爬虫学习笔记3-Json-path、Xpath数据提取
1、数据提取-响应内容的分类
(1)结构化响应
- json字符串:使用re、json、jsonpath等模块来提取特定数据(高频出现)
- xml字符串:使用re、lxml等模块来提取特定数据(低频出现)

(2)非机构化响应
- html字符串:可以使用re、lxml等模块来提取特定数据
1、xml和html的区别:
- html:
- 超文本标记语言
- 为了更好的显示数据,侧重点是为了显示
- xml:
- 可扩展标记语言
- 为了传输和存储数据,侧重点是在于数据内容本身
2、常用数据解析方法:


2、Jason-path模块
(1)使用场景: 对于多层嵌套的复杂字典,jsonpath可以按照key对python字典进行批量数据提取
(2)安装: pip install jsonpath
(3)使用方法
from jsonpath import jsonpath
ret = jsonpath(a, 'jsonpath语法规则字符串')

(4)使用实例
案例1:
from jsonpath import jsonpath
data = {
'key1':
{
'key2':
{
'key3':
{
'key4':
{
'key5':
{
'key6':'python'}
}
}
}
}
}
# 常规的提取方法
print(data['key1']['key2']['key3']['key4']['key5']['key6'])
# jasonpath 获取的结果是列表,需要通过索引获取数据
# 1.根节点获取数据
print(jsonpath(data,'$.key1.key2.key3.key4.key5.key6')[0])
# 2.直接获取数据
print(jsonpath(data,'$..key6')[0])
案例2:
from jsonpath import jsonpath
book_dict = {
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
# 输出所有作者
print(jsonpath(book_dict,"$..author"))
# 输出store中低于10块钱的书
print(jsonpath(book_dict,"$..book[?(@.price<10)]"))
案例3:以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市的名字的列表,并写入文件
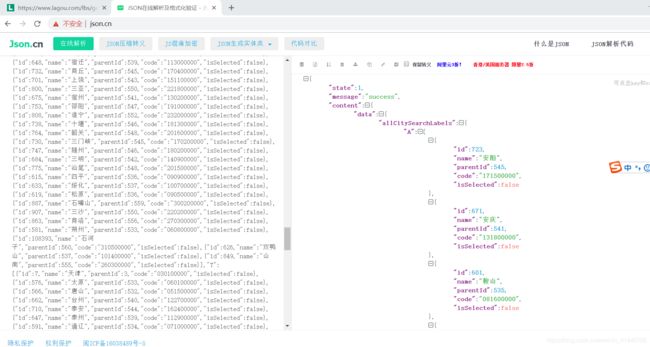
import requests
from jsonpath import jsonpath
import json
url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
response =requests.get(url, headers=headers)
data = json.loads(response.content.decode())
print(jsonpath(data,'$..name'))
3、lxml模块和XPath语法
(1)应用场景:
- lxml模块可以利用XPath规则语法,来快速的定位HTML\XML 文档中特定元素以及获取节点信息;
- XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML文档中对元素和属性进行遍历。
- 提取xml、html中的数据需要lxml模块和xpath语法配合使用
(2)谷歌浏览器XPath安装和使用
①下载(密码:gzcx)安装:解压拖动到谷歌浏览器的拓展程序界面,重启既可以使用
②使用

(3)Xpath的节点关系

(4)XPath语法-基础节点
| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素。 |
| / | 从根节点选取、或者是元素和元素间的过渡。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| text() | 选取文本。 |
-
获取html下的head下的title标签内容


-
获取所有的a标签的href

-
获取html下的head下的link标签的href

(5)xpath语法-节点修饰语法
①通过索引的方式修饰节点
# 通过指定元素的下标(下标从1开始)
html/body/div[3]/div/div[1]
# 选中最后一个
html/body/div[3]/div/div[last()]
# 选中倒数第二个
html/body/div[3]/div/div[last(-1)]
# 范围选择
html/body/div[3]/div/div[position()>10]
②通过属性值修饰节点
# 方括号内的@id起修饰作用,最后出现的@id为取值作用
//div[@id='content-left']/div/@id
③通过子节点的属性值来修饰
//div[span[i>9.6]]
④通过包含修饰
# 标签属性值
//div[contains(@id,"qiushi_tag_")]
//span[contains(text(),"一页")]
(6)xpath语法-其他常用节点选择语法
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| node() | 匹配任何类型的节点。 |
#全部的标签
//*
#全部的属性
//node()
(7) lxml模块的安装与使用
①lxml模块的安装: pip/pip3 install lxml
②lxml模块的使用:
from lxml import etree
# python3.5之后的 lxm 模块l中不能再直接引入etree模块,采用以下方法
# from lxml import html
# etree = html.etree
# 利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象
html = etree.HTML(text)
# Element对象具有xpath的方法,返回结果的列表
ret_list = html.xpath("xpath语法规则字符串")
- 返回空列表:根据xpath语法规则字符串,没有定位到任何元素
- 返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
- 返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
③使用实例
案例1:
from lxml import html
etree = html.etree
text = '''
-
first item
-
second item
-
third item
-
fourth item
-
a href="link5.html">fifth item
'''
# 创建element对象
html = etree.HTML(text)
# 返回结果的列表
print(html.xpath("//a/text()"))
print(html.xpath("//a/@href"))

案例2:
from lxml import html
etree = html.etree
text = '''
-
first item
-
second item
-
third item
-
fourth item
-
a href="link5.html">fifth item
'''
# 创建element对象
html = etree.HTML(text)
# 返回结果的列表
el_list = html.xpath('//a')
for el in el_list:
#print(el.xpath('./text()'))
#print(el.xpath('.//text()'))
print(el.xpath('text()')[0],':',el.xpath('./@href')[0])

案例3:百度贴吧爬取新闻数据
①分析抓包获取url、headers,找到要爬取的数据
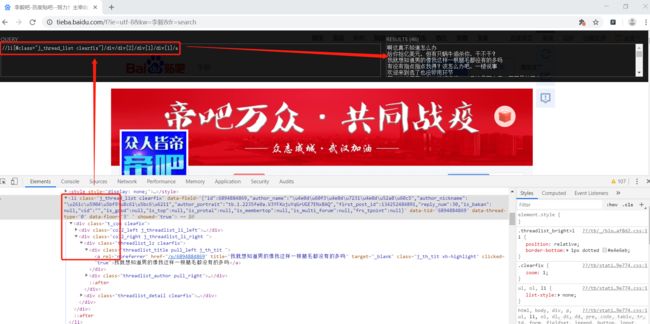
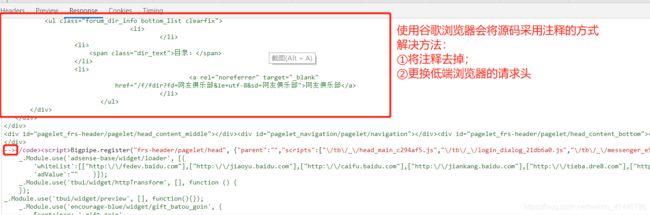
②在response发现需要爬取的数据被浏览器通过注释的方式隐藏起来
import requests
from lxml import html
etree = html.etree
class Tieba(object):
def __init__(self,name):
# url-headers
self.url = 'http://tieba.baidu.com/f?ie=utf-8&kw={}=search'.format(name)
self.headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
def get_data(self,url):
response = requests.get(url,headers = self.headers)
# 打印出来的源码可以发现会被注释
# with open("temp.html","wb") as f:
# f.write(response.content)
return response.content
def parse_data(self,data):
data = data.decode().replace("","")
# 利用replace函数将注释去掉后打印出为被注释的源码
# with open("temp2.html","wb") as f:
# f.write(data.encode())
# 创建element对象
html = etree.HTML(data)
el_list = html.xpath('//li[@class=" j_thread_list clearfix"]/div/div[2]/div[1]/div[1]/a')
data_list=[]
for el in el_list:
temp = {
}
temp['title'] = el.xpath("./text()")[0]
temp['link'] = 'http://tieba.baidu.com' + el.xpath('./@href')[0]
data_list.append(temp)
try:
next_url = 'http:' + html.xpath('//*[contains(text(),"下一页>")]/@href')[0]
except:
next_url = None
return data_list, next_url
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
# url-headers
# 发送请求,获取响应
next_url = self.url
while True:
data = self.get_data(next_url)
# 在响应中提取数据
data_list,next_url = self.parse_data(data)
# 保存数据
self.save_data(data_list)
# 判断是否终结
if next_url == None:
break
if __name__ == '__main__':
tieba = Tieba("李毅")
tieba.run()

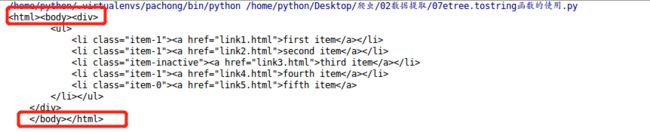
(8)lxml模块中etree.tostring函数的使用
- 自动补全原本缺失的li标签
- 自动补全html等标签
from lxml import html
etree = html.etree
html_str = '''
'''
html = etree.HTML(html_str)
handeled_html_str = etree.tostring(html).decode()
print(handeled_html_str)