Mybatis入门,增删改查,标签属性,占位符与字符拼接的区别
Mybatis是什么
JDBC的问题:
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 通过驱动管理类获取数据库链接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8", "root", "root");
// 定义sql语句 ?表示占位符
String sql = "select * from user where username = ?";
// 获取预处理statement
preparedStatement = connection.prepareStatement(sql);
// 设置参数,第一个参数为sql语句中参数的序号(从1开始),第二个参数为设置的参数值
preparedStatement.setString(1, "王五");
// 向数据库发出sql执行查询,查询出结果集
resultSet = preparedStatement.executeQuery();
// 遍历查询结果集
while (resultSet.next()) {
System.out.println(resultSet.getString("id") + " " + resultSet.getString("username"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
1、 数据库连接创建、释放频繁造成系统资源浪费,从而影响系统性能。如果使用数据库连接池可解决此问题。(用完就要释放)
2、 Sql语句在代码中硬编码,造成代码不易维护,实际应用中sql变化的可能较大,sql变动需要改变java代码。
3、 使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能多也可能少,修改sql还要修改代码,系统不易维护。
4、 对结果集解析存在硬编码(查询列名),sql变化导致解析代码变化,系统不易维护,如果能将数据库记录封装成pojo对象解析比较方便。(要对应名字)
Mybatis的架构

1.SqlMapConfig.xml,官方文档起的名字
两个Mapper就相当于用户和订单表,将表信息导给SqlMapConfig.xml全局配置文件,让全局文件知道用户和订单的存在,用来写sql语句
2.然后通过这两大配置文件产生sqlsession工厂,xml的配置文件就相当于原材料,工厂一生产就产生sqlsession
3.sqlsession对象,本身就可以操作数据库,里面还有一个叫executor的执行对象,如sqlsession有一个save()方法,但执行是由executor(执行者)去执行的。
4.MappedStatement:把sql语句要给sqlSession,就相当于把sql语句放在一个POJO对象,POJO对象就相当于我们用户对象一样,里面有我们的id,密码,性别,真实地址。。。,这里装sql语句,然后分为查询还是插入,哪张表,有哪些字段,完了让executor执行。输入映射赛的是输入映射,完了输出要映射回来就映射到输出映射,这些都是自动映射。
入门程序
1.选择查询
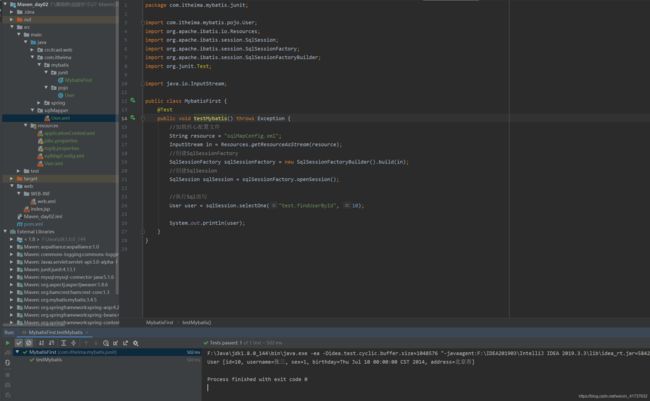
1.添加Mybatis依赖
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
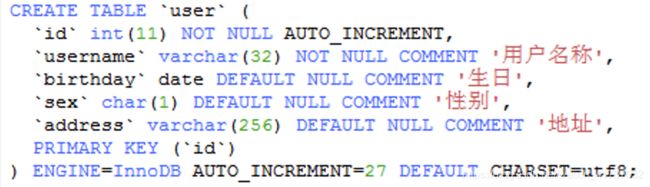
2.创建pojo
pojo类作为mybatis进行sql映射使用,po类通常与数据库表对应
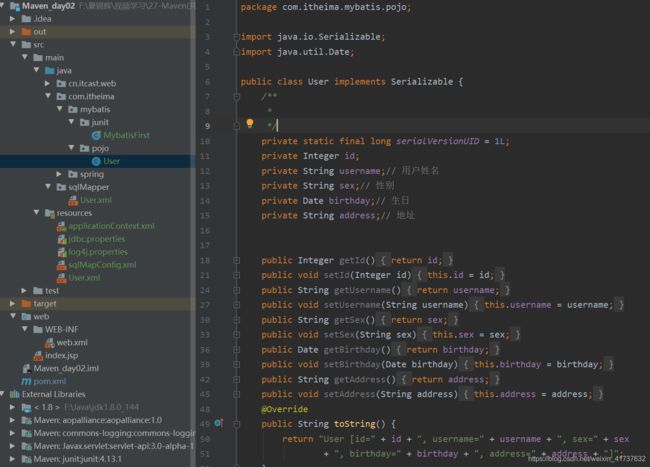 private static final long serialVersionUID=1L意思是定义程序序列化ID。
private static final long serialVersionUID=1L意思是定义程序序列化ID。
3.SqlMapConfig.xml

4.sql映射文件
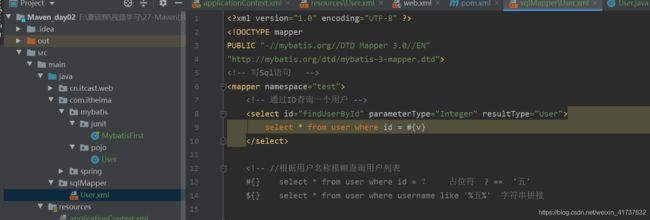
然后在sqlMapConfig.xml加载映射文件
这个#{}里面还要填写东西,写什么内容都行,都代表一个问号。
#{} 占位符 预编译的 防止sql注入
${}字符串拼接,这两个是不同的概念 不是预编译的 不防止sql注入,预编译是执行前已经把值给传进去了
为什么占位符能防止sql注入如:
String sql = “select * from administrator where adminname=?”;
psm = con.prepareStatement(sql);
String s_name =“zhangsan’ or ‘1’='1”;
psm.setString(1, s_name);原本以为是转为‘zhangsan’ or ‘1’='1’
经过JDK的setString()方法转意后变为如下图,因此占位符解决了该问题
#{}表示一个占位符号,通过#{}可以实现preparedStatement向占位符中设置值,自动进行java类型和jdbc类型转换。#{}可以有效防止sql注入。 #{}可以接收简单类型值或pojo属性值。 如果parameterType传输单个简单类型值,#{}括号中可以是value或其它名称。
表 示 拼 接 s q l 串 , 通 过 {}表示拼接sql串,通过 表示拼接sql串,通过{}可以将parameterType 传入的内容拼接在sql中且不进行jdbc类型转换, 可 以 接 收 简 单 类 型 值 或 p o j o 属 性 值 , 如 果 p a r a m e t e r T y p e 传 输 单 个 简 单 类 型 值 , {}可以接收简单类型值或pojo属性值,如果parameterType传输单个简单类型值, 可以接收简单类型值或pojo属性值,如果parameterType传输单个简单类型值,{}括号中只能是value。
![]()
而${}字符串拼接不能防止拼接如下例,只是单纯的把字符去掉""然后取出值来。
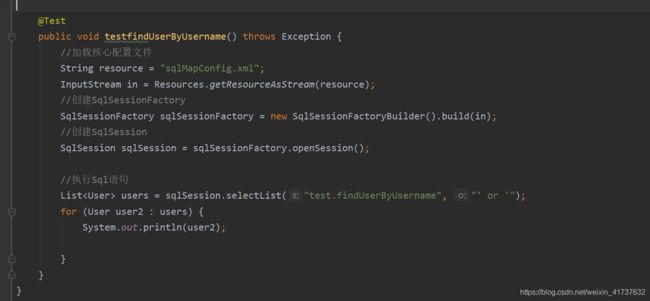

2模糊查询
模糊查询还是使用占位符的查询方式比较好,不容易引起sq注入,上面例子已经证明字符串拼接的坏处,猜到你的结构后就可以写语句进去查出你的所有。


这里输出的Mysql语句就会被解析为select * from user where username like “%”‘五’"%";
就是"%"+‘五’+"%",而你在selectList填入’五’肯定报错,因为别人接收的是String类型,而且在Mysql中单引号与双引号的用法是一样的,双引号是Mysql的扩展。
3.数据的插入

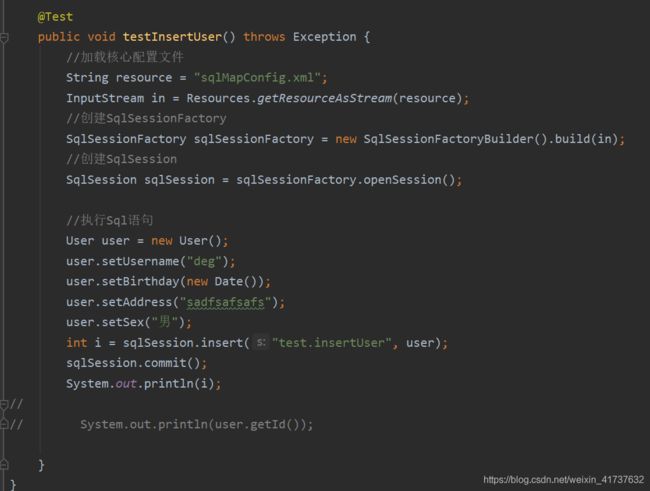
想在插入后立马获得新增加的id输入到另外一张表格中,先要获取id值,需要在xml
里的insert里添加一个查询主键
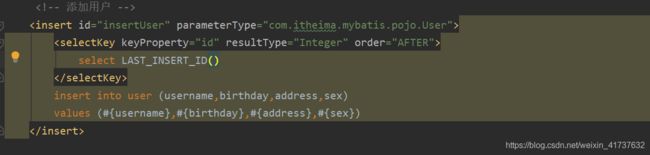
last表示最新的,insert表示插入的id,这个是Mysql提供的,在执行此语句前先执行insert便可以查到最新,若不执行则为0.
keyProperty=“id”,放到user对象的id,结果类型为Integer,这里有一个点,如果主键数据是Integer类型,他是先保存数据,再生成ID,如果ID是varchar先生成ID再一起保存进去,此时order选择的是之前。这时便可以立马获得新增用户的id了。
4.更新数据


5.删除数据

Mybatis和hibernate不同,它不完全是一个ORM框架(不用自己写sql语句,直接进行映射),因为MyBatis需要程序员自己编写Sql语句。mybatis可以通过XML或注解方式灵活配置要运行的sql语句,并将java对象和sql语句映射生成最终执行的sql,最后将sql执行的结果再映射生成java对象。
Mybatis学习门槛低,简单易学,程序员直接编写原生态sql,可严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件,工作量大。
Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用hibernate开发可以节省很多代码,提高效率。但是Hibernate的学习门槛高,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡,以及怎样用好Hibernate需要具有很强的经验和能力才行。
总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。
原本使用Dao开发
其中的Dao层就像我们的上面的junit测试单元的。
模拟一个Dao层的开发


我们可以看到,使用原生的Dao开发要写接口以及实现类,实现类的
SqlSession sqlSession = sqlSessionFactory.openSession();
return sqlSession.selectList(“test.findUserById”, id);
只有selectOne或selectList不同,还有这个命名空间不同。其余都是重复的内容
原始Dao开发中存在以下问题:
Dao方法体存在重复代码:通过SqlSessionFactory创建SqlSession,调用SqlSession的数据库操作方法
调用sqlSession的数据库操作方法需要指定statement的id,这里存在硬编码,不得于开发维护。
为了解决这些问题,出现了Mapper动态代理开发



Mapper接口开发需要遵循以下规范:
1、 Mapper.xml文件中的namespace与mapper接口的类路径相同。
2、 Mapper接口方法名和Mapper.xml中定义的每个statement的id相同
3、 Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
4、 Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
getMapper就会帮我们生成一个实现类,session.selectone或selectlist就不需自己做了,根据返回值是User还是List,不用硬编码了。
selectOne和selectList
动态代理对象调用sqlSession.selectOne()和sqlSession.selectList()是根据mapper接口方法的返回值决定,如果返回list则调用selectList方法,如果返回单个对象则调用selectOne方法。
namespace
mybatis官方推荐使用mapper代理方法开发mapper接口,程序员不用编写mapper接口实现类,使用mapper代理方法时,输入参数可以使用pojo包装对象或map对象,保证dao的通用性。
SqlMapConfig.xml的properties与typeAliases别名配置
properties:
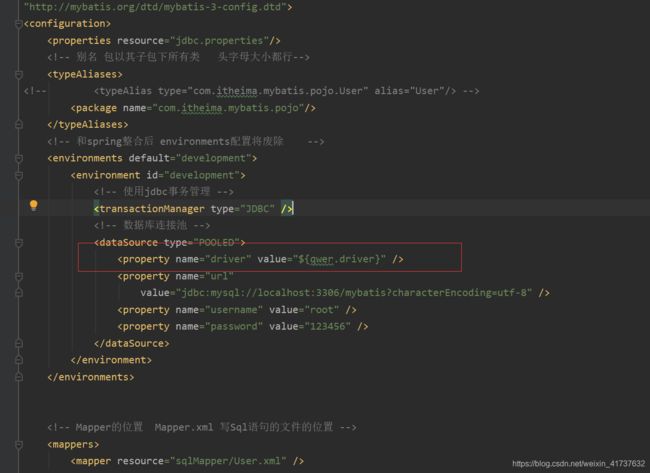
配置了就可以取jdbc.properties里面的值,不用在里面修改配置的值
typeAliases:别名,如果按红框这样配,万一有订单表,消费表会有许多哥配置,而红框下面则把包以及子包下的所有类都包括进来,这样返回类型都被包括跑进来,且对名字大小写不敏感。还有对于通用的int,都已经帮我们配置好了,就不用再配置了。



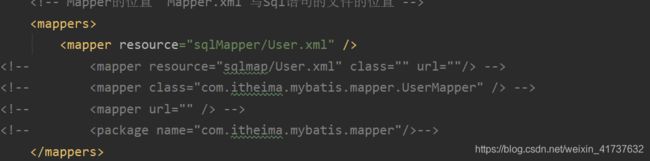
mappers(映射器标签)

包也可以防止万一有多个Mapper需要配置多个的问题,项目中一般用mapper.