python学习笔记 - 读写CSV文件
文章目录
- 1、前言
-
- 1.1、CSV简介
- 1.2、CSV文件读写方式分类
- 2、以列表为单位读写CSV文件
-
- 2.1、以列表为单位读取CSV文件(reader)
-
- 2.1.1、生成CSV文件读取对象
- 2.1.2、读取CSV文件
- 2.2、以列表为单位写入CSV文件(writer)
-
- 2.2.1、生成CSV文件写入对象
- 2.2.2、写入CSV文件
- 3、以字典为单位读写CSV文件
-
- 3.1、以字典为单位读取CSV文件(DictReader)
-
- 3.1.1、实例化CSV文件读取对象
- 3.1.2、获取每一列的标题
- 3.1.3、遍历CSV文件中的每条记录与字段
- 3.2、以字典为单位写入CSV文件(DictWriter)
-
- 3.2.1、实例化CSV文件写入类
- 3.2.2、添加标题行
- 3.2.3、添加数据行
1、前言
1.1、CSV简介
CSV的英文全称为:Comma-Separated Values,翻译过来就是:用逗号分隔的值。时至今日,CSV已经不限于仅仅支持以逗号去分隔数据。那么CSV文件中的数据都是以什么样的方式存储的呢:
- csv文件以纯文本的形式去存储表格数据。
- csv文件由任意数目的记录组成,通常,所有记录都有完全相同的字段序列。记录之间以某种换行符分隔,如:’\n’。
- csv中的每条记录由多个字段组成,每个字段之间以某种分隔符分隔,常见如:, 、| 、制表符。
CSV文件为纯文本文件,建议使用记事本来开启,其中使用逗号分隔每条记录中的字段:

或者,也可以另存新档后用Excel开启:
python三方库提供了csv库,我们需要通过这个库,来实现对CSV文件的读与写。所以我们在应用csv库之前,需要提前安装它。
# win:
pip install csv
# mac
pip3 install csv
# 若提示下载超时,则用以下的方式安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple csv
注意,本文的案例因为大多都是案例片段,最终显示的代码都没有关闭文档对象,在实际的运用中切记要关闭,或者使用with open as的方式打开。
1.2、CSV文件读写方式分类
csv库提供了两种读写csv文件的方式:以列表为单位读写csv文件、以字典为单位读写csv文件。
- 以列表为单位读写csv文件:csv文件中的每条记录以列表为单位呈现或操作。
- 以字典为单位读写csv文件:csv文件中的每条记录以字典为单位呈现或操作。
2、以列表为单位读写CSV文件
在1.1简介中,我们打开csv文件后发现,csv文件的数据中的每行数据都有这相同的字段序列,分别以姓名,语文,数学,英语的顺序排列组成每条记录。python中,我们可以用列表模拟csv文件中的每条数据关系。列表的有序性,可以很方便的表达或存储csv文件中的每条记录。我们可以通过列表的这个特性,去完成对csv文件的读写操作。
2.1、以列表为单位读取CSV文件(reader)
2.1.1、生成CSV文件读取对象
csv模块下提供了reader方法,用于生成一个可以方便用户读取csv文件的对象。我们先来看看这个接口的定义:
def reader(iterable, dialect='excel', *args, **kwargs):
"""
...
The "iterable" argument can be any object that returns a line
of input for each iteration, such as a file object or a list.
...
"""
我们从该接口对iterable参数的描述可知:
| 参数 | 类型 | 说明 |
|---|---|---|
| iterable | 可迭代对象(如列表)、文件对象 | 该参数可以赋一个可迭代对象,也可以赋一个文件对象。 |
我们需要操作csv文件,所以显然此处我们需要给iterable参数传递一个文件对象。即我们平时用到的open打开的文件。首先open中的参数newline必须赋值为’’,即newline=’’;其次,若编码集参数encoding期望值为utf-8,最好写成utf-8-sig,即encoding=‘utf-8-sig’。这样可以避免第一个获取到的值存在一段未解码的字符串;最后,既然是读取类,我们在使用open打开csv文件的时候当然需要以“读”的方式去打开。比如我们需要打开一个测试数据.csv,并生成一个csv读对象
csv_file = open('./测试数据.csv', 'r', encoding='utf-8-sig', newline='')
csv_reader = csv.reader(csv_file)
2.1.2、读取CSV文件
获取到csv读取对象后,我们就可以通过csv读取对象读取csv文件中的内容,csv文件读取对象是一个可遍历的对象,我们可以通过for循环遍历的方式,去获取csv文件中的数据:
for row in csv_reader:
print(type(row)) # 可以看到,每轮遍历都会获取一个列表,该列表中的元素就是遍历行的各个字段值。
2.2、以列表为单位写入CSV文件(writer)
2.2.1、生成CSV文件写入对象
csv模块下提供了writer方法,用于生成一个可以写入csv文件的对象。我们先来看看这个接口的定义:
def writer(fileobj, dialect='excel', *args, **kwargs):
"""
...
The "fileobj" argument can be any object that supports the file API.
...
"""
在此处,fileobj对象似乎跟读文件限制不同,但是我们需要将数据写入csv文件中,所以此处fileobj还是一个以“写”的方式打开的文件。生成csv文件写入对象的方法如下:
csv_file = open('./测试数据.csv', 'w', encoding='utf-8-sig', newline='')
csv_writer = csv.writer(csv_file)
2.2.2、写入CSV文件
csv文件写入对象提供了单条记录写入(writerow)与多条记录同时写入(writerows)的方法,大大的便捷了我们去写入csv文件。(我的python环境为3.9)
class _writer:
dialect: Dialect
if sys.version_info >= (3, 5):
def writerow(self, row: Iterable[Any]) -> Any: ...
def writerows(self, rows: Iterable[Iterable[Any]]) -> None: ...
else:
def writerow(self, row: Sequence[Any]) -> Any: ...
def writerows(self, rows: Iterable[Sequence[Any]]) -> None: ...
-
单条记录写入
我们首先查看一下writerow方法的定义:def writerow(self, row: Iterable[Any])从参数的定义中我们可以看到,writerow方法需要传递一个可迭代的对象,常见的如列表、元组。如:
data_row = ['张三', '90', '95', '93'] csv_writer.writerow(data_row) -
多条记录同时写入
我们查看一下writerows方法的定义:def writerows(self, rows: Iterable[Iterable[Any]])从参数的定义中我们可以看到,writerows方法需要传递一个可迭代的对象,该对象内的每个元素也都是一个可迭代的对象。如:
data_rows = [] # 用于存放多条列表 data_rows.append(['李四', '87', '100', '91']) data_rows.append(['王五', '97', '91', '95']) csv_writer.writerows(data_rows)
3、以字典为单位读写CSV文件
我们在1.1简介中提到:CSV文件由任意数目的记录组成,通常,所有记录都有完全相同的字段序列。也就是说,通常CSV文件中的每一列都对应相同的含义,如:第一列代表姓名、第二列代表编号等。简言之,CSV文件中的数据通常来说都是属于关系型数据。在关系型数据模型中,我们使用key - value的方式去表述每条记录中的每一列数据。那么在python中,字典可以完全胜任这个关系型数据的表述。我们可以进而通过字典的这个特性,去完成对CSV文件的读写操作。
3.1、以字典为单位读取CSV文件(DictReader)
3.1.1、实例化CSV文件读取对象
csv模块下提供了DictReader类,它可以将普通的文本文档读取对象转化为csv文档读取对象。我们首先看一下DictReader类的构造方法:
def __init__(self, f, fieldnames=None, restkey=None, restval=None,
dialect="excel", *args, **kwds):
| 参数 | 参数类型 | 说明 |
|---|---|---|
| f | 以open打开的csv文件读取对象。 | |
| fieldnames | csv文件每列标题,默认为None。 |
- 参数 f 需要赋一个打开的文件对象,即我们平时用到的open打开的文件。首先open中的参数newline必须赋值为’’,即newline=’’;其次,若编码集参数encoding期望值为utf-8,最好写成utf-8-sig,即encoding=‘utf-8-sig’。这样可以避免第一个获取到的值存在一段未解码的字符串;最后,既然是读取类,我们在使用open打开csv文件的时候当然需要以“读”的方式去打开。比如我们需要打开一个测试数据.csv:
csv_file = open('./测试数据.csv', 'r', encoding='utf-8-sig', newline='') - 参数 fieldnames 可以不赋值,不赋值的情况下默认值为None,对于他们的区别很重要:
-
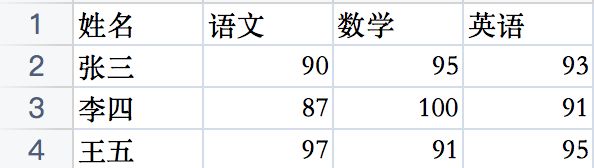
实例化的过程中,若 fieldnames 未赋予值,即其值为None时,则默认csv文件中的第一行为标题行:
csv_reader = DictReader(csv_file)那么此时csv文件中当数据应该是这样的,第一行数据认定为标题行,后续需要获取数据的时候,程序从第二行开始获取:
-
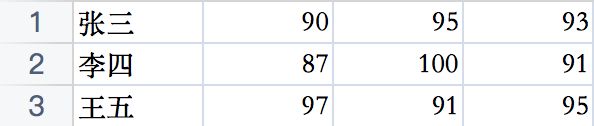
实例化的过程中,若 fieldnames 被赋予值,则csv文件从第一行开始即认定为数据行,例如我们进行了如下赋值:
fieldnames = ['姓名', '语文', '数学', '英语'] csv_reader = csv.DictReader(csv_file, fieldnames=fieldnames)那么此时csv文件中的数据应该是这样子的,第一行认定为数据行,后续需要获取数据的时候,程序从第一行开始获取:
-
3.1.2、获取每一列的标题
在2.1中,实例化DictReader的时候我们讲到过 fieldnames 参数。该参数的类型为一个列表,列表中每个元素代表着csv文件中每列的标题。在该值为None的时候,系统默认获取csv文件中的第一行为标题行。然而这种情况下我们如何获取到该标题行呢?
其实在实例化 DictReader 对象的时候,DictReader帮我们处理了fieldnames为None的时候的情况,他会他获取的第一行的数据作为标题行,并最终将获取的标题列表赋予了fieldnames这个参数中,所以我们可以直接通过获取属性的方式去获取列表:csv_reader.fieldnames。如:
csv_reader = csv.DictReader(csv_file)
fieldnames = csv_reader.fieldnames
print(type(fieldnames)) # 获取每一列对应的标题对于获取csv文件的数据是有重要意义的,因为后续我们在获取每条记录中的字段的时候,需要用到这个标题找到对应的值。
3.1.3、遍历CSV文件中的每条记录与字段
在2.1中,我们获取到了CSV文件读取对象(csv_reader),该对象大大方便了我们对于csv文档的操作。在这个对象中,它已经知晓数据行是从哪行开始的,标题又是什么。DictReader提供了可以直接使用for循环遍历对象的方式,跳过标题行,直接遍历数据行,极大的方便了我们获取其中的每条记录。
for csv_row in csv_reader:
print(type(csv_row)) # 可以看到,第一:获取到的csv是从去除标题行的数据行开始的,即它自动跳过了标题行;第二:获取到的每条记录(csv_row)的类型为字典类型,它们的键恰恰就是标题列表中的每个对应的元素。我们可以从以下图码直观的去看它们之间的关系。
csv_reader = csv.DictReader(csv_file)
print('=== 标题列表 ===')
fieldnames = csv_reader.fieldnames # 列表类型
print(fieldnames)
print('=== 数据字典 ===')
for csv_row in csv_reader: # 字典类型
print(csv_row)
'''输出结果
=== 标题列表 ===
['姓名', '语文', '数学', '英语']
=== 数据字典 ===
{'姓名': '张三', '语文': '90', '数学': '95', '英语': '93'}
{'姓名': '李四', '语文': '87', '数学': '100', '英语': '91'}
{'姓名': '王五', '语文': '97', '数学': '91', '英语': '95'}
'''
那么获取每个字段就成了很简单的事情了,如我们需要获取所有数据:
for csv_row in csv_reader:
for fieldname in fieldnames:
print(csv_row[fieldname], end=' ') # 根据键获取字典中的值
print()
'''输出结果
张三 90 95 93
李四 87 100 91
王五 97 91 95
'''
3.2、以字典为单位写入CSV文件(DictWriter)
3.2.1、实例化CSV文件写入类
csv模块下提供了DictWriter类,可以将我们普通的文本文档写入对象转化为csv文档写入对象,同样,我们看一下DictWriter类的构造方法:
def __init__(self, f, fieldnames, restval="", extrasaction="raise",
dialect="excel", *args, **kwds):
| 参数 | 参数类型 | 说明 |
|---|---|---|
| f | 以open打开的csv文件写入对象。 | |
| fieldnames | csv文件每列标题,必须赋值。 |
表面看上去,DictWriter类的构造方法与DictReader类的构造方法中的参数基本一致。但是,在实例化过程中,DictWriter与DictReader有着本质的区别:
- 既然是实例化csv文件写入类,那么csv文件打开方式(open)当然也得是以写入的方式打开:
csv_file = open('./测试数据2.csv', 'w', encoding='utf-8-sig', newline='') - 在构造DictWirter对象时,fieldnames参数一定要赋值,否则就会报错。

也就是说,在创建写入对象的过程中,首先得明确每个列的具体标题是什么。所以在实例化的过程中,一定要为fieldnames属性赋值:fieldnames = ['姓名', '语文', '数学', '英语'] csv_writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
3.2.2、添加标题行
在3.1中,我们设置了标题行(fieldnames),使得csv文件写入对象(csv_writer)明确了文件中每一列中具体的含义。但是它并没有为我们将这些标题真正的插入到csv文件中,我们需要自己手动添加进去。既然csv_writer中已经记录过这些信息,为了不让我们重复操作,DictWriter类为我们提供了writeheader方法,用于直接添加标题行到文件中:
csv_writer.writeheader()
3.2.3、添加数据行
创建DictWriter对象最终的目的就是为了将数据写入文件中,DictWriter类提供了writerow和writerows方法,可以将我们期望的数据写入csv文件中。我们看一下这两个方法及其参数:
class DictWriter:
...
def writerow(self, rowdict):
return self.writer.writerow(self._dict_to_list(rowdict))
def writerows(self, rowdicts):
return self.writer.writerows(map(self._dict_to_list, rowdicts))
| 参数 | 类型 | 说明 |
|---|---|---|
| rowdict | 行数据组成的字典对象。 | |
| rowdicts | 列表,列表中的元素为多个行的数据字典对象。 |
我们在2.3步骤中,从DictReader对象中读取的行数据,也是字典类型的。我们也很容易想到,读出来的数据,与写入的数据格式应该是一样的。我们先用wirterow插入一条记录的方式去验证一下:
csv_file = open('./测试数据2.csv', 'w', encoding='utf-8-sig', newline='')
fieldnames = ['姓名', '语文', '数学', '英语']
csv_writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
csv_writer.writeheader()
zhangsan = {
'姓名': '张三', '语文': '90', '数学': '95', '英语': '93'}
lisi = {
'姓名': '李四', '语文': '87', '数学': '100', '英语': '91'}
wangwu = {
'姓名': '王五', '语文': '97', '数学': '91', '英语': '95'}
csv_writer.writerow(zhangsan)
csv_writer.writerow(lisi)
csv_writer.writerow(wangwu)
csv_file.close()
如若希望用writerows的方式插入:
csv_file = open('./测试数据2.csv', 'w', encoding='utf-8-sig', newline='')
fieldnames = ['姓名', '语文', '数学', '英语']
csv_writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
csv_writer.writeheader()
data_list = []
data_list.append({
'姓名': '张三', '语文': '90', '数学': '95', '英语': '93'})
data_list.append({
'姓名': '李四', '语文': '87', '数学': '100', '英语': '91'})
data_list.append({
'姓名': '王五', '语文': '97', '数学': '91', '英语': '95'})
csv_writer.writerows(data_list)
csv_file.close()