作者 / Chad Hart
原文链接 / https://webrtchacks.com/webrt...
可扩展视频编码
可拓展视频编码(SVC)可以说是处理来自同一发送者的多个媒体流以处理组呼叫中每个接收者的不同条件的更好方法。在许多方面,它也被认为更复杂。Sergio&Gustavo对此主题发表了精彩的文章。
Chad:如果还没有Simulcast,那SVC在哪里呢?
Bernard:在某些方面,SVC比Simulcast容易一些。今天,它在Chromium中作为时间可伸缩性的实验性实现。在计划B中,还支持时间可伸缩性-因此实际上已经存在,并且会议服务器都支持它。因此,对于大多数会议服务而言,从某些方面来说,这实际上是一个更轻松的进步,例如,同时支持RID和MID。
MID是SDP媒体标识符,RID 是用于限制单个流的较新的限制标识符。我将它留给读者查看各种SDP规范,以获取有关这些规范的更多信息。
我认为许多会议服务都支持RID和MID,Medooze和Janus都支持。关于SVC的理解之一是,在VP8和VP9中都是必需的-解码器必须支持这一点。因此,没有什么可以谈判的。编码器可以将其推出。如果不希望,SFU甚至不必丢弃[SVC层],但这显然更好。
AV1
很久以前,Chris Wendt在这里写了一篇文章,内容涉及 H.26X和VPX阵营之间的编解码器之战,以及一个编解码器统治它们的潜力。今天,该编解码器已经存在,它被称为AV1。
WebRTC何时将AV1作为标准?

Bernard: [使用AV1]面临的挑战是设法在大量设备支持全分辨率编码之前弄清楚如何使其有用和可用。
Chad: 我应该向听众解释说AV1是下一代的开源免费编码解码器。
Bernard: AV1本身不需要对WebRTC PeerConnection进行任何更改。但是作为示例,AV1支持许多新的可伸缩性模式。因此,你需要该控件,这就是WebRTC SVC的用武之地。
另一件事是AV1具有非常有效的屏幕内容编码工具,你希望能够将其打开。因此,我们添加了一个称为内容提示的内容 ,可能会导致AV1内容编码器工具打开。
Floren t [Castelli]提出了一种混合编解码器Simulcasts。这样做的想法是,例如,如果你想执行360P或720P之类的操作,并且你拥有可以做到的机器,则可以以较低的比特率对AV1进行编码。你可以在软件中做到这一点,不需要硬件加速。然后,在较高分辨率下,你将使用另一个编解码器。例如,你可以使用VP8或VP9。
这样一来,你就可以立即引入AV1编码,而不必强制将其全部或全部删除。随着混合编解码器Simulcasts和内容提示基本上只要AV1编码器和解码器进入的WebRTC PC,也就是时候了。我认为人们对AV1的考虑不多,但是通过这些扩展(对API的调整很少),我们的目标是立即使它可用。
我们距离这个目标不远了。Alex博士正在编写测试套件。编码器和解码器库在那里,因此并不特别复杂。RTP封装也不是特别复杂,它非常非常简单。
Chad:那么,是什么让它变得困难呢?
Bernard:诀窍在于我们所谓的依赖描述符头扩展,它是SFU用来转发的。它的棘手之处在于将支持构建到会议服务器中。AV1生来就允许端到端加密[e2ee],这是可插入的流切入的地方。
实际上,AV1作为编解码器在[编解码器]方面并没有太大的区别。我认为它是VP8 VP9谱系的下一个分支。它具有某种H.264类型的MAL单元语义,因此有点像H.264和VP9之间的交叉。
但是从会议服务器的总体使用模型的角度来看,它非常独特,因为你具有端到端加密,因此,例如,你不应该解析AV1 OBU。SFU应该纯粹基于对描述的依赖来做出前向决策,以允许端到端加密。因此,从本质上讲,你已经进入了下一个模型,在此模型中,SFU现在可能可以独立于编解码器。
可插入的流和SFrame
可插入的流是与编解码器独立性松散相关并且与端到端加密(e2ee)直接相关的一个主题。实际上,我们已经在该主题上发表了文章, 而Emil Ivov几周前在Kranky Geek上深入探讨了e2ee 。
我将让Berard谈谈可插入流API的应用。

在TPAC的可插入流上滑动。资料来源:TPAC-2020-Meetings(https://docs.google.com/prese...)
Bernard:端到端加密不仅仅是一个简单的用例。可插入流实际上是这个想法,在可插入流API模型中,一种思考方法是你可以访问框架。你可以对框架执行操作,但是你无法访问RTP标头或RTP标头扩展或类似内容。你不应明显地改变框架的大小。因此,你无法向其中添加大量元数据。你应该在帧上进行操作,然后将其实质上返回给打包器,然后打包器将其打包为RTP并发送出去。因此它与RTP有一定联系。
还有其他正在开发的API也可以按照为你提供视频帧的相同思想进行操作。
其中最突出的是WebCodecs以及用于原始媒体的可插入流。考虑这一点的方法是对媒体流跟踪的扩展,因为可插入流,原始媒体不依赖RTCPeerConnection,而可插入流和编码媒体则依赖。在所有这些API中,你都可以访问视频帧(原始帧或编码帧),然后可以对其执行操作,此后,你也必不可少地要将其返回。在插入流的情况下,它被分组并通过网络发送。
有一些棘手的方面,有些bug已经被归档了。它现在可以适用于VP8和VP9。但它不能与H264一起使用,我不确定这一部分,但是我们有一个仍在处理的错误。
这里同样重要的想法是,我们不会试图告诉开发人员如何进行他们的加密或使用哪种密钥管理方案。我们正在开发端到端加密格式的标准,即SFrame,并在那里进行IETF标准化工作。我们还没有就密钥管理计划达成完全一致。事实证明,有多种场景可能需要不同的密钥管理。
安全帧或SFrame是一种较新的提议,用于通过对整个媒体帧进行加密而不是对单个数据包进行加密来允许通过SFU的端到端媒体。由于每帧可以有多个数据包,因此可以更有效地运行。

来源:IETF Secure Frame (SFrame) proposal
(https://datatracker.ietf.org/...)
Bernard:让SFrame更具可扩展性的一个很酷的事情是,你是在一个完整的框架上操作,而不是在数据包上。这意味着,如果你做一个标记,你就在整个框架上做一次。对每个包进行数字标记被认为是不可行的。例如,对于一个关键帧,这意味着您可以为许多数据包签名。但是对于SFrame,您只对每一帧进行标记。
因此,它实际上导致标记的工作量大幅减少。因此,现在实际上可以进行基本的原始身份验证——知道每个帧来自谁,这在每个数据包模型中是不可能的。
每个人似乎都同意只需要一种SFrame格式,但对于密钥管理来说,这是一件更棘手的事情。我们已经在TPAC讨论过在浏览器中构建sfame的可能性——拥有Sfame的本地实现。我们还没有达到我们认为可以拥有本机密钥管理的程度。这是一件非常棘手的事情,因为你最终可能会在浏览器中使用五个密钥管理方案。
WebCodecs
WebCodecs的主题是给开发人员更深的访问权限和对实时传输控制堆栈的更多控制。我会让Bernard解释那是什么:
Bernard:WebCodecs的作用是让你在较低的层次上访问已经在浏览器中的编码解码器。所以本质上你要考虑的是它与可插入流有相似之处你可以访问一个帧。例如,您可以访问一个编码帧,或者您可以输入一个原始帧并获得一个编码帧。
Chad:好吧,那么它更低级别,直接访问另一端的编码器和解码器?
Bernard:是的。在解码端,类似于我们所说的均方误差(MSE)。
Chad:媒体来源扩展?
媒体源扩展和媒体源API取代了Flash在标准化的JavaScript中为流媒体所做的大部分工作。它允许开发人员向浏览器播放任何容器化媒体,即使它有DRM内容保护。这里有一个MDN链接可以了解更多信息。
https://developer.mozilla.org...
那么这与MSE相比如何呢?
Bernard:在解码端把它看作WebCodecs的方式类似于MSE,只不过媒体不是容器化的,它会在编码视频帧中,所以它们在这点上是相似的。
当别人问我“这些东西怎么一起用?”例如,如果你想要制作游戏流媒体或电影流媒体,你可以连接WebTransport来接收编码媒体。然后你可以用MSE渲染它,或者你可以用WebCodecs渲染它。中小企业的不同之处在于,你必须传输容器化的媒体。有了WebCodecs,它就不会被封装,而是被打包,所以有一点点不同。在MSE的功能中,您实际上可以获得内容保护支持。而在WebCodecs中,至少在今天,你不会获得内容保护支持。
Chad:在编码方面,MSE与WebCodecs有什么不同?
Bernard:这很有趣,因为如果你仔细想想,如果这是一个云游戏或电影或从云上下来的东西,你永远不会在浏览器上编码,只会解码。因此,这种情况实际上不需要WebCodecs来编码任何东西。例如,编码场景可以是视频上传。因此,如果你想上传视频,你可以用WebCodecs编码视频,然后通过网络传输发送。您可以使用可靠的流来发送它,也可以用数据报来发送。如果你用数据报来做,那么你就必须做你自己的重传和你自己的前向纠错。
如果您不太关心视频上传的延迟控制,您可以只使用可靠的流。因此,这是一个使用WebCodecs作为编码器的场景,我认为这个场景或用例是一个WebCodecs具有真正优势的场景,因为您不必做任何奇怪的技巧,比如把它放在白板上什么的,或者做任何事情。
面对这些替代品,WebRTC还有前景吗?
发视频是WebRTC做的一件大事。使用其他API如网络编码解码器或在WASM建立自己的编码解码器的网络传输会取代网络实时传输吗?事实上,这就是Zoom所做的(正如我们已经讨论过的),谷歌Chrome团队的一些成员甚至在上一次网络直播中推广了这一点。
Chad:方向是让人们自己去思考和做那些事情吗?或者你认为还会有一个平行的轨道来标准化这些机制吗?
Bernard:这是个真正的问题。从某种意义上说,你可以自由地做任何你想做的事情,如果你的世界里一切都是端到端的,那也没关系。举个例子,今天许多人想使用开源的SFU。你不能只是把你想要的任何东西发送到一个开源的SFU——它对它将要得到的东西有期望。就像视频上传之类的简单的场景中这可能并不重要,但在会议服务之类的场景中就很重要,最重要的是你需要有一个标准来了解所期望的内容。
现在,要考虑的另一件事是性能,因为我知道人们已经提出了尝试使用WebTransport制作会议服务器的可能性。我对此深感忧虑,因为特别是今天,如果你看看会议服务,对越来越多的人数有巨大的需求,比如7乘7,或者谁知道它们会有多大。
因此,学生们的需求似乎无法满足——老师们希望每个人都能来上课,而这个班级可能非常庞大。因此,在这种情况下,您会看到数量惊人的流,可能是高清的。在这种情况下,性能实际上非常重要。因因此,对于这种分解模型,很多代码都在WASM中运行,它是否会将所有东西复制无数次,这是一个真正的问题。这就是它今天的运作方式。例如,在WebTransport中,您在接收时有两份副本。无论何时你把任何东西发送到WASM,你都有一份副本。并不是所有内容都转移到单独的线程中。
Chad:我想资源的低效利用有很大的潜力——浏览器要管理所有这些资源还有很多工作要做。
Bernard:对。因此,人们确实抱怨WebRTC是单一的,但另一方面,当它是一个单一的代码库,其中没有运行所有的JavaScript时,有巨大的优化机会。你可以消除分类模型中可能存在的大量副本。
机器学习
ML是计算机科学中普遍存在的一个话题。几年前,我们甚至在RTC举办了2018年的Kranky Geek活动。我们已经看到了在JavaScript内部的ML的改进,比如我的“不要碰你的脸”实验,以及在各种WebRTC应用程序的后台删除/替换的进展。这些大部分都是围绕着WebRTC运行的,而不是直接使用它。事实上,ML在较低层次的WebRTC中似乎明显不存在。这件事我问过Bernard。
Bernard:当我们在WebRTC-NV上开始讨论时,我们做的一件事是做NV用例,并尝试评估人们热衷于做什么。事实证明,除了端到端加密之外,人们最感兴趣的事情之一是访问原始媒体,因为这打开了机器学习的整个世界。
Chad:让我也澄清一下——访问原始媒体只是为了降低延迟?在我的实验中,我发现当堆栈中存在大量固有延迟时,很难让这些东西实时运行。
Bernard:我们看到的很多场景都涉及到本地处理。举个例子,你有一个捕获媒体,你想在发送之前在捕获的媒体上做一些事情。例如,Snapchat中的许多效果都是这样做的。这就是我们所说的滑稽帽子,你观察面部位置,然后戴上帽子什么的。一个非常受欢迎的特性是定制背景,在这里你可以检测背景并以某种方式改变它——有动态背景,等等。
今天,机器学习在许多方面都是在云端完成的。例如,通常语音转录或翻译。所以你把它发送到云端,我不知道我们是否能在本地做到这一点,更不用说在Web浏览器中了。还有其他的一些事情是可以在本地完成,比如面部定位和身体姿势之类的事情。
长期的总体目标是能够做任何您可以在本地完成的、也可以在web上完成的事情。这不仅需要访问原始媒体,还需要以高效的方式访问。例如,在本地实现中,我们经常看到所有东西都留在GPU上所有操作都在那里完成。我们还没到那一步。要做到这一点,我们需要捕获GPU而不需要复制,然后允许机器学习操作在不将其复制回主存、上传和下载的情况下完成。
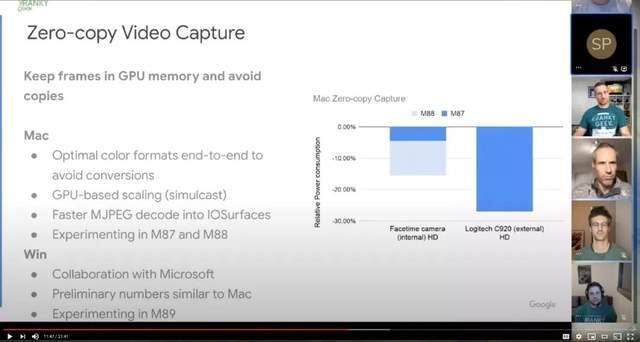
来源:Kranky Geek Virtual 2020 – Google WebRTC项目更新https://youtu.be/-THOaymtjp8?...
背景有点不同,谷歌实际上提到了“零复制视频捕获”来保持GPU帧:
Bernard:这是W3C研讨会上提出的一个话题。出现的概念之一是网络神经网络API。之前你看到的是很多像TensorFlow这样的库使用了像WebGL或者WebGPU这样的东西。但是如果你仔细想想,这并不是一个完全有效的方法。实际上,你要做的是让矩阵乘法这样的基本操作高效运行,仅仅给它WebGPU或WebGL操作并不一定是这样做的。因此,WebNN实际上试图在更高的层次上处理这些操作——比如矩阵乘法器的操作。
这里的一个关键是所有的API必须协同工作,这样它们就可以将数据传递到正确的地方,而不必复制到另一个API。举个例子,你会发现WebCodecs确实支持GPU缓冲区的概念,但是有一些限制,因为很多时候那些GPU缓冲区是不可写的——它们是只读的。所以如果你的目标是做机器学习和改变,GPU缓存里的东西,你不可能在没有副本的情况下做到这一点,但也许你会尝试获得尽可能多的性能。
2020年一个真正引起我注意的产品是英伟达的Maxine。英伟达在其图形处理器上使用生成对抗网络(GAN)来抓取少量关键帧,然后连续提取面部关键点,将关键帧数据与面部关键点相结合来重建面部。英伟达声称,这种方法使用的带宽只有H.264的十分之一。它还提供了新的功能,因为重建模型可以调整做一些事情,如超分辨率,面部重新排列,或模拟化身。
Chad:这似乎是ML对RTC更具革命性的使用。这也是标准的方向吗?
Bernard:如果你着眼于下一代编解码器的研究,现在有大量的研究是用机器学习完成的——这只是从编解码器的角度来看。我的思考方式是疫情期间观察你的周围,我们看到的是娱乐和实时会议的融合。所以你会看到你的许多节目——周六夜现场——都是通过视频会议制作的。我看的戏剧,里面的角色都有自己的背景。我们甚至看到了一些结合了会议技术的电影。从微软团队中,我们已经看到了我们所说的“协同模式”,它本质上是从会议服务中获取用户输入,并将其传输到一个完全合成的新事件中。篮球运动员是真实的,但它把比赛和实际上不在那里的球迷结合在一起。所以你构建了环境——增强现实/虚拟现实。我看到了娱乐和实时场景的融合。这反映在网络传输和WebCodecs等工具中。既有RTC又有流媒体。所有这些场景都是相同的。
机器学习可以是导演,可以是摄影师,可以是编辑,它可以把整个事情联系在一起。它的每个方面都可能受到机器学习的影响。
我不认为这只是一种传统媒体。我认为我们不应该认为这些只是试图用新的API做与之前同样的会议。这对于任何人来说都没有多大的激励作用,只是用这套全新的东西来重写你的会议服务。但我认为它实现了一套全新的娱乐和会议组合场景,这是我们今天甚至无法想象的。很多好像都有AR/VR的味道在里面。
Chad:好吧,那么会有更多的由人工智能控制的实时媒体类型的融合。
现在该做什么?
Chad:在我们结束之前,你还有什么想说的吗?
Bernard:关于这项新技术,有很多在原始试验中是可行的。使用它是很有启发性的,试着把东西放在一起看看它是如何工作的,因为你肯定会发现很多缺点。我不是说所有这些API在任何意义上都是一致的——它们不是。但我认为这会让你感觉到外面有什么是可能的,你能做什么。人们会对其中一些技术的问世速度感到惊讶。我想说,到2021年,这些东西很可能会开始上市,你会在商业应用中看到一些。所以人们经常把它当作今天不存在的东西,或者我不需要去想它,我认为他们是错的,那些这样想的人最终会感到非常惊讶。