DW_Pandas_Task5_变形
知识点整理
一、长宽表
属于某一列或几列 元素 和 列索引 之间的转换
1.pivot
参数理解:
index:变形后的行索引
columns:需要转到列索引的列
valus:列和行索引对应的数值
1)
原表df
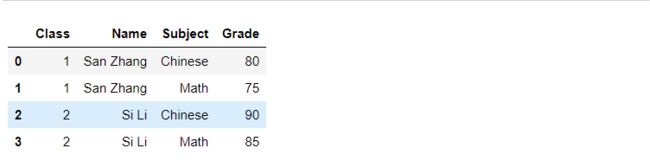
df.pivot(index=‘Name’, columns=‘Subject’, values=‘Grade’)
新表中:
Name 是行索引,唯一值(2个)
列索引:Subject中有两个唯一值,所以是两个列索引

2)变形后返回多级索引
新的行索引:等价于对 index 中的多列使用 drop_duplicates ,保持唯一性
新的列索引:长度为 values 的元素数 (2个)× columns 的唯一组合数(4个)
2.pivot_table
可以不受唯一值的限制, aggfunc 参数可以进行统计
3.melt
将列索引转换成列表元素(宽表变长表)
参数理解:
id_vars:保留的类别块
value_vars:要压缩的列索引,转化之后以其值做一列
var_name:转换之后新列的索引
value_name:变形前列元素的含义
4.wide_to_long
教程中复杂案例的运行与理解
import numpy as np
import pandas as pd
df = pd.DataFrame({
'Class':[1, 1, 2, 2, 1, 1, 2, 2],
'Name':['San Zhang', 'San Zhang', 'Si Li', 'Si Li',
'San Zhang', 'San Zhang', 'Si Li', 'Si Li'],
'Examination': ['Mid', 'Final', 'Mid', 'Final',
'Mid', 'Final', 'Mid', 'Final'],
'Subject':['Chinese', 'Chinese', 'Chinese', 'Chinese',
'Math', 'Math', 'Math', 'Math'],
'Grade':[80, 75, 85, 65, 90, 85, 92, 88],
'rank':[10, 15, 21, 15, 20, 7, 6, 2]})
df
#记录为班级、姓名、测试类型(期中考试和期末考试)、科目、成绩、排名
| Class | Name | Examination | Subject | Grade | rank | |
|---|---|---|---|---|---|---|
| 0 | 1 | San Zhang | Mid | Chinese | 80 | 10 |
| 1 | 1 | San Zhang | Final | Chinese | 75 | 15 |
| 2 | 2 | Si Li | Mid | Chinese | 85 | 21 |
| 3 | 2 | Si Li | Final | Chinese | 65 | 15 |
| 4 | 1 | San Zhang | Mid | Math | 90 | 20 |
| 5 | 1 | San Zhang | Final | Math | 85 | 7 |
| 6 | 2 | Si Li | Mid | Math | 92 | 6 |
| 7 | 2 | Si Li | Final | Math | 88 | 2 |
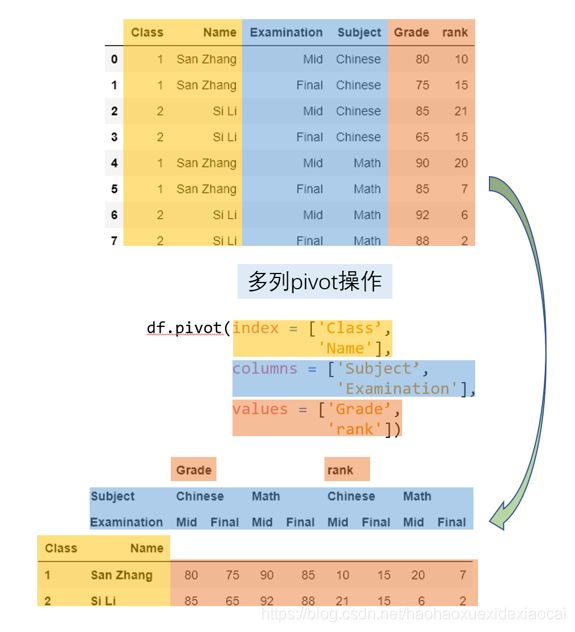
#把联合组成的四个类别(期中语文、期末语文、期中数学、期末数学)转到列索引
pivot_multi = df.pivot(index = ['Class', 'Name'],
columns = ['Subject','Examination'],
values = ['Grade','rank'])
pivot_multi
| Grade | rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Subject | Chinese | Math | Chinese | Math | |||||
| Examination | Mid | Final | Mid | Final | Mid | Final | Mid | Final | |
| Class | Name | ||||||||
| 1 | San Zhang | 80 | 75 | 90 | 85 | 10 | 15 | 20 | 7 |
| 2 | Si Li | 85 | 65 | 92 | 88 | 21 | 15 | 6 | 2 |
res = pivot_multi.copy()
res.columns = res.columns.map(lambda x:'_'.join(x))
res = res.reset_index()
res = pd.wide_to_long(res, stubnames=['Grade', 'rank'],
i = ['Class', 'Name'],
j = 'Subject_Examination',
sep = '_',
suffix = '.+')
res
#先将内两层索引合并压缩,列表只有两层索引
| Grade | rank | |||
|---|---|---|---|---|
| Class | Name | Subject_Examination | ||
| 1 | San Zhang | Chinese_Mid | 80 | 10 |
| Chinese_Final | 75 | 15 | ||
| Math_Mid | 90 | 20 | ||
| Math_Final | 85 | 7 | ||
| 2 | Si Li | Chinese_Mid | 85 | 21 |
| Chinese_Final | 65 | 15 | ||
| Math_Mid | 92 | 6 | ||
| Math_Final | 88 | 2 |
res = res.reset_index() #将两层变成一层索引
#reset_index 是 set_index 的逆函数,其主要参数是 drop ,表示是否要把去掉的索引层丢弃,而不是添加到列中
res
res[['Subject', 'Examination']] = res[
'Subject_Examination'].str.split('_', expand=True)
res
#从一列中生成两列
res = res[['Class', 'Name', 'Examination',
'Subject', 'Grade', 'rank']].sort_values('Subject')
res = res.reset_index(drop=True)
res
| Class | Name | Examination | Subject | Grade | rank | |
|---|---|---|---|---|---|---|
| 0 | 1 | San Zhang | Mid | Chinese | 80 | 10 |
| 1 | 1 | San Zhang | Final | Chinese | 75 | 15 |
| 2 | 2 | Si Li | Mid | Chinese | 85 | 21 |
| 3 | 2 | Si Li | Final | Chinese | 65 | 15 |
| 4 | 1 | San Zhang | Mid | Math | 90 | 20 |
| 5 | 1 | San Zhang | Final | Math | 85 | 7 |
| 6 | 2 | Si Li | Mid | Math | 92 | 6 |
| 7 | 2 | Si Li | Final | Math | 88 | 2 |
二、索引的变形
行列索引的转化
stack与unstack使用
三、其他变形函数
1.crosstab 可以聚合操作
2.explode 将一列纵向展开
3.get_dummies 将一列转为指示变量
练习题
EX1

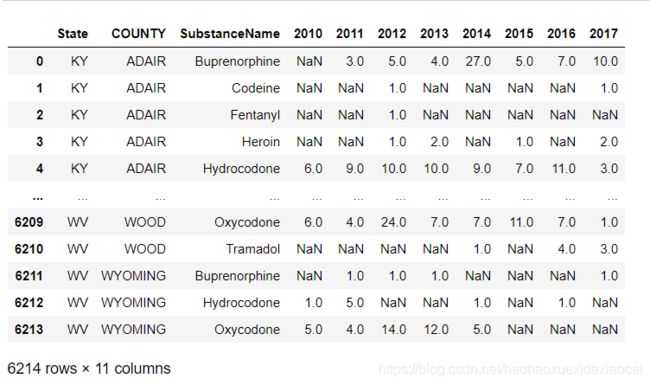
df_pivot=df.pivot(index=['State','COUNTY','SubstanceName'],columns='YYYY',values='DrugReports')
df_pivot
df1=df_pivot.reset_index()
df1.rename_axis(columns={'YYYY':''})
2.
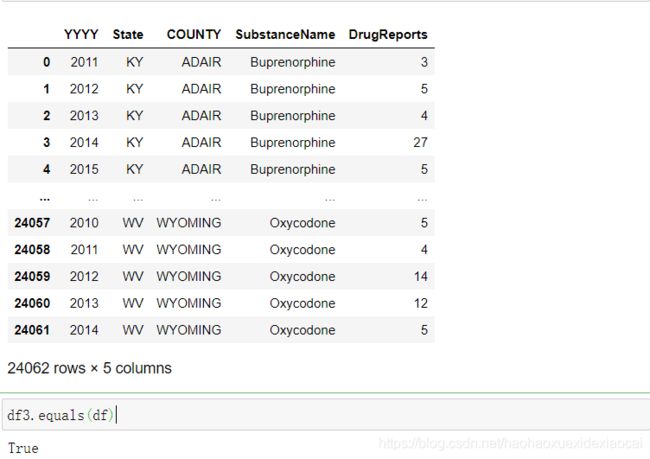
df2=df1.melt(id_vars = ['State','COUNTY','SubstanceName'],
value_vars = [2010, 2011,2012,2013,2014,2015,2016,2017],
var_name = 'YYYY', value_name = 'DrugReports').dropna(subset=['DrugReports'])
df2.index=range(0,df2.shape[0])
df3=df2[['YYYY','State','COUNTY','SubstanceName','DrugReports']].sort_values([
'State','COUNTY','SubstanceName'],ignore_index=True).astype({'YYYY':'int64', 'DrugReports':'int64'})
df3
df3.equals(df)
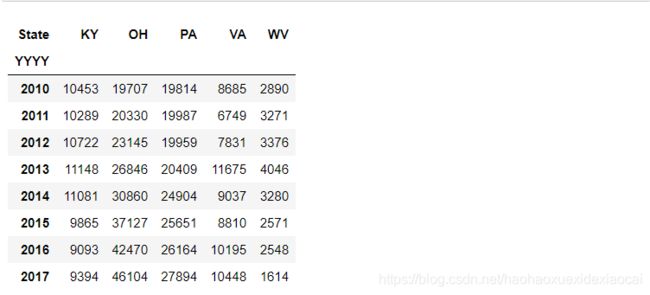
3. 1 pivot_table
df_3=df.pivot_table(index='YYYY',columns='State',values='DrugReports',aggfunc = 'sum')
df_3
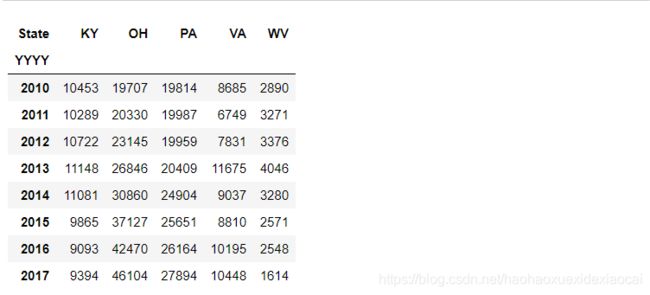
3.2 groupby+unstack
df_4=df.groupby(['YYYY','State'])['DrugReports'].sum()
df_4.unstack(1)
联系:
pivot_table是分组的基础上的聚合
DW_Pandas教程