论文笔记 | graph pre-training 系列论文
图预训练论文笔记
-
- 1. Strategies for pre-training graph neural networks
- 2. Multi-stage self-supervised learning for Graph Convolutional Networks on graphs with few labeled nodes
-
- Motivation
- 具体方法
- 3. GPT-GNN: Generative Pre-training of Graph Neural Networks
- 4. Pre-training Graph Neural Networks for Generic Structural Feature Extraction
-
- Motivation
- 具体方法
- 分析
- 5. Graph-BERT: Only Attention is Needed for Learning Graph Representation
- 6. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
- 7. Deep Graph InfoMax
1. Strategies for pre-training graph neural networks
ICLR 2020
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, Jure Leskovec
Stanford University, The University of Iowa, Harvard University
关键词:GNN pre-training, node-level and graph level pre-training tasks
code and data
本文是针对图数据做的预训练,作者从两个维度考虑,将预训练任务划分为四种。
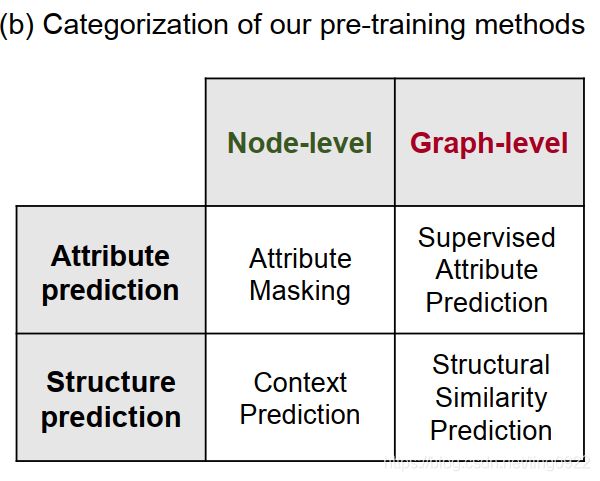
本文使用了三个预训练任务,分别为Attribute masking, Context prediction, supervised attribute prediction。
1. Attribute masking (node-level self-supervised learning)
将图中15%的节点属性或者边属性mask掉,利用GNN学习节点的embedding,最后接上一个线性模型去预测被mask掉的属性值。

2. Context prediction (node-level)
利用subgraph去预测周围的图结构,目标是预训练一个GNN模型,这个模型可以使得出现在类似结构中的节点embedding相近。
对于每个节点,有两种表示,一种是基于k-hop邻居节点的表示,一种是context graph embedding,图示如下:
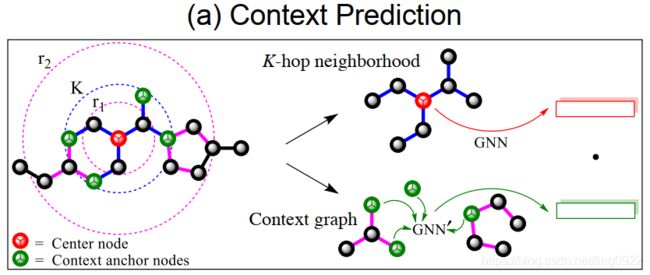
其中,中心节点的K-hop邻居是指距离该中心节点的最短路径小于等于K的节点,即上图中蓝色虚线圈内的节点。K-hop neighborhood embedding是指中心节点基于k阶邻居的向量表示,也就是利用GNN(main GNN)迭代k次,学习得到的表示。中心节点的context graph是指该中心节点 r 1 r_1 r1-hop 到 r 2 r_2 r2-hop 之间的部分,也就是上图中小虚线红圈和大虚线红圈中间的部分。这个部分与节点的K-hop邻居节点相交的节点称为context anchor nodes。通过另一个GNN(context GNN)网络学习得到节点embedding,然后将context anchor node embedding平均,得到context graph embedding。
得到了两种表示之后,通过负采样的方式联合学习main GNN和context GNN。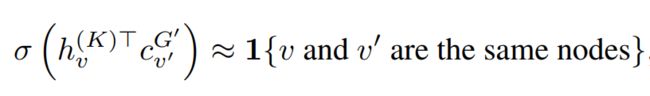
这里的 h v ( K ) T h_v^{(K)T} hv(K)T 是指中心节点v通过GNN迭代K次得到的节点表示, c v ′ G ′ c_{v'}^{G'} cv′G′是context graph embedding。正样本是中心节点v和v’是同一个节点,负样本是随机选择一个与v不同的节点。每个正样本对应一个负样本。
学习得到的main GNN作为预训练后的模型。
3. Supervised attribute prediction (graph-level)
两个node-level prediction的预训练任务都是self-supervised的,这里的graph-level预训练任务是supervised的。其中的监督信号是图的label,也就是通过图的embedding预测其label。
4. graph-level structure prediction
对应的预训练任务是structure similarity prediciton。相关的工作包括:modeling the graph edit distance (Bai et al., 2019) or predicting graph structure similarity (Navarin et al., 2018)。但是由于graph distance的groundtruth却反,并且也没有graph相似度的数值,较难进行预训练,所以这篇文章就没有考虑这方面的预训练任务。
在实验验证方面,主要解答了三个问题:
- 下游任务中,有预训练和没有预训练的对比,提升了9.4%
- 本文的node-level和graph-level相结合的预训练方式,先比于只进行node-level或者graph-level的预训练,效果提升5.4%
- 本文预训练使用的GIN图神经网络,相比于使用GCN、GraphSAGE、GAT等效果要好。
2. Multi-stage self-supervised learning for Graph Convolutional Networks on graphs with few labeled nodes
AAAI 2020
Ke Sun, Zhouchen Lin, Zhanxing Zhu
Peking University, Samsung Research China
key words:multi-stage training, self-supervised learning, few labeled data prediction
Motivation
[Li, Han, and Wu 2018]中解释了GCN网络分类效果好的原理,提出GCN的本质是Laplacian smoothing。平滑操作使得在同一个类别中的节点信息趋同,然后易于分类。但是当GCN网络深度增加,也有可能导致over-smoothing,导致不同类别的节点无法准确识别。
在Karate Club dataset(空手道俱乐部成员关系数据)上利用GCN学习节点表示。这个数据集包含34个节点,78条边,两个类别。
【故事:这个空手道俱乐部包含34名成员,管理员 John A 和教官 Mr. Hi 之间的一次冲突导致这个俱乐部一分为二,一半的成员围绕着 Mr. Hi 成立了一个新俱乐部,另一半成员要么找到了新的教练,要么放弃了空手道。因此,在对应的社交网络中,节点也被划分为两个组,一组属于Mr. Hi (Instructor) ,另一组属于John A (Administrator),其中节点0代表Mr. Hi,节点33代表John A。】
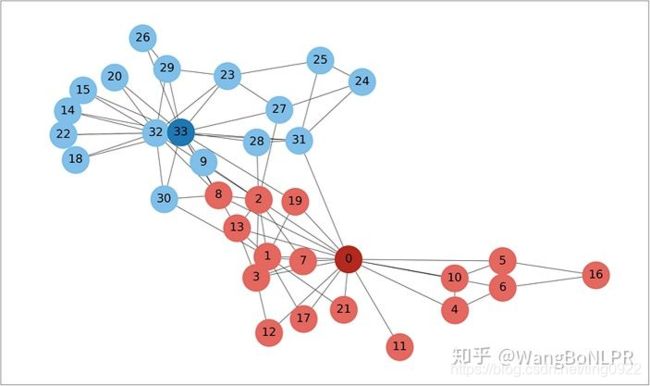
下图展示了层数不同的GCN对节点进行表示的结果,只有一成的GCN还无法将节点较好地划分,两层为最佳层数,之后,随着层数增加,节点又变得不可分。

这样的内在特性使得GCN网络不会太深,导致标签无法有效地传播。因此,GCN在few labeled data上表现不佳。
除此之外,self-supervised learning可以使用数据集本身的信息来构造伪标签,因此,可以对few labeled data进行增强。
基于以上两点,作者想要利用self-supervised learning对数据进行增强,并且设计一种基于GCN的高效训练算法。
具体方法
作者提出Multi-Stage Self-Supervised Learning (M3S)算法,算法流程图如下:
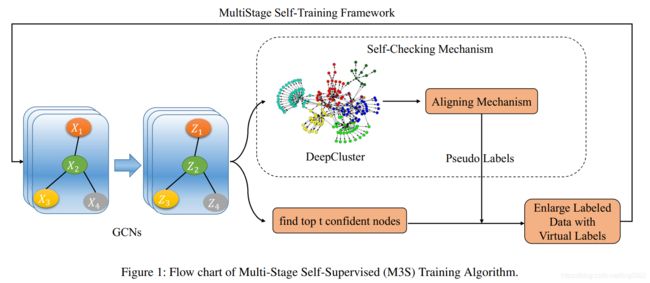
M3S可以分为两个部分:
-
Multi-Stage Training

-
DeepCluster + Alignment
DeepCluster是将节点划分到k个cluster
Alignment是将cluster和真正作为标签的class进行对齐。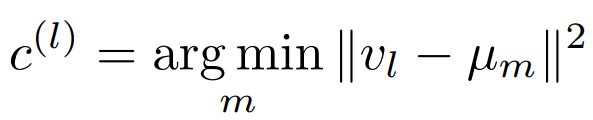
M3S训练的完整过程:
- GCN学习节点表示
- 利用DeepCluster将节点划分为k个cluster
- 对于每个cluster,计算cluster的中心表示;对于每个class,计算每个class的中心表示;通过计算cluster和每个class的距离,确定cluster中未标注节点的pseudo label。
- 选择每个类别中置信度最高的节点,进行self-checking,通过的节点则加入labeled set。
- 再执行下一个阶段的训练。

3. GPT-GNN: Generative Pre-training of Graph Neural Networks
KDD 2020
Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, Yizhou Sun
University of California, Microsoft Research
Key words: self-supervised attributed graph generation (attribute generation, edge generation)
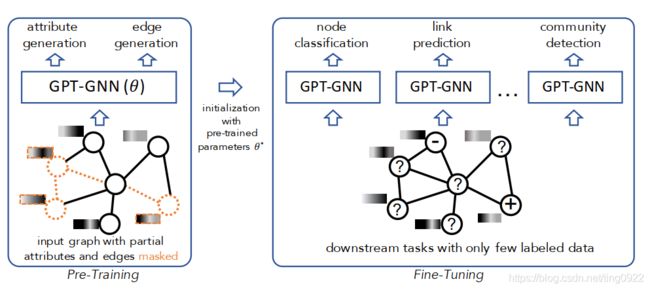
本文主要是为了解决GNN在few labeled data上的学习问题。
受到自然语言处理中通过预训练模型,然后迁移到少标签样本数据上的启发,这里要做一个GNN的预训练。
预训练的任务是self-supervised attributed graph generation,包括两个具体的任务,分别是attribute generation和edge generation。
4. Pre-training Graph Neural Networks for Generic Structural Feature Extraction
arxiv 2020
Ziniu Hu, Changjun Fan, Ting Chen, Kai-Wei Chang, Yizhou Sun
University of California
keywords: self-supervised pre-training tasks, 3 levels of graph structures, graph corpus generation
Motivation
训练GNN往往需要大量有标签的图数据,但是在很多场景中,有标签的数据极少,并且较难进行人工标注。受到自然语言处理中预训练方法的启发,作者提出了一个预训练的框架,希望能够获取一般性的图结构信息,这种信息可以比较容易地迁移到下游任务上去。
图的结构信息是包含多个层次的,比如:节点层次,边层次,子图层次。而目前的GNN预训练模型往往只针对其中一种结构层次进行预训练,导致泛化效果不佳。为了获取多层次的图结构信息,作者提出了三个预训练任务。
具体方法
从预训练语料、预训练框架、预训练任务三个方面进行介绍。
- 预训练语料
这里使用的预训练语料不是真实场景下的图数据,而是由DCBM算法生成的图数据。该算法生成图数据的步骤是:首先设定有K个cluster,每个节点随机分配到一个cluster。然后遵循cluster内的节点连接多于cluster外的节点连接的原则,将节点连边(这个过程也会对节点的度数有一定的限制,比如:节点度数的分布满足power-law或者uniform)
所以,可以通过控制参数,生成多样的图结构,如下图:

最终,为了预训练GNN,生成了900个图作为训练集,124个图作为验证集,节点的个数在100-2000范围内。
- 预训练框架
GNN预训练框架如下:
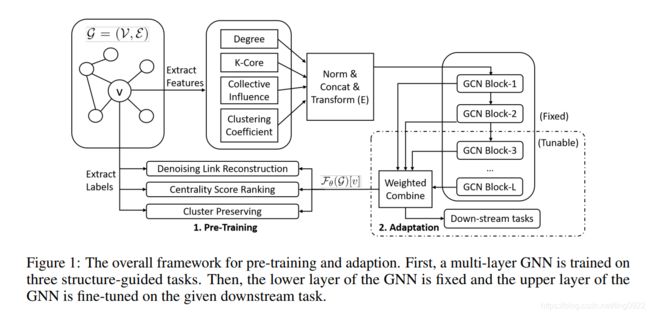
在预训练阶段,输入是给定的图,提取图中节点的四方面特征(degree, Core-Number, Collective Influence, Clustering Coefficient),经过归一化后进行拼接,然后输入到一个非线性转换器E,得到节点的初始向量表示。将这个向量表示作为GNN的输入,输出基于GNN计算得来的向量表示。最后根据三个自监督的预训练任务更新模型的参数。
在进行下游任务时,将GNN模型中的部分层固定,其他层根据下游任务进行微调。
- 预训练任务
1)Denoising Link Reconstruction (Edge-level)
将图中的一部分边移除,然后训练GNN网络,预测两个节点之间是否存在边连接。

2)Centrality Score Ranking (Node-level)
根据GNN生成的节点表示,预测两个节点的centrality相对排序,与真实的节点centrality比较,最小化损失。
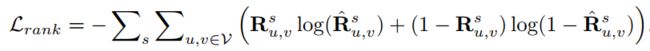
3)Clustering Preserving (Subgraph-level)
给定一个节点,通过GNN生成的节点表示,预测该节点属于的cluster,与真实的节点所属cluster进行比较,最小化损失。
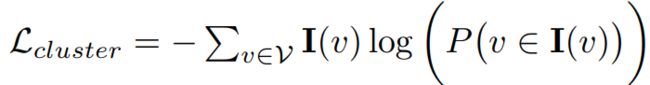
分析
创新点:
- 为3-level graph structural information 设计了三个对应的预训练任务
- 使用生成的数据作为预训练语料,可以控制数据的多样性
不足:
- 生成的数据中,节点的初始表示依赖于节点在图结构中的位置,没有节点本身的语义特征,一些下游任务中,节点本身的语义特征较为重要。
- 第三个预训练任务,优化目标中未包含负样本。
5. Graph-BERT: Only Attention is Needed for Learning Graph Representation
arxiv 2020
Jiawei Zhang, Haopeng Zhang, Congying Xia, Li Sun
Florida State University, University of Illinois at Chicago, Beijing University
Keywords: linkless subgraph batching, Graph-BERT architecture
本文关注GNN学习节点表示中存在的三个问题:
- suspended animation problem
- over-smoothing problem
- hard to parallel computation for large-sized graph
前两个问题是说当GNN的层数增加,图表示性能反而会下降。这是因为GNN本身的特性(在之前的[Li, Han, and Wu 2018]论文中有原理的解释)。第三个问题是说节点之间的内在互连性质,导致并行性不佳,并且对于无法放入内存的大规模图,处理起来就更加麻烦。
基于这三个问题,作者做了两点改进:
- 模型输入形式的改进:与之前图表示模型将整个图作为输入不同,这里是将一个完整的图,划分为由每个节点组成的子图,这些子图组成batch,输入到模型中,学习节点的表示。这样可以达到高效学习节点表示的效果。
- 预训练模型架构的改进:将GNN架构改为基于BERT的Graph-BERT架构,这样可以设计深层的网络结构,并且模型的并行效率高。
模型架构图如下:
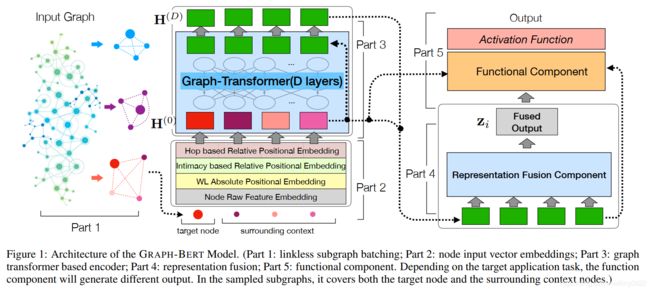
上图中主要包含五个部分,分别为:
-
linkless subgraph batching
这个部分是想要从原本的完整图中采样子图,然后输入模型。采样子图的方式可以参考[Zhang et al. 2018]中的方法。但是这里采用的是top-k intimacy sampling方法。
这个方法的具体做法是:首先根据Pagerank算法计算出节点之间的亲密度S(i, j)。对于每一个节点,根据亲密度排序,选出与该节点top-k亲密度的节点,作为该节点的上下文节点,组成子图,这个子图是由k+1个节点组成,这些节点直接没有边连接。 -
node input vector embedding
这里采用了四种方式的embedding,得到embedding之后进行加和操作,然后作为Graph-Transformer的初始输入。 -
graph transformer based encoder
这个部分就是将上面学到的初始表示输入到模型中,得到每一层的表示。 -
representation fusion
-
functional component
预训练任务有两个:
- Node Raw Attribute Reconstruction
经过Graph-BERT得到的节点表示为z_i,通过一个全连接层和激活函数的作用,希望能还原到节点的初始表示。

优化的损失函数为:
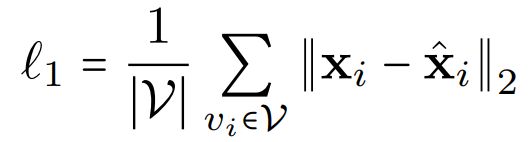
- Graph Structure Recovery
根据Graph-BERT中学到的节点表示,预测节点之间是否有边连接,与真实的节点之间亲密度进行比较。
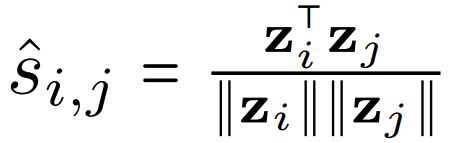
优化的损失函数为:
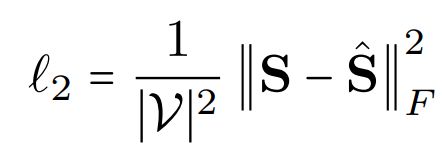
下游任务有两个:
- node classification
- graph clustering
实验设置上,通过以下几个方面进行了效果的验证:
- 预训练时模型的收敛速度,说明预训练模型可以很快收敛
- 在模型层数增加时,模型在下游任务上的表现。说明Graph-BERT在层数增加时,不会出现GNN网络中常见的那两个问题。
- Graph-BERT模型和其他baseline在下游任务上的表现对比。说明Graph-BERT比其他baseline方法好【但这里的提升较小】
- subgraph size k 对于模型在下游任务上的表现和总的时间消耗的影响
- 不同的graph residual对于模型在下游任务上的表现的影响
- 不同的初始化节点表示对于Graph-BERT性能的影响,说明raw feature embedding效果最大,整合四种表示形式,达到最优效果。
- 有预训练和没有预训练,下游任务的表现。【这里没有预训练的情况也是直接用的Graph-Bert的网络架构】
- 两个预训练任务对于模型性能的影响。
一点思考
- 输入模型的是subgraph,并行化效率提升,会不会造成语义稀疏性的问题?
- graph data: node in graphs are orderless
image/text data: pixel/words have their inferent order
那么,对于既有顺序,又有跨顺序连接的情况该如何处理?
6. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
KDD 2020
Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding
Tsinghua University, Microsoft Research, Renming University, DAMO Academy
Key words: graph-based contrastive pre-training, GNN, subgraph ( positive / negative instance ) construction
目前的大多数图表示模型在特定领域的特定数据集上进行学习,无法迁移到其他数据集。而受到自然语言处理和图像处理领域的预训练模型的启发,本文想要做的就是graph-based pre-training。
而做graph-based pre-training的一个重要问题是:how to design the pre-training tasks such that the universal strcutural patterns in and across networks can be captured and further transferred?
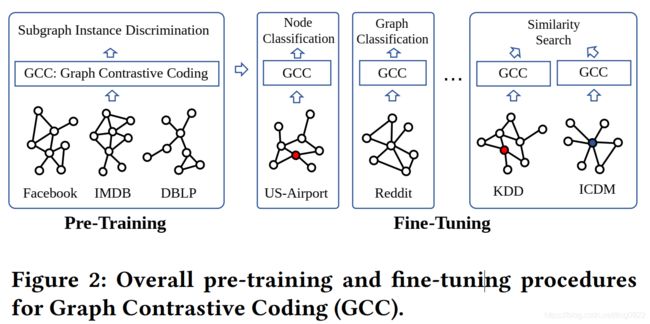
**本文借用contrastive learning 的思想设计graph pre-training任务,叫做subgraph instance discrimination。**而要做对比学习,就要确定三个问题,分别是:1. 怎样确定subgraph instance,也就是确定样本的格式;2. 怎样定义相近的和不相近的instance pair,也就是设计正负样本;3. 怎样对子图进行编码?也就是encoder的架构。
这三个问题的解答是:1. 给定一个中心节点,其 r-ego network中的节点构成的图成为该中心节点导出的子图。这里的r-ego类似r-hop的概念,但计算的是其他节点与中心节点的最短路径;2. 定义相同的 r-ego network 中采样出来的子图是相近的,相反不同 r-ego network中采样出来的子图是不相近的;3. 使用GIN做为graph encoder。
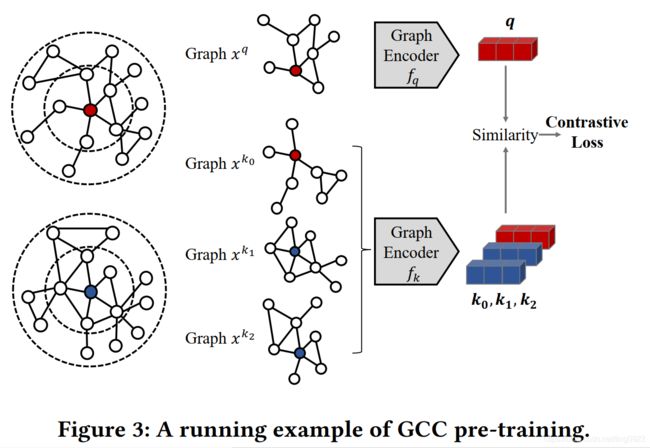
如上图所示,最左边的两个图结构分别是红色中心节点和蓝色中心节点导出的 2-ego network,中间的4个 graph都是根据 2-ego network采样出来的子图。前两个是在第一个 2-ego network中采样出来的,后两个是从第二个 2-ego network中采样出来的。其中第一个子图作为query graph,通过graph encoder学习每个子图的表示。然后根据InfoNCE loss最小化 graph q和 k0的距离,最大化graph q 和 k1以及 k2的距离。
考虑到计算资源的限制,这里使用到End-to-End和MoCO机制,来构建和维护词典。【这里不太理解其含义】
预训练的语料是Facebook, IMDB, DBLP graphs。
一点思考
- 文中提到GCC关注的是structural similarity, orthogonal to neighborhood similarity(代表性的有Deepwalk, LINE, node2vec等)
为什么不能两方面的相似性都关注呢?
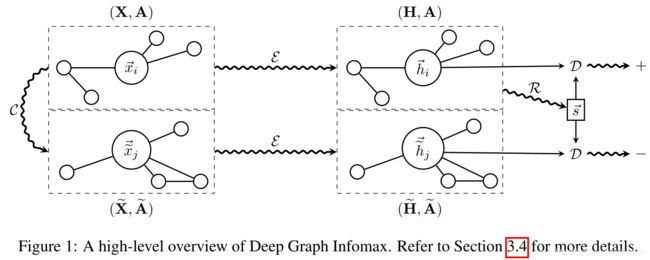
7. Deep Graph InfoMax
ICLR 2019
Petar Velickovic, William Fedus, William L. Hamilton, Pietro Lio, Yoshua Bengio, R Devon Hjelm
University of Cambridge, Google Brain, McGill University
Keywords: Mutual information maximization, context-instance(node representation - entire graph summarization representation)
code
本文是第一个将mutual information maximization应用到图结构数据上,无监督地学习节点表示的工作,简称为DGI。主要是通过最大化local-global(node - entire graph)的互信息。
要利用互信息最大化,需要定义正负样本。这里的样本是节点表示和整个图表示的pair,节点表示是通过encoder学习得到的,整个图的表示是通过readout将图中所有节点的表示综合成一个表示。
-
正样本
( h i , s h_i, s hi,s) pair
其中 h i h_i hi表示节点 v i v_i vi的表示, s s s表示该节点所在的整个图的表示。
利用一个判别器: D : R F × R F → R D: R^F \times R^F \rightarrow R D:RF×RF→R计算节点表示和图表示的匹配程度。比如 D ( h i , s ) D(h_i, s) D(hi,s) represents the probability scores assigned to this patch-summary pair. -
负样本
( h i ′ , s h_i', s hi′,s) pair
其中 h i ′ h_i' hi′表示非正样本的图中的节点表示, s s s仍然为正样本中的整个图的表示。
对于输入包含多个图的场景,可以选择其他图中的节点表示作为 h i ′ h_i' hi′。但本文设定的场景时输入仅包含一个图(也就是 (X, A) as input),所以这里用到了corruption function C : R N ∗ F × R N ∗ N → R M ∗ F × R M ∗ M C: R^{N * F} \times R^{N * N} \rightarrow R^{M * F} \times R^{M * M} C:RN∗F×RN∗N→RM∗F×RM∗M,将原图转换为另一个图,然后选择其中的节点表示作为 h i ′ h_i' hi′。 -
损失函数
利用交叉熵的思想列出损失函数
DGI模型的执行步骤为:

模型整体架构如下: