爬虫实战:批量爬取京东内衣图片(自动爬取多页,非一页)
做下男生想做的事,爬取大量妹子内衣图。
作者: 电气-余登武
准备工作
假如我们想把京东内衣类商品的图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用python爬虫实现。
第一步:分析网页地址
起始网页地址
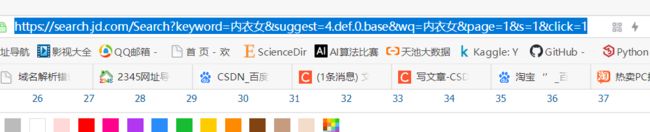
起始网页地址
https://search.jd.com/Search?keyword=%E5%86%85%E8%A1%A3%E5%A5%B3&suggest=4.def.0.base&wq=%E5%86%85%E8%A1%A3%E5%A5%B3&page=1&s=56&click=1
(在这里你会看到,明明在浏览器URL栏看到的是中文,但是复制url,粘贴到记事本或代码里面,就会变成如下这样?)
在很多网站的URL中对一些get的参数或关键字进行编码,所以我们复制出来的时候,会出现问题。但复制过来的网址可以直接打开。本例子不用管这个。
那么,怎样才能自动爬取第一页以外的其他页面,打开第三页,网页地址如下,分析发现和第一页区别在于:第一页最后&page=1,第三页&page=3
我们可以想到自动获取多个网页的方法,可以for循环实现,每次循环后,page+1
第三页网址如图
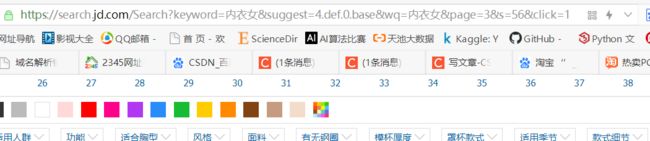
https://search.jd.com/Search?keyword=%E5%86%85%E8%A1%A3%E5%A5%B3&suggest=4.def.0.base&wq=%E5%86%85%E8%A1%A3%E5%A5%B3&page=3&s=56&click=1
第二步:分析网页图片链接
在每页中,我们都要提取对应的图片,可以使用正则表达式匹配源码中图片的链接部分,然后通过urllib.request.urlretrieve()将对应链接的图片保存到本地。
但是这里有一个问题,该网页中的图片不仅包括列表中的图片,还包括旁边一些无关图片。所以我们可以进行信息过滤。我们需要找到宝贝图片所在区域
- 操作步骤1:审查元素,找到第一页,第一个宝贝图片。元素如图
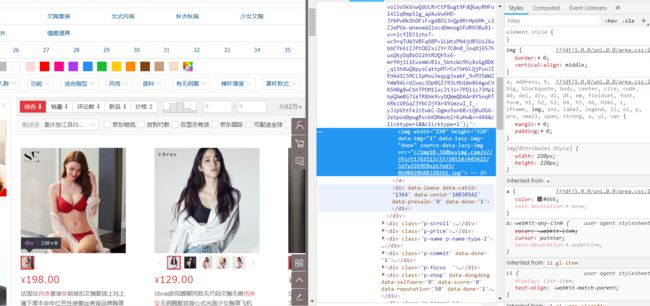
- 操作步骤2:空白处 单击查看源码
CTRL+F (搜索操作步骤1图片的最后几个字母)定位到宝贝1图片所在部分

我们通过几次定位,找到宝贝图片源码格式如下
图片1源码
<img width="220" height="220" data-img="1" data-lazy-img="//img13.360buyimg.com/n7/jfs/t1/88198/38/15103/241083/5e6ef386E75f87219/0945cd20a8d40904.jpg" />
图片2源码
<img width="220" height="220" data-img="1" data-lazy-img="//img10.360buyimg.com/n7/jfs/t1/62113/37/10114/445422/5d7a2269E8e2e7ed3/4b90428b88320241.jpg" />
于是我们可以定义正则规则
pat1='![]() 知识点.找到本机电脑网络的headers
知识点.找到本机电脑网络的headers
有的时候,我们无法爬取一些网页,会出现403错误,因为这些网页为了防止别人恶意采集信息所以进行了一些反爬虫的设置。
我们可以设置一些Headers信息,模拟成浏览器去访问这些网站,就能解决这个问题。
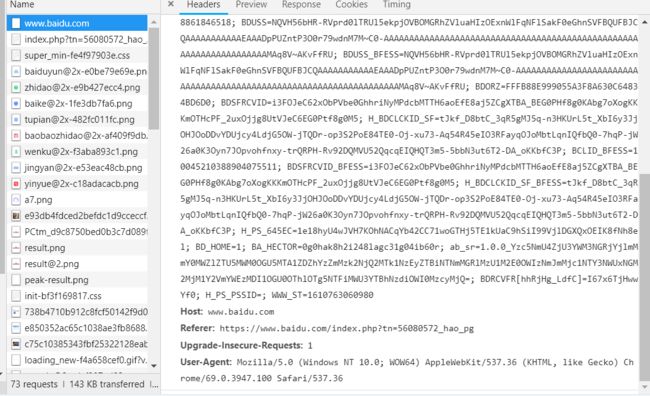
首先,单击网页中的百度一下,即让网页发生一个动作,下方窗口出现了很多数据,如图。

此时单击图中的www.baidu.com,出现如图
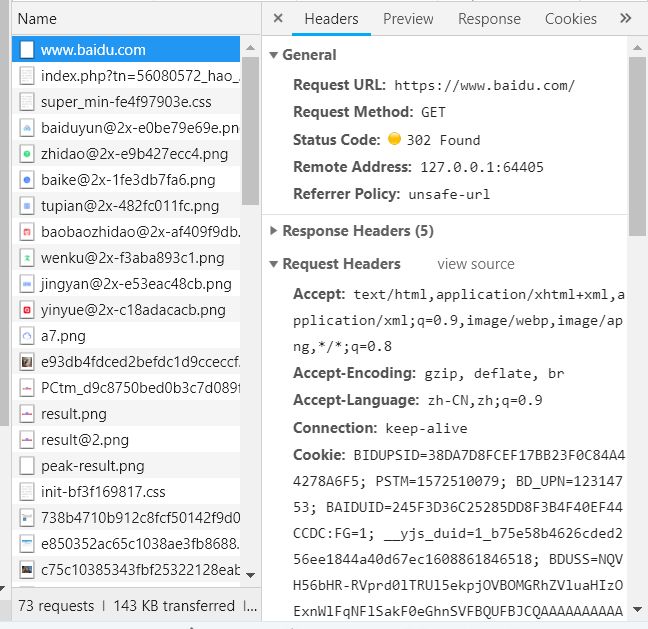
在Headers,往下拖动,找到User-agent
这一串信息就是我们下面模拟浏览器用到的信息,复制出来。
代码实现
语言:python
from urllib.parse import quote
import string
import re
from urllib import request
import urllib.request
#读取网页
def craw(url,page):
# 模拟成浏览器
headers = ("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# 将opener安装为全局
urllib.request.install_opener(opener)
url_request = request.Request(url)
html1 = request.urlopen(url_request, timeout=10)
html1 = html1.read().decode('utf-8') # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
html=str(html1)
#print(html)
#定位图片
pat1='![]() =re.compile(pat1).findall(html)
#print(imagelist)
x=1
for each in imagelist:
print(each)
try:
imagename='D:\\deeplearn\\xuexicaogao\\图片\\'+str(page)+str(x)+'.jpg'
imageurl="http://"+each #补全图片网页地址
request.urlretrieve(imageurl, filename=imagename) # 爬下载的图片放置在提前建好的文件夹里
except Exception as e:
print(e)
x+=1
finally:
print('下载完成。')
x+=1
for i in range(1,30):#遍历网页1-29
url="https://search.jd.com/Search?keyword=%E5%86%85%E8%A1%A3%E5%A5%B3&suggest=4.def.0.base&wq=%E5%86%85%E8%A1%A3%E5%A5%B3&page="+str(i)+"&s=56&click=1"
craw(url,i)
print('结束')
=re.compile(pat1).findall(html)
#print(imagelist)
x=1
for each in imagelist:
print(each)
try:
imagename='D:\\deeplearn\\xuexicaogao\\图片\\'+str(page)+str(x)+'.jpg'
imageurl="http://"+each #补全图片网页地址
request.urlretrieve(imageurl, filename=imagename) # 爬下载的图片放置在提前建好的文件夹里
except Exception as e:
print(e)
x+=1
finally:
print('下载完成。')
x+=1
for i in range(1,30):#遍历网页1-29
url="https://search.jd.com/Search?keyword=%E5%86%85%E8%A1%A3%E5%A5%B3&suggest=4.def.0.base&wq=%E5%86%85%E8%A1%A3%E5%A5%B3&page="+str(i)+"&s=56&click=1"
craw(url,i)
print('结束')

结果文件夹
文件夹里有800多张图
作者:电气-余登武

'</span>
</code></pre>
<p><strong><font color=) 知识点.找到本机电脑网络的headers
知识点.找到本机电脑网络的headers'</span>
imagelist<span class=) =
=