Soul网关源码分析-3期(吐血分析)
索引
-
- 分析选择器 - 一个让人感动的算法
- 分析 Dubbo 服务 - 中道崩殂...
- 分析同步配置 - Dubbo服务调不成功?!
- 分析请求类型解析
分析选择器 - 一个让人感动的算法
首先分别启动 soul-admin 、soul-bootstrap , 再启动两个相同的test服务组建集群 soul-test-http.
转到后台管理页的 Divide 插件页, 已经注册了的选择器 http 中, 可以看到两个服务路径的配置:

前置工作准备就绪, 在 DividePlugin 插件这打个断点, 看看 selector 的此时内容:
SelectorData(id=1349650852775989248, pluginId=5, pluginName=divide, name=/http, matchMode=0, type=1, sort=1, enabled=true, loged=true, continued=true, handle=[{"upstreamHost":"localhost","protocol":"http://","upstreamUrl":"192.168.31.233:8187","weight":"99"},{"upstreamHost":"localhost","protocol":"http://","upstreamUrl":"192.168.31.233:8188","weight":"1"}], conditionList=[ConditionData(paramType=uri, operator=match, paramName=/, paramValue=/http/**)])
重点的是 handle 属性, 存放两个真实路径信息, 以及权重 weight .
在 DividePlugin 的 doExecute() 中, 没有直接使用这个 Selector 的内容, 而是直接在缓存查询其id的对应信息:
final List<DivideUpstream> upstreamList = UpstreamCacheManager.getInstance().findUpstreamListBySelectorId(selector.getId());
对于检索到的 DivideUpstream 集合, 有包含权重、路径等信息, 并经过负载均衡工具类, 选择出一个服务:
DivideUpstream divideUpstream = LoadBalanceUtils.selector(upstreamList, ruleHandle.getLoadBalance(), ip);
继续追溯 LoadBalanceUtils 这部分:
public static DivideUpstream selector(final List<DivideUpstream> upstreamList, final String algorithm, final String ip) {
// 通过 algorithm, 确定返回的LoadBalance的子类
LoadBalance loadBalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getJoin(algorithm);
// 调用LoadBalance的select(), 从服务集群中选择一个节点
return loadBalance.select(upstreamList, ip);
}
这里就有疑问了, algorithm 是由上面 ruleHandle.getLoadBalance() 的信息得来, 而 ruleHandle 应该是规则配置, 仔细看了后台管理页面, 选择器中并没有规则配置, 规则配置被划分在更加细粒度的路径上了.
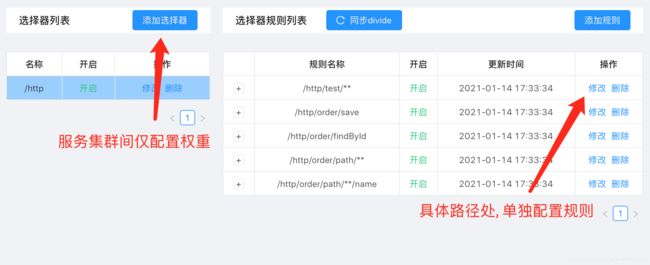
到这基本明白选择器的玩法了, 集群间的机器, 只有权重分数不同, 具体落实到不同路径上, 可以分配不同的规则.
负载规则总共有三种, hash (哈希)、random (随机)、roundRobin (轮询). 到这又有疑问了, 后面两个我大致能猜测到怎样与权重相作用, 使得实际比率与权重分比相匹配, 但哈希怎么去分呢? 看看 HashLoadBalance 代码吧:
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
final ConcurrentSkipListMap<Long, DivideUpstream> treeMap = new ConcurrentSkipListMap<>();
for (DivideUpstream address : upstreamList) {
// 每个节点*VIRTUAL_NODE_NUM(默认5), 使hash更加均匀
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long addressHash = hash("SOUL-" + address.getUpstreamUrl() + "-HASH-" + i);
treeMap.put(addressHash, address);
}
}
// 从当前ip得到一个hash值, 并比对treemap(有序), 找到大于此hash值的位置
long hash = hash(String.valueOf(ip));
SortedMap<Long, DivideUpstream> lastRing = treeMap.tailMap(hash);
// 只要服务节点不增减, 同一个ip得到的节点就可以保持不变
if (!lastRing.isEmpty()) {
return lastRing.get(lastRing.firstKey());
}
return treeMap.firstEntry().getValue();
}
并没有使用到 weight 属性, 可以看到, 当选用 hash 策略时, 权重就失去了其作用. 每个机器都有同等几率, 在某个ip下被访问到.
