Python模拟二维码登录百度
模拟二维码登录百度
-
- 写在前面
- 准备工作
-
- 二维码地址
- 登录状态
- 获取gid
- 登录参数
- 代码部分
-
- 二维码展示
- 获取cookie
- 完整代码
- 写在后面
写在前面
前段时间写了利用BDUSS到达百度首页,这一次尝试使用二维码模拟登录,目前网上能搜到的相关内容基本失效了,但是思路基本不变,无非是百度改了些参数。本文较为复杂,要求对python的requests模块以及Chrome审查元素有一定了解,我不确定自己是否能完全讲明白,讲多少是多少吧,各位看官请坐。
准备工作
二维码地址
打开Chrome浏览器,清理掉baidu.com下的所有cookie,如果没有则忽略。打开百度首页,F12审查元素,在右上角点击登录,切换到二维码登录,可以看到NetWork里面出现了一些相关内容:

查看getqrcode?lp=pc:

这里的imgurl代表二维码地址,在浏览器访问一下就能看到二维码,为了获得该地址,我们需要向该条目的Request URL发起请求:
https://passport.baidu.com/v2/api/getqrcode?lp=pc&qrloginfrom=pc
有些小伙伴可能看到Request URL包含有gid、callback等参数,这里并不需要,访问上面的地址就能获得imgurl。
登录状态
让页面停滞一会儿,可以看到出现了好多unicast开头的请求,就是用来验证二维码扫描状态的。

未扫描时response如下:
tangram_guid_1607686170040({"errno":1})
先分析一下需要的参数:

channel_id是不是看起来很熟悉?就是imgurl里面的sign,这个参数就搞定了。刷新几次页面,可以看到gid、callback、tt、_这四个参数发生了变化,仔细观察可以发现后面两个是毫秒级时间戳,callback变化的只有后面那串数字,也是毫秒级时间戳,gid等下再说。观察多个unicast请求,发现gid、callback是不变的,可以确定callback是一个默认字符串加上第一次unicast请求的时间戳,另外两项则是新的unicast请求发生时的时间戳。对比相邻的unicast的tt参数,相减得到的数值接近30000,即30s,再细心观察,新的unicast出现时是一个unsafe-url:

过30s左右会变成正常的Get请求,在浏览器直接访问Request URL也是在30s后得到Response(真的不是你断网了…),也就是说,二维码未被扫描的时候,每30s验证一次状态(二维码被扫描,未点击确定的时候会重新设定等待时间,也许是5s),这样的话,在使用requests发送请求时要将timeout设置为30s以上,不然无法正确验证状态。
获取gid
这个参数在getqrcode?lp=pc请求中就已经出现了,首先查看该请求调用的js文件:

打开setChannel对应的js,单击左下角的花括号可以让格式化输出,按Ctrl+F搜索“gid”,可以看到指向了guideRandom,再搜索guideRandom,得到如下信息:

需要将其转换为python代码:
#获取gid
def guideRandom():
string = 'xxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'
gid = ''
#下面是根据JavaScript代码写的
for z in string:
#获取0到1的随机数,并乘以16
t = 16 * random.random()
#如果是z是x或者y
if z in "xy":
#hex将数字转换为十六进制,后面的你肯定能读懂
s = hex(int(t)) if z == "x" else hex(3 & int(t) | 8)
#将十六进制数转换为字符串,删除前面0x
gid += str(s).replace('0x','')
else:
#不是x或y则不做处理
gid += z
#将字符串转换为大写,返回
return gid.upper()
另外关于callback的函数,可以在‘uni_loginv4_tangram_b55ba1e.js’中搜索‘callback’:

baidu.id.key是“tangram_guid”,m是时间戳加1,与上面的猜测差不多。
检测二维码扫描状态的参数分析完毕。
登录参数
用百度的app扫描二维码,但不要点确定,可以发现unicast的Response变了:

errno变为0,而且获取到channel_id,跟imgurl中的sign一致(我这里跟上面不一样是因为刷新了页面),还有一个status,不出意外的话,这个是用来判断用户是否点击确定的,app点击确定,再查看unicast的Response:

可以看到status变为0,而且多了个参数"v",这个有什么用处呢?先放着不管,去看下面这个包:
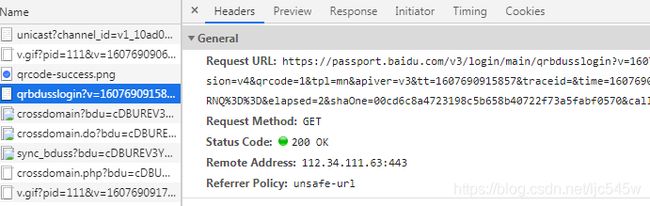
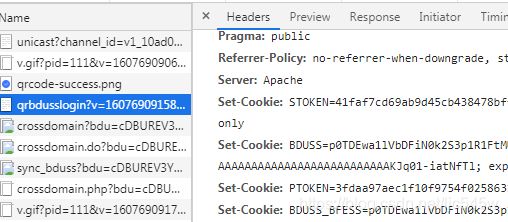
这里设置了BDUSS、PTOKEN、STOKEN三个cookie,这些就是登录成功的标志,带上这三个cookie可以访问百度的大多数产品。再看看需要的参数:
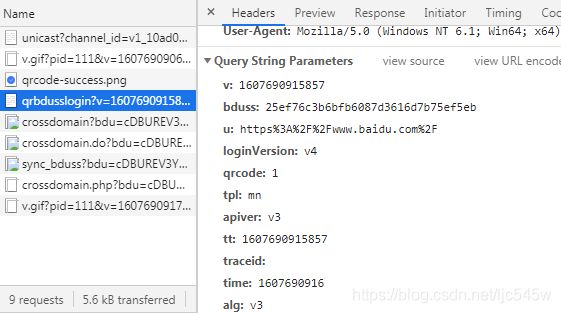
bduss是不是有点眼熟?没错,就是刚才unicast返回的v,而且只有这个参数比较重要,别的要么是时间戳或固定值,就算有几个是变化的(sig、shaOne、callback等),用固定值也没有什么影响。OK,参数解析完毕。
如果跳转太快抓不到包的话,在开发者工具里面:

将网络模式改为Slow 3G(手速比网速快的可以不改),调整完毕再点击客户端上的确定,Response发生变化时快速点击左上角的小红点停止继续抓包,就不会因为刷新页面丢失抓到的包。
代码部分
代码分为两部分,第一部分是二维码的获取及展示,第二部分是获取cookie。
二维码展示
#将关于二维码的部分封装成类
class Show(object):
def __init__(self,imgurl):
#创建一个子线程,用于展示二维码
#如果不创建子线程,在二维码关闭之前程序停滞
self.t = threading.Thread(target = self.get_img)
#将线程设置为后台运行
self.t.setDaemon(True)
#二维码的网页地址
self.imgurl = imgurl
def get_img(self):
#访问imgurl,将二维码保存到本地
res = requests.get(url = self.imgurl,headers = headers)
f = open('baidu.jpg','wb')
f.write(res.content)
f.close()
#暂停1秒,不然加载的二维码可能比较模糊
time.sleep(1)
#Pillow读取二维码
img = Image.open('baidu.jpg')
#在窗口中显示(此时并没有真的显示,因为子线程还没有启动)
img.show()
#调用此函数的是python子线程,展示图片的是一个windows进程
#使用psutil获取进程句柄,我们可以在合适的时候将该进程关掉
for proc in psutil.process_iter():
#前者是win10的照片查看器,后者是win7的
#如果你的图片默认程序不是照片查看器,那么此处需要修改
#获取方式:打开任意一张图片,任务管理器-性能-资源监视器
if proc.name() in ['Microsoft.Photos.exe','dllhost.exe']:
self.proc = proc
break
#启动子线程
def show(self):
self.t.start()
#关闭二维码进程
def close(self):
self.proc.kill()
获取cookie
class Login(object):
#初始化变量
def __init__(self,login_params,check_params,show):
#Show对象,控制二维码展示和关闭
self.show = show
#检查二维码扫描状态的URL
self.check_url = 'https://passport.baidu.com/channel/unicast'
#获取BDUSS等cookie的URL
self.login_url = 'https://passport.baidu.com/v3/login/main/qrbdusslogin'
#login_url的参数
self.login_params = login_params
#check_url的参数
self.check_params = check_params
#检查二维码扫描状态
def check_status(self):
#启动子线程在窗口展示二维码
self.show.show()
#将errno和status设定为1
errno = 1
status = 1
#用于在while循环中关闭windows照片查看器
flag = True
#unicast的response不是标准json格式,需要进行正则匹配
pattern = re.compile('({.*})')
#开始循环
while True:
#访问目标地址,将timeout设置为35s
req = requests.get(url = self.check_url,headers = passport_headers,cookies = cookie,params = self.check_params,timeout = 35)
#替换返回值中的不合法字符,以便转换为json格式
#菜如我只能用三个replace......
response = req.text.replace('\\','').replace('"{',"{").replace('}"',"}")
try:
#如果errno或者status其中一项为1
if errno or status:
#将response转换为json格式
message = json.loads(re.search(pattern,response).group())
#更新errno
errno = message['errno']
#如果errno变为0(用户扫描二维码),并且照片查看器未关闭
if errno == 0 and flag:
#关闭照片查看器,将flag设置为False
self.show.close()
flag = False
#如果errno为0,则更新status值
elif errno == 0:
status = message['channel_v']['status']
#如果errno和status都为0,则补充login_params的bduss字段,结束循环
if not errno and not status:
message = json.loads(re.search(pattern,response).group())
self.login_params['bduss'] = message['channel_v']['v']
break
#更新check_paramas中两个关于时间的参数
self.check_params['tt'] = get_time()
self.check_params['_'] = self.check_params['tt'] + 2
except Exception as e:
print(e)
break
#获取cookie
def login(self):
#带上完整参数请求登录地址
login_r = requests.get(self.login_url, headers=headers, params=self.login_params,cookies = cookie)
#将BDUSS、PTOKEN、STOKEN写入cookie
for key in login_r.cookies.keys():
cookie[key] = login_r.cookies[key]
print('登陆成功,正在保存cookie')
#将cookie保存到本地
f = open('auth_cookie.txt','wt')
f.write(str(cookie))
f.close()
print('保存完毕')
完整代码
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 11 08:36:50 2020
@author: ljc545w
"""
# -*- coding: utf-8 -*-
#用到的包
#注:requests和Pillow为第三方包,需要使用pip命令安装
import requests
#时间管理带师
import time
#获取随机数
import random
#正则、json字典
import re,json
#Pillow
from PIL import Image
#线程
import threading
#进程
import psutil
#请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',
}
passport_headers = {
'Host': 'passport.baidu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',
'Referer': 'https://www.baidu.com/'
}
#定义一个空字典用于保存cookie
cookie = {
}
#获取毫秒级时间戳
def get_time():
cur_time = int(round(time.time() * 1000))
return cur_time
#获取gid
def guideRandom():
string = 'xxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'
gid = ''
#下面是根据JavaScript代码写的
for z in string:
#获取0到1的随机数,并乘以16
t = 16 * random.random()
#如果是z是x或者y
if z in "xy":
#hex将数字转换为十六进制,后面的你肯定能读懂
s = hex(int(t)) if z == "x" else hex(3 & int(t) | 8)
#将十六进制数转换为字符串,删除前面0x
gid += str(s).replace('0x','')
else:
#不是x或者y则不做处理
gid += z
#将字符串转换为大写,返回
return gid.upper()
#获取必要参数
def GetParams():
#这个是百度首页
Base_url = 'https://www.baidu.com/'
#先获取一些固定的cookie,如BAIDUID、PSTM等
Base_res = requests.get(url = Base_url,headers = headers)
for key in Base_res.cookies.keys():
#这里有一定概率引发异常,可能是因为某个cookie为空,预处理一下
try:
cookie[key] = Base_res.cookies[key]
except:
pass
#用于登录的参数(这里还没有加入bduss)
login_params = {
#获取时间戳
'v': get_time(),
'u': 'https://www.baidu.com/',
'loginVersion': 'v4',
'qrcode': '1',
'tpl': 'mn',
'apiver': 'v3',
#获取时间戳
'tt': get_time(),
'traceid': None,
#这里也是时间戳,不过是秒级,所以直接调用time方法,然后取整
'time': round(time.time()),
'alg':'v3',
#下面四个参数虽然会变化,但是写死也没什么影响,实测不写都可以
'sig': 'SXFidmJBL3NzS0lNaERoL1pzckVxaFdSS0lrSDQ5SUNPWFdjUDRhVE5rZkVOMEpzN2FpZExBTDRFejEwOFBvdw==',
'elapsed': 18,
'shaOne': '0011f17de7b0a1b99aa70a6f1ea881c14d404379',
'callback': 'bd__cbs__1sgowp',
}
#获取二维码地址的url
pass_url = 'https://passport.baidu.com/v2/api/getqrcode?lp=pc&qrloginfrom=pc'
#这里返回的是标准json格式,所以可以调用json方法而无需使用text方法
response = requests.get(url = pass_url,headers = headers).json()
#获取channel_id
channel_id = response['sign']
#拼接callback
callback = "tangram_guid_" + str(get_time() + 1)
#延迟0.5s,callback的时间戳与tt的时间戳相差在500左右
time.sleep(0.5)
#用于检查二维码扫描状态的参数
check_params = {
"channel_id":channel_id,
"tpl":"mn",
"gid":guideRandom(),
"callback":callback,
"apiver":"v3",
#获取时间戳
"tt":get_time(),
#加不加2应该都没什么影响
"_":get_time() + 2,
}
#拼接出完整的imgurl
imgurl = "https://" + response['imgurl'].replace('\\','')
#返回三个变量
return imgurl,login_params,check_params
class Show(object):
def __init__(self,imgurl):
self.t = threading.Thread(target = self.get_img)
self.t.setDaemon(True)
self.imgurl = imgurl
def get_img(self):
res = requests.get(url = self.imgurl,headers = headers)
f = open('baidu.jpg','wb')
f.write(res.content)
f.close()
time.sleep(1)
img = Image.open('baidu.jpg')
img.show()
for proc in psutil.process_iter():
if proc.name() in ['Microsoft.Photos.exe','dllhost.exe']:
self.proc = proc
break
def show(self):
self.t.start()
def close(self):
self.proc.kill()
class Login(object):
def __init__(self,login_params,check_params,show):
self.show = show
self.check_url = 'https://passport.baidu.com/channel/unicast'
self.login_url = 'https://passport.baidu.com/v3/login/main/qrbdusslogin'
self.login_params = login_params
self.check_params = check_params
def check_status(self):
self.show.show()
errno = 1
status = 1
flag = True
pattern = re.compile('({.*})')
while True:
req = requests.get(url = self.check_url,headers = passport_headers,cookies = cookie,params = self.check_params,timeout = 35)
response = req.text.replace('\\','').replace('"{',"{").replace('}"',"}")
try:
if errno or status:
message = json.loads(re.search(pattern,response).group())
errno = message['errno']
if errno == 0 and flag:
self.show.close()
flag = False
elif errno == 0:
status = message['channel_v']['status']
if not errno and not status:
message = json.loads(re.search(pattern,response).group())
self.login_params['bduss'] = message['channel_v']['v']
break
self.check_params['tt'] = get_time()
self.check_params['_'] = self.check_params['tt'] + 2
except Exception as e:
print(e)
break
def login(self):
login_r = requests.get(self.login_url, headers=headers, params=self.login_params,cookies = cookie)
for key in login_r.cookies.keys():
cookie[key] = login_r.cookies[key]
print('登陆成功,正在保存cookie')
f = open('auth_cookie.txt','wt')
f.write(str(cookie))
f.close()
print('保存完毕')
#如果不想继续使用获取的cookie,可以使用这个函数
def logout():
#百度退出登录的url
logout_url = 'https://passport.baidu.com/?logout'
#从文本中读取cookie
f = open('auth_cookie.txt','r',encoding='utf-8')
logout_cookie = f.read()
f.close()
#转换为json格式。注意!!!如果文本中是单引号,要将其替换为双引号
logout_cookie = json.loads(logout_cookie.replace("'","\""))
#发起post请求,原本的cookie将失去作用
requests.post(url = logout_url,headers = headers,cookies = logout_cookie)
print('已退出登录')
def run():
#获取三个重要变量
imgurl,login_params,check_params = GetParams()
#声明一个对象控制二维码的显示
show = Show(imgurl)
#将两个参数和show传递给Login类,获取用于控制登录的对象
login = Login(login_params,check_params,show)
#调用类中的方法,检查二维码扫描状态
login.check_status()
#调用类中方法获取cookie
login.login()
#入口函数
if __name__ == '__main__':
#logout()
run()
写在后面
花了整整一天,暂时把百度的二维码登录搞明白了,这篇文章中的代码可能不久就会失效,我大概是不会再更新,不,是肯定不会。
这是爬虫小白对二维码登录的一次尝试,如有不足之处,恳请各位大佬批评指正。