Pandas
Pandas
Pandas可以进行统计特征计算,包括均值、方差、分位数、相关系数和协方差等,这些统计特征能反映数据的整体分布。
‘’’
mean():计算样本数据的算术平均值
std():计算标准差
cov():计算 协方差矩阵
var();计算方差
describe():描述样本数据的基本情况,包括非NaN数据个数,均值,标准差,最小值
样本的25%,50%,75%分位数,最大值
Pandas数据结构的范围可以从一维到三维。Series(序列)是一维的,DataFrame(数据框)是二维的,Panel是三维甚至更高维的数据结构。通常,Series和DataFrame可以用于大多数统计、工程、财务和社会科学的场景中。
Series:它是一个带标签的一维数组,可以用于存储任意类型数据,例如整型、浮点型、字符串和其他有效的Python对象。它的行标签称作index。
DataFrame:它是一个带标签的二维数组,有行和列。列可以有多种类型。DataFrame可以看作二维结构的数组,例如电子表格和数据库表格。DataFrame也可以看作包含多个不同类型的Series的集合。
Panel:在统计学和经济学中,Panel data(面板数据)指多维数据,这个多维数据包括不同时间的不同测量结果。该数据结构的名称来源于其概念。与Series和DataFrame相比,面板数据是不太常用的一种数据结构。
序列
构造一个序列可以使用如下方式实现:
通过同类型的列表或元组构建。
通过字典构建。
通过NumPy中的一维数组构建。
通过数据框中的某一列构建。
1.序列构造
#序列构建
import pandas as pd
import numpy as np
s1=pd.Series(np.array([1.5,2.5,4.5])) #由数组构造序列
s2=pd.Series({
"北京":1.5,"上海":2.5,"广东":4.5}) #由字典构造序列
s3=pd.Series([1.5,2.5,4.5],index=['b','c','d']) #给出行标签命名
print(s1)
print("-----------------")
print(s2)
print("-----------------")
print(s3)
运行结果:

序列有两列构成。
由数组构造的序列,其第一列是序列的行索引(可以理解为行号),自动从0开始,第二列才是序列的实际值。
通过字典构造的序列,第一列是具体的行名称(index),对应到字典中的键,第二列是序列的实际值,对应到字典中的值。
2.序列索引和计算
#序列索引和计算
import pandas as pd
import numpy as np
s=pd.Series([1.5,2.5,3.5],index=['a','b','c'])
a=s['b'] #取出序列第2个元素,输出:2.5
b1=np.mean(s)
b2=s.mean() #通过数列方法求均值
print(a,'\n',b1,'\n',b2)
运行结果:
2.5
2.5
2.5
数据框
DataFrame是由行和列构成的二维数据结构。虽然索引和列名称是可选的,但是最好把它们设置一下。索引可以看成是行标签,列名称可以看成是列标签。
数据框的创建方法如下:
DataFrame(data=二维数据 [, index=行索引[, columns=列索引[, dtype=数据类型]]])
其中的data可以是二维NumPy数组;
data如果是字典时,其值为一维数组,键为数据框的列名。
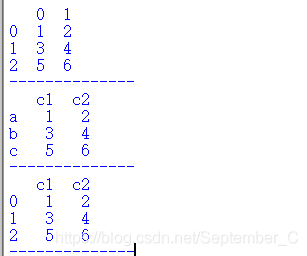
3.构造数据框
#构造数据框
import pandas as pd
import numpy as np
a=np.arange(1,7).reshape(3,2)
df1=pd.DataFrame(a)
df2=pd.DataFrame(a,index=['a','b','c'],columns=['c1','c2'])
df3=pd.DataFrame({
'c1':a[:,0],'c2':a[:,1]})
print(df1)
print("--------------")
print(df2)
print("--------------")
print(df3)
print("--------------")
运行结果: