接口自动化-get/post接口详解
一、 Get接口详解
1. Get请求的基本用法
做接口自动化的一般都是前后端分离的,返回json体,几乎没有返回结果是HTML的,会很复杂。
格式:requests.gett(url,data/json,headers,其他)
说明:
| 参数 | 说明 |
|---|---|
| url | 必填,有3种写法,下面会有详解 |
| data | 传入参数是表单类型(x-www-form)时使用,传入请求数据 |
| json | 传入参数是json类型,即content-type为application/json时使用,传入请求数据 |
| headers | 传入cookie,需要使用cookie时使用 |
| 其他 | 比如可传入超时时间:timeout=30 |
注意:
- get请求参数原则上都是包含在url里的,但是可以灵活处理,将请求参数和url分别传入
- 请求响应的结果一般都需要使用.json方法,将响应的文本内容按照json化处理,在Python中被处理成了一个字典类型
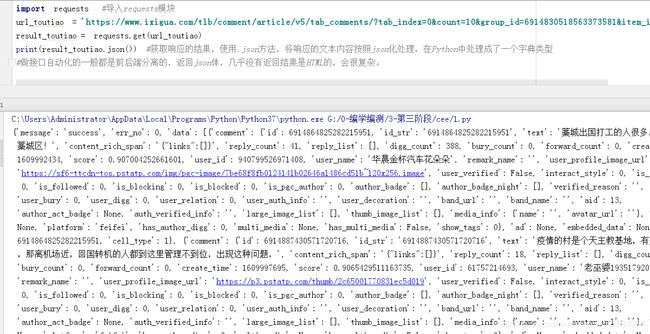
import requests #导入requests模块
url_toutiao = 'https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768'
result_toutiao = requests.get(url_toutiao)
print(result_toutiao.json())
#获取响应的结果,使用.json方法,将响应的文本内容按照json化处理,在Python中处理成了一个字典类型
2. get请求的3种写法
#get请求的写法1:标准写法
result_toutiao = requests.get(url = url_toutiao)
#get请求的写法2:直接跟变量
result_toutiao = requests.get(url_toutiao)
#get请求的写法3:直接跟URL,但一般不建议这样写
result_toutiao = requests.get('https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768')
3. 定制请求头
- 定制请求头:传cookie、content-type等
- 自定义一个字典,再传给headers参数即可
#定制请求头:传cookie、content-type等
#自定义一个字典,再传给headers参数即可
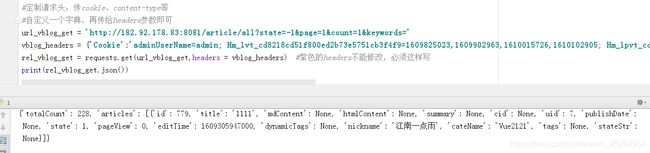
url_vblog_get = 'http://182.92.178.83:8081/article/all?state=-1&page=1&count=1&keywords='
#自定义一个字典
vblog_headers = {
'Cookie':'adminUserName=admin; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609825023,1609902963,1610015726,1610102905; Hm_lpvt_cd8218cd51f800ed2b73e5751cb3f4f9=1610103196; SESSION=ZDBkYmRmOWQtODQ5Zi00ZjdjLTg3ZDgtZTIxYmI5Y2U4OTkz; JSESSIONID=67921EF59A8808D21AC6E421EDC7061F'}
rel_vblog_get = requests.get(url_vblog_get,headers = vblog_headers) #前面的headers不能修改,必须这样写
print(rel_vblog_get.json())
4. 请求参数拆分
将get请求参数不放在url里,单独拿出来做处理,使用起来会更灵活
url_vblog_get = 'http://182.92.178.83:8081/article/all'
vblog_headers = {
'Cookie':'adminUserName=admin; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609825023,1609902963,1610015726,1610102905; Hm_lpvt_cd8218cd51f800ed2b73e5751cb3f4f9=1610103196; SESSION=ZDBkYmRmOWQtODQ5Zi00ZjdjLTg3ZDgtZTIxYmI5Y2U4OTkz; JSESSIONID=67921EF59A8808D21AC6E421EDC7061F'}
#将URL问号后面的参数传到自定义字典中
payload = {
'state':'-1','page':'1','count':'6','keywords':'江南'}
rel_vblog_get = requests.get(url_vblog_get,headers = vblog_headers,params = payload)
print(rel_vblog_get.json())
print(rel_vblog_get.url) #查看当前访问的URL

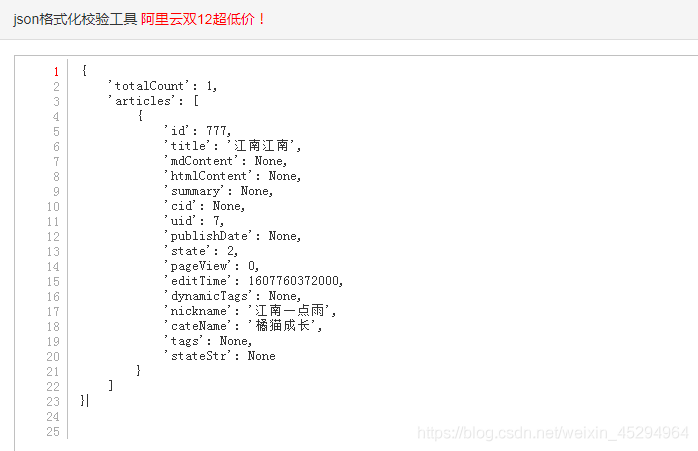
运行结果转换为json格式后:
个人认为比较好用的json格式化工具:http://www.ab173.com/json/
5. payload的灵活运用
#payload的灵活运用
url_vblog_get = 'http://182.92.178.83:8081/article/all'
vblog_headers = {
'Cookie':'adminUserName=admin; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609825023,1609902963,1610015726,1610102905; Hm_lpvt_cd8218cd51f800ed2b73e5751cb3f4f9=1610103196; SESSION=ZDBkYmRmOWQtODQ5Zi00ZjdjLTg3ZDgtZTIxYmI5Y2U4OTkz; JSESSIONID=67921EF59A8808D21AC6E421EDC7061F'}
#将URL问号后面的参数传到自定义字典中
payload = {
'state':'-1','page':'1','count':'6','keywords':'江南'}
keys = ['大','刀','江南']
for key in keys:
payload['keywords']=key
payload['page'] = '1' #展示第1页
payload['count'] = '2' #每页展示2个数量
rel_vblog_get = requests.get(url_vblog_get,headers = vblog_headers,params=payload)
print(rel_vblog_get.json())
print(rel_vblog_get.url)
6. 超时
应用场景:接口发送出去后到底有没有响应
如果不设置超时,会出现的问题:如果后端不给响应,接口就会一直请求,程序会一直等待。
设置超时的方法:
- 超时设置:timeout,单位是秒,一般设置为30秒,30秒后如果还没有响应,就报超时。或重试3次,每次30秒还是没有响应,就不会再请求。
- 超时是对程序的一个保护机制,避免一直请求无响应,让程序更加健壮
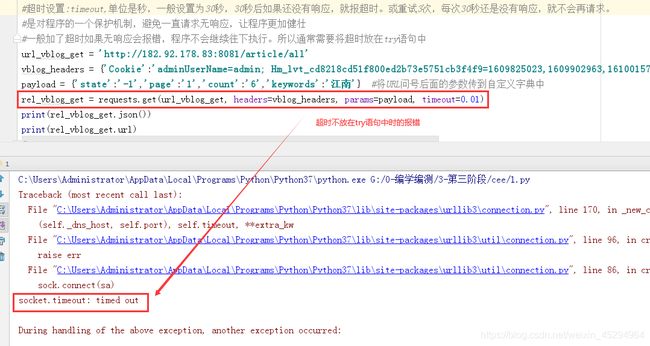
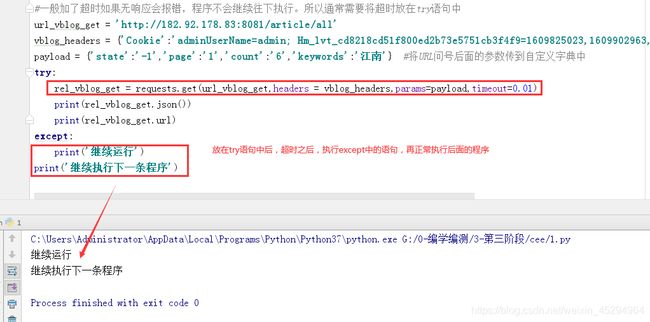
- 一般加了超时如果无响应会报错,程序不会继续往下执行。所以通常需要将超时放在try语句中
try:
rel_vblog_get = requests.get(url_vblog_get,headers = vblog_headers,params=payload,timeout=1)
except:
print('继续运行')
7. 各属性获取
| 获取属性 | 方法 |
|---|---|
| 获取url地址 | .url |
| 获取服务器响应的内容 | .text |
| 获取编码格式 | .encoding |
| 获取json格式 | .json() |
| 获取响应状态码 | .status_code |
| 获取cookie | .cookies |
url_vblog_get = 'http://182.92.178.83:8081/article/all'
vblog_headers = {
'Cookie':'adminUserName=admin; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609825023,1609902963,1610015726,1610102905; JSESSIONID=0DBC5567722FDBC3723824B22C1BFAD4'}
payload = {
'state':'-1','page':'1','count':'6','keywords':'江南'} #将URL问号后面的参数传到自定义字典中
rel_vblog_get = requests.get(url_vblog_get,headers = vblog_headers,params=payload,timeout=1)
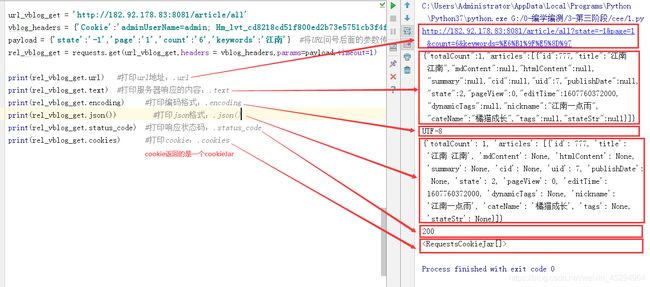
print(rel_vblog_get.url) #打印url地址:.url
print(rel_vblog_get.text) #打印服务器响应的内容:.text
print(rel_vblog_get.encoding) #打印编码格式:.encoding
print(rel_vblog_get.json()) #打印json格式:.json()
print(rel_vblog_get.status_code) #打印响应状态码:.status_code
print(rel_vblog_get.cookies) #打印cookie:.cookies
二、 Post接口详解
1. Post请求的基本用法
格式:requests.post(url,data/json,headers,其他)
说明:
| 参数 | 说明 |
|---|---|
| url | 必填,有3种写法,同get一样 |
| data | 传入参数是表单类型(x-www-form)时使用,传入请求数据 |
| json | 传入参数是json类型,即content-type为application/json时使用,传入请求数据 |
| headers | 传入cookie,需要使用cookie时使用 |
| 其他 | 比如可传入超时时间:timeout=30 |
import requests
#post请求
url = 'http://182.92.178.83:8081/login'
#传入的参数需要处理成字典类型
data_post={
'username':'sang','password':'123'}
#传入的参数是表单类型(x-www-form)的,使用data;传入的参数是json类型,使用json
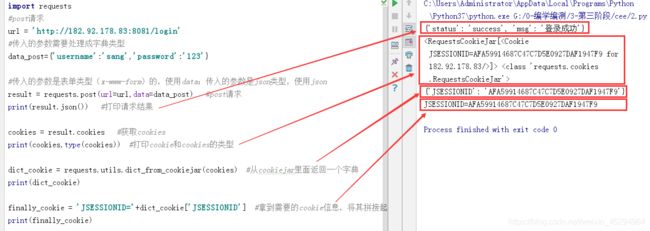
result = requests.post(url=url,data=data_post) #post请求
print(result.json()) #打印请求结果
2. 获取cookie
获取cookie的思路:
(1)使用.cookies获取到cookie jar
(2)使用requests.utils.dict_from_cookiejar(cookies)从cookie jar中获取到cookie的字典形式
(3)进行拼接,得到我们传入的cookie形式
cookies = result.cookies #获取cookies
print(cookies,type(cookies)) #打印cookie和cookies的类型
dict_cookie = requests.utils.dict_from_cookiejar(cookies) #从cookiejar里面返回一个字典
print(dict_cookie)
finally_cookie = 'JSESSIONID='+dict_cookie['JSESSIONID'] #拿到需要的cookie信息,将其拼接起来
print(finally_cookie) #这个cookie在后续的操作中都可以调用
3. 模块封装
- 封装的模块
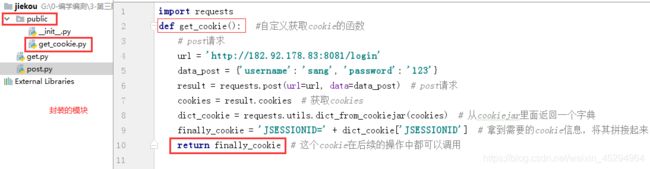
一般会将较长使用的模块作为公共模块封装起来,比如获取cookie
import requests
def get_cookie(): #自定义获取cookie的函数
# post请求
url = 'http://182.92.178.83:8081/login'
data_post = {
'username': 'sang', 'password': '123'}
result = requests.post(url=url, data=data_post) # post请求
cookies = result.cookies # 获取cookies
dict_cookie = requests.utils.dict_from_cookiejar(cookies) # 从cookiejar里返回一个字典
finally_cookie = 'JSESSIONID=' + dict_cookie['JSESSIONID'] # 拿到需要的cookie信息 return finally_cookie # 这个cookie在后续的操作中都可以调用
- 函数调用
函数调用之前需要导入该函数,导入后即可直接调用
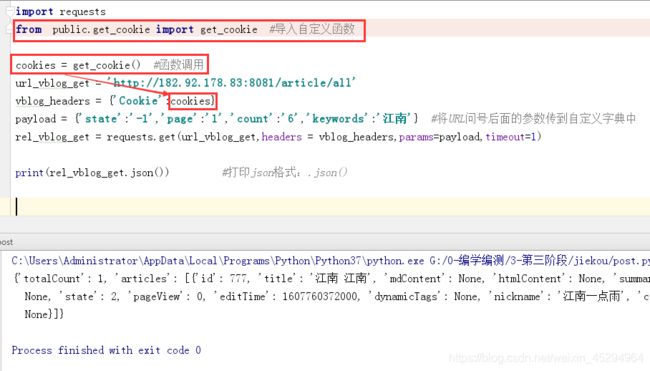
import requests
from public.get_cookie import get_cookie #导入自定义函数
cookies = get_cookie() #函数调用
url_vblog_get = 'http://182.92.178.83:8081/article/all'
vblog_headers = {
'Cookie':cookies}
payload = {
'state':'-1','page':'1','count':'6','keywords':'江南'}
rel_vblog_get = requests.get(url_vblog_get,headers = vblog_headers,params=payload,timeout=1)
print(rel_vblog_get.json()) #打印json格式:.json()
4. 批量获取cookie脚本
Jmeter里面模拟不了提交试卷(提交试卷是不可能要先登录一下再去提交,单测提交试卷接口和登录没有任何关系),而在jmeter里面为了实现批量提交试卷,先进行了登录,这是jmeter不足的一个地方。
如何解决?可以通过写脚本的方式:
批量获取cookie的思路:
(1)准备工作:准备一个用户信息文件,最好是CSV格式,里面放有批量的用户信息,比如100个用户名和密码
(2)初始化操作:以覆盖写(w)的方式,打开一个csv文件,写入一个空字符串。
- 这个文件是后面用来写入cookie信息的。由于cookie一直都在变化,我们每次都需要获取最新的cookie信息,所以在写入cookie前需要保证文件已被清空。
- 此处还可以使用删除的方式,方法多样。
- 打开文件的路径可以使用相对路径,也可以使用绝对路径,相对路径中,两个点(. .)是返回上级的意思
(3)读取预先准备好的用户信息文件,获得批量的用户名和密码
- 由于用户信息本身就有换行,需要使用.strip去掉首位的空格及换行符,输出结果为一个字符串
- 使用.split将字符串分割成一个列表,由于CSV文件是按逗号隔开的,故此处以逗号作为分割线
- 获取列表中的元素,按下标取即可得到我们想要的用户名和密码
(4)调用获取cookie的函数,得到批量的cookie
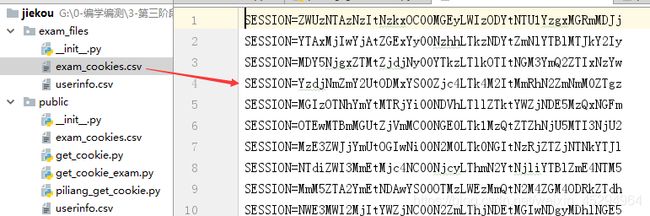
(5)将获取到的批量cookie以追加写(a)的方式写入步骤2中已被清空的文件
- 此处如果使用覆盖写(w),最后只会有最后一行的cookie
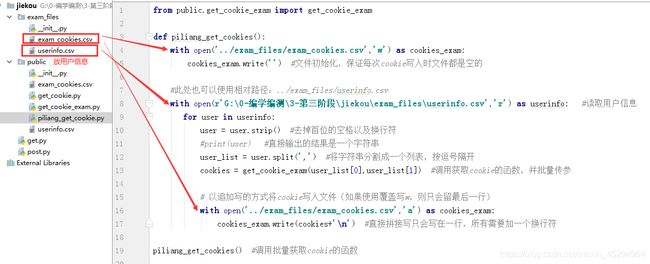
from public.get_cookie_exam import get_cookie_exam
def piliang_get_cookies():
with open('../exam_files/exam_cookies.csv','w') as cookies_exam:
cookies_exam.write('') #文件初始化,保证每次cookie写入时文件都是空的
#此处也可以使用相对路径:../exam_files/userinfo.csv
#读取用户信息
with open(r'G:\0-编学编测\3-第三阶段\jiekou\exam_files\userinfo.csv','r') as userinfo: for user in userinfo:
user = user.strip() #去掉首位的空格以及换行符
#print(user) #直接输出的结果是一个字符串
user_list = user.split(',') #将字符串分割成一个列表,按逗号隔开
cookies = get_cookie_exam(user_list[0],user_list[1]) #调用获取cookie的函数,并批量传参
#print(cookies) #批量生成cookie
with open('../exam_files/exam_cookies.csv','a') as cookies_exam: #以追加写的方式将cookie写入文件(如果使用覆盖写w,则只会留最后一行)
cookies_exam.write(cookies+'\n') #直接拼接写只会写在一行,所有需要加一个换行符
piliang_get_cookies() #调用批量获取cookie的函数
- 生成的新cookie
5. Post+put+delete
每一次增(post)、删(delete)、改(put)之后都会查(get)一下



import requests
from public.get_cookie import get_cookie
url = 'http://182.92.178.83:8081/admin/category/'
payload_select = {
'cateName':'requests0110'}
cookies=get_cookie() #调用get_cookie函数
vblog_headers = {
'Cookie':cookies}
#post:新增
rel_select_catename = requests.post(url,data=payload_select,headers = vblog_headers)
#表单类型,使用data
print(rel_select_catename.json())
#put:编辑
payload_update={
'id':'56','cateName':'request011001'}
rel_update_catename = requests.put(url,data=payload_update,headers=vblog_headers)
print(rel_update_catename.json())
#delete:删除,删除没有参数
url_delete_catename = 'http://182.92.178.83:8081/admin/category/56'
rel_delete_catename = requests.delete(url,headers = vblog_headers)
print(rel_delete_catename.json())
