论文笔记 | code summarization(代码表示学习)系列
代码摘要生成论文列表
-
- 1. Recommendations for Datasets for Source Code Summarization
- 2. Abridging Source Code
- 3. Summarizing Source Code Using a Neural Attention Model
- 4. Code Generation as a Dual Task of Code Summarization
- 5. A Transformer-based Approach for Source Code Summarization
- 6. PYMT5: multi-mode translation of natural language and PYTHON code with transformers
- 7. Improved Code Summarization via a Graph Neural Network
- 8. Deep code comment generation
- 9. Summarizing Source Code with Transferred API Knowledge
- 10. A neural model for generating natural language summaries of program subroutines
- 11. Structured Neural Summarization
- 12. CoCoGUM: Contextual Code Summarization with Multi-Relational GNN on UMLs
- 13. Improving Automatic Source Code Summarization via Deep Reinforcement Learning
- 14. Improved Automatic Summarization of Subroutines via Attention to File Context
- 15. Autofolding for source code summarization
- 16. A parallel corpus of Python functions and documentation strings for automated code documentation and code generation
- 17. A Convolutional Attention Network for Extreme Summarization of Source Code
- 18. Automatic Source Code summarization with extended Tree-LSTM
- 19. Commit Message Generation for Source Code Changes
- 20. Automatic Generation of Text Descriptive Comments for Code Blocks
- 21. TranS: A Transformer-based framework for unifying code summarization and code search
- 22. Automatic Code sunmmarization: A systematic literature review
- 23. Reinforcement-Learning-Guided source code summarization using hierarchical attention
- 24. Fret: Functional Reinforced Transformer with BERT for code summarization
- 25. DeepSum - Deep Code Summarization using Neural Transformer Architecture
1. Recommendations for Datasets for Source Code Summarization
NAACL 2019
A. LeClair, C. McMillan
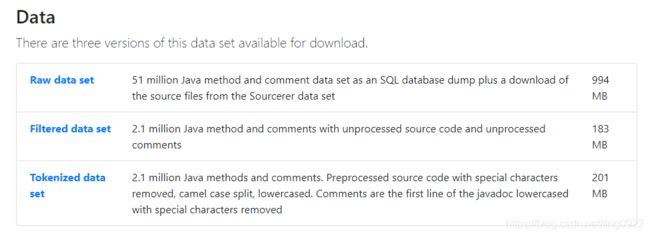
这篇文章最大的贡献是提供了一个code summarization的数据集(仅包含Java语言的代码和英文的comments)FunCom (A java function and comment parallel corpus)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jlfa7GkX-1611020510022)(en-resource://database/1632:1)]
在论文中,还提出并回答了两个问题:
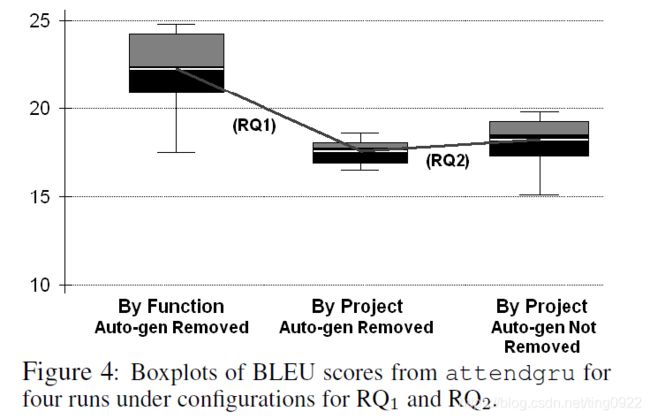
- What is the effect of splitting by method versus splitting by project?
提出这个问题是因为,一些工作按照method划分,划分成80%的训练集,10%的验证集,10%的测试集。但是这样就存在一个问题,就是一个project中的不同method可能被分到了训练集和测试集中,也就是说训练集和测试集中包含了similar vocabulary 和 code patterns。
这里的按照project划分的意思,应该是一个project中的所有method都划分到一个集合中,比如都在训练集中,或者都在测试集中。但是训练和测试的数据格式是和以method划分时候是一样的,都是(method, comment) pair。 - What is the effect of removing automatically generated Java methods?
提出这个问题是因为,Java中自动生成的代码是非常常见的,可能会出现训练集和测试集中都生成了相似的代码的情况。
文中验证了这两种不同的情况下,一个经典的NMT的表现的区别。下图纵轴是BLEU,可以看出,第一列和第二列回答的是第一个问题,发现通过function划分比通过project划分的BLEU值要大,也就是因为通过function划分时,训练集和测试集会有一些的重叠,导致性能更好。第二列和第三列的比较回答了第二个问题,发现在去掉自动生成的代码时,BLEU值下降。
除了以上两个问题,文中还说明了code 和 natural language之间的区别,比如:code中的词频比较集中,不像是自然语言中的长尾问题那么严重。还有两种语言中的词共现。
如果我用这个数据集来做实验,需要关注的是:
- 文中提供的dataset的规模与其他的code summarization的数据集规模对比,质量对比,有什么比较好的地方吗?
-
ICML 2016, A Convolutional Attention Network for Extreme Summarization of Source Code. 其中的数据集是自己收集的,从github上找到了最受欢迎的11个Java projects。数据集和代码
-
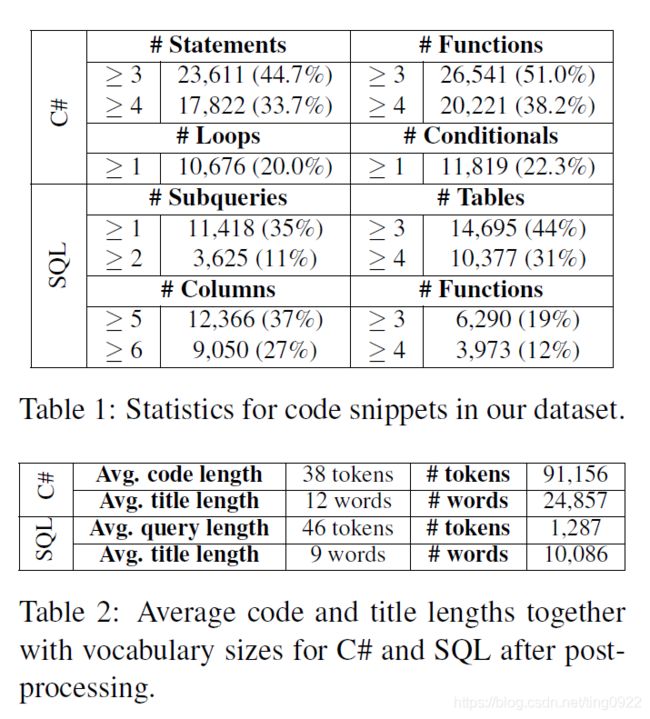
ACL 2016, Summarizing Source Code using a Neural Attention Model. 其中的数据集是从StackOverflow上收集的,其中包含C#和sql的代码,数据集的统计信息如下:

数据集(看着像是每年都在更新的,最新的版本是2020年的) -
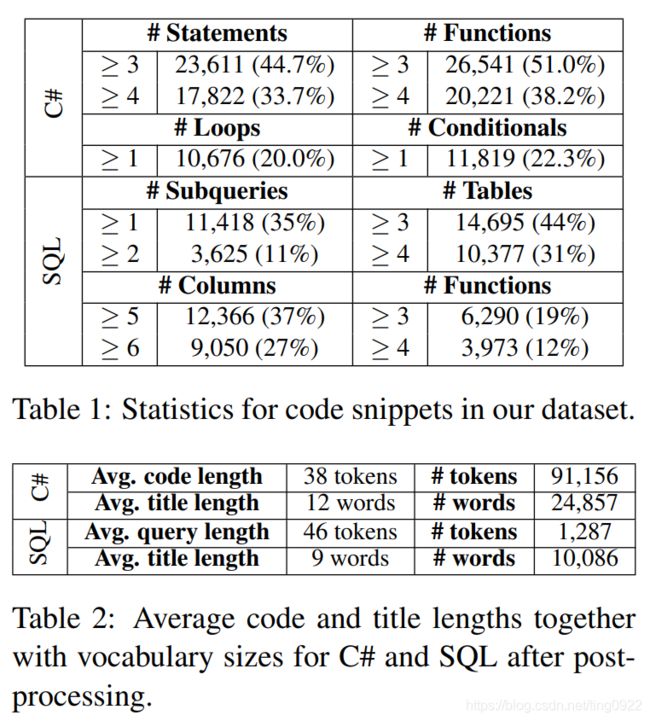
ASE 2018, Improving Automatic Source Code Summarization via Deep Reinforcement Learning. 其中用到的数据集是由另一篇文章贡献出来的(A parallel corpus of python functions and documentation strings for automated code documentation and code generation)。其中包含108726个python语言的code-comment pair,vocabulary size of code and comment is 50400 and 31350.
-
TSE 2017, Autofolding for Source Code Summarization. 其中用到的数据集是在github上收集的受欢迎的6个Java projects.
-
目前有什么工作用了这个数据集来做研究吗?
目前看到有5个工作引用了这篇论文,用了这个数据集来做BLEU的测试,但是这五篇论文的作者都有A. LeClair,也就是他们团队自己在做关于这个数据集的研究。
对比的baseline方法也是类似的,比如:attendgru, ast-attendgru, transformer, graph2seq, code2seq. -
code search (codeSearchNet)和本文中的code summarization数据集有什么区别?
2. Abridging Source Code
OOPSLA 2017, CCF A (软件工程领域)
Binhang Yuan, Vijayarghaven Murali, Christopher Jermaine
Rice University, USA
这篇文章做的是代码的删减,作者认为代码的删减对于读者理解一段代码来说是有作用的,对于一个方法而言,删减不那么重要的部分,留下方法的主要部分,有利于读者快速并且有效的了解这个方法的功能。
文章将source code abridgement任务建模成整数规划的问题,也是一个约束优化问题,需要满足的条件是根据语法和语义特征设计的。
目标函数为:
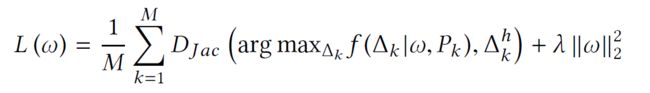
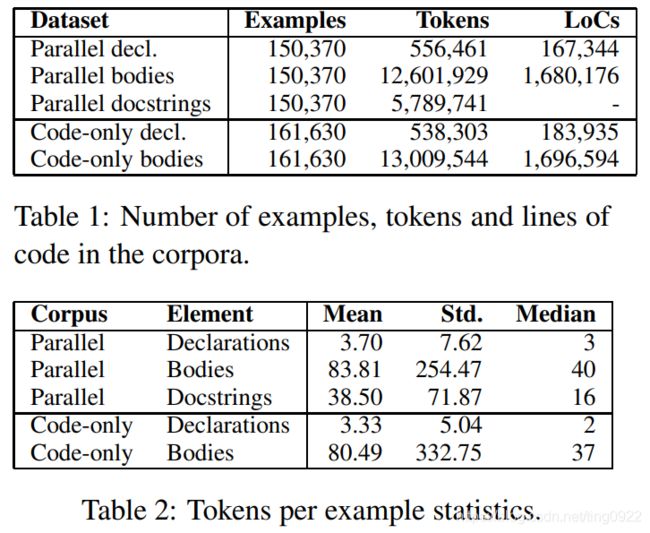
其中的delta_k表示第k个代码删减后的statement表示,f measures the quality of the alignment,w相当于重要性向量,是随机初始化,并在训练过程中学习的。delta_k^h表示专家标注的删减数据。(训练集中包括70个Java方法)
在评估这个方法的有效性方面,这里用到的不是人为标注的数据进行评估,而是对23个研究生进行了测试。测试过程中,设计了两个任务,第一个任务是search problem,每一个题目会提供一个自然语言的描述,还包括5个候选Java methods,需要测试者选出与自然语言描述最相关的Java method。共有8个题目,包括2个热身题目,也就是任务1共需要准备(6+2) * 5= 40个代码。第二个任务是match problem,每个题目会提供两个自然语言描述,还有两个Java methods,需要测试者将自然语言和Java method进行匹配。共11个题目,包括2个热身题目,也就是任务2共需要准备(9+2) * 2=22个代码。每个任务中的Java method都有三部分组成,一部分是原始的代码,一部分是由一个很简单的方法删除50%代码后的代码,另一部分是由本文提出的整数规划方法删除50%代码后的代码。
任务2的系统截图
最终,得到的实验结果是:
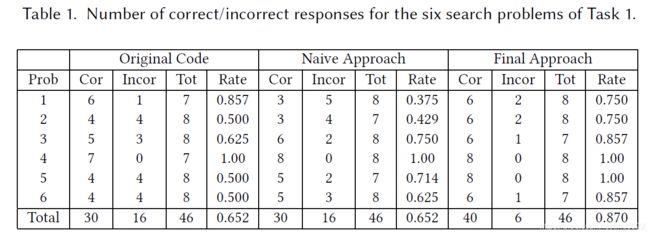


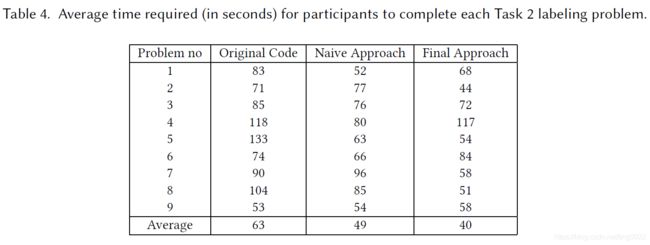
以上结果可以看出,由本文提出的方法删减代码,读者做这些任务的准确率有了提升,并且在花费时间上也有提升。所以说明这个方法删减代码是对于程序员理解代码有用的。
3. Summarizing Source Code Using a Neural Attention Model
ACL 2016
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, Luke Zettlemoyer
University of Washington
data and code
这篇文章做的是code summary,为了减轻人工写summary的负担,本文提出一个完全数据驱动的code summary生成的模型,叫做CODE-NN。该模型的基本架构是LSTM with attention。本文的贡献点在于:
- 提出了一个数据驱动的模型CODE-NN,在code summarization和code retrieval两个任务上取得了sota的结果。
- 贡献了一个code summary的数据集,该数据集是从StackOverflow上收集的,并经过一系列清洗等处理,最终的数据集规模如下图。
CODE-NN模型部分:
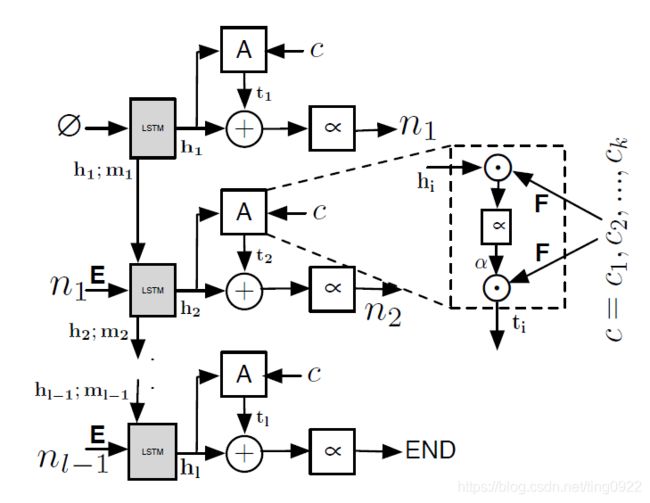
上图是根据代码生成自然语言summary的过程,模型使用的是LSTM,最开始输入LSTM的是NULL,接着根据代码c和当前LSTM输出的隐状态向量计算attention,得到attention之后,形成新的表示向量,softmax得到该时刻应该输出的自然语言的token,再将该token作为下一时刻的输入,重复以上过程,直至输出END。
模型包含两个主要的部分,一个是LSTM学习自然语言token基于上下文的表示,一个是attention。
在实验部分,对于code summary的任务,比较的baseline方法是:
- IR: An information retrieval baseline that outputs the title associated with the code c_j in the training set that is closest to the input code c in terms of token Levenshtein distance.
- MOSES (2007): A popular phrase-based machine translation system.
- SUM-NN (2015): A neural attention-based abstractive summarization model.
评价指标包括:
- METEOR
- BLEU-4
- Human Evaluation
对于code retrieval任务,比较的baseline方法是:
- RET-IR: An information retrieval baseline
评价指标包括:
- MRR
4. Code Generation as a Dual Task of Code Summarization
code
NIPS 2019
Bolin Wei, Ge Li, Xin Xia, Zhiyi Fu, Zhi Jin
Peking University, Monash University
2020.11.6
可用:数据集、dual task的思想和训练方式
这篇文章最大的创新点在于将code summarization和code generation作为dual task,而不是将他们作为单独的任务,单独训练。作者认为 the attention weights from the two models should be as similar as possible because they both reflect the similarity between the token at one end to the token at the other end.

两个网络都是seq2seq架构,encoder是bi-SLTM,decoder是LSTM with attention。每个网络都有自己的参数,并且在训练过程中,计算各自参数的梯度,然后完成参数的更新。其中联合训练的部分是 l d u a l l_{dual} ldual和 l a t t n l_{attn} lattn。

在实验评估部分,本文用到了两个数据集,一个是[Hu et al. 2018b]中的Java dataset,一个是[Wan et al. 2018]中的Python dataset。这两个数据集的统计信息是:
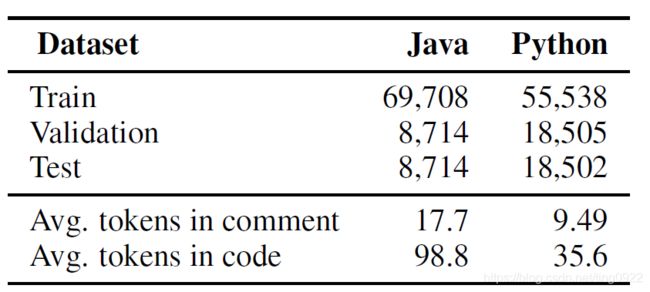
实验评估的结果是:

5. A Transformer-based Approach for Source Code Summarization
code
ACL 2020
Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang
University of California, Columbia University
2020.11.6
可用:Structure-based Traversal technique(Hu et al. 2018) 一种遍历AST形成sequence的方法
这篇文章基本无创新点,主要是作者认为RNN-based code summary方法存在两个问题:
- 代码的结构信息无法获取
- long-range dependencies
所以基于第二个问题,作者使用Transformer学习代码表示,用到了相对位置编码。并且在实验中验证了相对位置编码对于提升性能是有帮助的。
在3.2部分,也提到了基于AST结构的表示,使用到的是Hu et al. 2018提出的Structure-based Traversal technique,将AST表示为序列,然后也是用相同的网络进行表示。
在实验评估部分,本文用到了两个数据集,一个是[Hu et al. 2018b]中的Java dataset,一个是[Wan et al. 2018]中的Python dataset。
6. PYMT5: multi-mode translation of natural language and PYTHON code with transformers
EMNLP 2020
Colin B. Clement, Dawn Drain, Jonathan Timcheck, Alexey Svyatkovshiy, Neel Sundaresan
Microsoft Cloud and AI, Stanford University
2020.11.8
可用:python语言中比codesearchNet更大的平行语料(python代码和其各类的注释,包括一行的注释,带有参数返回值的注释等),预训练的方式(借鉴text-to-text transfer Transformer(Raffel et al. 2019)的思想,进行了auto-encoder pre-training,在大量语料下学习了一个预训练的模型,用于下游任务,训练时间较长)
本文主要有两个贡献点:
- 提出了一个multi-mode PYTHON method text-to-text transfer transformer model PYMT5。这里的multi-mode指的是signatures, docstrings, code bodies等,在预训练的时候。
- 在python
- 将method generation(通过自然语言描述生成一个方法的代码)和 code summarization(docstring generation)作为dual task,联合训练。
以下为两个任务的例子:
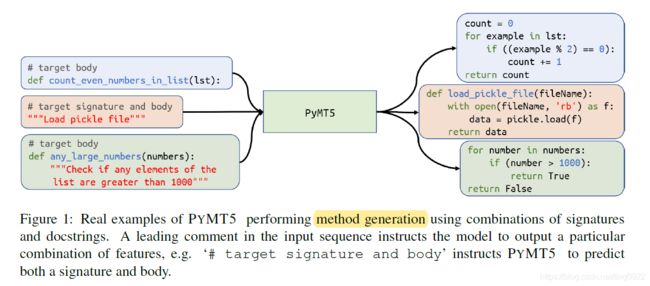

7. Improved Code Summarization via a Graph Neural Network
ICPC 2020
Alexander LeClair, Sakib Haque, Lingfei Wu, Collin McMillan
University of Notre Dame, IBM Research
2020.11.9
可用:GNN的四种分类,ConvGNN处理AST,文中列出的相关工作可以继续看下去
作者认为,其他的code summary工作,有的是关注于获取代码的结构信息,也就是考虑代码的AST结构,有的是在模型方面做改进,比如使用GNN来学习代码的表示。但是没有工作考虑GNN对于AST进行建模,所以这里主要是使用ConvGNN对AST进行建模,学习代码结构信息的表示。
作者提到,code summary 和传统的NMT的区别在于:
- code is longer than summary
- code is not merely a sequence of words
对于第二个区别,作者使用了AST结构信息,但是第一个区别,好像没有具体的解决方法。
文中列出的相关工作包括:
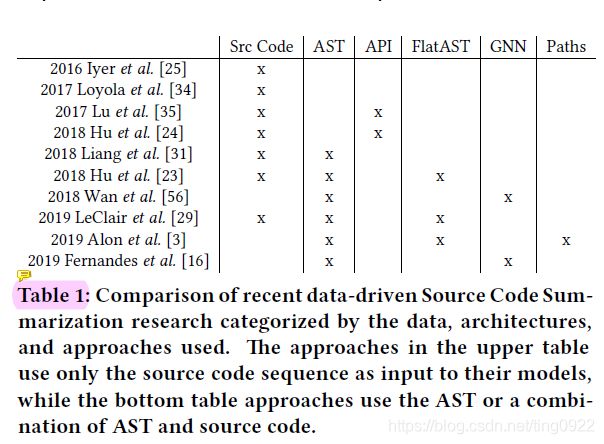
使用到了code sequence和AST,分别学习code token和AST node token的embedding,然后code sequence利用recurrent layer处理,AST nodes and edges用ConvGNN来处理。
在实验部分,使用到的数据集是《Recommendations for Datasets for source code summarization》中提出的2.1 million Java method 和自然语言描述。
baseline包括:
- ast-attendgru
- graph2seq
- code2vec
- BiLSTM + GNN
8. Deep code comment generation
ICPC 2018
Xing Hu, Ge Li, Xin Xia, David Lo, Zhi Jin
Peking Univerisity, Monash University, Singapore Management University
2020.11.10
可用:SBT(一种可逆的AST遍历为sequence的方式),OOV问题的解决方式
data
本文主要解决两个问题:
-
源代码的结构问题:其他利用代码结构信息的工作基本是将AST按照先序遍历得到sequence,然后利用序列模型学习表示。但是这种先序遍历的方式得到的序列无法还原到原来的AST,也就是不同的AST可能会生成同样的序列。所以作者提出了一个SBT,基于结构的遍历方式,得出的序列可以还原AST,并且方便找到节点的同级节点、父节点和子节点(但是这一点这里没有用到,只是将AST转换为序列)
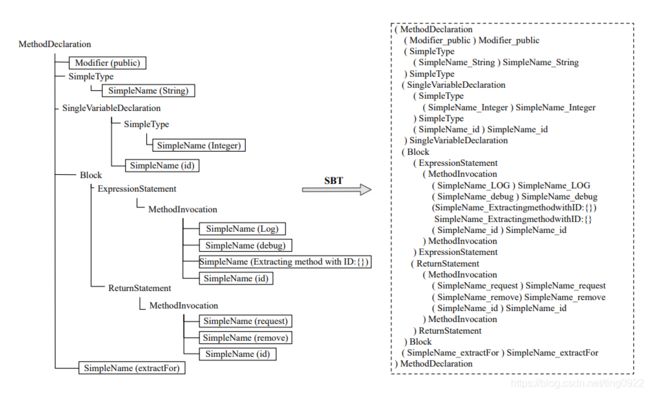
-
代码vocabulary(OOV问题):作者认为如果使用自然语言的词典,那么代码中出现的很多token都没有在这样的词典中出现,按照通常的方法,就是讲这些没有出现过的token表示为,但是这样代码表示中就会出现大量的,不利于表示代码。本文的解决方法是:对于那些没有出现在vocabulary中的终结节点token,用它们的type进行初始表示(也就是value的表示不予考虑)。
实验中用到的数据集是作者通过Github收集的,收集到69708个
baseline包括一个code summary的工作CODE-NN,还有两个自然语言生成的工作Seq2Seq,Attention-based Seq2Seq。
9. Summarizing Source Code with Transferred API Knowledge
IJCAI 2018
Xing Hu, Ge Li, Xin Xia, David Lo, Shuai Lu, Zhi Jin
Peking University, Monash University, Singapore Management University
data and code
这篇文章做的主要是将API sequence summarization knowledge 迁移到 code sumarization任务上。模型架构如下:
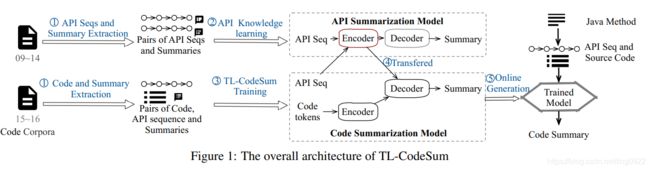
10. A neural model for generating natural language summaries of program subroutines
ICSE 2019
Alexander LeClair, Siyuan Jiang, Collin MaMillan
University of Notre Dama, Eastern Michigan University
2020.11.11
data and code 目前不可访问
作者提出模型ast-attendgru,使用的attention-based encoder-decoder架构。在表示代码方面,使用了代码的token sequence和代码的结构AST,并且这两个部分分别进行encode,架构图如下:
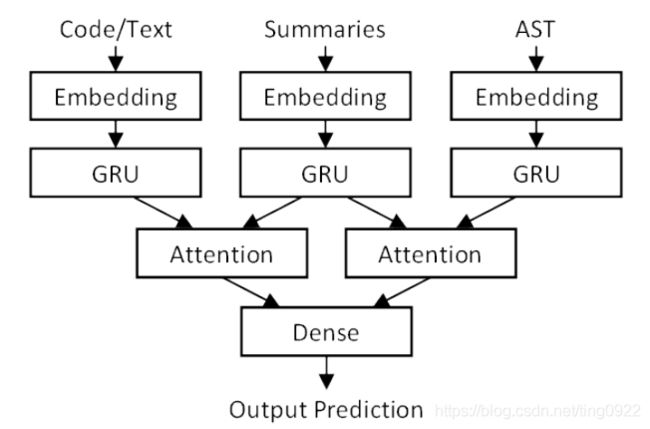
数据集:自己收集的Java method 语料,51 million Java method form 50000 projects,经过处理后得到大约2.1m methods。
baselines:
- attendgru
- SBT (ICPC 18)
- CODE-NN (Iyer 19)
11. Structured Neural Summarization
ICLR 2019
Patrick Fernandes, Miltiadis Allamanis, Marc Brockschmidt
Unbabel, Microsoft Research
2020.11.11
可用:
data and code
sequence embedding
结合sequence representation和GNN,首先使用RNN得到token representation,再将得到的向量表示作为GNN中节点的初始表示。
sequence GNNs: novel combination of GGNN and standard sequence encoders.
12. CoCoGUM: Contextual Code Summarization with Multi-Relational GNN on UMLs
arxiv 2020
Yanlin Wang, Lun Du, Ensheng Shi, Yuxuan Hu, Shi Han, Dongmei Zhang
Microsoft Research Asia, Xi’an Jiaotong University, Beijing Unversity of Technology
2020.11.11
可用:除了code sequence 和 AST之外可以用来提升表示性能的元素:class name, UML;multi-relational GNN
【这品文章的立意部分,说面向对象的语言的特征,使得他们想到要利用border context的想法,我没有看懂】
这里主要的想法是,很多其他工作用的是code sequence 和 AST来表示。这里引入了除此之外的其他表示形式,如class name和UML。
13. Improving Automatic Source Code Summarization via Deep Reinforcement Learning
ASE 2018
Yao Wan, Zhou Zhao, Min Yang, Guandong Xu, Haochao Ying, Jian Wu, Philip S. Yu
Zhejiang University, Chinese Academy of Sciences, University of Technology Sydney, University of Illinois at Chicago
2020.11.12
可用:两个研究问题(结构信息、exposure bias问题)
作者认为现有的code summary基本是基于encoder-decoder架构的方法,面临两个问题
- 代码的结构信息没有充分利用
- exposure bias问题:传统的decoder部分,一般采用teacher forcing的方式进行训练,但是在训练的时候没有groundtruth,并且训练时的评价指标和测试时的评价指标不同。
针对以上两个问题,作者的解决方案是:
- 结构问题:结合code sequence和AST,利用LSTM学习code sequence的表示,利用AST-based LSTM(tree-LSTM)学习AST的表示。再通过hybrid attention融合这两类的表示。
- exposure bias问题:作者采用Actor-Critic方法,Actor每一步选择一个当前状态下最适合的token,Critic网络评估Action的价值,并且以BLEU为指标。

数据集:论文 A parallel corpus of python functions and documentation strings for automated code documentation and code generation中提供的数据集。
数据集中包含108726个code-comment pairs,vacabulary size of code and comment is 50400 and 31350。
baselines:
- Seq2Seq
- Seq2Seq + Attn
- Seq2Seq + Attn + DRL
- Tree2Seq
- Tree2Seq + Attn
- Tree2Seq + Attn + DRL
- Hybrid2Seq
- Hybrid2Seq + Attn
- Hybrid2Seq + Attn + DRL
14. Improved Automatic Summarization of Subroutines via Attention to File Context
MSR 2020
Sakib Haque, ALexander LeClair, Lingfei Wu, Collin McMillan
University od Notre Dame, IBM Research
2020.11.13
可用:file context (不仅考虑一个method本身,还考虑它的上下文code file);AST的三种处理方式
本文最大的贡献点在于:在对一个method进行表示的时候,作者认为如果仅仅利用该method本身的信息,是不足以充分表示这个方法的,有时候还需要结合这个方法的上下文(这个方法所在的文件中的其他方法)。
模型架构是encdoer-decoder,在encoder部分,除了code和AST,还增加了file context,架构图如下:

AST的三种处理方式是:
- flatten the tree to a sequence
- AST paths
- graph-NN处理AST
baseline包括:
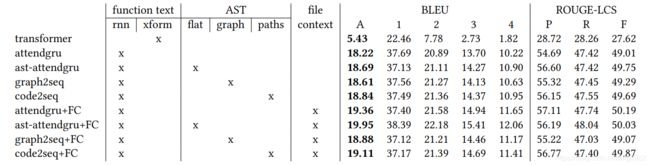
15. Autofolding for source code summarization
TSE 2017
Jaroslav Fowkes, Pankajan Chanthirasegaran, Razvan Ranca, Miltiadis Allamanis,…
University of Edinburgh
2020.11.13
通过autofolding理解代码
our work is based on the idea that an effective summary can be obtained by carefully folding the original file —— summarization code with code
16. A parallel corpus of Python functions and documentation strings for automated code documentation and code generation
IJCNLP 2017
Antonio Valerio Miceli Barone, Rico Sennrich
The University of Edinburgh
2020.11.13
可用:数据集(python 2.7 code)

17. A Convolutional Attention Network for Extreme Summarization of Source Code
ICML 2016
Miltiadis Allamanis, Hao Peng, Charles Sutton
University of Ednburgh, Peking University
2020.11.13
作者认为很多领域都存在平移不变特征,所以使用CNN来学习表示。
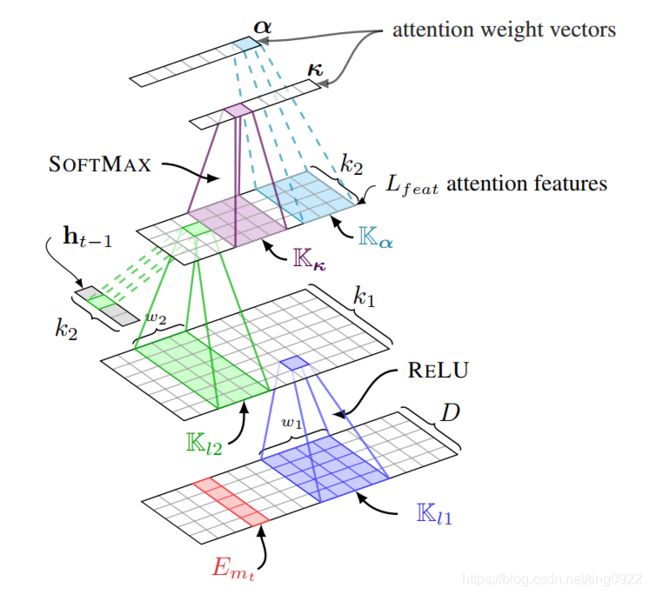
18. Automatic Source Code summarization with extended Tree-LSTM
IJCNN 2019 (CCF C 2021-1-15截稿)
Yusuke Shido, Yasuaki Kobayashi, Akihiro Yamamoto, Atsushi Miyamoto, Tadayuki Matsumura
Kyoto University, Center for Exploratory Research
2020.11.13
可用:两种Tree-LSTM, extended Tree-LSTM
作者认为由于自然语言和代码的区别,现有的NMT不能直接用于code summarization任务。尽管有的工作考虑了代码的结构信息,即AST,但是Tree-LSTM不能处理节点有任意数量有序子节点的AST。
所以作者提出 extension of Tree-LSTM,叫做Multi-way Tree-LSTM架构。
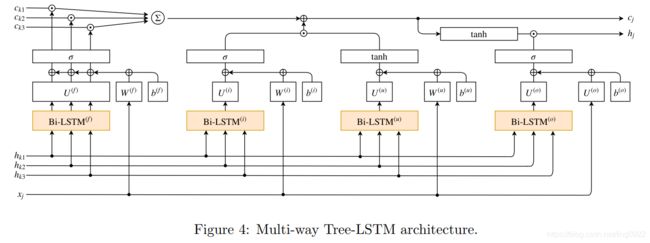
作者提到,Tai et al. [24] proposed 2 kinds of Tree-LSTMs: Child-sum Tree-LSTM, N-ary Tree-LSTM

19. Commit Message Generation for Source Code Changes
IJCAI 2019
Shengbin Xu, Yuan Yao, Feng Xu, Tianxiao Gu, Hanghang Tong, Jian Lu
Nanjing University, Alibaba G
20. Automatic Generation of Text Descriptive Comments for Code Blocks
AAAI 2018
Yuding Liang, Kenny Q. Zhu
Shanghai Jiao Tong University
2020.11.16
可用:AST处理方式Code-Recursive NN;代码生成模型code-GRU;两个评估任务(按功能的代码分类,代码摘要生成);subword和缩略词补全
data and code
本文做的任务是代码摘要生成,按照encoder-decoder架构,该任务可以划分为两个部分,encoder部分是学习代码的表示,decoder部分是根据代码表示生成自然语言的代码摘要。
作者认为之前的方法有两点不足:
- 基于模板的方法不够灵活
- 基于RNN进行encode的方法,缺失代码的结构信息
基于以上两点不足,作者提出一种自动生成代码摘要的模型,该模型的encoder部分叫做Code-Recursive NN,能够获取代码的结构信息(与Tree-LSTM不同的是:可以处理一个节点有多个子节点的情况,而不需要将AST转换为二叉树);decoder部分叫做Code-GRU,是对传统GRU的第一个门控网络进行了改进,使其更突出code block vector的重要性。
Encoder: Code-RNN
Code-RNN有两种实现方式:

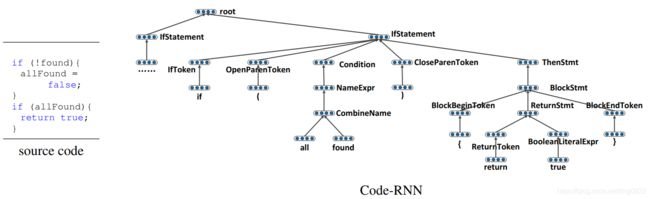
Decoder: Code-GRU
作者认为:We can not feed the code block representation vector to the Recurrent NN cell directly(不懂为什么Code-RNN生成的向量不能直接让RNN-decoder处理)
所以就提出一种GRU的变体(图4),每一个Code-GRU单元如图5所示。其中第一个sigmod部分与一般的GRU有区别,目的在于加强code block vector的影响。


Evaluation
作者在两个任务上对模型进行了评估,对应Code-RNN和Code-GRU:
- 代码分类任务(按照功能分类的数据集,6个类):验证Code-RNN学习代码表示的效果
- 代码摘要生成任务:验证Code-RNN的代码表示和Code-GRU的生成效果
文中针对token的sub-word划分,还有对于那些缩写的token进行的补全可以参考。
21. TranS: A Transformer-based framework for unifying code summarization and code search
arxiv 2020
Wenhua Wang, Yuqun Zhang, Zhengran Zeng, Gudong Xu
Southern University of Science and Technology, University of Technology Sydney
2020.11.17
可用:code summarization和code search任务的相互促进,actor-critic网络的应用
本文主要做了两个任务,一个是code summarization,一个是code search。在code summarization任务中,使用了actor-critic架构,actor网络主要是根据当前状态生成token,critic主要是评估生成的效果。
总体的模型架构如下:
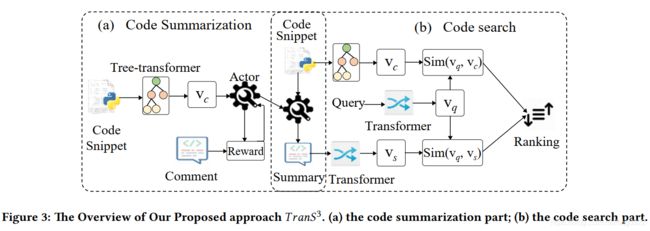
在对自然语言,代码变量,查询进行表示时,用到的是transformer;在对代码进行表示时,用到的是Tree-transformer。但是这里的tree并不是AST,而是根据代码缩进来建立关系的树,节点是代码的语句,同样缩进的语句是同级节点,不同缩进的语句可以是父亲节点/子节点。
下图的代码构造出来的树为:


得到树之后,通过后序遍历,得到序列,再输入Transformer,得到代码段的表示。
使用的是Python数据集。
22. Automatic Code sunmmarization: A systematic literature review
arxiv 2019
Yuxiang Zhu, Minxue Pan
Nanjing University
2020.11.18
可用:代码摘要生成的搜索关键词
这篇综述整理了41篇code summarization论文,内容包括:数据获取、模型和评价指标等。时间轴是2010年1月到2019年1月,但是其中2016年以前的工作占到大半。
各研究工作根据数据获取、模型和评价指标划分的分类体系:
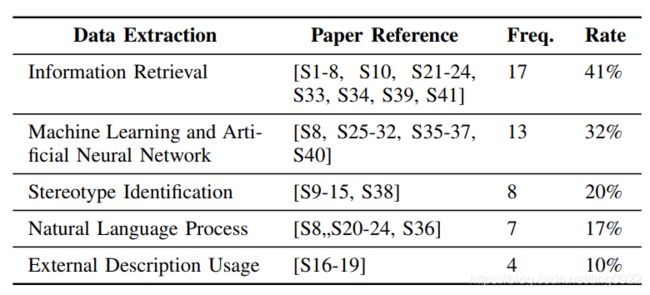
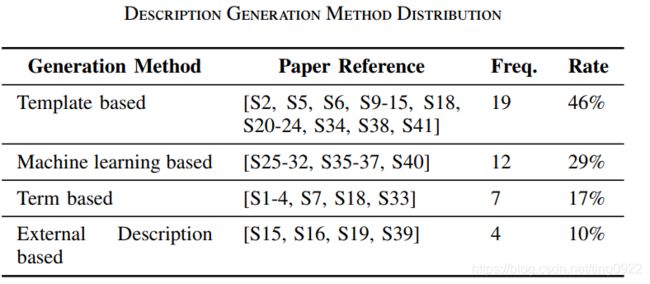

