Python爬虫:对Uniqlo、Zara、H&M等快销品牌的门店数量作统计并展示
Python爬虫:对优衣库、Zara、H&M等快销品牌的门店数量作统计并展示
一、获取门店数量信息
(一)在百度地图搜索门店信息
- 在搜索框输入“优衣库”,并在当前页面进行审查元素,对应网址为
https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=after_baidu&pcevaname=pc4.1&qt=s&c=1&wd=%E4%BC%98%E8%A1%A3%E5%BA%93&da_src=shareurl&on_gel=1&l=5&gr=1&b=(10596830.798851967,335720.162427478;21089588.756612036,5631283.944234513)&pn=0&device_ratio=2&auth=8YyzOHwzY%40VSgKUFy2U7NE%3D3ye%40%3DFaZguxHTxHVRNxztgz%402VJtyBxwi04vy77u1GgvPUDZYOYIZuVt1cv3uVtGccZcuVtPWv3GuVtPYIuVtUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7u%40ZPuVteuVtegvcguxHTxHVRNxztpt66FcErZZWuV&tn=B_NORMAL_MAP&nn=0&u_loc=13437490,3654265&ie=utf-8&t=1591508712823
- 选择对应的包文件信息,选择NetWork -> XHR -> Preview,可查看数据信息,确定url;
- *其他的门店信息类似,在搜索框输入“Zara”、“H&M”后,复制网址链接即可;
- 也可以通过修改关键字‘wd’字段的数据内容,将文字encode转码即可;
(二)分析门店数量信息结构
- 对Preview或Response下的数据信息进行检验,可以发现如下的信息结构:
| key1 | key2 | key3 | key4 | key5 | 具体内容 | 备注 |
|---|---|---|---|---|---|---|
| content | i(0~len-1) | ’view_name‘ | “上海市” | 热门城市名称 | ||
| ’num‘ | ‘0’ | 当前城市的门店数量 | ||||
| more_city | i(0~len-1) | ’province‘ | “江苏省” | 省份名称 | ||
| ’num‘ | “93” | 当前省份包含的门店数量 | ||||
| ’city‘ | ‘i(0~len-1)’ | 字典格式 | 当前省份包含的第i个城市信息 | |||
| ’city‘ | ‘i(0~len-1’ | ’name‘ | ’苏州市‘ | 当前省份包含的第i个城市名 | ||
| ’city‘ | ‘i(0~len-1’ | ’num‘ | ’27‘ | 当前省份包含的第i个城市的门店数量 |
(三)使用csv表格存储获取的门店数量信息
- python 编码获取信息
- 使用requests、csv、json库
- 定义CreateUrls( )用于生成urls
# 定义函数用于获取数据
def CreateUrls():
urls = {
'hm': [
'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=after_baidu&pcevaname=pc4.1&qt=s&c=1&wd=h%26m&da_src=pcmappg.map&on_gel=1&l=5&gr=1&b=(10791381.798845354,3109633.7229259782;14055506.524756543,6852939.549588665)&&pn=0&auth=SV3aQL689PMv9fKZaae0D85TyFLzK5xeuxHTxNNBBNVtDpnSCE%40%40B1GgvPUDZYOYIZuVt1cv3uVtGccZcuVtPWv3Guxtdw8E62qvMuTa4AZzUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7u%40ZPuxtfvAughxehwzJVzPPDD4BvgjLLwWvrZZWuB&device_ratio=2&tn=B_NORMAL_MAP&nn=0&u_loc=13437544,3654207&ie=utf-8&t=1591773370952'],
'uniqlo': [
'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=after_baidu&pcevaname=pc4.1&qt=s&c=1&wd=%E4%BC%98%E8%A1%A3%E5%BA%93&da_src=shareurl&on_gel=1&l=6&gr=1&b=(11578857.408287704,2665277.557463113;13697860.04207616,5103892.227464317)&pn=0&device_ratio=2&auth=%3DUEDYcMwaBTBxU1yPHPXVXZ%3DD99Rx4YeuxHTxETTBzxt1qo6DF%3D%3DC1GgvPUDZYOYIZuVtcvY1SGpuBtGfyMxXwGccZcuVtPWv3GuVtPYIuVtUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7u%40ZPuVteuVtegvcguxHTxETTBzxtfiKKv7urZZWuV&tn=B_NORMAL_MAP&nn=0&u_loc=13437490,3654265&ie=utf-8&t=1591499321742'],
'zara': [
'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=after_baidu&pcevaname=pc4.1&qt=s&da_src=shareurl&wd=zara&c=1&src=0&pn=0&sug=0&l=5&b=(6822227.219999999,2174811.880000001;12458323.219999999,8638299.88)&from=webmap&biz_forward=%7B%22scaler%22:2,%22styles%22:%22pl%22%7D&device_ratio=2&auth=FY4VxWfHX6KUYU2cBRU3KdVdyF%3D%40W%3DJeuxHTxNNVHEEtDpnSCE%40%40B1GgvPUDZYOYIZuVtcvY1SGpuBtGfyMxXwGccZcuVtPWv3GuVtPYIuVtUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7u%40ZPuVteuVtegvcguxHTxNNVHEEthl44yYxrZZWuV&tn=B_NORMAL_MAP&nn=0&u_loc=13437544,3654207&ie=utf-8&t=1591770544636']
}
return urls
- 定义Crawl( url )用于获取原始json数据
# 获取网页的json数据
def Crawl(url):
headers = {
"Accept": "*/*",
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Host': 'map.baidu.com',
'Referer: https': '//map.baidu.com/search/%E4%BC%98%E8%A1%A3%E5%BA%93/@13432005.56,3644785.89,13z?querytype=s&c=224&wd=%E4%BC%98%E8%A1%A3%E5%BA%93&da_src=shareurl&on_gel=1&l=13&gr=1&b=(13401285.56,3629281.89;13462725.56,3660289.89)&pn=0&device_ratio=2',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
r = requests.get(url,headers)
return r.json()
- 定义getData(urls),用于解析数据,并返回每个城市的门店数量
def getData(urls):
# urls = ['https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=after_baidu&pcevaname=pc4.1&qt=s&c=1&wd=%E4%BC%98%E8%A1%A3%E5%BA%93&da_src=shareurl&on_gel=1&l=6&gr=1&b=(11578857.408287704,2665277.557463113;13697860.04207616,5103892.227464317)&pn=0&device_ratio=2&auth=%3DUEDYcMwaBTBxU1yPHPXVXZ%3DD99Rx4YeuxHTxETTBzxt1qo6DF%3D%3DC1GgvPUDZYOYIZuVtcvY1SGpuBtGfyMxXwGccZcuVtPWv3GuVtPYIuVtUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7u%40ZPuVteuVtegvcguxHTxETTBzxtfiKKv7urZZWuV&tn=B_NORMAL_MAP&nn=0&u_loc=13437490,3654265&ie=utf-8&t=1591499321742']
for url in urls:
currentInfo = []
moreInfo = []
data = Crawl(url)
current_province = data['current_city']['up_province_name']
current_city_info = data['content']
other_city_info = data['more_city']
for city in current_city_info:
l = []
city_name = city['view_name'][:-1]
city_num = city['num']
# print('%-12s%-10s 所包含门店数量为%4d' % (current_province, city_name, city_num))
l.append(city_name)
l.append(city_name)
l.append(city_num)
currentInfo.append(l)
for other_cities in other_city_info:
province = other_cities['province'][:-1]
cities = other_cities['city']
for city in cities:
l = []
other_city_num = city['num']
other_city_name = city['name'][:-1]
# print('%-12s%-10s 所包含门店数量为%4d' % (province, other_city_name, other_city_num))
l.append(province)
l.append(other_city_name)
l.append(other_city_num)
moreInfo.append(l)
return currentInfo,moreInfo
- 定义存储函数storeData( ),存储至csv表格文件中
def storeData(currentInfo, moreInfo):
filepath = '/Users/authorcai/Documents/Authorcai/蔡升豪的假期学习/app爬虫/百度地图门店数量爬取/data.csv'
with open(filepath,'a') as file:
writer = csv.writer(file)
rows = currentInfo+moreInfo
for row in rows:
print(row)
writer.writerow(row)
- 定义主函数main( )
def main():
# 定义字典用于存储uniqlo,zara,hm等品牌的对应url
urls = CreateUrls()
# 获取对应的url
currentInfo,moreInfo = getData(urls['hm'])
storeData(currentInfo,moreInfo,'hm')
currentInfo, moreInfo = getData(urls['uniqlo'])
storeData(currentInfo, moreInfo, 'uniqlo')
currentInfo, moreInfo = getData(urls['zara'])
storeData(currentInfo, moreInfo, 'zara')
- 数据存储结果
- uniqlo_data.csv
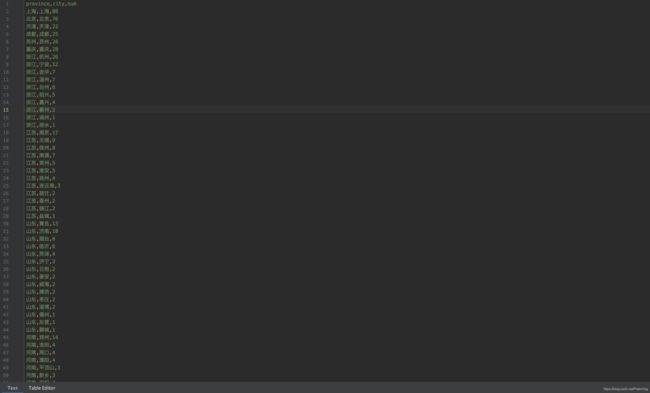
- zara_data.csv
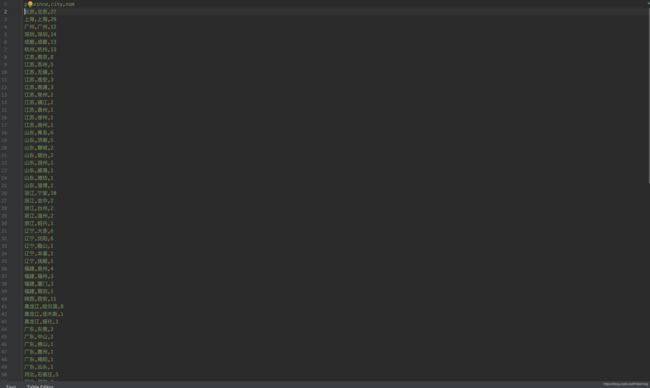
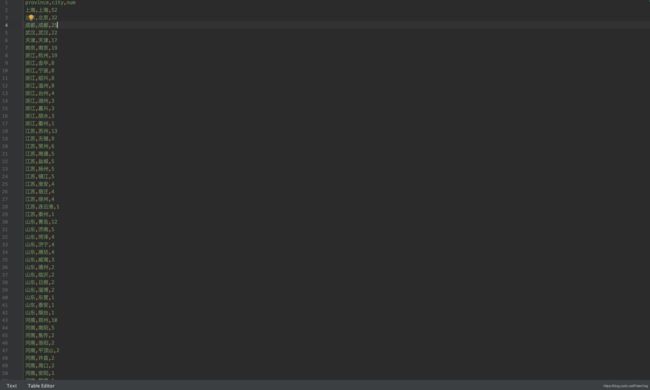
- hm_data.csv
二、使用pyecharts展示地图
(一)生成省级门店数量分布图:MapCreatorProvince
注意使用pyechaarts的时候,极可能会出现error提示,可见pyecharts官方提示对症下药:出现error解决办法
- 处理数据
# 定义dataManage()用于处理初始数据
def dataManage(filepath,type):
# 从爬虫获取的data.csv中读取'province','num'字段
ProvinceInfo = pd.read_csv(filepath,usecols=['province','num'])
# 定义直辖市字典
city_direct = ['上海','北京','重庆','天津']
# 初始化省份list,对应的数量list
provinces = []
nums = []
# 定义num字典,其中old字段存储统一的数量累加,new字段存储当前城市的数量
num = {
