Hive源码本地IDEA调试的正确姿势
Hive源码本地IDEA调试的正确姿势
-
- 背景
- 环境准备
- 初始化配置
-
- 修改配置
- 初始化元数据库
- 编译代码
- 启动HiveMetaStore
- 启动Hive sql客户端
-
- Client Driver模式
- HiveServer2模式
-
- 启动HiveServer2
- 启动beeline客户端
-
- 本地启动
- 远程启动
- 总结
背景
Hive作为最最基础的大数据框架,可以说,没装Hive,就等于没有大数据这回事。Hive的功能也越来越强大,经过大多数用户市场的检验,也诞生许多稳定的版本。所以,大多数人把Hive当成黑盒使用,只需要明白其原理。但是,万一某种情况下,你的需求里出现未知bug或者有新的需求需要改造的时候,这时你不得不跟Hive源码打交道。本人在最近的Hive bug修复和开发中也走了不少弯路,网上的教程要么是依赖外部环境太重,要么问题重重,找不到像样的,现在总结出来给各位,避免踩坑。
环境准备
-
Hive
这里选用hive2.3.7版本,2.x版本中的稳定版,不算太新,也不算太老源码下载: http://mirror.bit.edu.cn/apache/hive/stable-2/apache-hive-2.3.7-src.tar.gz
-
Ubuntu 或Mac os
这里重点说明下,windows并不适合大型项目的开发调试,会涉及到许多环境问题,使用unix系统更适合,有条件的可以使用Mac,没条件的推荐使用 ubuntu系统,使用win系统不适合本教程
-
thrift
由于Hive的Hiveserver2和Metastore组件本质上都是一个Thrift Server,可以满足跨语言间的RPC通信。注意Thrift有严格的版本要求,环境的版本需要与代码里保持一致,在pom.xml文件
安装:
wget http://mirror.bit.edu.cn/apache/thrift/0.9.3/thrift-0.9.3.tar.gz . tar -zxvf thrift-0.9.3.tar.gz cd thrift-0.9.3 sudo apt-get install libssl1.0-dev #不装libssl1.0-dev安装会失败 ./configure --prefix=/home/lijufeng/tmp/thrift #这里/home/lijufeng/tmp/thrift为thrift安装目录,后面要用到 sudo make sudo make install -
jdk1.8
-
maven3
-
mysql5.7或mysql8
-
IDEA
项目比较大,idea的本身运行内存和编译内存设置大点,编译内存设置如下
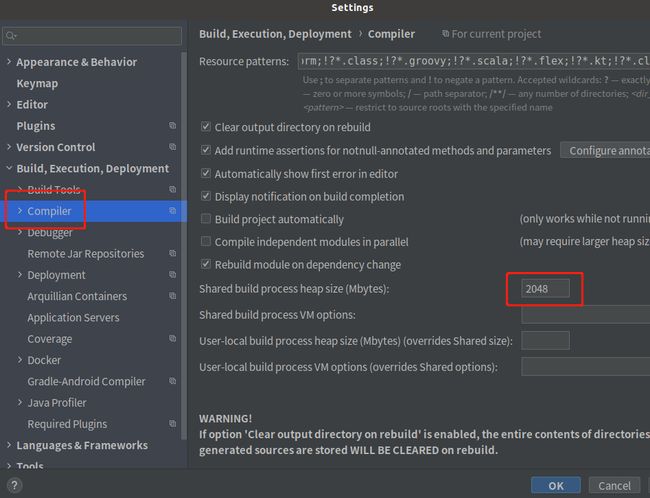
特别说明下:本地调试和运行hive-sql不需要依赖和安装hadoop,表数据文件存放本地系统目录不依赖hdfs,计算也不依赖yarn!
初始化配置
修改配置
- 修改配置文件hive-site.xml:
由于不依赖hdfs,hive的数据都放本地目录
cd apache-hive-2.3.7-src
vi conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>datanucleus.schema.autocreateall</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>file:///tmp/hive/warehouse</value>
</property>
<property>
<name>fs.default.name</name>
<value>file:///tmp/hive</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.DefaultHiveMetastoreAuthorizationProvider</value>
<description>The hive client authorization manager class name.</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9083</value>
</property>
<property>
<name>hive.privilege.synchronizer</name>
<value>false</value>
</property>
</configuration>
注意一定要严格按照上面的配置去改,尤其是datanucleus.schema.autocreateall配置项,不然后面HiveMetaStore起不来,网上也没有任何答案!
-
修改pom.xml文件
vim pom.xml # 把上面thrift的安装路径填上去 <thrift.home>/home/lijufeng/tmp/thrift</thrift.home>vim cli/pom.xml # 把hive-site.xml等配置文件打包 <build> <resources> <resource> <directory>../conf</directory> <includes> <include>*.*</include> </includes> </resource> </resources> </build> # 把test 改成runtime <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>${commons-io.version}</version> <scope>runtime</scope> </dependency> <dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>${disruptor.version}</version> <scope>runtime</scope> </dependency>vim metastore/pom.xml # 把hive-site.xml等配置文件打包 <build> <resources> <resource> <directory>../conf</directory> <includes> <include>*.*</include> </includes> </resource> </resources> </build> # 把test 改成runtime <dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>${disruptor.version}</version> <scope>runtime</scope> </dependency> #添加mysql jdbc驱动包依赖,我这里用的是mysql8 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.22</version> </dependency>vim service/pom.xml # hive-site.xml等配置文件打包 <build> <resources> <resource> <directory>../conf</directory> <includes> <include>*.*</include> </includes> </resource> </resources> </build>vim beeline/pom.xml # 把test 改成runtime <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> <scope>runtime</scope> </dependency> -
修改
HiveConf.java文件,修改参数默认值hive.in.test=true hive.in.tez.test=true hive.exec.mode.local.auto=true -
修改
apache-hive-2.3.7-src/metastore/if/hive_metastore.thrift文件第25行vim apache-hive-2.3.7-src/metastore/if/hive_metastore.thrift # 找到自己的thrift下载的源码路径(编译前),注意不是安装路径,25行替换成如下 include "/home/lijufeng/tmp/thrift-0.9.3/contrib/fb303/if/fb303.thrift"
初始化元数据库
mysql -uroot -p123456
create database hive;
use hive;
source /home/lijufeng/tmp/apache-hive-2.3.7-src/metastore/scripts/upgrade/mysql/hive-schema-2.3.0.mysql.sql
source /home/lijufeng/tmp/apache-hive-2.3.7-src/metastore/scripts/upgrade/mysql/hive-txn-schema-2.3.0.mysql.sql
这里要注意,源码路径apache-hive-2.3.7-src/metastore/scripts/upgrade/mysql/下有很多个版本的sql文件,对应不同版本,这里三hive2.3.7版本,对应
hive-schema-2.3.0.mysql.sql、hive-txn-schema-2.3.0.mysql.sql两个文件
编译代码
如图

也可以执行编译命令:
mvn clean compile -Dmaven.test.skip=true -P thriftif,protobuf
启动HiveMetaStore
HiveMetaStore是hive最核心的组件,没有之一,可以没有HiveServer2,但是一定不能没有HiveMetaStore
修改metastore/pom.xml文件,加上下面依赖
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>${project.version}version>
<scope>runtimescope>
dependency>
一定要注意!必须编译完后再修改这个pom文件,不然会产生循环依赖的报错!修改完后一定要导入maven,点红圈圈里面

细节决定成败,一步都不能落下!
找到org.apache.hadoop.hive.metastore.HiveMetaStore类后,以下两项相当重要:
- 把主类的启动前自动编译禁掉,不然会报循环依赖的错误编译不通过
- 检查hive-site.xml是否文件在target/classes下,如果不在,请检查上面的pom.xml文件配置
启动main方法:
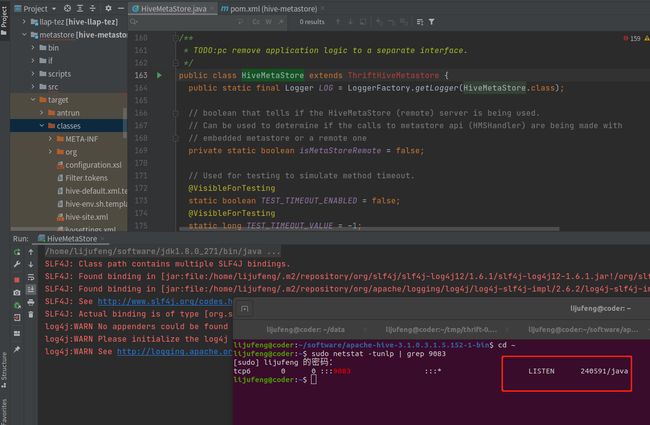
启动成功后查看9083端口是否成功被占用
sudo netstat -tunlp | grep 9083
启动Hive sql客户端
Hive的sql客户端启动有两种方式,一种是基于CliDriver的方式,sql的解析提交和监控管理都在本地进程中,也是最早的hive版本的启动形式;另一种的基于HiveServer2模式,需要使用beeline客户端或者jdbc的方式进行连接,这种方式中用户的客户端提交sql后都在HiveServer2中完成解析和提交。
Client Driver模式
启动主类org.apache.hadoop.hive.cli.CliDriver,注意都禁止启动前的自动编译!

启动成功后会提供一个交互式的窗口,可以自由的执行sql,同时也可以执行计算型的sql,默认引擎是mr,但是不跑在yarn上,跑在本的,方便debug
HiveServer2模式
启动HiveServer2
启动主类org.apache.hive.service.server.HiveServer2,注意都禁止启动前的自动编译!

启动后查看端口是否被成功占用
sudo netstat -tunlp | grep 10000
启动beeline客户端
beeline客户端启动有两种方式,一种是启动源码的类org.apache.hive.beeline.BeeLine的方式,这里就叫本地启动;另一种是在你任意一台安装了hive的机器上,注意网络要通,启动beeline命令行连接,这里叫做远程启动
本地启动
vi beeline/pom.xml
# 把 test 改成 runtime
org.apache.hive
hive-service
${project.version}
runtime
记得改完后务必导入maven依赖!!
启动主类org.apache.hive.beeline.BeeLine,传入args参数-u jdbc:hive2://127.0.0.1:10000 -n hive -p hive注意都禁止启动前的自动编译!
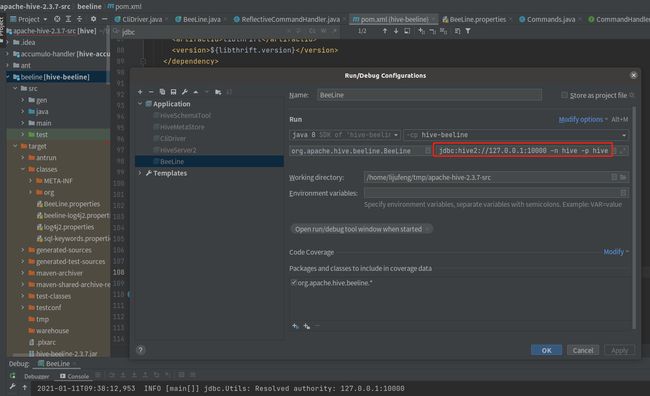
同样会生成一个sql交互窗口,跟你平常执行hive sql一样的效果

远程启动
这种方式可能就是平常工作用的方式,找一台已经装过hive的任意机器,网络要通,执行连接命令:
beeline -u jdbc:hive2://你机器的ip:10000 -n hive -p hive
这里要注意安装的hive版本与源码版本中,保证thrift版本必须一致才行!

总结
关于Hive源码调试的方法,或许还有更好的办法,此篇文章也是作为小白一步一步踩坑总结出来的。期间修复了两个Hive3.1.0的bug,一个已提交pr到官方社区
HIVE-24609,另一个Hive时区导致相差8小时的问题也已提交到自己维护的代码仓库,timestamp-utc8-fix 。希望本篇教程对你有用,一定要严格按照上面教程去配置,非常多细节的东西,一不注意就run不起来,动动手,告别黑盒式的Hive,自己本地跑起来,收货会很大。