pandas基础知识点,包含Python和numpy基础
pandas基础知识点,包含Python和numpy基础
-
- 学习过程(笔记)
- 结束语:
学习过程(笔记)
print([m+'爱'+w for m in ['我','你'] for w in ['你','我']]) #列表表达式多层嵌套
def data(x): #定义函数
return x*100
for x in [2,2]:
print(data(x))
value = 'cat' if 2>1 else 'dog' #带有 if 选择的条件赋值,其形式为 value = a if condition else b
print(value)
print([(lambda x:x*2)(i) for i in range(3)]) #lambda匿名函数的用法
# Python 中提供了 map 函数来完成,它返回的是一个 map 对象,需要通过 list 转为列表:
L=list(map(lambda a,b:a+'爱'+b,['我','你'],['编程','打游戏'])) #map(包含a,b的lambda函数,a映射内容,b映射内容) a b需要一一对应(有多少a就得有多少b)
print(list(L))
# zip函数能够把多个可迭代对象打包成一个元组构成的可迭代对象
l1,l2,l3=list('123'),list('456'),list('789') #
print(list(zip(l1,l2,l3))) #打包并输出打包后的列表
print(tuple(zip(l1,l2,l3))) #打包并输出打包后的元组
for i,j,k in zip(l1,l2,l3): #循环迭代使用zip的格式
print(i,j,k)
#enumerate 是一种特殊的打包,它可以在迭代时绑定迭代元素的遍历序号:
B=list('abcde')
for index,value in enumerate(B): #enumerate(B)=zip(range(len(B)),B)
print(index,value)
for index,value in zip(range(len(B)),B):
print(index,value)
#两个字典建立映射,可以用zip对象
C=dict(zip(l1,l2))
print(C)
#通过*号来进行打包后解打包的操作
zipped=list(zip(l1,l2,l3)) #先打包
print(zipped)
print(list(zip(*zipped))) #解打包,恢复到原状态
import numpy as np
t1=np.array([1,2,3])
print(t1)
t2=np.linspace(1,5,11) #linspace(起始,终止(包含),样本个数)----------------(等差序列)
print(t2)
t3=np.arange(1,5,2) # arang(起始,终止(不包含),步长)
print(t3)
t4=np.zeros((2,3)) #因为zeros是多维 所以传入了一个元组,一维只需要一个数字就行
print(t4)
t5=np.eye(5) #5*5的单位矩阵
t6=np.eye(5,k=1) #偏移主对角线1(向上)个单位的伪单位矩阵
t7=np.eye(5,k=-1) # 偏移主对角线-1(向下)个单位的伪单位矩阵
print(t5)
print(t6)
print(t7)
print(np.full((2,3),10)) # 元组传入大小,10表示填充数值
print(np.full((2,3),[1,2,3])) #通过传入列表填充每列的值(列表的对象数要与列数对应)
print(np.random.rand(3)) # 生成服从0-1均匀分布的三个随机数
print(np.random.rand(5,5)) ## 生成服从0-1均匀分布的5个随机数,生成五行的维度
print(np.random.randn(3)) #-1,到1的三个y轴的正态分布
print(np.random.randn(3,4))
#randint 可以指定生成随机整数的最小值最大值(不包含)和维度大小
low,high,size = 2,14,(2,2) #生成2到14的两行两列的随机数
print(np.random.randint(low,high,size))
print(np.random.choice(l1,2,replace=False,p=(0.6,0.2,0.2))) #当replace=false时为不放回抽样,反之则为放回,p=后面跟的是每个元素的概率
print(np.random.choice(l1,(3,3))) #生成三行三列的l1列表中元素的随机矩阵
print(np.random.permutation(l1)) #打散列表l1
print(np.random.choice(l1,3,replace=False)) #等同于上面的
np.random.seed(0)
print(np.random.rand()) #随机种子,它能够固定随机数的输出结果
#合并
print(np.zeros((2,3)).T) #.T为倒置
#对于二维数组而言, r_ 和 c_ 分别表示上下合并和左右合并:
print(np.r_[np.zeros((2,3)),np.zeros((2,3))])
print(np.c_[np.zeros((2,3)),np.zeros((2,3))])
ta=np.arange(8).reshape(2,4) #reshape(行,列)
print(ta)
ra=np.arange(12).reshape(2,6,order='C') # 按照行读取和填充
ha=np.arange(12).reshape(2,6,order='F') # 按照列读取和填充
print(ra)
print(ha)
'/n'
print(np.arange(9).reshape(3,3))
la=np.arange(9).reshape(3,3)
df=la[:-1,(0,2)] #-1代表重倒数第二行开始,以此类推,1,就是第一行,2就代表第二行,3代表第三行,0代表倒数第一行,-1代表倒数第二行,-2代表倒数第三行
print(df)
#还可以利用 np.ix_ 在对应的维度上使用布尔索引,但此时不能使用 slice 切片:
LA=la[np.ix_([True,True,False],[True,True,False])] #ix_([对应的行数1,对应的行数2...],[[对应的列数1,对应的列数2...] 布尔型
print(LA)
#where函数
a = np.array([-1,1,-1,0])
dd=np.where(a>0, a, 5) # 对应位置为True时填充a对应元素,否则填充5 格式 .where(条件,符合条件填充内容,不符合的替换的内容)
print(dd)
#nonzero, argmax, argmin
#这三个函数返回的都是索引, nonzero 返回非零数的索引, argmax, argmin 分别返回最大和最小数的索引
gg=np.nonzero(dd)
hh=np.argmax(dd)
jj=np.argmin(dd)
print(gg)
print(hh)
print(jj)
martix_target = np.arange(4).reshape(2,2)
print(martix_target )
M1 = np.random.rand(2,3)
print(M1)
any 指当序列至少 存在一个 True 或非零元素时返回 True ,否则返回 False
all 指当序列元素 全为 True 或非零元素时返回 True ,否则返回 False
a=np.array([0,1,2,3])
aaa=a.any()
print(aaa)
True #结果
bbb=a.all()
print(bbb)
False #结果
cumprod, cumsum 分别表示累乘和累加函数,返回同长度的数组, diff 表示和前一个元素做差,由于第一个元素为缺失值,因此在默认参数情况下,返回长度是原数组减1
a=np.array([0,1,2,3,6])
ccc=a.cumprod() #累乘函数
print(ccc)
ddd=a.cumsum() #累加函数
print(ddd)
[0 0 0 0 0] #输出结果ccc
[ 0 1 3 6 12] #输出结果ddd
eee=np.diff(a) #和前一个元素做差
print(eee)eee
[1 1 1 3] #输出结果eee
累乘函数,列表里有一个0,全部元素为0,如上代码ccc输出结果全部为0
- 统计函数
常用的统计函数包括 max, min, mean, median, std, var, sum,quantile
用法如下
a.max() #取最大值
6 #输出结果
np.quantile(a, 0.5) # 0.5分位数
2.0 #输出结果
对于协方差和相关系数分别可以利用 cov, corrcoef 如下计算
In [100]: target1 = np.array([1,3,5,9])
In [101]: target2 = np.array([1,5,3,-9])
In [102]: np.cov(target1, target2)
Out[102]:
array([[ 11.66666667, -16.66666667],
[-16.66666667, 38.66666667]])
In [103]: np.corrcoef(target1, target2)
Out[103]:
array([[ 1. , -0.78470603],
[-0.78470603, 1. ]])
需要说明二维 Numpy 数组中统计函数的 axis 参数,它能够进行某一个维度下的统计特征计算,当 axis=0 时结果为列的统计指标,当 axis=1 时结果为行的统计指标
In [104]: target = np.arange(1,10).reshape(3,-1)
In [105]: target
Out[105]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [106]: target.sum(0)
Out[106]: array([12, 15, 18])
In [107]: target.sum(1)
Out[107]: array([ 6, 15, 24])
- 广播机制
当一个标量和数组进行运算时,标量会自动把大小扩充为数组大小,之后进行逐元素操作:
res = 7 * np.ones((8, 8)) + 1
print(res)
[[8. 8. 8. 8. 8. 8. 8. 8.] #输出结果
[8. 8. 8. 8. 8. 8. 8. 8.]
[8. 8. 8. 8. 8. 8. 8. 8.]
[8. 8. 8. 8. 8. 8. 8. 8.]
[8. 8. 8. 8. 8. 8. 8. 8.]
[8. 8. 8. 8. 8. 8. 8. 8.]
[8. 8. 8. 8. 8. 8. 8. 8.]
[8. 8. 8. 8. 8. 8. 8. 8.]]]
res=1/res
print(res)
[[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125] #输出结果
[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125]
[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125]
[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125]
[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125]
[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125]
[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125]
[0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125]]
二维数组之间的操作
当两个数组维度完全一致时,使用对应元素的操作,否则会报错
1×2 数组和 3×2 数组做逐元素运算时会把第一个数组扩充为 3×2
res = 7 * np.ones((3, 4)) + 1
print(res)
res=1/res
print(res)
qq=res * np.array([[2,3,3,3]]) #一维元素数量要等于列的数量,才不会报错,每行数都对应相乘
print(qq)
ww=res * np.array([[2],[3],[4]]) #这种写法[]的数量要等于行的数量才不会报错,每行相对应相乘
print(ww)
rr=res * np.array([[8]]) # 等价于两次扩充,相当于每个维度的元素都乘以8
print(rr)
一维数组与二维数组的操作
y=np.ones(3) #一维和二维相加时候,一维的数量必须等于二维的列数才不会报错3!=3
h=np.ones((6,3))
jj=y+h
print(jj)
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]
i=np.ones(3)+np.ones((2,1))
u=np.ones(1)+np.ones((2,3))
print(i==jj)
print(i==u)
[[ True True True] #输出结果
[ True True True]]
[[ True True True]
[ True True True]]
两个一维数组相加,第二个一维数组里面的1相当与第一个一维数组里面的3,直接替换等同于np.onse(3)+np.ones((2,3))等同于np.ones(1)+np.ones(2,3)
- 向量与矩阵的计算
(ps:工作党,在学校数学就是学渣,现在关于线代的东西忘完了。。。看来要重新复习下线性代数的东西。。呜呜。。。以下内容纯属先做好笔记,复习玩线性代数再来一战)
【a】向量内积: dot
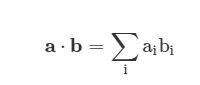
In [120]: a = np.array([1,2,3])
In [121]: b = np.array([1,3,5])
In [122]: a.dot(b)
Out[122]: 22
向量范数和矩阵范数: np.linalg.norm
在矩阵范数的计算中,最重要的是 ord 参数,可选值如下:

In [123]: martix_target = np.arange(4).reshape(-1,2)
In [124]: martix_target
Out[124]:
array([[0, 1],
[2, 3]])
In [125]: np.linalg.norm(martix_target, 'fro')
Out[125]: 3.7416573867739413
In [126]: np.linalg.norm(martix_target, np.inf)
Out[126]: 5.0
In [127]: np.linalg.norm(martix_target, 2)
Out[127]: 3.702459173643833
In [128]: vector_target = np.arange(4)
In [129]: vector_target
Out[129]: array([0, 1, 2, 3])
In [130]: np.linalg.norm(vector_target, np.inf)
Out[130]: 3.0
In [131]: np.linalg.norm(vector_target, 2)
Out[131]: 3.7416573867739413
In [132]: np.linalg.norm(vector_target, 3)
Out[132]: 3.3019272488946263
矩阵乘法: @
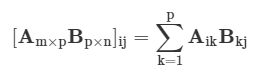
In [133]: a = np.arange(4).reshape(-1,2)
In [134]: a
Out[134]:
array([[0, 1],
[2, 3]])
In [135]: b = np.arange(-4,0).reshape(-1,2)
In [136]: b
Out[136]:
array([[-4, -3],
[-2, -1]])
In [137]: a@b
Out[137]:
array([[ -2, -1],
[-14, -9]])
练习部分,线代里面的矩阵都要复习下。练习题也是一脸懵。。
结束语:
刚接触python并想要学好python的小白,平时工作中有涉及到数据处理的东西,想着学好python,为日常工作减轻些负担。本以为学好语法就行了,就可以实现一些简单的数据处理的动作。这task1下来。发现里面还是包含不少数学知识的,上学时数学就不好。受到了不小的打击,好歹涉及到语法的代码都敲了一遍。生成的结果也结合代码思考了几番,意识到自己的不足。。看来要恶补线代。。概率论,高数了。。。
第一次用csdn论坛,第一次学着用csdn写笔记,第一次熟悉csdn里面的md语法编辑器,写的内容排版混乱,还请 Datawhale的观众大佬爷们多多包涵。。。