计组复习(四):cache,虚拟内存,页表与TLB
目录
- 前言
- cache高速缓存
-
- 直接映射
- 全相连映射
- 组相连映射
- 多级 cache 的 CPI 计算
- 指令缓存与数据缓存
- 虚拟内存(重要⚠)
-
- 页表
- 缺页
- 替换
- TLB
- 例题(重要⚠)
- FastMath(重要⚠)
前言
来到存储器章节的复(yu)习。首先引入 cache 高速缓存,来缓解高速的 cpu 和低速的内存之间的拖带关系。然后是虚拟内存机制,虚拟内存能够很好的帮助程序员避免麻烦的内存管理与冲突等问题,并且将内存作为模块化独立出来。
上一篇博客回顾:计组复习(三):流水化的数据通路,流水线冒险检测与处理
在去年的计系 2 课程也讲到了 cache,本篇博客只是简单提一下,详情请戳我之前的博客:
计系2复习(4)存储:磁盘存储与cache
三种cache映射方式简单讲解
然后按照惯例,请出徐涛老师讲解复习要点与秘诀:

cache高速缓存
cpu 速度远快于内存,那么每次读取数据都需要等待内存就绪,坏起来了!
科学家们通过引入高速缓存 cache 来缓解这一矛盾。cache 更加靠近 cpu,访问速度也更快。cache 存储了一小部分内存的数据。
每次 cpu 需要访问内存时,首先问 cache 要,如果 cache 中存在对应的数据,那么 hit。如果 cache 中不存在,那么再向内存要数据,称为 miss。
cache 可以看作是一种硬件的哈希表,来快速查找 cache 中是否存在特定地址的数据,下面讲解三种场景的 cache 结构。
直接映射
直接映射模拟了以模除函数为哈希函数的哈希表,即所有地址经过模 n 之后,得到相同余数的,被分配到同一组。
即每一个 cache 行只能存储模 n 等于 x 的地址的数据!如下图:

优点是简单成本低,缺点是 miss 率高。
全相连映射
全相联映射意味着一个 cache 行可以存储任意内存地址的数据:

优点是 hit 率高,缺点是硬件实现复杂,成本高
组相连映射
组相连结合了全相连与值即映射的优缺点。首先通过直接映射,对不同的内存进行分组,然后每一组内使用全相连进行最终的查找。

折中的方案。
多级 cache 的 CPI 计算
多级 cache 按照级数分类讨论即可。只需要计算各级存储器的缺失代价,然后乘以概率。
此外,要注意缺失率是整体还是相对,比如下图 L2-cache 的缺失率就算整体缺失率,直接使用即可。
而如果是相对 L1-cache 的缺失率,那么还要像概率论一样,进行两个概率的乘法,计算 L1,L2 同时缺失的概率。

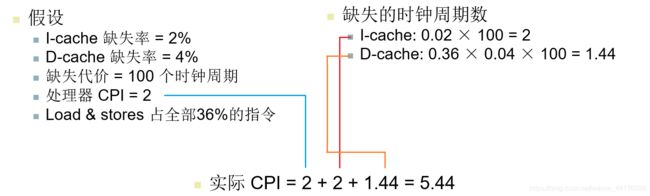
指令缓存与数据缓存
cache 也分指令缓存与数据缓存,数据缓存复杂存储来自内存的数据,指令缓存则复杂存储 cpu 将要执行的指令。
那么计算一个程序的实际 CPI 的时候,就需要分为三个部分:
- 理想状态下的 CPI
- 指令缓存 miss 造成的开销
- 数据缓存 miss 造成的开销
三个部分的加和才是实际情况下的 CPI,如下图:
虚拟内存(重要⚠)
在实际运行的过程中,程序会遇到一些问题:
-
申请一些连续的内存,或者释放它们。但是大家都要连续的内存,在物理内存的分配策略上就很棘手
-
程序需要的内存大小可能超过机器的内存大小,这意味着程序只能在特定的机器上面运行。
为了解决上述的两个问题,虚拟内存技术被提出来。虚拟内存技术提供一种虚拟地址到实际物理地址的映射,将连续的虚拟地址暴露给程序,而实际上他们在物理内存(比如内存条)上面是不连续的。
此外,虚拟内存还能解决内存不够用的情况,物理内存不够时,开辟一块磁盘空间作为额外的 “内存” 强行使用。如图:

页表
上文提到通过地址映射来进行虚拟地址到实际地址的换算。页表就是这样一种辅助换算的结构。我们人为地将内存分为一页一页,页是访问的最小单位(类似 cache 行的概念)
页表使用虚拟地址的页号作为索引,以找到实际物理存储器中的页号。每个程序都有一张自己的页表。索引的过程如下图:

以一个 4 KB 的页大小为例,那么一页就是 4096 字节,于是使用 12 bit 表示页内偏移,剩下的 20 bit 作为页号查询页表。
此外,页表存在于内存中,页表寄存器存储了页表的起始地址,下面给出计组书上的原图:

缺页
因为虚拟内存允许应用程序使用超出其物理内存大小的虚拟地址,那么意味着总有一些内存访问会向磁盘要数据。
页表中会有一个标志位(有效位),当其为 1 时表示当前页在内存中。为 0 则表示当前页在磁盘中。

当标志位为 0 时,无法直接向内存取数据,而是要访问磁盘。这个行为称为缺页。
替换
缺页发生时,必须向磁盘要数据。根据存储器的层次结构,我们要想向磁盘要数据,必然是将数据读入内存,再从内存中读取。
如果有效位是 1 那么直接读取(下图绿色标记):

如果有效位为 0,那么发生缺页(下图红色标记)。首先从磁盘中读取数据到内存(下图绿色标记)这个读会覆盖一页的数据。假设初始情况如下:
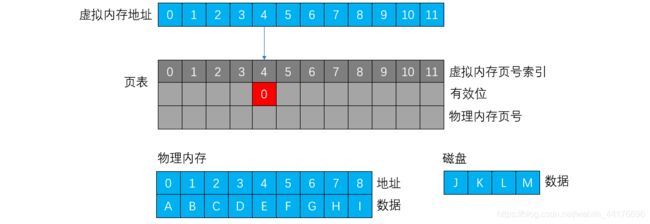
覆盖(替换)之后,数据 L 被读入内存中的某一页(2 号页):

然后 重写 页表的标志位和页号,因为此时 L 数据已经在内存了(下图绿色标记)那么下一次根据页表去内存就可以直接找到数据了:

这个替换可不是乱替换的。替换遵守最近最少使用原则(LRU,least recently use),即替换掉最近最不常用的页。
TLB
上文提到使用页表进行虚拟地址的转换。值得注意的是,页表也存在内存中!这意味着读取慢。前文提到 cache 可以加速内存的读取,于是我们引入一种特殊的 cache 来加速页表的访问。
现代 CPU 都包含一张名为 TLB(Transfer Look-aside Table),叫做快表,或者高速地址变址缓存,以加速对于页表的访问。加入 TLB 之后的完整地址映射长这样:

那么对于一次存取,就会有分 3 级的情况:
- TLB hit,直接访问内存取数据
- TLB miss,但是在内存中有对应页
- TLB miss,同时内存中没有对应页,发生缺页
例题(重要⚠)

首先看地址 4669,查找 TLB 发生 miss,然后查找页表,发现页表缺页:

然后我们从磁盘中,将对应的页读取到内存的第 13 页(13 也可以是其他数字,无所谓)。因为目标页已经在内存,我们改写页表和 TLB。注意在 TLB 中优先替换有效位为 0 的页:

再看地址 2227,查找 TLB 发生 miss,但是页表中存在对应项:
我们只需要改变 TLB 即可。这里先替换最旧的页,然后把替换后的页设置为最新:

最后看地址 13916,在 TLB 中直接 hit 了:

然后我们只需要将刚刚从 TLB 读取的页设置为最新即可,无需其他操作:

三种情况我都画了图,于是剩下的虚拟地址序列,如法炮制即可。(我是铁飞舞兼臭懒狗,懒得画图了
FastMath(重要⚠)
警告⚠
唔。。。我至今没搞懂这玩意的真正用途,因为我上课天天摸鱼 OTL
以下内容纯属嗯编+抄书,请谨慎食用
编辑下,之前嗯编的内容是错的。
上次不是说到除了 TLB,还有一个 cache 吗?那个 cache 的用途,我一开始以为是页表的 L2 cache,加速页表读取用的,后来发现不是这样。
我后来又看了下书,那个额外的 cache 是负责加速主存(内存)数据读取的,而 TLB 是加速页表读取的。
简而言之,TLB 是地址缓存,那个 cache 是数据缓存。那么其实就分为了三个情况:
- TLB 缺失,要去页表中找地址
- cache 缺失,要向内存要数据
- 缺页,要向磁盘要数据,同时更新 TLB 和 页表
先查找 TLB,如果缺失,那么查找页表,还缺就缺页了。如果查找 TLB 命中,那么根据 TLB 获取物理地址,然后查找数据 cache,就算普通的 cache 查找了。
