Python序列化中json模块和pickle模块(详解)
文章目录
-
- 一、什么是序列化?
- 二、为什么需要序列化?
- 三、什么类型可以序列化?
- 四、序列化模块
- 五、json()方法
-
-
- 1、JSON和Python内置的数据类型对应如下:
- 2、Json序列化示例
- 3、json反序列化
-
- 六、pickle()方法
-
-
- 1、pickle序列化
- 2、pickle 反序列化
-
- 七、shelve()方法
- 8、JSON和pickle的区别
一、什么是序列化?
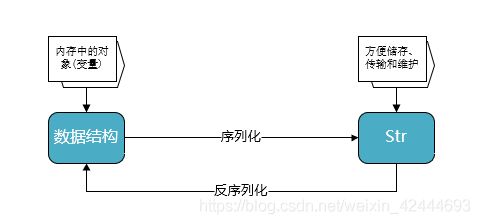
把对象(或变量)从内存变成可存储或可传输的过程称之为序列化,在python中被称为picking,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
二、为什么需要序列化?
序列化的目的:
1、以某种存储形式使自定义对象持久化;
2、将对象从一个地方传递到另一个地方。(方便跨平台数据交互)
3、使程序更具维护性。
三、什么类型可以序列化?
- None,
- True, 和 False
- 整形、浮点、
- 复数 strings, bytes, bytearrays
- 元组, 列表, 集合,和 只包含可序列化对象的字典
- 定义在模块顶层的函数(lambda表达式不可以)
- 定义在模块顶层的内建函数 定义在模块顶层类
8、 instances of such classes whose dict or the result of calling getstate() is picklable.
参考博文
四、序列化模块
| 模块 | 描述 | 方法 | 作用范围 |
|---|---|---|---|
| json | 用于实现Python数据类型与通用(json)字符串之间的转换 | dumps()、dump()、loads()、load() | 不能转换自定义类型。明文保存,保密性差 |
| pickle | 用于实现Python数据类型与Python特定二进制格式之间的转换 | dumps()、dump()、loads()、load() | 不能用于Python之外 |
| shelve | 专门用于将Python数据类型的数据持久化到磁盘,shelve是一个类似dict的对象,操作十分便捷 | open() | 只能用在Python中 |
五、json()方法
JSON表示的对象就是标准的JavaScript语言的对象,表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输,是目前跨平台常用的序列化格式.
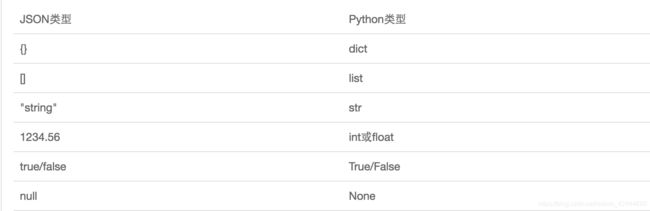
1、JSON和Python内置的数据类型对应如下:
2、Json序列化示例
import json
#dump方式
dic = {
'name':'jasn','age':18}
json.dump(dic, open('dic.json', 'w', encoding='utf-8'))
# dumps方式
payroll={
'name':'jasn','wage':8900,'Absence':False,'onJob':True}
with open('payroll.json','w', encoding='utf-8')as f:
f.write(json.dumps(payroll))
print(json.dumps(payroll))
'''
dumps和dump 序列化方法
序列化成字符串:json.dumps(json_obj)
序列化字符串到文件中:json.dump(json_obj, write_file)
'''
3、json反序列化
# 1|json 反序列化
# json类型的字符串不认单引号''
# load方式
re = json.load(open('dic.json','r',encoding='utf-8'))
print(re)
# loads方式
with open('payroll.json','r',encoding='utf-8')as f:
res=json.loads(f.read())
print(res)
六、pickle()方法
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表…可以把python中任意的数据类型序列化)
1、pickle序列化
# pickle.dumps方式
set = {
1,2,3,4,65,756,8754,34,253} # 集合
with open('set1.pkl','wb')as f:
f.write(pickle.dumps(set))
print(pickle.dumps(set))
# pickle.dump方式
set1 = {
1,4,34,253} # 集合
pickle.dump(set1,open('set2.pkl','wb'))
2、pickle 反序列化
# 2\pickle 反序列化
#==========================================================
#pickle.loads()方法
with open('set1.pkl','rb')as f:
re_pik=pickle.loads(f.read())
print(re_pik)
# pickle.load()方法
re_pik2=pickle.load(open('set2.pkl','rb'))
print(re_pik2)
七、shelve()方法
shelve与pickle类似用来持久化数据的,不过shelve是以键值对的形式,将内存中的数据通过文件持久化,值支持任何pickle支持的python数据格式,它会在目录下生成三个文件。
# shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。
# shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
#(1)shelve存入数据
import shelve
f = shelve.open('shelve_file')
f['key'] = {
'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
f.close()
#(2)shelve读出数据
import shelve
f1 = shelve.open('shelve_file')
existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
f1.close()
print(existing)
8、JSON和pickle的区别
1、JSON只能处理基本数据类型。pickle能处理所有Python的数据类型。
2、JSON用于各种语言之间的字符转换。pickle用于Python程序对象的持久化或者Python程序间对象网络传输,但不同版本的Python序列化可能还有差异。