Coursera-Deep Learning Specialization 课程之(五):Sequence Models: -weak2编程作业 (第二部分)
Emojify!
1 - Baseline model: Emojifier-V1
1.3 - Implementing Emojifier-V1
# GRADED FUNCTION: sentence_to_avg
def sentence_to_avg(sentence, word_to_vec_map):
"""
Converts a sentence (string) into a list of words (strings). Extracts the GloVe representation of each word
and averages its value into a single vector encoding the meaning of the sentence.
Arguments:
sentence -- string, one training example from X
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
Returns:
avg -- average vector encoding information about the sentence, numpy-array of shape (50,)
"""
### START CODE HERE ###
# Step 1: Split sentence into list of lower case words (≈ 1 line)
words = sentence.lower().split()
# Initialize the average word vector, should have the same shape as your word vectors.
avg = np.zeros((50,))
# Step 2: average the word vectors. You can loop over the words in the list "words".
for w in words:
avg += word_to_vec_map[w]
avg = avg/len(words)
### END CODE HERE ###
return avgavg = sentence_to_avg("Morrocan couscous is my favorite dish", word_to_vec_map)
print("avg = ", avg)avg = [-0.008005 0.56370833 -0.50427333 0.258865 0.55131103 0.03104983
-0.21013718 0.16893933 -0.09590267 0.141784 -0.15708967 0.18525867
0.6495785 0.38371117 0.21102167 0.11301667 0.02613967 0.26037767
0.05820667 -0.01578167 -0.12078833 -0.02471267 0.4128455 0.5152061
0.38756167 -0.898661 -0.535145 0.33501167 0.68806933 -0.2156265
1.797155 0.10476933 -0.36775333 0.750785 0.10282583 0.348925
-0.27262833 0.66768 -0.10706167 -0.283635 0.59580117 0.28747333
-0.3366635 0.23393817 0.34349183 0.178405 0.1166155 -0.076433
0.1445417 0.09808667]
# GRADED FUNCTION: model
def model(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400):
"""
Model to train word vector representations in numpy.
Arguments:
X -- input data, numpy array of sentences as strings, of shape (m, 1)
Y -- labels, numpy array of integers between 0 and 7, numpy-array of shape (m, 1)
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
learning_rate -- learning_rate for the stochastic gradient descent algorithm
num_iterations -- number of iterations
Returns:
pred -- vector of predictions, numpy-array of shape (m, 1)
W -- weight matrix of the softmax layer, of shape (n_y, n_h)
b -- bias of the softmax layer, of shape (n_y,)
"""
np.random.seed(1)
# Define number of training examples
m = Y.shape[0] # number of training examples
n_y = 5 # number of classes
n_h = 50 # dimensions of the GloVe vectors
# Initialize parameters using Xavier initialization
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
# Convert Y to Y_onehot with n_y classes
Y_oh = convert_to_one_hot(Y, C = n_y)
# Optimization loop
for t in range(num_iterations): # Loop over the number of iterations
for i in range(m): # Loop over the training examples
### START CODE HERE ### (≈ 4 lines of code)
# Average the word vectors of the words from the i'th training example
avg = sentence_to_avg(X[i],word_to_vec_map)
# Forward propagate the avg through the softmax layer
z = np.dot(W,avg)+b
a = softmax(z)
# Compute cost using the i'th training label's one hot representation and "A" (the output of the softmax)
cost = -np.sum(Y_oh[i]*np.log(a))
### END CODE HERE ###
# Compute gradients
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h))
db = dz
# Update parameters with Stochastic Gradient Descent
W = W - learning_rate * dW
b = b - learning_rate * db
if t % 100 == 0:
print("Epoch: " + str(t) + " --- cost = " + str(cost))
pred = predict(X, Y, W, b, word_to_vec_map)
return pred, W, bprint(X_train.shape)
print(Y_train.shape)
print(np.eye(5)[Y_train.reshape(-1)].shape)
print(X_train[0])
print(type(X_train))
Y = np.asarray([5,0,0,5, 4, 4, 4, 6, 6, 4, 1, 1, 5, 6, 6, 3, 6, 3, 4, 4])
print(Y.shape)
X = np.asarray(['I am going to the bar tonight', 'I love you', 'miss you my dear',
'Lets go party and drinks','Congrats on the new job','Congratulations',
'I am so happy for you', 'Why are you feeling bad', 'What is wrong with you',
'You totally deserve this prize', 'Let us go play football',
'Are you down for football this afternoon', 'Work hard play harder',
'It is suprising how people can be dumb sometimes',
'I am very disappointed','It is the best day in my life',
'I think I will end up alone','My life is so boring','Good job',
'Great so awesome'])
print(X.shape)
print(np.eye(5)[Y_train.reshape(-1)].shape)
print(type(X_train))
(132,)
(132,)
(132, 5)
never talk to me again
pred, W, b = model(X_train, Y_train, word_to_vec_map)
print(pred)Expected Output (on a subset of iterations):
Epoch: 0 cost = 1.95204988128 Accuracy: 0.348484848485
Epoch: 100 cost = 0.0797181872601 Accuracy: 0.931818181818
Epoch: 200 cost = 0.0445636924368 Accuracy: 0.954545454545
Epoch: 300 cost = 0.0343226737879 Accuracy: 0.969696969697.
1.4 - Examining test set performance
print("Training set:")
pred_train = predict(X_train, Y_train, W, b, word_to_vec_map)
print('Test set:')
pred_test = predict(X_test, Y_test, W, b, word_to_vec_map)
```Training set:
Accuracy: 0.977272727273
Test set:
Accuracy: 0.857142857143
<div class="se-preview-section-delimiter">div>
X_my_sentences = np.array([“i adore you”, “i love you”, “funny lol”, “lets play with a ball”, “food is ready”, “not feeling happy”])
Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map)
print_predictions(X_my_sentences, pred)
“`
X_my_sentences = np.array(["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "not feeling happy"])
Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map)
print_predictions(X_my_sentences, pred)
```Accuracy: 0.833333333333
i adore you ❤️
i love you ❤️
funny lol ��
lets play with a ball ⚾
food is ready ��
not feeling happy ��
"se-preview-section-delimiter">
print(Y_test.shape)
print(’ ‘+ label_to_emoji(0)+ ’ ’ + label_to_emoji(1) + ’ ’ + label_to_emoji(2)+ ’ ’ + label_to_emoji(3)+’ ’ + label_to_emoji(4))
print(pd.crosstab(Y_test, pred_test.reshape(56,), rownames=[‘Actual’], colnames=[‘Predicted’], margins=True))
plot_confusion_matrix(Y_test, pred_test)
“`
(56,)
print(Y_test.shape)
print(' '+ label_to_emoji(0)+ ' ' + label_to_emoji(1) + ' ' + label_to_emoji(2)+ ' ' + label_to_emoji(3)+' ' + label_to_emoji(4))
print(pd.crosstab(Y_test, pred_test.reshape(56,), rownames=['Actual'], colnames=['Predicted'], margins=True))
plot_confusion_matrix(Y_test, pred_test)
❤️ ⚾ �� �� ��
Predicted 0.0 1.0 2.0 3.0 4.0 All
Actual
0 6 0 0 1 0 7
1 0 8 0 0 0 8
2 2 0 16 0 0 18
3 1 1 2 12 0 16
4 0 0 1 0 6 7
All 9 9 19 13 6 56
2 - Emojifier-V2: Using LSTMs in Keras:
import numpy as np
np.random.seed(0)
from keras.models import Model
from keras.layers import Dense, Input, Dropout, LSTM, Activation
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
from keras.initializers import glorot_uniform
np.random.seed(1)2.1 - Overview of the model
2.3 - The Embedding layer
# GRADED FUNCTION: sentences_to_indices
def sentences_to_indices(X, word_to_index, max_len):
"""
Converts an array of sentences (strings) into an array of indices corresponding to words in the sentences.
The output shape should be such that it can be given to `Embedding()` (described in Figure 4).
Arguments:
X -- array of sentences (strings), of shape (m, 1)
word_to_index -- a dictionary containing the each word mapped to its index
max_len -- maximum number of words in a sentence. You can assume every sentence in X is no longer than this.
Returns:
X_indices -- array of indices corresponding to words in the sentences from X, of shape (m, max_len)
"""
m = X.shape[0] # number of training examples
### START CODE HERE ###
# Initialize X_indices as a numpy matrix of zeros and the correct shape (≈ 1 line)
X_indices = np.zeros((m,max_len))
for i in range(m): # loop over training examples
# Convert the ith training sentence in lower case and split is into words. You should get a list of words.
sentence_words =X[i].lower().split()
# Initialize j to 0
j = 0
# Loop over the words of sentence_words
for w in sentence_words:
# Set the (i,j)th entry of X_indices to the index of the correct word.
X_indices[i, j] = word_to_index[w]
# Increment j to j + 1
j = j+1
### END CODE HERE ###
return X_indicesX1 = np.array(["funny lol", "lets play baseball", "food is ready for you"])
X1_indices = sentences_to_indices(X1,word_to_index, max_len = 5)
print("X1 =", X1)
print("X1_indices =", X1_indices)X1 = [‘funny lol’ ‘lets play baseball’ ‘food is ready for you’]
X1_indices = [[ 155345. 225122. 0. 0. 0.]
[ 220930. 286375. 69714. 0. 0.]
[ 151204. 192973. 302254. 151349. 394475.]]
# GRADED FUNCTION: pretrained_embedding_layer
def pretrained_embedding_layer(word_to_vec_map, word_to_index):
"""
Creates a Keras Embedding() layer and loads in pre-trained GloVe 50-dimensional vectors.
Arguments:
word_to_vec_map -- dictionary mapping words to their GloVe vector representation.
word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words)
Returns:
embedding_layer -- pretrained layer Keras instance
"""
vocab_len = len(word_to_index) + 1 # adding 1 to fit Keras embedding (requirement)
emb_dim = word_to_vec_map["cucumber"].shape[0] # define dimensionality of your GloVe word vectors (= 50)
### START CODE HERE ###
# Initialize the embedding matrix as a numpy array of zeros of shape (vocab_len, dimensions of word vectors = emb_dim)
emb_matrix = np.zeros((vocab_len,emb_dim))
# Set each row "index" of the embedding matrix to be the word vector representation of the "index"th word of the vocabulary
for word, index in word_to_index.items():
emb_matrix[index, :] = word_to_vec_map[word]
# Define Keras embedding layer with the correct output/input sizes, make it trainable. Use Embedding(...). Make sure to set trainable=False.
embedding_layer = Embedding(vocab_len,emb_dim,trainable=False)
### END CODE HERE ###
# Build the embedding layer, it is required before setting the weights of the embedding layer. Do not modify the "None".
embedding_layer.build((None,))
# Set the weights of the embedding layer to the embedding matrix. Your layer is now pretrained.
embedding_layer.set_weights([emb_matrix])
return embedding_layerembedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
print("weights[0][1][3] =", embedding_layer.get_weights()[0][1][3])2.3 Building the Emojifier-V2
# GRADED FUNCTION: Emojify_V2
def Emojify_V2(input_shape, word_to_vec_map, word_to_index):
"""
Function creating the Emojify-v2 model's graph.
Arguments:
input_shape -- shape of the input, usually (max_len,)
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words)
Returns:
model -- a model instance in Keras
"""
### START CODE HERE ###
# Define sentence_indices as the input of the graph, it should be of shape input_shape and dtype 'int32' (as it contains indices).
sentence_indices = sentence_indices = Input(input_shape, dtype='int32')
# Create the embedding layer pretrained with GloVe Vectors (≈1 line)
embedding_layer = embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
# Propagate sentence_indices through your embedding layer, you get back the embeddings
embeddings = embedding_layer(sentence_indices)
# Propagate the embeddings through an LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a batch of sequences.
X = LSTM(128, return_sequences=True)(embeddings)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X trough another LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a single hidden state, not a batch of sequences.
X = LSTM(128, return_sequences=False)(X)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X through a Dense layer with softmax activation to get back a batch of 5-dimensional vectors.
X = Dense(5)(X)
# Add a softmax activation
X = Activation('softmax')(X)
# Create Model instance which converts sentence_indices into X.
model = Model(inputs=sentence_indices,outputs=X)
### END CODE HERE ###
return modelmodel = Emojify_V2((maxLen,), word_to_vec_map, word_to_index)
model.summary()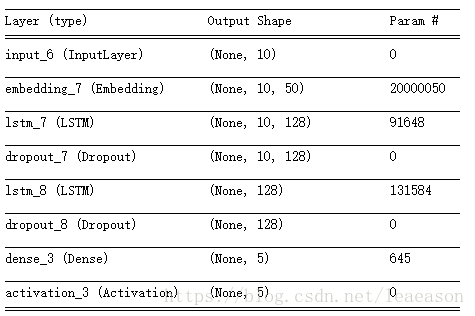
Total params: 20,223,927
Trainable params: 223,877
Non-trainable params: 20,000,050
model.fit(X_train_indices, Y_train_oh, epochs = 50, batch_size = 32, shuffle=True)Epoch 1/50
132/132 [==============================] - 0s - loss: 1.5888 - acc: 0.3106
Epoch 2/50
132/132 [==============================] - 0s - loss: 1.5299 - acc: 0.3258
Epoch 3/50
132/132 [==============================] - 0s - loss: 1.4601 - acc: 0.3561
Epoch 4/50
132/132 [==============================] - 0s - loss: 1.4097 - acc: 0.4697
Epoch 5/50
132/132 [==============================] - 0s - loss: 1.2922 - acc: 0.5909 - ETA: 0s - loss: 1.2952 - acc: 0.5
Epoch 6/50
132/132 [==============================] - 0s - loss: 1.1628 - acc: 0.6212
Epoch 7/50
132/132 [==============================] - 0s - loss: 1.0218 - acc: 0.5985
Epoch 8/50
132/132 [==============================] - 0s - loss: 0.9362 - acc: 0.5758
Epoch 9/50
132/132 [==============================] - 0s - loss: 0.8741 - acc: 0.6818
Epoch 10/50
132/132 [==============================] - 0s - loss: 0.7400 - acc: 0.7500
Epoch 11/50
132/132 [==============================] - 0s - loss: 0.6614 - acc: 0.7803
Epoch 12/50
132/132 [==============================] - 0s - loss: 0.7047 - acc: 0.7652
Epoch 13/50
132/132 [==============================] - 0s - loss: 0.7020 - acc: 0.7500
Epoch 14/50
132/132 [==============================] - 0s - loss: 0.7872 - acc: 0.7121
Epoch 15/50
132/132 [==============================] - 0s - loss: 0.5422 - acc: 0.8333
Epoch 16/50
132/132 [==============================] - 0s - loss: 0.5135 - acc: 0.8333
Epoch 17/50
132/132 [==============================] - 0s - loss: 0.4245 - acc: 0.8788
Epoch 18/50
132/132 [==============================] - 0s - loss: 0.3978 - acc: 0.8561
Epoch 19/50
132/132 [==============================] - 0s - loss: 0.3575 - acc: 0.8939
Epoch 20/50
132/132 [==============================] - 0s - loss: 0.3730 - acc: 0.8788
Epoch 21/50
132/132 [==============================] - 0s - loss: 0.3674 - acc: 0.8788
Epoch 22/50
132/132 [==============================] - 0s - loss: 0.2523 - acc: 0.9167
Epoch 23/50
132/132 [==============================] - 0s - loss: 0.2698 - acc: 0.9091
Epoch 24/50
132/132 [==============================] - 0s - loss: 0.3899 - acc: 0.8788
Epoch 25/50
132/132 [==============================] - 0s - loss: 0.3978 - acc: 0.8485
Epoch 26/50
132/132 [==============================] - 0s - loss: 0.2802 - acc: 0.8864
Epoch 27/50
132/132 [==============================] - 0s - loss: 0.2703 - acc: 0.9091
Epoch 28/50
132/132 [==============================] - 0s - loss: 0.1756 - acc: 0.9697
Epoch 29/50
132/132 [==============================] - 0s - loss: 0.2059 - acc: 0.9242
Epoch 30/50
132/132 [==============================] - 0s - loss: 0.3586 - acc: 0.8864
Epoch 31/50
132/132 [==============================] - 0s - loss: 0.3518 - acc: 0.8561
Epoch 32/50
132/132 [==============================] - 0s - loss: 0.2116 - acc: 0.9394
Epoch 33/50
132/132 [==============================] - 0s - loss: 0.3801 - acc: 0.8561
Epoch 34/50
132/132 [==============================] - 0s - loss: 0.2007 - acc: 0.9242
Epoch 35/50
132/132 [==============================] - 0s - loss: 0.2072 - acc: 0.9470
Epoch 36/50
132/132 [==============================] - 0s - loss: 0.1615 - acc: 0.9318
Epoch 37/50
132/132 [==============================] - 0s - loss: 0.1019 - acc: 0.9848
Epoch 38/50
132/132 [==============================] - 0s - loss: 0.0991 - acc: 0.9848
Epoch 39/50
132/132 [==============================] - 0s - loss: 0.1185 - acc: 0.9697
Epoch 40/50
132/132 [==============================] - 0s - loss: 0.0891 - acc: 0.9697
Epoch 41/50
132/132 [==============================] - 0s - loss: 0.0820 - acc: 0.9773
Epoch 42/50
132/132 [==============================] - 0s - loss: 0.0691 - acc: 0.9924
Epoch 43/50
132/132 [==============================] - 0s - loss: 0.0468 - acc: 0.9924
Epoch 44/50
132/132 [==============================] - 0s - loss: 0.0427 - acc: 0.9848
Epoch 45/50
132/132 [==============================] - 0s - loss: 0.1823 - acc: 0.9167
Epoch 46/50
132/132 [==============================] - 0s - loss: 0.2270 - acc: 0.9091
Epoch 47/50
132/132 [==============================] - 0s - loss: 0.1793 - acc: 0.9394
Epoch 48/50
132/132 [==============================] - 0s - loss: 0.1913 - acc: 0.9318
Epoch 49/50
132/132 [==============================] - 0s - loss: 0.1709 - acc: 0.9394
Epoch 50/50
132/132 [==============================] - 0s - loss: 0.0842 - acc: 0.9848
X_test_indices = sentences_to_indices(X_test, word_to_index, max_len = maxLen)
Y_test_oh = convert_to_one_hot(Y_test, C = 5)
loss, acc = model.evaluate(X_test_indices, Y_test_oh)
print()
print("Test accuracy = ", acc)# This code allows you to see the mislabelled examples
C = 5
y_test_oh = np.eye(C)[Y_test.reshape(-1)]
X_test_indices = sentences_to_indices(X_test, word_to_index, maxLen)
pred = model.predict(X_test_indices)
for i in range(len(X_test)):
x = X_test_indices
num = np.argmax(pred[i])
if(num != Y_test[i]):
print('Expected emoji:'+ label_to_emoji(Y_test[i]) + ' prediction: '+ X_test[i] + label_to_emoji(num).strip())Expected emoji:�� prediction: work is hard ��
Expected emoji:�� prediction: This girl is messing with me ❤️
Expected emoji:�� prediction: work is horrible ��
Expected emoji:�� prediction: any suggestions for dinner ��
Expected emoji:❤️ prediction: I love taking breaks ��
Expected emoji:�� prediction: you brighten my day ��
Expected emoji:�� prediction: she is a bully ❤️
Expected emoji:❤️ prediction: I love you to the stars and back ��
Expected emoji:❤️ prediction: family is all I have ��# Change the sentence below to see your prediction. Make sure all the words are in the Glove embeddings.
x_test = np.array(['not feeling happy'])
X_test_indices = sentences_to_indices(x_test, word_to_index, maxLen)
print(x_test[0] +' '+ label_to_emoji(np.argmax(model.predict(X_test_indices))))