coco数据集目标检测论文_Tensorflow对COCO目标检测数据预处理
COCO数据集是微软发布的一个大型图像数据集, 专为对象检测、分割、人体关键点检测、语义分割和字幕生成而设计。这个数据集还提供了Matlab, Python 和 Lua 的 API 接口. 该 API 接口可以提供完整的图像标签数据的加载, parsing 和可视化。
下面记录一下我是如何利用COCO的数据集来制作目标检测的数据,以及对数据进行增广处理的。
首先我们去COCO的官网http://mscoco.org下载图像数据。之后我们还要下载安装COCO API, https://github.com/Xinering/cocoapi
COCOAPI安装好后,在PythonAPI的目录下,有一个pycocoDemo.ipynb的文件,用Jupyter Notebook运行这个文件,可以看到cocoapi的用法,我根据这个文件的示例来进行改造,把COCO的图像数据和目标检测用到的标注框的数据打包制作为Tensorflow的tfrecord格式的数据,方便之后用Tensorflow来进行训练。代码如下:
#-*- encoding: utf-8 -*-
import tensorflow as tf
import cv2
import numpy as np
import os
from multiprocessing import Process, Queue
import sys
import time
import random
import math
from pycocotools.coco import COCO
#读取COCO的标注文件,里面包含了检测框的数据
annFile='annotations/instances_train2014.json'
#COCO训练集的图像数据保存的目录
train_path = '/data/AI/cocoapi/images/'
coco=COCO(annFile)
cores=8 #定义用到的CPU处理的核心数
max_num=1000 #每个TFRECORD文件包含的最多的图像数
# display COCO categories and supercategories
cats = coco.loadCats(coco.getCatIds())
cats_dict = {}
for cat in cats:
cats_dict[cat['id']] = cat['name']
#获取COCO数据集中所有图像的ID
imgIds = coco.getImgIds()
print(len(imgIds))
#构建训练集文件列表,里面的每个元素是路径名+图片文件名
train_images_filenames = os.listdir(train_path)
#查找训练集的图片是否都有对应的ID,并保存到一个列表中
train_images = []
i = 1
total = len(train_images_filenames)
for image_file in train_images_filenames:
if int(image_file[15:-4]) in imgIds:
train_images.append(train_path+','+image_file)
if i%100==0 or i==total:
print('processing image list %i of %ir' %(i, total), end='')
i+=1
random.shuffle(train_images)
all_cat = set() #保存目标检测所有的类别, COCO共定义了90个类别,其中只有80个类别有目标检测数据
imagefile_box = {}
#获取每个图像的目标检测框的数据并保存
for item in train_images:
boxes = [[],[],[],[],[]]
filename = item.split(',')[1]
imgid = int(filename[15:-4])
annIds = coco.getAnnIds(imgIds=imgid, iscrowd=None)
anns = coco.loadAnns(annIds)
for ann in anns:
bbox = ann['bbox']
xmin = int(bbox[0])
xmax = int(bbox[0] + bbox[2])
ymin = int(bbox[1])
ymax = int(bbox[1] + bbox[3])
catid = ann['category_id']
all_cat.add(cats_dict[catid])
boxes[0].append(catid)
boxes[1].append(xmin)
boxes[2].append(ymin)
boxes[3].append(xmax)
boxes[4].append(ymax)
imagefile_box[filename] = boxes
#获取有目标检测数据的80个类别的名称
all_cat_list = list(all_cat)
all_cat_dict = {}
for i in range(len(all_cat_list)):
all_cat_dict[all_cat_list[i]]=i
print(all_cat_dict)
#把图像以及对应的检测框,类别等数据保存到TFRECORD
def make_example(image, height, width, label, bbox, filename):
colorspace = b'RGB'
channels = 3
img_format = b'JPEG'
return tf.train.Example(features=tf.train.Features(feature={
'image' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])),
'height' : tf.train.Feature(int64_list=tf.train.Int64List(value=[height])),
'width' : tf.train.Feature(int64_list=tf.train.Int64List(value=[width])),
'channels' : tf.train.Feature(int64_list=tf.train.Int64List(value=[channels])),
'colorspace' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[colorspace])),
'img_format' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_format])),
'label' : tf.train.Feature(int64_list=tf.train.Int64List(value=label)),
'bbox_xmin' : tf.train.Feature(int64_list=tf.train.Int64List(value=bbox[0])),
'bbox_xmax' : tf.train.Feature(int64_list=tf.train.Int64List(value=bbox[2])),
'bbox_ymin' : tf.train.Feature(int64_list=tf.train.Int64List(value=bbox[1])),
'bbox_ymax' : tf.train.Feature(int64_list=tf.train.Int64List(value=bbox[3])),
'filename': tf.train.Feature(bytes_list=tf.train.BytesList(value=[filename]))
}))
#定义多进程函数用于生成TFRECORD文件
def gen_tfrecord(trainrecords, targetfolder, startnum, queue):
tfrecords_file_num = startnum
file_num = 0
total_num = len(trainrecords)
pid = os.getpid()
queue.put((pid, file_num))
writer = tf.python_io.TFRecordWriter(targetfolder+"train_"+str(tfrecords_file_num)+".tfrecord")
for record in trainrecords:
file_num += 1
fields = record.split(',')
img = cv2.imread(fields[0]+fields[1])
height, width, _ = img.shape
img_jpg = cv2.imencode('.jpg', img)[1].tobytes()
bbox = imagefile_box[fields[1]]
bbox[1] = [item for item in bbox[1]] #xmin
bbox[3] = [item for item in bbox[3]] #xmax
bbox[2] = [item for item in bbox[2]] #ymin
bbox[4] = [item for item in bbox[4]] #ymax
catnames = [cats_dict[item] for item in bbox[0]]
label = [all_cat_dict[item] for item in catnames]
ex = make_example(img_jpg, height, width, label, bbox[1:], fields[1].encode())
writer.write(ex.SerializeToString())
#每写入100条记录,向父进程发送消息,报告进度
if file_num%100==0:
queue.put((pid, file_num))
if file_num%max_num==0:
writer.close()
tfrecords_file_num += 1
writer = tf.python_io.TFRecordWriter(targetfolder+"train_"+str(tfrecords_file_num)+".tfrecord")
writer.close()
queue.put((pid, file_num))
#定义多进程处理
def process_in_queues(fileslist, cores, targetfolder):
total_files_num = len(fileslist)
each_process_files_num = int(total_files_num/cores)
files_for_process_list = []
for i in range(cores-1):
files_for_process_list.append(fileslist[i*each_process_files_num:(i+1)*each_process_files_num])
files_for_process_list.append(fileslist[(cores-1)*each_process_files_num:])
files_number_list = [len(l) for l in files_for_process_list]
each_process_tffiles_num = math.ceil(each_process_files_num/max_num)
queues_list = []
processes_list = []
for i in range(cores):
queues_list.append(Queue())
#queue = Queue()
processes_list.append(Process(target=gen_tfrecord,
args=(files_for_process_list[i],targetfolder,
each_process_tffiles_num*i+1,queues_list[i],)))
for p in processes_list:
Process.start(p)
#父进程循环查询队列的消息,并且每0.5秒更新一次
while(True):
try:
total = 0
progress_str=''
for i in range(cores):
msg=queues_list[i].get()
total += msg[1]
progress_str+='PID'+str(msg[0])+':'+str(msg[1])+'/'+ str(files_number_list[i])+'|'
progress_str+='r'
print(progress_str, end='')
if total == total_files_num:
for p in processes_list:
p.terminate()
p.join()
break
time.sleep(0.5)
except:
break
return total
if __name__ == '__main__':
print('Start processing train data using %i CPU cores:'%cores)
starttime=time.time()
total_processed = process_in_queues(train_images, cores, targetfolder='/data/data/coco/train_tf/')
endtime=time.time()
print('nProcess finish, total process %i images in %i seconds'%(total_processed, int(endtime-starttime)), end='')TFRECORD数据生成后,我们可以进行很多的数据增广(Data augmentation)的处理了。具体的数据增广包括了以下几个方面:
- 对图像大小调整到固定的大小(例如416*416),并相应调整Bounding Box的坐标
- 把图像大小调整到固定的大小的120%(例如500*500),然后再随机裁剪图片到固定的大小(416*416),并相应调整Bounding Box的坐标
- 对图像进行Expand操作,例如随机生成一个是图像1-3倍大小的一个图像(像素值都为0),然后随机放置这个图像进去。然后再把扩展后的图像调整大小到固定的大小(416*416),并相应调整Bounding Box的坐标。相当于缩小Bounding Box
- 随机对图像进行Patch的操作,Patch的大小是图像的0.1-1.0,Patch和Bounding Box的IOU值需要在[0.1,0.3,0.5,0.7,0.9]这几个随机值中。相当于对Bounding Box进行扩大
- 随机调整图像的颜色,对比度,明亮度,并对图像的数值进行标准化的操作。
具体的代码如下:
import tensorflow as tf
import numpy as np
import os
import cv2
import matplotlib.pyplot as plt
resize_width = 458
resize_height = 458
image_width = 416
image_height = 416
image_width_delta = resize_width - image_width
image_height_delta = resize_height - image_height
batch_size = 32
labels = ['umbrella',
'sandwich',
'handbag',
'person',
'snowboard',
'cell phone',
'traffic light',
'potted plant',
'toaster',
'baseball glove',
'cow',
'surfboard',
'remote',
'toilet',
'baseball bat',
'giraffe',
'book',
'bottle',
'stop sign',
'frisbee',
'boat',
'sheep',
'mouse',
'motorcycle',
'car',
'bird',
'pizza',
'bed',
'kite',
'zebra',
'broccoli',
'cat',
'chair',
'bench',
'teddy bear',
'tennis racket',
'laptop',
'sink',
'sports ball',
'skateboard',
'parking meter',
'carrot',
'hair drier',
'banana',
'wine glass',
'scissors',
'spoon',
'cake',
'fire hydrant',
'dog',
'backpack',
'airplane',
'clock',
'keyboard',
'truck',
'bicycle',
'skis',
'bus',
'hot dog',
'dining table',
'cup',
'toothbrush',
'horse',
'elephant',
'refrigerator',
'knife',
'suitcase',
'apple',
'donut',
'couch',
'train',
'microwave',
'bear',
'oven',
'bowl',
'orange',
'tv',
'tie',
'vase',
'fork']
#解析TFRECORD文件,对图像进行缩放,随机裁减,翻转和图像标准化的操作,并相应的调整检测框的位置
def _parse_function(example_proto):
features = {
"image": tf.FixedLenFeature([], tf.string, default_value=""),
"height": tf.FixedLenFeature([1], tf.int64, default_value=[0]),
"width": tf.FixedLenFeature([1], tf.int64, default_value=[0]),
"channels": tf.FixedLenFeature([1], tf.int64, default_value=[3]),
"colorspace": tf.FixedLenFeature([], tf.string, default_value=""),
"img_format": tf.FixedLenFeature([], tf.string, default_value=""),
"label": tf.VarLenFeature(tf.int64),
"bbox_xmin": tf.VarLenFeature(tf.int64),
"bbox_xmax": tf.VarLenFeature(tf.int64),
"bbox_ymin": tf.VarLenFeature(tf.int64),
"bbox_ymax": tf.VarLenFeature(tf.int64),
"filename": tf.FixedLenFeature([], tf.string, default_value="")
}
parsed_features = tf.parse_single_example(example_proto, features)
label = tf.expand_dims(parsed_features["label"].values, 0)
label = tf.cast(label, tf.int64)
height = parsed_features["height"]
width = parsed_features["width"]
channels = parsed_features["channels"]
#Resize the image
image_raw = tf.image.decode_jpeg(parsed_features["image"], channels=3)
image_decoded = tf.image.convert_image_dtype(image_raw, tf.float32)
shape = tf.shape(image_decoded)
height, width = shape[0], shape[1]
image_resize = tf.image.resize(image_decoded, [resize_height, resize_width])
height_ratio = tf.cast(resize_height/height, tf.float16)
width_ratio = tf.cast(resize_width/width, tf.float16)
#Adjust the bbox
xmin = tf.cast(tf.expand_dims(parsed_features["bbox_xmin"].values, 0), tf.float16)
xmax = tf.cast(tf.expand_dims(parsed_features["bbox_xmax"].values, 0), tf.float16)
ymin = tf.cast(tf.expand_dims(parsed_features["bbox_ymin"].values, 0), tf.float16)
ymax = tf.cast(tf.expand_dims(parsed_features["bbox_ymax"].values, 0), tf.float16)
xmin = tf.cast(xmin*width_ratio, tf.int64)
xmax = tf.cast(xmax*width_ratio, tf.int64)
ymin = tf.cast(ymin*height_ratio, tf.int64)
ymax = tf.cast(ymax*height_ratio, tf.int64)
#Generate the random crop offset
random_width_start = tf.random.uniform([1], minval=0, maxval=image_width_delta, dtype=tf.dtypes.int64)
random_height_start = tf.random.uniform([1], minval=0, maxval=image_height_delta, dtype=tf.dtypes.int64)
random_start = tf.concat([random_height_start, random_width_start, tf.constant([0], dtype=tf.dtypes.int64)], axis=0)
#Adjust the bbox coordinates with random crop offset
def f1():
xmin_temp = xmin - random_width_start
xmin_temp = tf.clip_by_value(xmin_temp, 0, image_width)
xmax_temp = xmax - random_width_start
xmax_temp = tf.clip_by_value(xmax_temp, 0, image_width)
ymin_temp = ymin - random_height_start
ymin_temp = tf.clip_by_value(ymin_temp, 0, image_height)
ymax_temp = ymax - random_height_start
ymax_temp = tf.clip_by_value(ymax_temp, 0, image_height)
return xmin_temp, xmax_temp, ymin_temp, ymax_temp
#Adjust the bbox coordinates with image flipped and random crop offset
def f2():
xmin_temp1 = xmin - random_width_start
xmax_temp1 = xmax - random_width_start
xmin_temp = image_width - tf.clip_by_value(xmax_temp1, 0, image_width)
xmax_temp = image_width - tf.clip_by_value(xmin_temp1, 0, image_width)
ymin_temp = ymin - random_height_start
ymin_temp = tf.clip_by_value(ymin_temp, 0, image_height)
ymax_temp = ymax - random_height_start
ymax_temp = tf.clip_by_value(ymax_temp, 0, image_height)
return xmin_temp, xmax_temp, ymin_temp, ymax_temp
#Generate the random flip flag
random_flip = tf.random.uniform([1], minval=0, maxval=1, dtype=tf.dtypes.float32)
#Get the bbox coordinates after random flip and crop
xmin, xmax, ymin, ymax = tf.cond(tf.less(random_flip[0], 0.5), f1, f2)
image_sliced = tf.slice(image_resize, random_start, [image_height, image_width, -1])
image_flipped = tf.cond(tf.less(random_flip[0], 0.5), lambda:image_sliced, lambda:tf.image.flip_left_right(image_sliced))
image_standard = tf.image.per_image_standardization(image_flipped)
image_train = tf.transpose(image_standard, perm=[2, 0, 1])
#evaluate which anchor most fit the box
box_width = (xmax-xmin)
box_height = (ymax-ymin)
box_area = box_width*box_height
intersect_area_list = []
for i in range(9):
intersect_area_list.append(tf.minimum(box_width, anchors[2*i])*tf.minimum(box_height, anchors[2*i+1]))
intersect_area = tf.concat(intersect_area_list, axis=0)
iou = intersect_area/(box_area+anchors_area-intersect_area)
anchor_id = tf.reshape(tf.argmax(iou, axis=0), [1, -1])
bbox = tf.concat(axis=0, values=[xmin, xmax, ymin, ymax, anchor_id, label])
bbox = tf.transpose(bbox, [1, 0])
return bbox, image_train, image_flipped, image_decoded
#构建处理TFRECORD的pipeline
with tf.device('/cpu:0'):
train_files = tf.data.Dataset.list_files("/data/data/coco/train_tf/*.tfrecord")
dataset_train = train_files.interleave(tf.data.TFRecordDataset, cycle_length=4, num_parallel_calls=4)
dataset_train = dataset_train.shuffle(buffer_size=epoch_size)
dataset_train = dataset_train.repeat(100)
dataset_train = dataset_train.map(_parse_function, num_parallel_calls=12)
dataset_train = dataset_train.padded_batch(batch_size,
padded_shapes=([None,None],
[None, None, None],
[None, None, None],
[None, None, None]))
dataset_train = dataset_train.prefetch(batch_size)
iterator = tf.data.Iterator.from_structure(dataset_train.output_types, dataset_train.output_shapes)
bbox, image_train, image_flipped, image_decoded = iterator.get_next()
train_init_op = iterator.make_initializer(dataset_train)
#验证数据
with tf.Session() as sess:
sess.run(train_init_op)
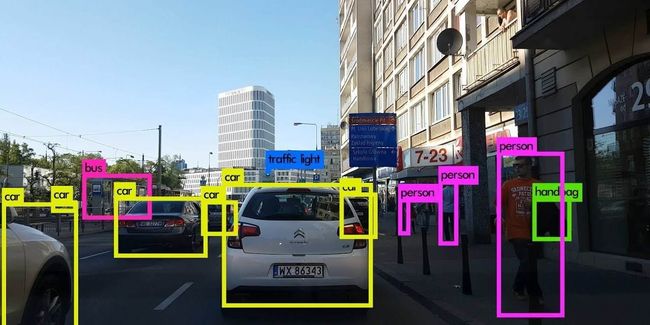
images_run, bbox_run, images_d = sess.run([image_flipped, bbox, image_decoded])
image_index = 0 #select one image in the batch
image = images_run[image_index]
image_bbox = bbox_run[image_index]
for i in range(image_bbox.shape[0]):
cv2.rectangle(image, (image_bbox[i][0],image_bbox[i][2]), (image_bbox[i][1],image_bbox[i][3]), (0,255,0), 2)
plt.imshow(image)运行结果如下:

文章转载自:https://blog.csdn.net/gzroy/article/details/95027532