本文为CenterNet作者发表的,论文提出anchor-free/two-stage目标检测算法CPN,使用关键点提取候选框再使用两阶段分类器进行预测。论文整体思路很简单,但CPN的准确率和推理速度都很不错,比原本的关键点算法更快,源码也会公开,到时可以一试
来源:晓飞的算法工程笔记 公众号
论文: Corner Proposal Network for Anchor-free,Two-stage Object Detection

Introduction

目前,amchor-based目标检测方法和anchor-free目标检测方法都涌现了大量的优秀检测方案。论文认为,对于形状特异的目标,anchor-free目标检测方式比较占优,但acnhor-free方法通常会出现大量的误检,如图1所示,需要一个独立的分类器来提升检测的准确率。为此,论文提出CPNDet(Corner Proposal Network),结合了anchor-free和two-stage的检测范式。先基于CornerNet进行角点检测,将有效的角点枚举组合成大量候选预测框。由于候选框包含大量负样本,先训练一个二值分类器过滤大部分的候选预测框,再使用多类别分类器进行标签预测。
Anchor-based or Anchor-free? One-stage or Two-stage?
这里论文主要讨论anchor-based vs anchor-free以及one-stage vs two-stage的问题。
Anchor-based or Anchor-free?
Anchor-based方法将大量的anchor平铺在特征图上,然后预测每个anchor是否包含物体以及标签。通常,anchor是与图片特定的位置关联,大小也是相对固定的,bbox回归能够轻微地改变其几何形状。Anchor-free方法则不受预设的anchor限制,直接定位目标的关键点,然后再预测其形状和标签。所以,论文认为anchor-free方法在任意形状目标的定位上更灵活,召回率也更高。
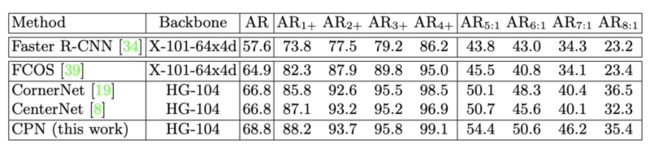
论文也对anchor-based方法和anchor-free方法在不同大小以及不同比例的目标上的进行召回率对比,结果如上表所示。可以看出anchor-free方法通常有较高的召回率,特别是在长宽比较大的物体上,anchor-based方法由于预设的anchor与目标差异大,召回率偏低。其次,FCOS虽然也是anchor-free方法,但其最后需要预测关键点到边界的距离,这在这种场合下也难以预测。
One-stage or Two stage?
虽然anchor-free方法解决了寻找目标候选框的约束,但由于缺乏目标的内部信息,难以很好地建立关键点与目标之间的联系,会给检测的准确率带来较大的影响,而关键点和目标之间的联系的建立通常需要丰富的语义信息。

论文将高召回率CornerNet和CenterNet作为实验目标,结果如上表所示。主干网络的加强能够带来准确率的提升,但仍然有很多的误检。如果去掉无目标的误检($AP_{refined}$)以及纠正标签的错误识别($AP_{correct}$)后,准确率能够明显地提升了。上述的实验说明,为了建立关键点与目标间的联系,需要借用two-stage的范式,提取候选框的信息来过滤误检部分。
The Framework of Corner Proposal Network
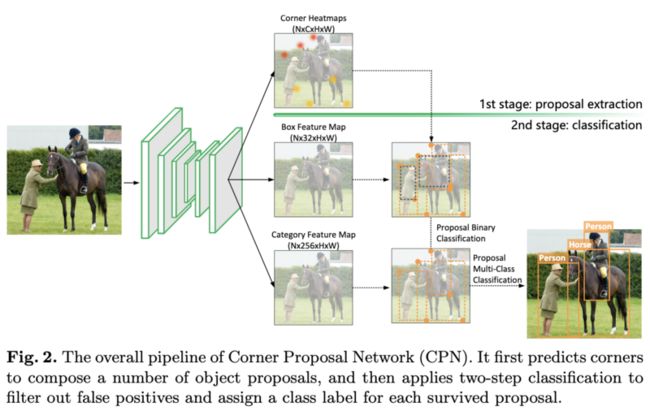
基于上面的分析,论文结合acnhor-free方法和two-stage范式提出了Corner-Proposal-Network(CPN),完整的结构如图2所示。首先使用anchor-free方法提取关键点,遍历关键点组合成候选框,最后使用两个分类器分别对候选框进行误检过滤以及标签预测。
Stage 1: Anchor-free Proposals with Corner Keypoints
第一阶段为anchor-free候选框提取过程,假定每个目标都由两个关键点进行定位,先根据CornerNet输出两组角点的热图,选择top-k个左上角点以及top-k个右下角点。将有效的关键点组合成目标的候选框,关键点组合是否有效主要有两个判断:
- 关键点是否属于同一个类别
- 左上角点必须在右上角点的左上位置
尽管论文基于CornerNet提取候选框,但后处理有较大差异。CornerNet使用embedding向量来组合关键点,论文认为embedding向量并不能保证是可学习的,而论文采用独立的分类器进行处理,能够使用完整的中间特征来提升准确率。
Stage 2: Two-step Classification for Filtering Proposals
基于anchor-free方法提取候选框虽然召回率很高,但会带来大量的误检,论文采用two-step分类方法进行过滤和校正。首先采用轻量的二值分类器过滤80%的候选框,然后使用多分类器预测剩余候选框的类别。
第一步训练二值分类器来决定候选框是否为目标,采用$7\times 7$的RoIAlign提取每个候选框的在box特征图上的特征,然后使用1个$32\times 7\times 7$的卷积层来输出每个预测框的分类置信度,损失函数为:

$M$为总候选框数,$N$为正样本数,$p_m$为$m$候选框为目标的概率,$\tau$为IoU阈值,设为0.7。
第二步用于给剩余的候选框预测类别,由于缺乏目标的内部信息的,关键点的类别通常不太准确,所以需要强大的分类器来根据ROI特征进行预测。首先使用$7\times 7$的ROIAlign提取每个候选框在category特征图上的特征,然后使用$C$个$256\times 7\times 7$的卷积层输出$C$维向量,$C$为类别数量,损失函数为:
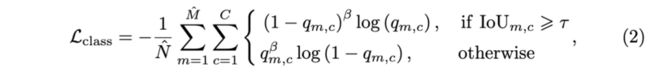
$\hat{M}$和$\hat{N}$为过滤后的候选框数量和正样本数量,$q_{m,c}$为$m$候选框的$c$类别置信度,其余的参数与第一步类似。
The Inference Process
推理过程跟训练过程基本一样,由于训练过程包含很多低质量的预测框,$p_m$和$q_{m,c}$的值是偏向零的,所以推理阶段第一步使用相对低的阈值(0.2)进行过滤,大约保留20%的候选框。在第二步,每个候选框有两个标签,分别为角点预测的标签$s_1$和第二阶段分类器预测的标签$s_2$,当其中一个标签分数大于0.5时才将候选框输出,分数计算为$s_c=(s_1+0.5)(s_2+0.5)$,再归一化到$[0,1]$。
Experiments
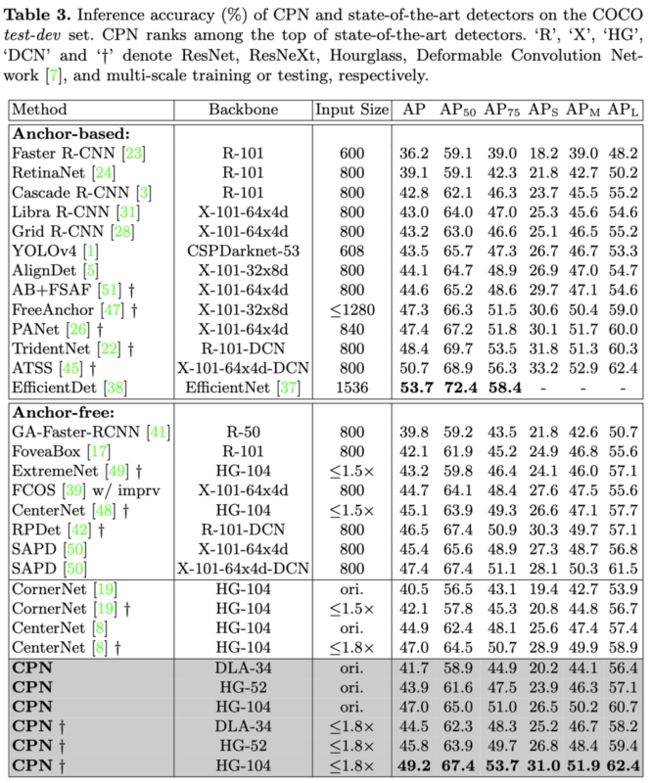
与SOTA检测算法进行对比,初始的输入分辨率为$511\times 511$。
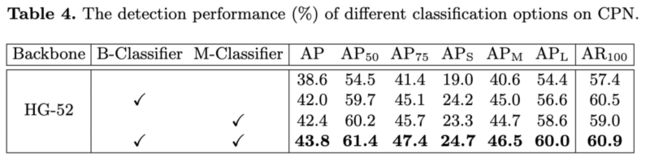
推理阶段的两个分类器对性能的影响,B-Classifier为二值分类器,M-Classifier为多标签分类器。
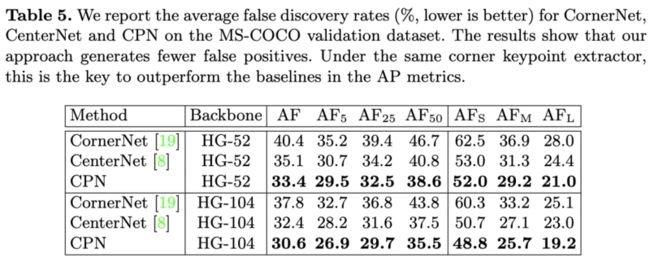
相对于其它keypoint-based方法,CPN误检更低。
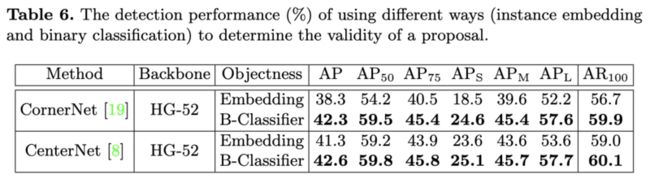
二值分类器与CornerNet的embedding向量的性能对比。

推理速度对比。
CONCLUSION
论文提出anchor-free/two-stage目标检测算法CPN,使用关键点提取候选框再使用两阶段分类器进行预测。论文整体思路很简单,但CPN的准确率和推理速度都很不错,比原本的关键点算法更快,论文的细节也值得推敲。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
