西瓜书-sklearn中逻辑回归算法
要求
- 学习时长:6/27—6/28
- 任务标题:学习sklearn包中逻辑回归算法的使用
- 任务简介:实验-sklearn-user guide 1.1.11
- 任务详解:
本节的主要任务是,了解sklearn包中逻辑回归算法的使用。逻辑回归算法大家基本了解了,简单使用大家也用过了。
但是这次实验的主要目的,是让大家了解一下sklearn包的官网,这个官网提供了详细的教程和案例,对于机器学习来讲是一种最为宝贵的资源,我们应该怎么使用这个官网来进行机器学习的学习,和实际任务的开发,这个资源也是我们日后学习的一个重点内容。
资料链接:https://scikit-learn.org/dev/modules/linear_model.html#logistic-regression - 内容:参照链接给的代码,实际动手敲一遍,使用sklearn的逻辑回归接口实现MNIST 分类,将运行结果截图。
https://scikit-learn.org/stable/autoexamples/linearmodel/plotsparselogisticregressionmnist.html#sphx-glr-auto-examples-linear-model-plot-sparse-logistic-regression-mnist-py
知识点
- 分类模型
- 使用逻辑函数对描述单个试验的可能结果的概率进行建模
函数
Logistic回归实现于LogisticRegression。此实现可以使用可选的二进制,一对多静态或多项逻辑回归 ℓ 1 \ell_1 ℓ1, ℓ 2 \ell_2 ℓ2或弹性网络正规化。(使用正则化增加使模型更好训练,增加泛化性,提高数值稳定性;正则化相当于将C设置为非常高的值)
 1)“liblinear”使用坐标下降(CD)算法,并依赖于scikit-learn附带的优秀C ++ LIBLINEAR库。然而,在liblinear中实现的CD算法无法学习真正的多项(多类)模型; 相反,优化问题以“一对一”方式分解,因此为所有类训练单独的二元分类器。这发生在幕后,因此 LogisticRegression使用此解算器的实例表现为多类分类器。对于 ℓ 1 \ell_1 ℓ1正则化sklearn.svm.l1_min_c允许计算C的下界,以便获得非“空”(所有特征权重为零)模型。
1)“liblinear”使用坐标下降(CD)算法,并依赖于scikit-learn附带的优秀C ++ LIBLINEAR库。然而,在liblinear中实现的CD算法无法学习真正的多项(多类)模型; 相反,优化问题以“一对一”方式分解,因此为所有类训练单独的二元分类器。这发生在幕后,因此 LogisticRegression使用此解算器的实例表现为多类分类器。对于 ℓ 1 \ell_1 ℓ1正则化sklearn.svm.l1_min_c允许计算C的下界,以便获得非“空”(所有特征权重为零)模型。
2)“lbfgs”,“sag”和“newton-cg”解算器只支持 ℓ 2 \ell_2 ℓ2正则化或没有正则化,并且发现对于某些高维数据更快收敛。multi_class使用这些求解器设置为“多项式”可以学习一个真正的多项Logistic回归模型[5],这意味着它的概率估计应该比默认的“one-vs-rest”设置更好地校准。
3) “下垂”求解器使用随机平均梯度下降[6]。当样本数量和特征数量都很大时,它比大型数据集的其他求解器更快。
4)“saga”解算器[7]是“sag”的变体,也支持非平滑penalty=“l1”。因此,这是稀疏多项Logistic回归的首选求解器。它也是唯一支持的解算器 penalty=“elasticnet”。
5)“lbfgs”是一种近似于Broyden-Fletcher-Goldfarb-Shanno算法的优化算法[8],属于准牛顿方法。建议将“lbfgs”求解器用于小型数据集,但对于较大的数据集,其性能会受到影响。[9]
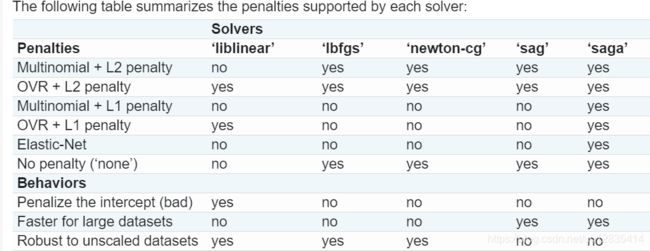
6)默认情况下,“lbfgs”求解器用于其稳健性。对于大型数据集,“saga”解算器通常更快。对于大型数据集,您还可以考虑使用SGDClassifier “log”丢失,这可能更快,但需要更多调整。
- 使用稀疏逻辑回归进行特征选择
逻辑回归与 ℓ1惩罚产生稀疏模型,因此可用于执行特征选择,如基于L1的特征选择中所详述 。
参数
LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
1.penalty:
正则化项的选择。正则化主要有两种:L1和L2,LogisticRegression默认选择L2正则化。
‘liblinear’ 支持L1和L2,但‘newton-cg’, ‘sag’ 和‘lbfgs’ 只支持L2正则化。
2.dual:bool(True、False), default:False
如果为True,则求解对偶形式,只有在penalty=‘l2’ 且solver=‘liblinear’ 时有对偶形式;通常样本数大于特征数的情况下,默认为False,求解原始形式。
3.tol : float, default:1e-4
停止标准,误差不超过tol时,停止进一步的计算。
4.C :float,default:1.0
正则化强度(正则化系数λ)的倒数; 必须是大于0的浮点数。 与支持向量机一样,较小的值指定更强的正则化,通常默认为1。
5.fit_intercept:bool(True、False),default:True
是否存在截距,默认存在。
6.intercept_scaling :float,default :1.0
仅在使用solver为“liblinear”且fit_intercept=True时有用。 在这种情况下,x变为[x,intercept_scaling],即具有等于intercept_scaling的常数值的“合成”特征被附加到实例矢量。 截距变成了intercept_scaling * synthetic_feature_weight. 注意: 合成特征权重与所有其他特征一样经受l1 / l2正则化。 为了减小正则化对合成特征权重(并因此对截距)的影响,必须增加intercept_scaling。相当于人造一个特征出来,该特征恒为 1,其权重为b。
7.class_weight :dict or ‘balanced’,default:None
class_weight参数用于标示分类模型中各种类型的权重,可以不输入,即不考虑权重,或者说所有类型的权重一样。如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者我们自己输入各个类型的权重,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9, 1:0.1},这样类型0的权重为90%,而类型1的权重为10%。
如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))
8.random_state:
int,RandomState instance or None,optional,default:None
在随机数据混洗时使用的伪随机数生成器的种子。 如果是int,则random_state是随机数生成器使用的种子; 如果是RandomState实例,则random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。 在求solver是’sag’或’liblinear’时使用。
9.solver :‘newton-cg’,‘lbfgs’,‘liblinear’,‘sag’,‘saga’,default:liblinear
liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
saga:线性收敛的随机优化算法。
对于小型数据集,‘liblinear’是一个不错的选择,而’sag’和’saga’对于大型的更快。对于多类问题,只有’newton-cg’,‘sag’,'saga’和’lbfgs’处理多项损失;'liblinear’仅限于一项损失。 ‘newton-cg’,'lbfgs’和’sag’只处理L2惩罚,而’liblinear’和’saga’处理L1惩罚。“sag”和“saga”快速收敛仅在具有大致相同比例的要素上得到保证, 可以使用sklearn.preprocessing中的缩放器预处理数据。
10.max_iter:int ,default:100
仅适用于newton-cg,sag和lbfgs求解器。 求解器收敛的最大迭代次数。
11.multi_class:str,{‘ovr’, ‘multinomial’},default:‘ovr’
‘ovr’ :采用 one-vs-rest 策略,‘multinomial’:直接采用多分类逻辑回归策略。
多类选项可以是’ovr’或’multinomial’。 如果选择的选项是’ovr’,那么二进制问题适合每个标签。 另外,最小化损失是整个概率分布中的多项式损失拟合。 不适用于liblinear解算器。
12.verbose:int,default:0
对于liblinear和lbfgs求解器,将verbose设置为任何正数以表示详细程度。用于开启/关闭迭代中间输出的日志。
13.warm_start:bool(True、False),default:False
如果为True,那么使用前一次训练结果继续训练,否则从头开始训练。对于liblinear解算器没用。
14.n_jobs:int,default:1
如果multi_class =‘ovr’,则在对类进行并行化时使用的CPU数量。 无论是否指定’multi_class’,当solver设置为’liblinear’时,都会忽略此参数。 如果给定值-1,则使用所有CPU。
参考文献:
[5] Christopher M. Bishop:模式识别和机器学习,第4.3.4章
[6] Mark Schmidt,Nicolas Le Roux和Francis Bach:用随机平均梯度最小化有限和。
[7] Aaron Defazio,Francis Bach,Simon Lacoste-Julien:SAGA:一种支持非强凸复合目标的快速增量梯度法。
[8] https://en.wikipedia.org/wiki/Broyden–Fletcher–Goldfarb–Shanno_algorithm
[9] “Lbfgs与其他求解器的性能评估”
本文参考:
- sklearn:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html