基于Zookeeper的kafka集群搭建及简单使用
基于Zookeeper的kafka集群搭建(详细)
1.前期准备
创建三台linux服务器,我是在虚拟机中创建的三台服务器
| 主机名 | IP |
|---|---|
| maser | 192.168.164.129 |
| salve1 | 192.168.164.130 |
| salve2 | 192.168.164.131 |
我安装的linux版本是centos7
linux的安装可以参考
centos7安装教程
2.安装jdk
由于zookeeper集群的运行需要Java运行环境,所以有此步
1.首先检查3台linux系统的jdk环境,如果有,则把删掉,详细步骤,进入linux系统,以 root 用户登录:输入 java -vesion.
如果出现如下信息,则默认安装有,需要卸载
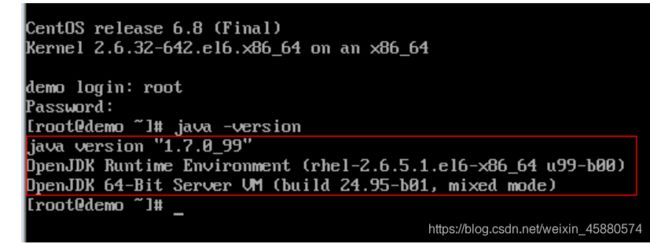
2.卸载默认安装的 Open JDK
①、输入: rpm -qa | grep jdk
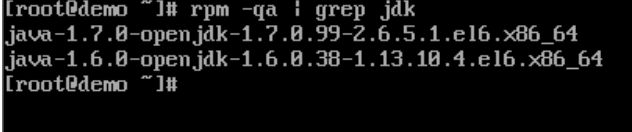
②、输入:rpm -e --nodeps 上面的出现的信息
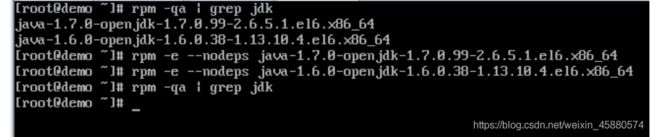
3、下载jdk
网址 https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
我是下载在本地,然后通过xftp(和linux系统连接的工具)将文件传到三台linux系统上,
![]()
输入tar jdk-8u221-linux-x64_2.rpm 解压
设置环境变量vi /etc/profile
#set java environment
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
保存后输入
source /etc/profile
让环境生效
然后输入java -version检查是否安装好

3.安装zookeeper
zookeeper的理论知识,这里就不阐述了,主要讲下安装步骤
1.官网下载地址(http://mirror.bit.edu.cn/apache/zookeeper/
我下载的是http://mirror.bit.edu.cn/apache/zookeeper/stable/apache-zookeeper-3.5.8-bin.tar.gz
我的目录统一放在/opt下面
首先创建Zookeeper项目目录
mkdir zookeeper #项目目录
mkdir zkdata #存放快照日志
mkdir zkdatalog#存放事物日志
在zookeeper目录下解压下载的zookeeper安装包
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
2.解压完成后,进入到conf目录修改配置文件 zoo.cfg

将 zoo_sample.cfg 文件复制并重命名为 zoo.cfg 文件
cp zoo_sample.cfg zoo.cfg
然后通过 vim zoo.cfg 命令对该文件进行修改:

红色部分即为改动部分,三台机器均改成这样
这里是引用
#tickTime:
这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
#initLimit:
这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 52000=10 秒
#syncLimit:
这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是52000=10秒
#dataDir:
快照日志的存储路径
#dataLogDir:
事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多
#clientPort:
这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。修改他的端口改大点
3.创建myid文件(此台服务器zoo.cfg下面server.后面是几,echo就填几)
#master
echo "1" > /opt/zookeeper/zkdata/myid
#slave1
echo "2" > /opt/zookeeper/zkdata/myid
#slave2
echo "3" > /opt/zookeeper/zkdata/myid
4.为了能够在任意目录启动zookeeper集群,我们需要配置环境变量。
ps:你也可以不配,这不是搭建集群的必要操作,只不过如果你不配置环境变量,那么每次启动zookeeper需要到安装文件的 bin 目录下去启动。
首先进入到 /etc/profile 目录,添加相应的配置信息:
#set zookeeper environment
export ZK_HOME=/opt/zookeeper/apache-zookeeper-3.5.8-bin
export PATH=$PATH:$ZK_HOME/bin
#让修改生效
source /etc/profle
5、启动zookeeper服务
启动命令:zkServer.sh start
停止命令:zkServer.sh stop
重启命令:zkServer.sh restart
查看集群节点状态:zkServer.sh status
我们分别对集群三台机器执行启动命令。执行完毕后,分别查看集群节点状态:
出现如下即是集群搭建成功:



6.中间除了一个错误

可以去zookeeper的安装目录中找到logs,查看原因
![]()
我报了这个错误

是因为防火墙没有关闭,查看防火墙的状态systemctl status firewalld.service,果然是active状态,然后systemctl stop firewalld.service 之后,重新启动就好了。
4.安装kafka
1. 下载kafka安装包,官网下载地址http://kafka.apache.org/downloads
创建kafka安装目录mkdir /opt/kafka
wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
2 . 解压安装包
tar -zxf kafka_2.12-2.0.0.tgz
3.进入kafka安装目录中,找到config下server.properties这个文件。
修改这个文件,主要查看修改一下几个属性
#broker.id=0 每台服务器的broker.id都不能相同
#hostname
host.name=192.168.164.129
#在log.retention.hours=168 下面新增下面三项
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
#设置zookeeper的连接端口
zookeeper.connect=192.168.164.129:2181,192.168.164.130:2181,192.168.164.131:2181
属性详情介绍
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=19092 #当前kafka对外提供服务的端口默认是9092
host.name=192.168.7.129 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=192.168.164.129:2181,192.168.164.130:2181,192.168.164.131:2181 #设置zookeeper的连接端口
4.启动kafka集群
4.1启动服务
#从后台启动Kafka集群(3台都需要启动)
cd /opt/kafka/kafka_2.12-2.0.0/bin/ 进入到kafka的bin目录,输入下面语句启动
./kafka-server-start.sh -daemon ../config/server.properties
4.2查看是否启动成功
#执行命令jps

启动成功
4.3创建Topic来验证是否创建成功
'''选一台机器执行如下语句'''
./kafka-topics.sh --create --zookeeper 192.168.164.129:2181 --replication-factor 2 --partitions 1 --topic kafka
#解释
--replication-factor 2 #复制两份
--partitions 1 #创建1个分区
--topic #主题为kafka
'''在一台服务器上创建一个发布者'''
#创建一个broker,发布者
./kafka-console-producer.sh --broker-list 192.168.164.130:9092 --topic kafka
'''在一台服务器上创建一个订阅者'''
./kafka-console-consumer.sh --bootstrap-server 192.168.164.131:9092 --topic kafaka
然后在发布者那个窗口输入消息,订阅者那里会收到消息。


5.程序中简易使用
package com.example.kafkalearn.day1;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class ProducerStart {
public final static String TOPIC = "kafka";
public static void main(String[] args) {
Properties properties = new Properties();
//设置key的序列化器
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
//设置尝试次数
properties.put(ProducerConfig.RETRIES_CONFIG,10);
//设置值序列化器
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//设置集群地址
properties.put("bootstrap.servers", "192.168.164.129:9092");
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC,"hello kafka");
try{
producer.send(record);
System.out.println("over");
}catch (Exception e){
e.printStackTrace();
}
producer.close();
}
}
运行完毕后,去订阅者窗口查看,收到了消息
