| 版本 |
说明 |
发布日期 |
| 1.0 |
发布文章第一版 |
2020-11-20 |
文章目录
- 前言
- 初识集合
-
- 泛型——盘古开天
-
- 基本概念
-
- 泛型接口、泛型类
-
- 泛型方法
- 泛型通配符——烧脑!稳住,我们能懂!
-
- Collection家族
-
- Collection
-
- List
-
- ArrayList
-
- LinkedList
-
- Vector(矢量)
- Stack(栈)
- Queue(队列)
-
- Set
-
- HashSet
- TreeSet
-
- LinkedHashSet
- 迭代器
-
- 常用方法
- 并发修改异常(ConcurrentModificationException)
- foreach循环
- Map家族
-
- 常用方法
- 常用实现类
-
- HashMap
-
- TreeMap
- LinkedHashMap
- Hashtable
- Properties
- Collections!这是一个类!
-
前言
- 这篇文章不是面面俱到的基础知识集合,只是我个人的学习笔记。学习资料来源于《拉勾教育Java就业急训营》。
- 这篇文章只是对集合的一个比较浅显的学习,对底层原理的探究较少,主要侧重于如何使用。
- 这一篇是由我自己复习Java过程中,总结而得。所以内容不一定能够深刻见底,也不一定完全正确。希望小伙伴们能以辩证的眼光研读~也希望大家多多讨论!
- 如果想完整阅读这个系列的文章,欢迎关注我的专栏《Java基础系列文章》~
初识集合
集合的作用
- 集合的作用是什么呢?我们来看一看我们想存储数据时,通常采用何种方式?
- 记录单个数据内容:声明一个变量;
- 记录多个类型相同的数据内容:声明一个数组;
- 记录多个类型不同的数据内容:创建一个对象。
- 记录多个类型相同的对象数据:创建一个对象数组。
- 那么问题来了。如果我们想记录多个类型不同的对象数据或者数据内容时,或者想对类似于数组这样的结构,进行更灵活的操作,咋整呢?用之前提到的方法都行不通了。所以集合驾着七彩祥云来了~
集合大家族
- 众所周知,集合有两个大分支:java.util.Collection和java.util.Map。
- Collection存储单个元素。俗称单身狗。
- Map存储一对儿元素。俗称小情侣。
- 他们手下又有很多小弟,部分小弟如下图:

泛型——盘古开天
基本概念
盘了个古但还没开天的时候
- java 1.5之前,还没有泛型这个东西,这个时候,集合的参数还都是Object类型。
- 这个Object类型吧,虽然让集合可以存放不同类型的元素,但是也产生了一个问题。
- 很多时候,虽然使用了集合,但其实我并不想存储多种类型的数据(比如既存Integer,又存String)。我只想存String类型。结果发现:
- 我取数据的时候,还必须要类型强转(因为存储的类型是Object,接收返回值的类型是String)。
- 强转麻烦不说,还容易出错。
- 为了不出错,还必须翻前面的代码,来看看它里面存的是啥类型的数据。
- 如果这些代码是自己一个人写的还OK,如果是别人写的…只需要想象一下,就能感受到人外有人,坑外有坑。很有画面感!
- 举个极端点的例子:如果不使用泛型,Stack的push形参是Object类型。所以要真搞成如下这样,一运行肯定就出问题了。
public class GenericityTest {
public static void main(String[] args) {
Stack co = new Stack();
co.push(1);
co.push("11");
System.out.println("========隔了亿点点代码======");
Integer a = (Integer)co.pop();
Integer b = (Integer)co.pop();
}
}
后来的后来
- Java 1.5带来了泛!型!
- 泛型其实可以理解成“类型的参数”,这个参数不是数据内容,而是引用数据类型。定义了泛型之后,就可以在后面使用这个类型。
- 这样一来,虽然不能放不同类型了,但是再也不用强转了,不用担心报错了。
- 先简单地眼熟一下泛型,这个<引用数据类型>,就是泛型的表现形式:
public class GenericityTest {
public static void main(String[] args) {
Stack<Integer> co = new Stack<>();
co.push(1);
System.out.println("========隔了亿点点代码======");
Integer a = co.pop();
}
}
注意事项
- java 1.7之前,泛型在实例化的时候,必须完整写出
new Stack()。java 1.7之后,就可以如上例那样简写成new Stack<>()。
- 一种泛型的引用不能指向另一种泛型的实例。也就是下面的代码在编译阶段是会报错的:
Stack<Integer> co = new Stack<>();
Stack<String> coco = new Stack<>();
coco = co;
泛型接口、泛型类
声明和使用
- 其实泛型接口和泛型类是一回事儿,总之就是在类名后面增加了类型参数列表,实现了泛型机制。这里直接通过下面的例子来讲解:
public class GenericPerson<Gender> {
private String name;
private Gender gender;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Gender getGender() {
return gender;
}
public void setGender(Gender gender) {
this.gender = gender;
}
}
public class GenericityTest {
public static void main(String[] args) {
GenericPerson per1 = new GenericPerson();
GenericPerson<String> per2 = new GenericPerson<>();
GenericPerson<Boolean> per3 = new GenericPerson<>();
per1.setGender("男");
per1.setGender(per2);
per2.setGender("女");
per3.setGender(true);
}
}
- 其中泛型的名字只需要符合Java命名规范即可,但是通常情况下泛型命名都采用单词首字母大写,例如E、T等。
- 如果没有指定泛型的类型,则泛型会被当作Object类型。
继承、实现中的泛型
public class SubGenericPerson<E> extends GenericPerson<String> implements GenericAnimal<Double>
{
@Override
public void run(Double aDouble) {
}
}
- 对于不保留泛型的子类,子类在实例化时无需指定泛型类型。而其父类的泛型在子类的声明中已经指定且固定了。
- 对于保留泛型的情况,子类可以重新给父类的泛型取个名字,但父类的泛型还是一一对应的。此时子类在实例化的时候,需要指明泛型类型,指定的泛型类型会同时被子类和父类使用。接口也是同理。
- 此外,不管保不保留父类的泛型,子类都可以自己再定义新的泛型。
- 下面举个例子感受一下:
public class GenericPerson<Gender> {
private String name;
private Gender gender;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Gender getGender() {
return gender;
}
public void setGender(Gender gender) {
this.gender = gender;
}
}
public interface GenericAnimal<Kind> {
void run(Kind kind);
}
public class SubGenericPerson<T, E> extends GenericPerson<T> implements GenericAnimal<T> {
@Override
public void run(T o) {
System.out.println("Running way is " + o.toString());
}
public void show(E e) {
System.out.println("show " + e.toString());
}
}
public class GenericityTest {
public static void main(String[] args) {
SubGenericPerson<String, Double> per = new SubGenericPerson<>();
per.run("用腿");
per.show(123.0);
per.setGender("男");
System.out.println(per.getGender());
}
}
Running way is 用腿
show 123.0
男
泛型方法
- 泛型方法就是输入的参数是泛型参数,而不是具体的参数。我们在调用这个泛型方法的时需要对泛型参数进行实例化。
- 需要注意的是,这个“泛型参数”并不同于声明类时定义的“泛型”。因为类层级的泛型,在实例化的时候,类型就确定了,所以在方法传参的时候已经是具体的参数了。
- 泛型方法的格式:
[访问权限] <泛型> 返回值类型 方法名([泛型标识 参数名称]) {}
- 静态方法使用泛型时,必须定义为泛型方法。因为类层级的泛型必须在实例化时才能指定类型,而静态方法的调用无需实例化。
- 栗子来了~
public class GenericMethod {
public <T> void genericPrint(T para){
System.out.println(para);
}
}
public class GenericityTest {
public static void main(String[] args) {
GenericMethod test = new GenericMethod();
test.genericPrint("小钰真漂亮!");
test.genericPrint(12);
}
}
小钰真漂亮!
12
泛型通配符——烧脑!稳住,我们能懂!
普通泛型中无法体现继承关系
- 例如有两个类Animal和Dog,其中Dog是Animal子类。此时下列代码是编译错误的:
LinkedList<Dog> test = new LinkedList<Animal>();
- 为了能够在泛型中体现多态,java就引入了通配符的概念。使用了通配符之后,泛型的类型就可以在一定的范围内进行指定了(而不是必须一模一样)。
- 目前泛型通配符有下面三种:
- :无限制通配符。表示可以传入任意类型的参数。该通配符等价于。
- :限定通配符。表示指定类型只能是E或者是E的子类;
- :限定通配符。表示类型只能是E或者是E的父类。
- 这玩意儿单说有点晦涩,直接上栗子吧:
public class Wildcard {
public static void main(String[] args) {
GenericPerson<? extends Animal> per1;
per1 = new GenericPerson<Person>();
per1 = new GenericPerson<Dog>();
per1 = new GenericPerson<>();
Animal gender = per1.getGender();
GenericPerson<? super Person> per2;
per2 = new GenericPerson<Animal>();
per2 = new GenericPerson<Object>();
per2 = new GenericPerson<>();
per2.setGender(new Person());
Object gender1 = per2.getGender();
GenericPerson<Person> per3 = new GenericPerson<>();
per3.setGender(new Person());
per1 = per3;
}
private static class Animal {
}
private static class Person extends Animal {
}
private static class Dog extends Animal {
}
}
- 这个时候就有小伙伴说:你这上了栗子我并不能妨碍我不懂。但是我懂你们不懂,所以我现在就来把你们讲懂~
- 首先需要明确,通配符到底什么意思。
GenericPerson per1;意思是per1实例化的时候,可以指定为Animal以及Animal的子类。也就是我在接下来三行举例的实例化语句。GenericPerson per2;同理,意思是per2实例化的时候,可以指定为Person以及Person的父类。我在下面也例举了三种情况。
- 接下来再来看
? extends Animal。我造你们要问capture of ? extends Animal是什么意思?capture的意思是传入的参数,必须要能够被捕获。而能够被捕获,意思是传入的参数的类型,必须要比泛型指定的类型小(也就是必须要是指定类型的子类)。
- 对于写数据的情况,被我注释掉了,因为会报错。因为实例化的时候,指定的类型可以是Animal的子类。但是Animal的子类可以是Person,也可以是Person的子类,也可以是Person的孙子类…一次类推,可以无限小。所以传入的参数必须要能够被这个无限小的子类捕获,当然这样的类是不存在的。所以这种情况,结果就是无法赋值。
- 对于读数据的情况,因为要capture,而我们知道此时per1最大的情况,就是泛型被指定为了Animal。所以根据自动类型转换规则,我们接泛型的时候,gender只需要是Animal或者Animal的父类,就不会有问题了。
- 我又造有小伙伴不开心了:只能读,不能写,这个通配符岂不是整了个寂寞!诶,不然,且看per3。很简单,我们只需要先把各种数据写好,最后将写好的实例赋值给per1,不就达到了先写后读的需求了么~
- 接下来再看
? super Person。我双造你们要问capture of ? super Person是什么意思。同样的意思,要想捕获,那传入的参数类型,必须比泛型指定的类型小。对没错,还是要更小!捕获,其实意思就是要可以触发自动类型转换!
- 对于写数据的情况,因为per2的实例,指定的类型可能是Person,也可能是Person的父类,所以最小的情况就是Person。那我们只要写入的参数小于等于Person就OK了。所以setGender中可以传入Person的实例,也可以传入Person的子类的实例。
- 对于读数据的情况,因为per2的泛型类型,最大可能是所有类的爸爸——Object。所以,接的数据必须是Object,木有例外。
- 如果还是没懂,建议再看一遍。还不懂,那就从下往上再看一遍~
Collection家族
Collection
基本概念
- 位于java.util.Collection,是一个接口。
- 在类声明的时候同时定义了一个泛型,名字叫E。
- Collection中存储的都是单个元素。所以有一点像是一个高级的数组。
常用方法
增删改查
- Collection的常用方法都很简单,但是还是有几个需要注意一下:
- 小伙伴们要能够区分出来
c1.add(c2);和c1.addAll(c2);的区别;c1.contains(c2);和c1.containsAll(c2);的区别;c1.remove(c2);和c1.removeAll(c2);的区别。
- 对于判断两个元素是否是相同元素的情况,本质上调用的都是对应实例的equals方法。所以对于自定义类,记得重写equals和hashCode方法。
- 对于contains和containsAll方法,和add类型,需要能够区分。
| 方法声明 |
功能 |
| boolean add(E e); |
向集合中添加对象。添加失败返回false。 |
| boolean addAll(Collection c) |
将集合c中的所有元素添加到调用集合中。根据通配符可知,addAll的泛型类型可以是E的子类。任一添加失败返回false。 |
| boolean contains(Object o); |
判断是否包含指定对象。没有则返回false。 |
| boolean containsAll(Collection c) |
判断是否包含指定集合中的所有元素。不全有则返回false。 |
| boolean retainAll(Collection c) |
调用集合和参数集合取交集,结果存放至调用集合,参数集合不发生变化。如果调用集合的元素前后没有发生改变,则返回false。 |
| boolean remove(Object o); |
从集合中删除对象。删除失败(比如没有对应的元素)则返回false。 |
| boolean removeAll(Collection c) |
从集合中删除参数指定的所有对象。任一删除失败则返回false。 |
| void clear(); |
清空集合 |
| int size(); |
返回包含对象的个数 |
| boolean isEmpty(); |
判断是否为空 |
| boolean equals(Object o) |
判断是否相等 |
| int hashCode() |
获取当前集合的哈希码值 |
| Object[] toArray() |
将集合转换为数组(其实是用迭代器实现的) |
| Iterator iterator() |
获取当前集合的迭代器。迭代器的使用方法见下文 |
与数组的转换
- 其实Collection可以通俗地理解成一种高级的数组。
- Collection转为数组,使用
Object[] array = c.toArray();
- 数组转为Collection,使用
Collection c = Arrays.asList(array);
List
- 位于java.util.List,同样是一个接口。
- List的特点在于元素可重复、强调元素间的顺序性。
- 常用方法如下,因为都很简单,就不细说啦~
| 方法声明 |
功能 |
| void add(int index, E element) |
向集合中指定位置添加元素 |
| boolean addAll(int index, Collection c) |
向集合中添加所有元素 |
| E get(int index) |
从集合中获取指定位置元素 |
| int indexOf(Object o) |
查找参数指定的对象第一次出现的索引位置 |
| int lastIndexOf(Object o) |
查找参数指定的对象最后一次出现的索引位置 |
| E set(int index, E element) |
修改指定位置的元素。返回被修改位置的原有元素 |
| E remove(int index) |
删除指定位置的元素,后面的元素自动向前补位。返回被删除的元素。 |
| List subList(int fromIndex, int toIndex) |
获取左闭右开区间的子List。 |
- 需要格外注意!subList获取的子list,和原list共用同一块内存。
ArrayList
- 底层采用动态数组进行数据管理。因此支持下标访问,访问效率高。但增删元素效率较低。
一些底层原理
- ArrayList有两个重要的属性:size:记录当前集合中的元素个数;elementData:存放元素的数组。
- 当调用无参构造时,创建的是一个长度为0的空数组。
- 调用add时的大概逻辑:
- 判断size是否等于elementData的length。如果是,则执行扩容:
- 数组扩容为原length的1.5倍。然后判断扩容后的length与原length+1谁大:
- 如果原length+1更大。则判断10与原length+1谁大,谁大则扩容为对应大小。
- 如果扩容后的length更大,则扩容为扩容后的length(或者扩容为ArrayList支持的最大容量)。
- 放入新元素,size+1。
LinkedList
- 底层采用双向链表进行数据管理。双向链表的特点是访问效率较低,但增删元素效率很高。
一些底层原理
- LinkedList有四个重要的属性:size:记录当前集合中的元素个数;first:记录第一个节点;last:记录最后一个节点;Node:内部类,用于存放节点数据(数值、前节点引用、后节点引用)。
- 无参构造是一个空方法。也就是说此时first和last均为null。
- 至于双向链表的原理,属于数据结构的基础知识,就不在这里赘述啦~
Vector(矢量)
- Vector和ArrayList非常相似,都是使用动态数组维护数据,但是有以下区别:
- Vector是线程安全的,ArrayList是非线程安全的。
- Vector在Java 1.0的时候推出,ArrayList在Java 1.2的时候推出。
- 通常ArrayList自动扩容为1.5倍,而Vector的自动扩容为2倍。
Stack(栈)
- 我们在小学二年级学数据结构的时候,知道了栈是一个先进后出的数据结构。这个Stack也不例外。
- Stack继承了Vector。因为Stack都是对数组尾部进行添加删除,所以不会产生数组补位的额外开销。因此使用数组效率较高。
- 通过push方法推入元素、通过pop方法推出元素、通过peek查看栈顶元素。
- 现在该类基本被Deque接口取代,所以就不详说了。
Queue(队列)
- 位于java.util.Queue。是一个接口。
- 该接口虽然与List平级,但是学过数据结构的小伙伴都知道,Queue是与Stack相对应的。
- Queue也是一种经典的数据结构,特点是数据先进先出,应用场景较多,例如各种排队场景。
- Queue的典型实现类是LinkedList。因为队列会对集合首部和尾部进行大量增删操作,使用数组开销会很大,而双向链表就不会有这种担心。
常用方法
| 方法声明 |
功能 |
| boolean offer(E e) |
将元素添加至队尾,若添加成功则返回true |
| E poll() |
从队首删除并返回一个元素 |
| E peek() |
返回队首的元素,但不删除 |
- 只要大家在小学二年级学好数据结构,这个接口也就没啥不理解的地方了。所以俺也不在这儿赘述了~
Set
- 位于java.util.Set。是一个接口。
- 与List平级,并与其形成对比:
- List强调元素放入的先后顺序,而Set不保证先后顺序(注意,并不是代表Set每次遍历的顺序是随机的)
- List中的元素可以重复,而Set中的元素不能够重复。因此实际开发中,Set常被用于去重。
- 常用方法与Collection接口的方法类似。
HashSet
- 底层采用hashMap来存储元素,将元素值作为hashMap的key值,而value值始终放一个Object对象。他们之间的关系我在下文HashMap中有再次介绍哦~
- HashSet简化版的存储结构(或者说是HashMap的存储结构)和写数据时的处理逻辑如下:

- 这也是为什么重写equals方法就必须重写hashCode方法的原因。这种哈希表算法,可以在小数据量的时候大大提高数据的写入效率。
TreeSet
- 底层采用红黑树来管理数据。红黑树是什么?数据结构,你懂的~
- 红黑树大概的特点是:能始终维持数据的大小顺序,查找效率较高,写入效率不算特别高,但是很稳定。因为其按照大小排序,所以自然也就丢失了数据放入的先后顺序。
比较大小的方式
- 因为TreeSet底层是红黑树,因此写数据的时候需要比较大小。
- TreeSet提供了两种比较大小的方式:
- 自然排序:放入TreeSet的元素实现java.lang.Comparable接口。该接口提供了一个抽象方法
int compareTo(T o)。如果没有指定比较器,则放入TreeSet的元素必须重写该方法,否则写入操作时会抛出ClassCast异常。
- 比较器规则:实例化TreeSet的时候传入传入java.util.Comparator接口的实例。
- 自然排序举例如下。首先定义内部类Person,实现Comparable接口,比较age的大小。然后实例化三个Person
public class TreeSetTest {
private class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age){
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
return this.age - o.age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public static void main(String[] args) {
TreeSetTest test = new TreeSetTest();
Person per1 = test.new Person("小钰", 24);
Person per2 = test.new Person("angel", 23);
Person per3 = test.new Person("姐姐", 24);
Set<Person> set = new TreeSet<>();
set.add(per1);
set.add(per2);
set.add(per3);
System.out.println(set);
}
}
- 运行结果如下。可以看到,元素按照age从小到大的顺序打印,并且对于相等的元素,不会重复添加。
[Person{name='angel', age=23}, Person{name='小钰', age=24}]
- 比较器规则举例如下。我们只需要在上面的例子做一点小小的变动:实例化一个Comparator匿名内部类,同样比较age,但是变成了从大到小排序。在main方法中给TreeSet提供这个比较器,就可以正常使用了。
public class TreeSetTest {
private class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
return this.age - o.age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public static void main(String[] args) {
Comparator<Person> comparator = (o1, o2) -> {
System.out.println("o1是:" + o1 + ",o2是:" + o2);
return o2.age - o1.age;
};
TreeSetTest test = new TreeSetTest();
Person per1 = test.new Person("小钰", 24);
Person per2 = test.new Person("angel", 23);
Person per3 = test.new Person("姐姐", 24);
Set<Person> set = new TreeSet<>(comparator);
set.add(per1);
set.add(per2);
set.add(per3);
System.out.println(set);
}
}
- 运行结果如下。不难发现,在Comparable和Comparator都存在的情况下,Comparator的优先级更高。此外,对于参数o1和o2,可以发现o2是集合中的元素,o1是准备写入的元素。
o1是:Person{name='小钰', age=24},o2是:Person{name='小钰', age=24}
o1是:Person{name='angel', age=23},o2是:Person{name='小钰', age=24}
o1是:Person{name='姐姐', age=24},o2是:Person{name='小钰', age=24}
[Person{name='小钰', age=24}, Person{name='angel', age=23}]
LinkedHashSet
- 继承于HashSet。在其基础上维护了一个双向链表,该链表维护了各个元素放入Set的先后顺序,从而让LinkedHashSet变为了有先后顺序的集合。
迭代器
- 位于java.util.Iterator。
- 迭代器(iterator)就是一种用于遍历元素的工具。其实有点像游标的感觉。
- 迭代器提供了Iterator接口,所有实现了这个接口的类均可与迭代器进行配合。
常用方法
| 方法声明 |
功能介绍 |
| boolean hasNext() |
判断集合中是否有下一个可以迭代的元素 |
| E next() |
取出下一个元素。如果没有下一个元素,会抛出NoSuchElement异常 |
| void remove() |
删除当前位置的元素 |
public class IteratorTest {
public static void main(String[] args) {
ArrayList<String> listPer = new ArrayList<>();
listPer.add("小钰");
listPer.add("angel");
listPer.add("姐姐");
Iterator<? extends String> iterator = listPer.iterator();
while(iterator.hasNext()){
String str = iterator.next();
System.out.println("将要删除" + str);
iterator.remove();
}
}
}
将要删除小钰
将要删除angel
将要删除姐姐
并发修改异常(ConcurrentModificationException)
- 当在执行迭代器迭代的过程中,如果试图更改被迭代对象的数值,将会抛出并发修改异常。这一点在多线程情况下依然适用。
- 但是为了解决迭代过程中不能删除的问题,迭代器本身提供了remove方法。当使用该方法时,将不会抛出此错误。
- 什么叫在迭代过程中呢?其实就是指在hasNext()循环过程中。例如下面这样:
public class IteratorTest {
public static void main(String[] args) {
ArrayList<String> listPer = new ArrayList<>();
listPer.add("小钰");
listPer.add("angel");
listPer.add("姐姐");
Iterator<? extends String> iterator = listPer.iterator();
while(iterator.hasNext()){
iterator.next();
iterator.remove();
}
}
}
foreach循环
- 从java5开始,出现了for循环plus版——foreach。
- 可以用于对实现了Iterator的类或者数组的遍历。对于实现了Iterator接口的类来说,foreach是对迭代器的简化。
- 迭代器语法如下:
for(元素类型 变量名 : 数组/类实例名) {
循环体;
}
- foreach是如何对迭代器进行简化的呢?下面就来对比一下:
public class IteratorTest {
public static void main(String[] args) {
ArrayList<String> listPer = new ArrayList<>();
listPer.add("小钰");
listPer.add("angel");
listPer.add("姐姐");
listPer.add("老刘");
listPer.add("凯哥");
System.out.println("原版迭代方式:");
Iterator<? extends String> iterator = listPer.iterator();
while(iterator.hasNext()){
String str = iterator.next();
System.out.println("下一位小伙伴:" + str);
}
System.out.println("简化后:");
for (String str : listPer) {
System.out.println("下一位小伙伴:" + str);
}
}
}
Map家族
- 位于java.util.Map,是一个接口。
- 在类声明的时候同时定义了两个泛型——K和V。
- K是元素的键值,相当于目录,整个集合中唯一。这也是HashSet保证元素唯一的原因。
- V是元素的值,相当于内容,在集合中可以重复。
- Collection中存储的都是单个元素。所以有一点像是一个高级的数组。
- 在实际开发中,我们通常都是用String作为K。原因如下:
- 因为String的内容不可变,所以String对hashCode有优化:对hashCode的值进行了缓冲,以后用到hashCode时,无需重复计算。
- HashMap存在大量对hashCode方法的调用,此时有缓冲的String可以更得心应手地应对这种情况。
常用方法
| 方法声明 |
功能 |
| V put(K key, V value) |
将Key-Value对存入Map,若集合中已经包含该Key,则替换该Key对应的Value。返回值为该Key原来所对应的Value,若没有则返回null |
| V get(Object key) |
返回参数Key对应的Value对象,如果不存在则返回null |
| boolean containsKey(Object key); |
判断集合中是否包含指定的Key |
| boolean containsValue (Object value); |
判断集合中是否包含指定的Value |
| V remove(Object key) |
根据参数指定的key进行删除。返回该key对应的value,如果不存在则返回null |
- 以下三种方法用于对Map进行遍历。因为Map没有实现Iterator接口,所以需要将key和value转换为Collection,然后使用Iterator进行遍历。
| 方法声明 |
功能 |
| Set keySet() |
将map中所有key放入Set,并返回 |
| Collection values() |
将map中所有value放入Collection,并返回 |
| Set> entrySet() |
将map中所有key和value分别放入Entry,再将Entry放入Set,然后返回。 |
- 有些小伙伴可能不知道这个Entry是啥子东东。这个东东其实是Map的内部接口,主要用来实现对单对KV的存储。有相应的get、set、equals等方法。口说无凭,整个栗子如何?
public class MapTest {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("小钰", 20);
map.put("angel", 23);
map.put("姐姐", 24);
map.put("小钰", 24);
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.print("key is: " + entry.getKey());
System.out.println(". value is: " + entry.getValue());
}
}
}
- 运行结果如下。关于Entry的更多抽象方法,建议大家直接去看Map类的源码。里面关于Entry的源码还是很简单滴~
key is: 小钰. value is: 24
key is: angel. value is: 23
key is: 姐姐. value is: 24
常用实现类
HashMap
- 底层采用哈希表和桶(Bucket)来管理数据。
- 哈希表是什么?这也是数据结构的事情,有兴趣的小伙伴可以去看看数据结构~哈希表的特点是在数据量不是特别大的时候,写入效率、查找效率都很高。但是不能保证数据放入的先后顺序。
- 桶是什么?桶指的是用来存放Node的数据结构,在数据量小的时候,他是个单链表,数据量大的时候,他是个红黑树。
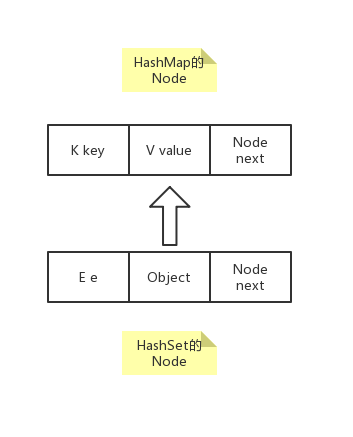
- 前面也说到了,HashSet其实直接使用的HashMap来存储元素。那到底是怎么一回事呢?二者节点(Node)的关系如下图。也就是说,HashSet将元素存放在了key,而value并不被HashSet使用,于是始终存放的是new Object()产生的对象。
一些底层原理
重要成员
- HashMap存放数据的东西是一个内部类:
- Node:该类中有key、value、hash值、指向下一个Node的属性next。
- HashMap中比较重要的成员属性:
- loadFactor:加载因子。作用是作为一个扩容阈值。
- table:哈希表。其本质是一个Node数组。
- size:table当前使用量,记录table当前存放了多少个值。
- HashMap还有一些比较重要的常量:
- DEFAULT_LOAD_FACTOR:加载因子默认值。值为0.75
- DEFAULT_INITIAL_CAPACITY:容量默认值。值为16.
- TREEIFY_THRESHOLD:桶由单链表转红黑树的节点个数临界值,该值为8。
- MIN_TREEIFY_CAPACITY:桶由单链表转红黑树的table容量临界值,该值是64。
HashMap的特点
- 当
loadFactor * table.length > size时,则会执行扩容操作。
- 当执行的是空构造的时候,加载因子设置为DEFAULT_LOAD_FACTOR。之后在第一次执行put时,table长度会设置为DEFAULT_INITIAL_CAPACITY。
- 当一个桶中Node个数达到TREEIFY_THRESHOLD,并且哈希表table的容量达到64。则该单链表会转换为红黑树。而当Node个数小于6时,又会从红黑树转换为单链表。
- 为什么一个是8,一个是6呢?这是为了防止个数在6-8之间摇摆时,导致频繁发生转换。
TreeMap
LinkedHashMap
- 同LinkedHashSet与HashSet的关系。
Hashtable
- 与HashMap相比,Hashtable是线程安全的。此外,Hashtable不允许将null放入key或者value。
Properties
Collections!这是一个类!
- 注意啦!注意啦!这是一个类,一个工具类!他比Collection多了个s哈!
- 位于java.util.Collections。
- 主要提供了对Collection家族进行各种操作的静态方法。
常用方法
| 方法声明 |
功能 |
| static > T max(Collection coll) |
返回集合中的最大元素(根据元素的自然排序) |
| static T max(Collection coll, Comparator comp) |
返回集合中的最大元素(根据比较器排序) |
| static > T min(Collection coll) |
返回集合中的最小元素(根据元素的自然排序) |
| static T min(Collection coll, Comparator comp) |
返回集合中的最小元素(根据比较器排序) |
| static void copy(List dest, List src) |
将src列表中的所有元素复制到dest列表中 |
| static void reverse(List list) |
反转list中元素的顺序 |
| static void shuffle(List list) |
使用默认的随机源随机排序list |
| static > void sort(List list) |
将list升序排序(根据元素的自然排序) |
| static void sort(List list, Comparator c) |
将list升序排序(根据比较器排序) |
| static void swap(List list, int i, int j) |
交换list中下标为i和j的元素 |
- 这些常用方法都很简单,但是对于copy方法,有一点需要强调一下:
public class CollectionsTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(10, 20, 30, 40);
List<Integer> list2 = Arrays.asList(new Integer[10]);
Collections.copy(list2, list);
System.out.println(list2);
}
}
- 上面这段代码中,如果采用被注释的那一行,则会报数组下标越界异常(IndexOutOfBoundsException)。为什么呢?
- copy方法中,在开头会比较两个数组的size。注意,是size,而不是数组的capacity。dest的size必须要大于等于src的size。
- 被注释掉那一行的List构造方法,只是把capacity设置为了10。而因为此时list中没有元素,所以size为0。
- 而下面通过asList实例化,返回的其实是Arrays类里面的一个静态内部类的实例。这个说起来就有点复杂了。但是简而言之,这样返回的呢,size和数组的capacity都是10,所以就能放下了。
- 当然,让size达标的方式有无数种,不一定非得用asList哈~