'old':0,
'new':0}
# 遍历DataFrame的每行,对同一省份作累加
for row in ProvinceInfo.iterrows():
num['new'] = row[1]['num']
if row[1]['province'] in provinces:
num['old'] = num ['old']+ num['new']
elif row[1]['province'] not in provinces:
if row[1]['province'] == '上海':
provinces.append(row[1]['province'])
num['old'] = num['new']
else:
provinces.append(row[1]['province'])
nums.append(num['old'])
num['old'] = num['new']
nums.append(num['old'])
# 将获取到的省份和数量转换为DataFrame
Infoes = {
'Province':provinces,'Num':nums}
Infoes = pd.DataFrame(Infoes)
# 将Infos写入到优衣库表格文件中
#Infoes.to_csv('/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data_province.csv',
# sep=',',header=True,index=True)
# 将Infos写入到zara表格文件中
Infoes.to_csv('/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/'+type+'_data_province.csv',
sep=',', header=True, index=True)
return Infoes
- 生成地图
def CreateMap(data,type):
# print(data)
province = data['Province'].to_list()
num_province = data['Num'].to_list()
length = len(province)
list_data = []
for i in range(0,length):
data = (province[i],num_province[i])
# print(data)
list_data.append(data)
print(list_data)
china_province = (
Map()
.add('', list_data, 'china')
.set_global_opts(
title_opts=opts.TitleOpts(title=type+'省级分布图'),
visualmap_opts=opts.VisualMapOpts(
min_=0,
max_=70,
is_piecewise=True)
)
.render(path='./htmls/'+type+'省级分布图.html')
)
- main( )
# 定义主函数main()
def main():
# 分别定义路径
# Uniqlo_filepath 为uniqlo_data存储路径,对应uniqlo的全国省,市数量信息
uniqlo_filepath = '/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/uniqlo_data.csv'
# Zara_filepath 为zara_data存储路径,对应uniqlo的全国省,市数量信息
zara_filepath = '/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/zara_data.csv'
# HM_filepath 为zara_data存储路径,对应uniqlo的全国省,市数量信息
hm_filepath = '/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/hm_data.csv'
# 依次调用dataManage(),获取数据
# Uniqlo_data = dataManage(uniqlo_filepath,'uniqlo')
# Zara_data = dataManage(zara_filepath,'zara')
hm_data = dataManage(hm_filepath,'hm')
# CreateMap(Uniqlo_data,'Uniqlo')
# CreateMap(Zara_data,'Zara')
CreateMap(hm_data,'hm')
- 输出结果
- uniqlo省级分布图
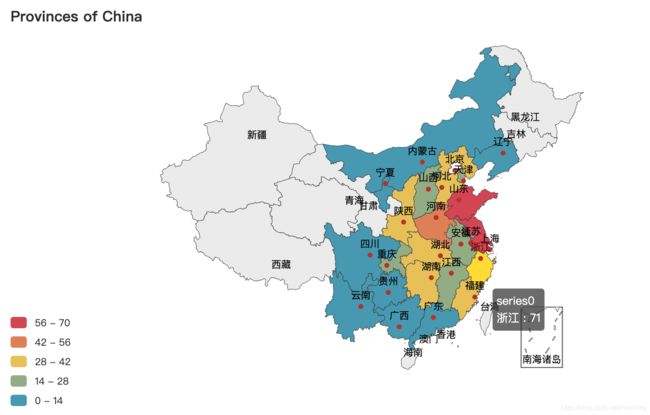
- zara省级分布图
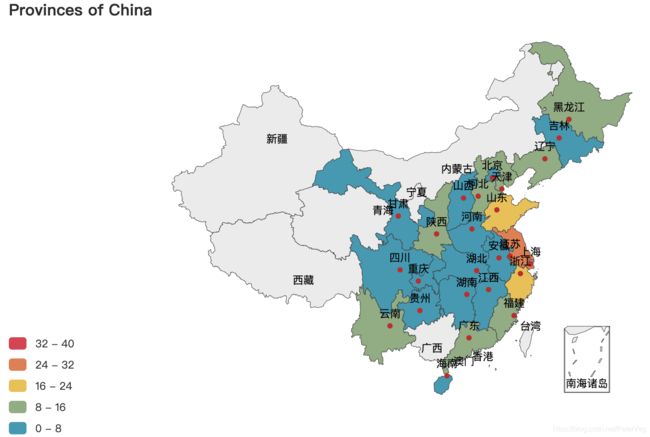
- hm省级分布图
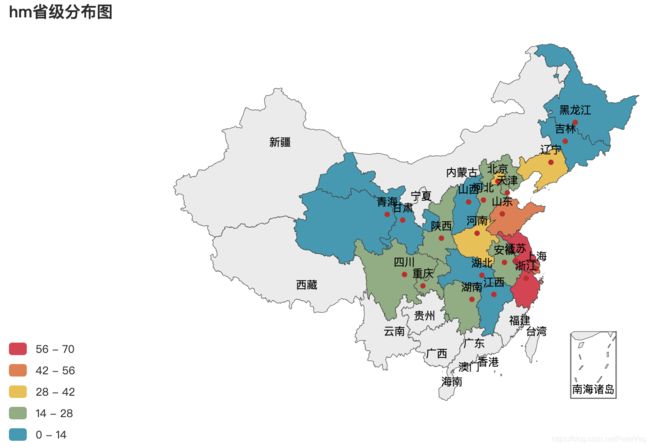
(二)生成市级门店数量分布图:MapCreatorCities
- 处理数据
def dataManage(filepath,type):
# 从爬虫获取的data.csv中读取'province','num'字段
CityInfo = pd.read_csv(filepath, usecols=['city', 'num'])
all_city = []
nums = []
# 定义num字典,其中old字段存储统一的数量累加,new字段存储当前城市的数量
num = 0
# 遍历DataFrame的每行,统计城市的num
for row in CityInfo.iterrows():
num = row[1]['num']
all_city.append(row[1]['city'])
nums.append(num)
# 将获取到的省份和数量转换为DataFrame
Infoes = {
'Cities': all_city, 'Num': nums}
Infoes = pd.DataFrame(Infoes)
# 将Infos写入到表格文件中
Infoes.to_csv('/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/'+type+'_data_cities.csv',
sep=',', header=True, index=True)
return Infoes
- 生成分布图
def CreateMap(data,type):
# print(data)
cities = data['Cities'].to_list()
num_province = data['Num'].to_list()
length = len(cities)
list_data = []
for i in range(0,length):
data = (cities[i],num_province[i])
# print(data)
list_data.append(data)
print(list_data)
china_city = (
Map()
.add(
"",
list_data,
"china-cities",
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title=type+'地级市分布图'),
visualmap_opts=opts.VisualMapOpts(
min_=0,
max_=20,
is_piecewise=True
),
)
.render(path='./htmls/'+type+'地级市分布图.html')
)
- main()
def main():
# 分别定义路径
# Uniqlo_filepath 为uniqlo_data存储路径,对应uniqlo的全国省,市数量信息
uniqlo_filepath = '/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/uniqlo_data.csv'
# Zara_filepath 为zara_data存储路径,对应uniqlo的全国省,市数量信息
zara_filepath = '/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/zara_data.csv'
# HM_filepath 为zara_data存储路径,对应uniqlo的全国省,市数量信息
hm_filepath = '/Users/authorcai/Documents/Authorcai/CSH/Spider/BaiduMap_Spider/data/hm_data.csv'
# 依次调用dataManage(),获取数据
# Uniqlo_data = dataManage(uniqlo_filepath,'uniqlo')
# Zara_data = dataManage(zara_filepath,'zara')
hm_data = dataManage(hm_filepath,'hm')
# CreateMap(Uniqlo_data,'Uniqlo')
# CreateMap(Zara_data,'Zara')
CreateMap(hm_data, 'hm')
- 输出结果
- uniqlo市级分布图
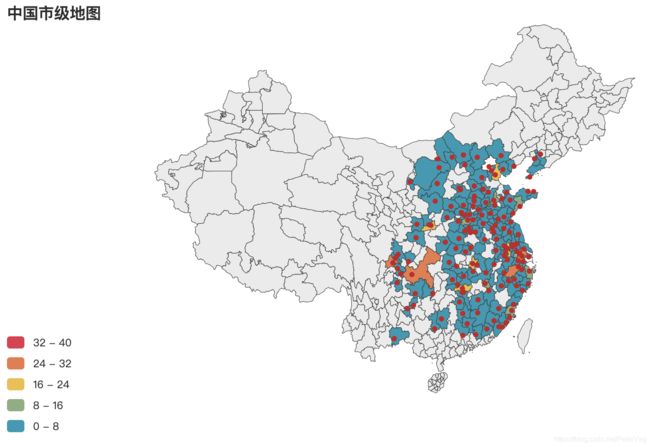
- zara市级分布图
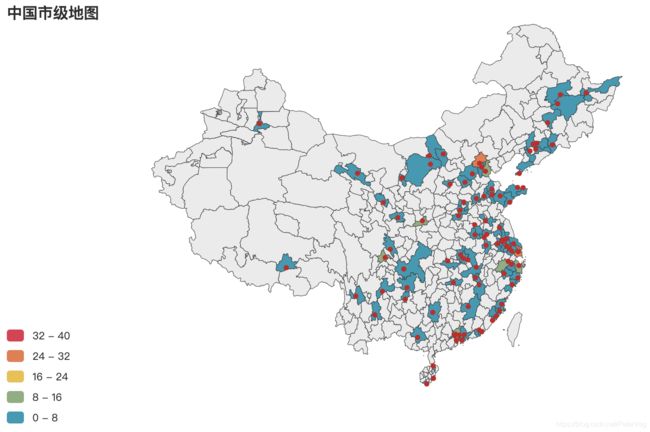
- hm市级分布图
