python3网络爬虫--爬取b站视频评论用户信息(附源码)
文章目录
- 一.准备工作
-
- 1.工具
- 二.思路
-
- 1.整体思路
- 2.爬虫思路
- 三.分析网页
-
- 1.分析网页加载方式
- 2.分析数据接口
- 3.获取oid
- 四.撰写爬虫
- 五.存储数据
- 六.总结
最近马保国老师在b站挺火的,关于他的视频播放量很高,b站视频评论区都是人才说话好听,写个爬虫爬取一下b站评论区用户信息和评论内容。
一.准备工作
1.工具
(1)Chrome 谷歌浏览器 安装地址:https://www.google.cn/chrome/ (插件:json-handle 下载地址:http://jsonhandle.sinaapp.com/,json-handle安装方法:
https://blog.csdn.net/xb12369/article/details/79002208
用于分析网页结构
(2)python 3.x 安装地址:https://www.python.org/ 用于编写代码,开发工具:JetBrains PyCharm Professional下载地址:https://www.jetbrains.com/pycharm/
(3)Mongodb 数据库存储数据 安装地址:https://www.mongodb.com/try/download/community, 数据库可视化工具MongoDB Compass 用于动态管理数据库,安装教程详见:
https://blog.csdn.net/weixin_41466575/article/details/105326230
二.思路
1.整体思路
2.爬虫思路
三.分析网页
要想写好爬虫,一定要先把网页结构分析透彻。
1.分析网页加载方式
我们要爬取用户信息和评论,所以先打开一个视频。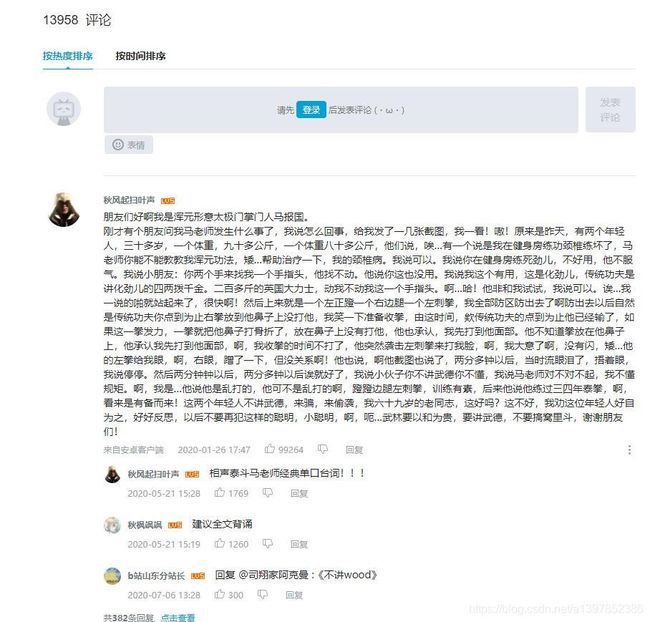
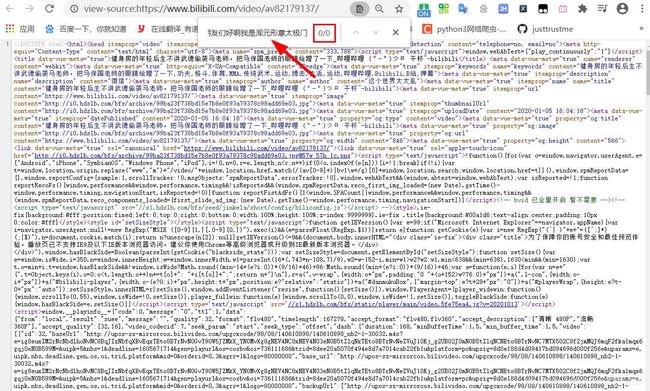
鼠标右击 查看源代码 ,在源代码中搜索相关评论内容,并没有找到相关数据,可以判断此页面为ajax异步加载数据渲染出来的。
2.分析数据接口
回到视频页面F12打开开发者工具,刷新一下,ctrl+f搜索一下,发现评论数据都在这个json中。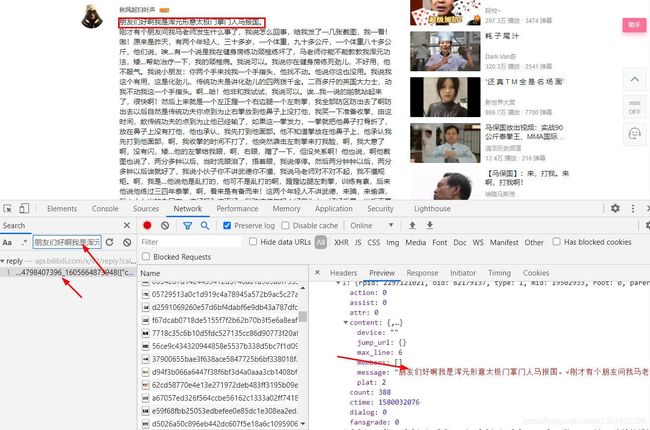
这个json指向了下面这个地址:
https://api.bilibili.com/x/v2/reply?callback=jQuery1720631904798407396_1605664873948&jsonp=jsonp&pn=1&type=1&oid=82179137&sort=2&_=1605664874976
使用jsonhandle查看这个json可以看到用户信息在member里,评论信息在message里。
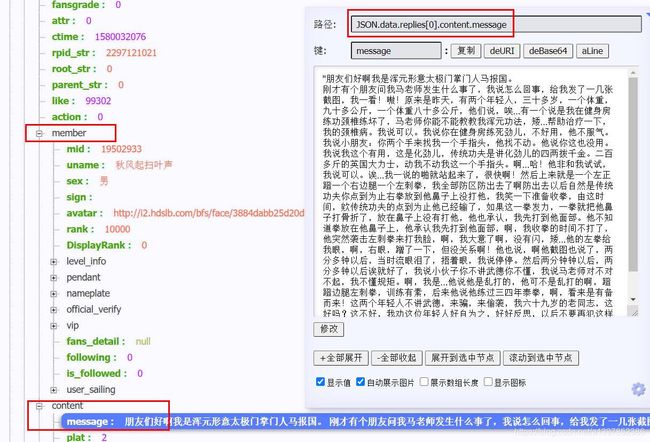
回到这个接口,此接口需要传以下参数:
callback: jQuery1720631904798407396_1605664873948 #经测试可以不传
jsonp: jsonp #经测试可以不传
pn: 1 #页码标识
type: 1 #所属类型
oid: 82179137 #视频标识
sort: 2 #所属分类
_: 1605664874976 #当前时间戳,经测试可以不传
通过分析发现关键参数为oid和pn,sort,个人猜测oid为视频标识,pn为评论所在页数,sort为类别,我们要获取到oid。
3.获取oid
