上嘛,那肯定robust了,其余就是GAIL了~
1.2.5 Forward Transfer Summary
- Source Task与Target Task 都Fixed:
- 利用MERL进行finetuning
- Source Task Flexible 与 Target Task Fixed:
- Source Domain Randomization:Dynamics、Manipulation、State等等
- Source Task 与 Target Task 都 Flexible:
- Domain Adaptation:利用Target Domain的数据,结合一些方法建立Source Domain与Target Domain之间的联系
这些都是在Single Source Task的设定下,transfer到一个new Target Task上,下面这是Multi-Task Source Domain的多任务机制进行transfer了。
1.3 Multi-task Transfer
之前的Forward Transfer可总结凝练为:More Diversity = Better Transfer
现在的Multi-task Transfer则是更符合人的学习方式,可以从多种任务中习得经验,然后transfer到新任务上,但问题是
- Source Domain中的多种任务有什么是in common的?如何提炼出来?
- Source Domain的多任务与Target Domain的新任务哪些是可借鉴的Knowledge?
1.3.1 MBRL
 在MBRL的设定下,Dynamics Model是多个Source Task中共有的,而Target Domain也有,因此可以在Dynamics Model上transfer,而transfer的方式有两种,一是hope for the best,二是fine-tune or adapt
在MBRL的设定下,Dynamics Model是多个Source Task中共有的,而Target Domain也有,因此可以在Dynamics Model上transfer,而transfer的方式有两种,一是hope for the best,二是fine-tune or adapt
因此,上图是下面这篇文章的,在5个Source Task的共同点dynamics model进行transfer,直观理解类似于law of physics,是Source与Target任务共通的。
One-shot learning of manipulation skills with online dynamics adaptation and neural network priors 2016 IROS
1.3.2 Model Distillation

Model Distillation类似于Knowledge Distillation,将多个Model融合成一个Model。
具体的文章是Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning 2016 ICLR
一般有两种设定:
- 将不同task的policy融合成一个joint policy,将这个joint policy在new task上finetune or adapt
- 同一个环境,修改MDP中不同的对象,形成一个joint MDP,在独立的MDP中train一个policy,再distillation到一个joint Policy中,放到joint MDP中finetune or adapt,具体如下

所以在第一种多任务设定中,Model Distillation将多任务各自的policy融合到一个joint policy中;第二种多任务设定,则是将同一任务下,修改其MDP,将各自MDP的policy融合到一个joint policy中(开头说了一个task在RL中指一个MDP,这里术语有点混淆)
1.3.3 Contextual Policies

其实这种做法,正是lec1-lec4中的goal-conditioned的behavior cloning,只不过现在用在了RL中,称为Contextual Policies,其与上述内容最大的区别就是输入多了一个task vector即 w \mathbf w w, w 1 w_1 w1指让agent去洗碗的, w 1 w_1 w1指让agent去折叠衣服,即一个policy通过扩充输入,增加任务相关的prior vector而具备了多任务功能,这其实就很像meta-learning了,只是meta-learning稍后再介绍。

举个列子:
在(1,0,0),(0,1,0)的prior输入下的policy已经train好了,然后在(0,0,1)的输入下对new task进行Finetune~
1.3.4 Modular Policy Network


感觉通过这两幅图就挺明显的,感觉这很像Hierarchical RL,只不过此处用在了Multi-task的模块化中。
1.4 总结
Transfer Learning中还有第三大类为Meta Learning,稍后介绍,分为两类:
- RNN-based meta-learning
- Gradient-based meta-learning
总结一下:
- Transfer Learning
- Forward Transfer :Domain randomization、Doamin Adaptation、Hope For the Best
- Multi-task Transfer:Model Distillation、Dynamics Adapation、Contextual Policy、Modular Policy
- Meta Learning:在Past Tasks中学习一种Learning to learn的能力,然后在new task中adapt这种这能力
一些论文资料
-
Fine-Tune in RL:
Finetuning via MaxEnt RL: Haarnoja*, Tang*, et al. (2017). Reinforcement Learning with Deep Energy-Based Policies.
Finetuning from transferred visual features (via VAE): Higgins et al. DARLA: improving zero-shot transfer in reinforcement learning. 2017.
Pretraining with hierarchical RL methods:
Andreas et al. Modular multitask reinforcement learning with policy sketches. 2017.
Florensa et al. Stochastic neural networks for hierarchical reinforcement learning. 2017. -
Domain Randomization in RL:
Rajeswaran, et al. (2017). EPOpt: Learning Robust Neural Network Policies Using Model Ensembles.
Yu et al. (2017). Preparing for the Unknown: Learning a Universal Policy with Online System Identification.
Sadeghi & Levine. (2017). CAD2RL: Real Single Image Flight without a Single Real Image.
Tobin et al. (2017). Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World.
James et al. (2017). Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task.
Tzeng*, Devin*, et al. (2016). Adapting Deep Visuomotor Representations with Weak Pairwise Constraints.
Bousmalis et al. (2017). Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping.
Fu etal. (2016). One-Shot Learning of Manipulation Skills with Online Dynamics Adaptation and Neural Network Priors.
Rusu et al. (2016). Policy Distillation.
Parisotto et al. (2016). Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning.
Devin*, Gupta*, et al. (2017). Learning Modular Neural Network Policies for Multi-Task and Multi-Robot Transfer.
CS285的Lecture16的PPT
后记
本来应该趁热打铁,直接写一篇Meta-Learning的,但还是根据课程顺序,下一篇写Distributed RL,接着再写Meta-Learning,最后一篇是Exploration与Exploitation,然后考虑一下Multi-arm bandit problem,毕竟它跟探索与利用密切相关呢,争取在四月前写完这个,开始边看论文边跑实验= =