看下另一个负载均衡规则, RandomLoadBalance 是怎么实现权重的:
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
// 总个数
int length = upstreamList.size();
// 总权重
int totalWeight = 0;
// 权重是否都一样
boolean sameWeight = true;
for (int i = 0; i < length; i++) {
int weight = upstreamList.get(i).getWeight();
// 累计总权重
totalWeight += weight;
if (sameWeight && i > 0
&& weight != upstreamList.get(i - 1).getWeight()) {
// 计算所有权重是否一样
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
// 如果权重不相同且权重大于0则按总权重数随机
int offset = RANDOM.nextInt(totalWeight);
// 并确定随机值落在哪个片断上
for (DivideUpstream divideUpstream : upstreamList) {
offset -= divideUpstream.getWeight();
if (offset < 0) {
return divideUpstream;
}
}
}
// 如果权重相同或权重为0则均等随机
return upstreamList.get(RANDOM.nextInt(length));
}
PS: 这些注释是官方自带的…
这里可以通过注释很明白的得知, 当使用 random 规则时, 所有节点权重分累加并随机得到数字, 看具体是落在那个节点的权重片段上; 如果分数0或者相同则很直接的随机集群长度即可.
最后看下 `RoundRobinLoadBalance` 的实现:
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
String key = upstreamList.get(0).getUpstreamUrl();
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.get(key);
if (map == null) {
methodWeightMap.putIfAbsent(key, new ConcurrentHashMap<>(16));
map = methodWeightMap.get(key);
}
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
DivideUpstream selectedInvoker = null;
WeightedRoundRobin selectedWRR = null;
for (DivideUpstream upstream : upstreamList) {
String rKey = upstream.getUpstreamUrl();
// 取出节点在缓存中的信息
WeightedRoundRobin weightedRoundRobin = map.get(rKey);
int weight = upstream.getWeight();
if (weightedRoundRobin == null) {
weightedRoundRobin = new WeightedRoundRobin();
weightedRoundRobin.setWeight(weight);
map.putIfAbsent(rKey, weightedRoundRobin);
}
if (weight != weightedRoundRobin.getWeight()) {
weightedRoundRobin.setWeight(weight);
}
// 这里是第一个关键: 缓存中的分数增加当前节点权重分
long cur = weightedRoundRobin.increaseCurrent();
weightedRoundRobin.setLastUpdate(now);
// 选择缓存分值高的节点
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = upstream;
selectedWRR = weightedRoundRobin;
}
totalWeight += weight;
}
if (!updateLock.get() && upstreamList.size() != map.size() && updateLock.compareAndSet(false, true)) {
try {
ConcurrentMap<String, WeightedRoundRobin> newMap = new ConcurrentHashMap<>(map);
newMap.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > recyclePeriod);
methodWeightMap.put(key, newMap);
} finally {
updateLock.set(false);
}
}
if (selectedInvoker != null) {
// 这里是第二个关键: 缓存中的分数, 减少总节点权重分
selectedWRR.sel(totalWeight);
return selectedInvoker;
}
return upstreamList.get(0);
}
这个算法有点复杂, 我解释下核心计算权重的方面:
- 两个分值分别为2、100的节点进入, 缓存中保留它们各自, 分值从0开始
- 经过for循环后, 两个节点在缓存中的分值会以自身为基数增加, 假设后面步骤不进行, 则缓存第一次为2、100, 第二次为4、200, 依次类推.
- 关键的第三步, 选出节点缓存中分值最高的, 进行"处罚"措施, 减少所有节点的累计分值, 即102.
根据这个算法的步骤, 一直没有被选中的节点, 作为"成长奖励", 会持续以自身为基数自增; 而被选中的节点, 作为"惩罚", 会减少其他节点的权重分之和.
可以预见, 权重分小的节点, 要自增到很久之后, 才会等来自身被选中的一刻, 然而那一刻它被惩罚的力度会非常大, 导致它一朝回到解放前, 又要开始漫长的积蓄力量. 而权重分大的节点, 每次被选上的惩罚力度很小, 即使多次后分数太低没被选上, 他的奖励分数(自身)也特别高, 一次增加就远远超越其他节点.
(就仿佛看到了一个没有天赋但一直努力的平凡人, 然而上天仿佛给他开了玩笑, 每到一定时间, 必然降下天罚, 更可悲的是, 千百次的努力也抵不过一次惩罚, 一切又是归0… 周而往复, 这个平凡的人, 依旧还会用千百次追逐换一次短暂的露头, 可恶, 我被一个算法感动到了!)
分析 Dubbo 服务 - 中道崩殂…
启动 soul-test-alibaba-dubbo-service 项目注册Dubbo服务. 注意要在后台管理的插件管理中, 将Dubbo插件开启, 并运行 Zookeeper 服务.
启动后老习惯, 看看打印的日志里能捞出什么信息:
2021-01-17 00:08:06.702 INFO 2244 --- [pool-1-thread-1] a.d.AlibabaDubboServiceBeanPostProcessor : dubbo client register success :{} {"appName":"dubbo","contextPath":"/dubbo","path":"/dubbo/saveComplexBeanTestAndName","pathDesc":"","rpcType":"dubbo","serviceName":"org.dromara.soul.test.dubbo.api.service.DubboMultiParamService","methodName":"saveComplexBeanTestAndName","ruleName":"/dubbo/saveComplexBeanTestAndName","parameterTypes":"org.dromara.soul.test.dubbo.api.entity.ComplexBeanTest,java.lang.String","rpcExt":"{\"timeout\":10000}","enabled":true}
首先看到启动过程中陆陆续续的打出这类日志, 表示注册了相关Dubbo服务, 这里有资源名、类名方法名等信息, 关键类 AlibabaDubboServiceBeanPostProcessor 中追溯下, 发现还是与http服务的注册基本一样, 老一套也恰恰说明, soul 将dubbo服务与http服务定义了同样的元数据, 设计很好的体现. 之后可以看看元数据这方面的设计.
其他信息就没什么有价值的了, 都是Dubbo包打出来的.
分析同步配置 - Dubbo服务调不成功?!
在调用网关转发 Dubbo 服务期间发生了意外, 没有成功调取, 于是在插件祖宗类 SoulPlugin 上断点, 看下都进了哪些插件. 发现除了 WebClientPlugin 和 WebClientResponsePlugin, 其他都走了一遍. Web的不走是正确的, 本身是Dubbo服务, 但是, 最关键的是没有看到 DubboPlugin .
于是继续追溯, 检查 SoulWebHandler 中获取到的 plugins 列表, 发现还是那9个, 并没有Dubbo插件, 继续探索!
发现 soul-bootstrap 在启动时的配置 SoulConfiguration , 有获取:
@Bean("webHandler")
public SoulWebHandler soulWebHandler(final ObjectProvider<List<SoulPlugin>> plugins) {
List<SoulPlugin> pluginList = plugins.getIfAvailable(Collections::emptyList);
final List<SoulPlugin> soulPlugins = pluginList.stream()
.sorted(Comparator.comparingInt(SoulPlugin::getOrder)).collect(Collectors.toList());
soulPlugins.forEach(soulPlugin -> log.info("loader plugin:[{}] [{}]", soulPlugin.named(), soulPlugin.getClass().getName()));
return new SoulWebHandler(soulPlugins);
}
尝试重启网关并断点, 仍然只有9个插件, 疑惑十足. 这时想起, 分析源码第0期, 有在 soul-bootstrap 启动日志中, 看到和 soul-admin 建立 WebSocket 的相关类 WebsocketSyncDataService, 当时还记了一笔日后要分析它的同步配置, 没想到来的这么快…
跟踪 WebsocketSyncDataService 的构造器, 找到监听类 SoulWebsocketClient :
@Override
public void onMessage(final String result) {
handleResult(result);
}
private void handleResult(final String result) {
WebsocketData websocketData = GsonUtils.getInstance().fromJson(result, WebsocketData.class);
ConfigGroupEnum groupEnum = ConfigGroupEnum.acquireByName(websocketData.getGroupType());
String eventType = websocketData.getEventType();
String json = GsonUtils.getInstance().toJson(websocketData.getData());
websocketDataHandler.executor(groupEnum, json, eventType);
}
这个 handleResult() 方法处断点, 并在 管理后台 手动点下同步配置, 这里看到传入更新插件的json:
{
"groupType": "PLUGIN",
"eventType": "REFRESH",
"data": [
{
"id": "1",
"name": "sign",
"role": 0,
"enabled": false
},
{
"id": "2",
"name": "waf",
"config": "{\"model\":\"black\"}",
"role": 0,
"enabled": false
},
{
"id": "3",
"name": "rewrite",
"role": 0,
"enabled": false
},
{
"id": "4",
"name": "rate_limiter",
"config": "{\"master\":\"mymaster\",\"mode\":\"Standalone\",\"url\":\"192.168.1.1:6379\",\"password\":\"abc\"}",
"role": 0,
"enabled": false
},
{
"id": "5",
"name": "divide",
"role": 0,
"enabled": true
},
{
"id": "6",
"name": "dubbo",
"config": "{\"register\":\"zookeeper://localhost:2181\"}",
"role": 0,
"enabled": true
},
{
"id": "7",
"name": "monitor",
"config": "{\"metricsName\":\"prometheus\",\"host\":\"localhost\",\"port\":\"9190\",\"async\":\"true\"}",
"role": 0,
"enabled": false
},
{
"id": "8",
"name": "springCloud",
"role": 0,
"enabled": false
},
{
"id": "9",
"name": "hystrix",
"role": 0,
"enabled": false
}
]
}
可以看到, soul-admin 传来的配置信息都是正确的, 继续追溯 handleResult , 找到 WebsocketDataHandler 的抽象类 AbstractDataHandler:
public void handle(final String json, final String eventType) {
List<T> dataList = convert(json);
if (CollectionUtils.isNotEmpty(dataList)) {
DataEventTypeEnum eventTypeEnum = DataEventTypeEnum.acquireByName(eventType);
switch (eventTypeEnum) {
case REFRESH:
case MYSELF:
doRefresh(dataList);
break;
case UPDATE:
case CREATE:
doUpdate(dataList);
break;
case DELETE:
doDelete(dataList);
break;
default:
break;
}
}
}
这里就是网关的同步刷新机制核心处了, 根据debug找到 doRefresh , 找到插件相关的更新类 PluginDataHandler :
protected void doRefresh(final List<PluginData> dataList) {
// 类似清理缓存, 先跳过不管, 关注更新方法
pluginDataSubscriber.refreshPluginDataSelf(dataList);
// 追溯这个方法
dataList.forEach(pluginDataSubscriber::onSubscribe);
}
追溯到 CommonPluginDataSubscriber 类:
public void onSubscribe(final PluginData pluginData) {
BaseDataCache.getInstance().cachePluginData(pluginData);
Optional.ofNullable(handlerMap.get(pluginData.getName())).ifPresent(handler -> handler.handlerPlugin(pluginData));
}
这里的第二句, 看的出从map匹配对应的handler实现, 不为空则执行. 查看 PluginDataHandler 的实现, 包含有 AlibabaDubboPluginDataHandler 这个看上去和 Dubbo相关的数据更新类, 但为什么插件没出来呢?
debug到 handlerMap 的数据后, 终于发现问题所在! 这里的内容, 仅包含之前见到的几个插件, 根本没有 Dubbo插件的名称, 看来问题就出在这里了.
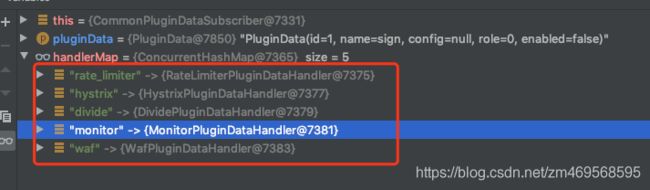
追溯 handlerMap 的来源, 又回到一切配置的源头 SoulConfiguration 类, 这里的 pluginDataSubscriber 方法, 注入了 handlerMap 的所有信息:
@Bean
public PluginDataSubscriber pluginDataSubscriber(final ObjectProvider<List<PluginDataHandler>> pluginDataHandlerList) {
return new CommonPluginDataSubscriber(pluginDataHandlerList.getIfAvailable(Collections::emptyList));
}
这是spring bean , 自然是启动时加载的数据, 那么这些可读取的插件信息, 就肯定来自与配置文件.
又是漫长的时间过去, 最终检查到 soul-bootstrap 的 pom.xml 这里, 看到 alibaba-dubbo 这里的屏蔽状态, 我立刻相通了…
<dependency>
<groupId>org.dromaragroupId>
<artifactId>soul-spring-boot-starter-plugin-alibaba-dubboartifactId>
<version>${project.version}version>
dependency>
解开真相, 找到 soul-spring-boot-starter-plugin-alibaba-dubbo 项目的 AlibabaDubboPluginConfiguration 类, 这里就有我苦苦找寻的 Dubbo插件数据更新处理类:
@Bean
public PluginDataHandler alibabaDubboPluginDataHandler() {
return new AlibabaDubboPluginDataHandler();
}
将 soul-bootstrap 网关的pom中alibaba-dubbo启用并重启项目, 它在 CommonPluginDataSubscriber 里静静躺着:

尝试 http调用网关dubbo服务, 测试通过! 太辛苦了!
分析请求类型解析
尝试调用dubbo的时候又发生了个小插曲, 调用没有走通在 DividePlugin 这里被吃掉了, 没有走到 DubboPlugin 处. 折腾了一会后 (重启等) 再次调用又好了, 在这里分析下原因:
首先 DividePlugin 插件在 DubboPlugin 插件前, 如果走入 DividePlugin 且没匹配到规则, 会直接 return 掉, 在 AbstractSoulPlugin 的 execute() 这里:
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
String pluginName = named();
final PluginData pluginData = BaseDataCache.getInstance().obtainPluginData(pluginName);
if (pluginData != null && pluginData.getEnabled()) {
final Collection<SelectorData> selectors = BaseDataCache.getInstance().obtainSelectorData(pluginName);
if (CollectionUtils.isEmpty(selectors)) {
return CheckUtils.checkSelector(pluginName, exchange, chain);
}
final SelectorData selectorData = matchSelector(exchange, selectors);
// 规则未匹配到, 进入这里
if (Objects.isNull(selectorData)) {
if (PluginEnum.WAF.getName().equals(pluginName)) {
return doExecute(exchange, chain, null, null);
}
return CheckUtils.checkSelector(pluginName, exchange, chain);
}
...
}
return chain.execute(exchange);
}
CheckUtils 类这里, 会打印规则未匹配的日志, 并return:
public static Mono<Void> checkRule(final String pluginName, final ServerWebExchange exchange, final SoulPluginChain chain) {
if (PluginEnum.DIVIDE.getName().equals(pluginName)
|| PluginEnum.DUBBO.getName().equals(pluginName)
|| PluginEnum.SPRING_CLOUD.getName().equals(pluginName)) {
LOGGER.error("can not match rule data :{}", pluginName);
Object error = SoulResultWarp.error(SoulResultEnum.RULE_NOT_FIND.getCode(), SoulResultEnum.RULE_NOT_FIND.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
return chain.execute(exchange);
}
所以, 如果关于 Dubbo 服务的调用, 只要走入 DividePlugin 肯定就出不去了, 正常的情况是怎样呢? 会跳过 DividePlugin 直接下一个的, 具体看 SoulWebHandler 这:
public Mono<Void> execute(final ServerWebExchange exchange) {
return Mono.defer(() -> {
if (this.index < plugins.size()) {
SoulPlugin plugin = plugins.get(this.index++);
// 如果是dubbo调用, 轮到DividePlugin时会跳过的
Boolean skip = plugin.skip(exchange);
if (skip) {
return this.execute(exchange);
} else {
return plugin.execute(exchange, this);
}
} else {
return Mono.empty();
}
});
}
继续追踪 DividePlugin 的 skip() 方法:
public Boolean skip(final ServerWebExchange exchange) {
final SoulContext soulContext = exchange.getAttribute(Constants.CONTEXT);
// 检查调用类型是否是 http
return !Objects.equals(Objects.requireNonNull(soulContext).getRpcType(), RpcTypeEnum.HTTP.getName());
}
这里得到的 RPCType 正常是 dubbo , 说明刚刚的调用时返回的上下文中 soulContext 信息有误.
查看下 rpcType 属性被谁引用, 看到 DefaultSoulContextBuilder 类有 set() 过, debug追溯, 发现每次请求, 都会进入这里的 build() 去注入相关信息给上下文:
public SoulContext build(final ServerWebExchange exchange) {
final ServerHttpRequest request = exchange.getRequest();
String path = request.getURI().getPath();
// 这里是关键, 通过链接解析元数据, 得到rpcType类型
MetaData metaData = MetaDataCache.getInstance().obtain(path);
if (Objects.nonNull(metaData) && metaData.getEnabled()) {
exchange.getAttributes().put(Constants.META_DATA, metaData);
}
return transform(request, metaData);
}
private SoulContext transform(final ServerHttpRequest request, final MetaData metaData) {
final String appKey = request.getHeaders().getFirst(Constants.APP_KEY);
final String sign = request.getHeaders().getFirst(Constants.SIGN);
final String timestamp = request.getHeaders().getFirst(Constants.TIMESTAMP);
SoulContext soulContext = new SoulContext();
String path = request.getURI().getPath();
soulContext.setPath(path);
if (Objects.nonNull(metaData) && metaData.getEnabled()) {
if (RpcTypeEnum.SPRING_CLOUD.getName().equals(metaData.getRpcType())) {
setSoulContextByHttp(soulContext, path);
// 这里将元数据的rpctype注入到上下文中
soulContext.setRpcType(metaData.getRpcType());
} else {
setSoulContextByDubbo(soulContext, metaData);
}
} else {
setSoulContextByHttp(soulContext, path);
soulContext.setRpcType(RpcTypeEnum.HTTP.getName());
}
soulContext.setAppKey(appKey);
soulContext.setSign(sign);
soulContext.setTimestamp(timestamp);
soulContext.setStartDateTime(LocalDateTime.now());
Optional.ofNullable(request.getMethod()).ifPresent(httpMethod -> soulContext.setHttpMethod(httpMethod.name()));
return soulContext;
}
继续追踪解析类 MetaDataCache:
public MetaData obtain(final String path) {
MetaData metaData = META_DATA_MAP.get(path);
if (Objects.isNull(metaData)) {
String key = META_DATA_MAP.keySet().stream().filter(k -> PathMatchUtils.match(k, path)).findFirst().orElse("");
return META_DATA_MAP.get(key);
}
return metaData;
}
其中的 PathMatchUtils 会去匹配并输出类型, 不继续跟踪了, 明日尝试下看还能否复现问题…