尝试在视频网页源代码中搜索oid。
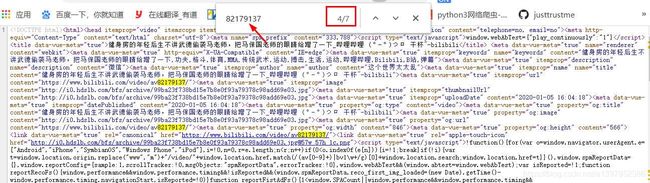
检索到了7个相关,那就好办了,我们先请求视频网页获取oid,再通过oid去构造加载接口。
这样我们就把视频评论信息加载方式、加载接口搞清楚了,可以去撰写爬虫了。
四.撰写爬虫
废话不说,直接上源码
import json
import requests
import pymongo
import re
import time
import random
class Bilibili_Comment_Parse(object):
#设置参数,数据根据视频标题不同存在不同的集合中,所有集合存在Bilibili库中
def set_page(self):
host='127.0.0.1'
port=27017
myclient=pymongo.MongoClient(host=host,port=port)
mydb='Bilibili'
sheetname=self.video_title
db=myclient[mydb]
self.post=db[sheetname]
#根据输入的网址获取oid和视频标题
def get_oid(self,url):
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
r = requests.get(url,headers=headers)
res = r.text
patten = ''
oid = re.findall(patten, res)
aim_oid = oid[0]
patten1=''
video_title=re.findall(patten1,res)
if video_title:
self.video_title=video_title[0].split('_哔哩哔哩')[0]
return aim_oid
#爬虫主程序,用于解析视频评论用户信息
def parse(self,oid):
base_url=f'https://api.bilibili.com/x/v2/reply?jsonp=jsonp&type=1&oid={oid}&sort=2'
n=0
url=base_url+'&pn={}'
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
try:
while True:
r=requests.get(url.format(n),headers=headers)
_json=json.loads(r.text)
replies=_json.get('data').get('replies')
item={
}
n+=1
if len(replies)!=0:
print(f'\033[34;47m--------------------正在爬取{n}页--------------------')
for replie in replies:
item['user_id']=replie.get('member').get('mid')#用户id
item['user_name']=replie.get('member').get('uname')#用户名
item['user_sex']=replie.get('member').get('sex')#性别
item['user_level']=replie.get('member').get('level_info').get('current_level')#等级
vip=replie.get('member').get('vip').get('vipStatus')#是否vip
if vip==1:
item['user_is_vip']='Y'
elif vip==0 :
item['user_is_vip']='N'
comment_date=replie.get('member').get('ctime')#评论日期
timeArray = time.localtime(comment_date)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
item['apprecate_count']=replie.get('like')#点赞数
item['reply_count']=replie.get('rcount')#回复数
item['comment_date']=otherStyleTime
item['comment']=replie.get('content').get('message')#评论内容
#判断数据库中有无此文档,也可用于断点续
res=self.post.count_documents(item)
if res==0:
data = dict(item)
self.post.insert(data)
print(f'\033[35;46m{item}\033[0m')
else:
print('\033[31;44m pass\033[0m')
time.sleep(0.5)
else:
print(f'\033[31;44m--------------------程序在第{n}页正常退出!--------------------\033[0m')
break
except:
pass
def main():
while True:
type = input('请输入视频地址:')
#使用正则表达式进行简单过滤
patten1 = re.compile(r'^(?:http|https)?://(\S)*')
flag= re.findall(patten1, type)
if flag:
try:
bilibili_parse=Bilibili_Comment_Parse()
oid =bilibili_parse.get_oid(type)
bilibili_parse.set_page()
bilibili_parse.parse(oid)
break
except:
print('\033[35;49m您输入信息有误!请检查!\033[0m')
else:
print('\033[35;49m您输入信息有误!请检查!\033[0m')
if __name__ == '__main__':
main()
这里要说一下,开始我用正则判断了一下输入内容,而且我并没有将api所有参数都传过去,像_这样的时间戳可以用time.time()去构造,用户信息的话,可以按需去抽取。
控制台一直在输出数据,直到结束。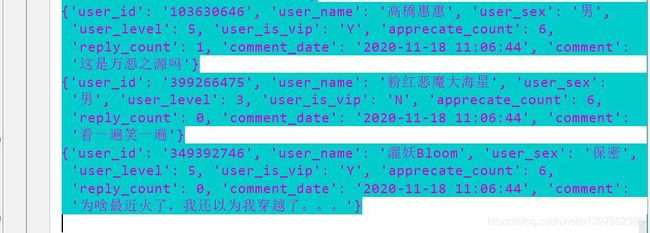
五.存储数据
数据存储,我选择mongodb数据库,您可以自行选择存储方式。
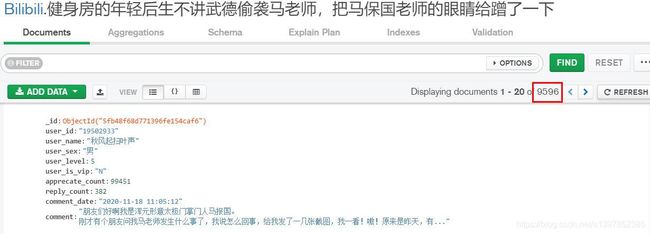
一共九千多条,您可自行选择导出数据为json或者csv格式。
六.总结
- 本次爬取的是b站视频评论用户信息和评论数据,不只适用于马老师这个视频,是通用的。b站对ip访问频率有限制,所以保险起见,加入了限速,此爬虫的重点在于寻找评论api接口,url构造完成以后数据抽取就简单容易了,一共九千多条数据,而视频下面显示1w3K多条应该是包含回复。思路、代码方面有什么不足欢迎各位大佬指正、批评!