所有41篇论文的情况,在文中列出了一张表:
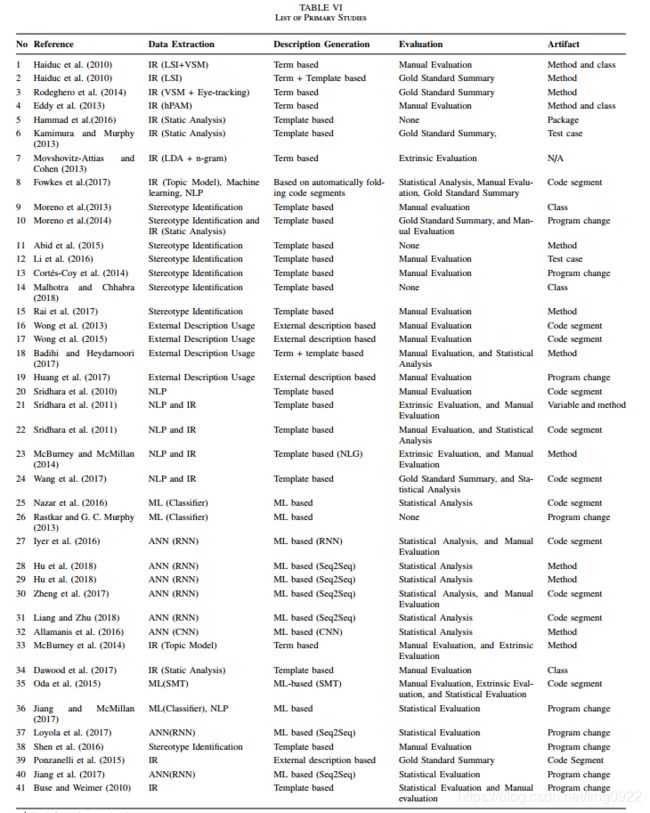
代码摘要生成的搜索关键词:
- code summmarization
- summarize code
- code mining
- automatic document source code
- comment generation
- summarizing source code change
23. Reinforcement-Learning-Guided source code summarization using hierarchical attention
arxiv 2019
Wenhua Wang, Yuqun Zhang, Yulei Sui, Yao Wan, Zhou Zhao, Jian Wu, Philip S. Yu, Guandong Xu
University of Technology, Sydney, Southern University of Science and Technology
2020.11.19
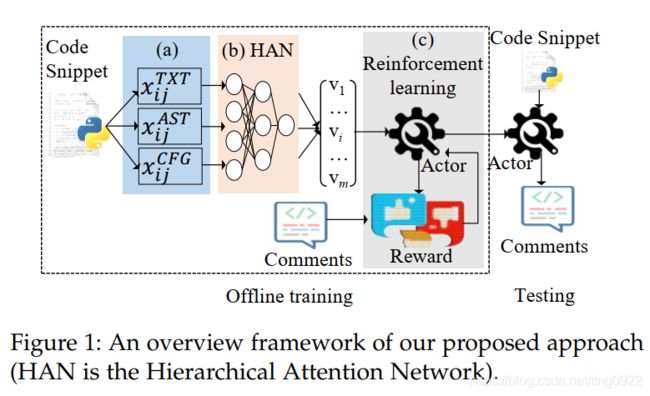
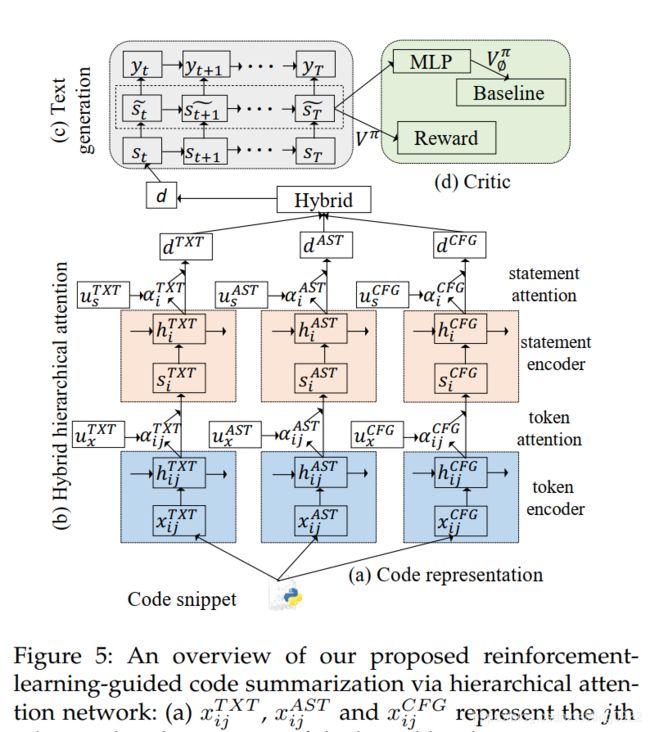
可用:AST和CFG的使用,层次attention
无代码
作者认为目前基于encoder-decoder的工作存在三个局限:
- most of the existing approaches input code as a plain texts that are composed of tokens directly without considering the code hierarchy
意思是忽略了代码的层次关系,这里的层次关系指的是function由statement组成,statement由token组成 - utilize simple sequential features
意思是大部分方法仅考虑代码序列,忽略代码的结构信息,如:AST、CFG等 - exposure bias
针对以上三个问题,作者提出:
- 在代码表示方面,利用三方面的信息,分别是:纯文本、AST、CFG(文中有个例子非常好的说明了为什么要用这三种表示)
- 在代码层次方面,作者提出hybrid attention,认为不同的token和statement对于code summarization来说重要性是不同的
- 利用actor-critic网络解决exposure bias问题
24. Fret: Functional Reinforced Transformer with BERT for code summarization
IEEE Access 2020
Ruyun Wang, Hanwen Zhang, Guoliang Lu, Lei LYU, Chen LYU
Shandong Normal University, Shandong University
2020.11.20
可用:functional reinforcer提取代码中最关键的token
作者认为目前主流的方法存在以下三个缺陷:
- Limitation by the long dependency problem
代码长度通常比摘要长,怎样获取长距离依赖的确是个需要解决的问题 - Lack of effective guidance
这个不太明白指的是什么 - Lack of code understanding
作者的意思是现有方法很多在机械地进行单词映射,缺乏对于代码的深层理解,性能遇到瓶颈。
作者提出Fret (Functional REinforced Transformer with BERT),针对以上三个问题,具体的解决方案是:
- encoder中对代码进行表示的部分是Transformer的encoder,这样就可以解决长距离依赖的问题
- 但transformer并不是为代码所设计的,所以不能有效的获取代码的结构信息。所以作者设计了一个structure encoding的算法。和Bert结合,能做到深度理解代码和结构。
- 提出了一个functionality-reinforced source code representation method,其中的functional reinforcer被用来提取代码中最关键的token。
这里说到的structure encoding的设计比较简单,就是根据statement的层次,确定权重。

functional reinforcer的具体做法没有给出,但这一点很有意思,把代码段中重要的token提取出来。

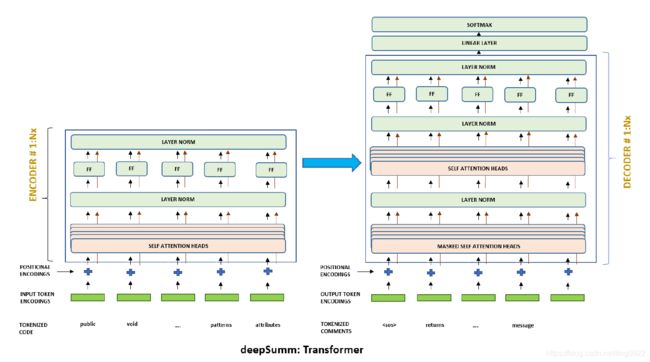
25. DeepSum - Deep Code Summarization using Neural Transformer Architecture
模型架构是encoder-decoder,其中用到的是Transformer。架构图如下: