Neural Attention Model for Abstractive Sentence Summarization
本周开始分享自动文摘相关的paepr,今天分享的一共有两篇。其中一篇是A Neural Attention Model for Abstractive Sentence Summarization,另一篇是Abstractive Sentence Summarization with Attentive Recurrent Neural Networks,两篇文章都出自于Harvard NLP组,两篇是姊妹篇,第二篇是第一篇的升级版,所以要结合着读,对比着分析。
世上没有什么所谓的银弹,每种方法存在都有其存在的意义。第一篇paper尝试将seq2seq+attention应用在summarization任务上,但并未取得比较令人满意的结果,反而增加了一些人工特征之后,才得到了很大的提升,虽然第二篇模型依旧是一个data-driven的模型,但我想如果给其添加上人工特征也会得到更好的效果。综合多种方法的优点来解决一个问题才是王道,而不是一味地、粗暴地套用某个范式,某个框架。
两篇文章从同一个角度入手,采用了不同难度的模型,非常好地解决了这个问题。联想到上周看的paper,他所采用的是多层lstm作为encoder和decoder,但数据集使用的并不相同,所以并不知道与本周的两篇paper哪个效果更好。但这也给出了一种发paper的思路,多去尝试一些encoder和decoder模型,不断地组合和对比,一定会有不错的发现。但这样的解决方案对于提升层次上没有太多溢出,因为大家都是照着模板去做,并没有真正地更深地理解到这个问题的本质。
一个系统的构建需要处理好方方面面的细节,比如数据的预处理,比如评测的实现,比如模型的参数调优,每个方面想要做好做精都是一门学问。
Abstract
Paper 1
本文提出了一种data-driven的方法来做句子摘要,使用了一种基于局部注意力模型(local attention-based model),在给定输入句子的情况下,生成摘要的每个词。模型结构非常简单,可以套用流行的end2end框架来训练,并且很容易扩展到大型训练数据集上。模型在DUC-2004任务中效果优于几个不错的baselines。
Paper 2
本文使用一种conditional RNN来生成摘要,条件是卷积注意力模型(convolutional attention-based encoder),用来确保每一步生成词的时候都可以聚焦到合适的输入上。模型仅仅依赖于学习到的features,并且很容易在大规模数据上进行end2end式地训练,并且在Gigaword语料上和DUC-2004任务中取得了更好的效果。
两篇paper的模型框架都是seq2seq+attention,最大的区别在于选择encoder和decoder的模型,第一篇的模型偏容易一些,第二篇用了rnn来做。seq2seq或者说end2end现在火的不得了,最初在机器翻译开始使用,后面推广到多模态学习,对话生成,自动问答,文本摘要等等诸多领域。
Introduction
文本摘要有几种类型的任务,本文属于headlines generation,输入的是一段话,输出的是一句话或者一个标题。
Paper 1
受最近机器翻译中seq2seq技术的启发,本文将Neural Language Model和带有上下文的encoder结合起来,其中encoder与Bahdanau(Neural machine translation by jointly learning to align and translate)的attention-based encoder一样。encoder和decoder在句子摘要任务中共同训练。另外,decoder中也使用了beam search进行摘要生成。本文的方法简称ABS(Attention-Based Summarization),可以轻易扩展到大规模数据集进行训练,而且可以在任何document-summary对中进行使用。本文采用Gigaword语料集进行训练,包括大约400万篇新闻文章。为了检验模型的效果,与多种类型的文摘系统进行了对比,并且在DUC-2004任务上获得了最高分。
Paper 2
本文的decoder是一个RNN LM,生成摘要依赖的条件是encoder的输出,encoder会计算输入中每个词的分数,这个分数可以理解为对输入作软对齐(soft alignment),也就是说decoder在生成下一个单词时需要注意输入中的哪些单词。encoder和decoder要在一个sentence-summary数据集中进行共同训练。本文的模型可以看作第一篇ABS模型的扩展,ABS模型中decoder是用FNN LM,而本文使用RNN,encoder部分本文更加复杂,将输入单词的位置信息考虑在内,并且使用了卷积网络来编码输入单词。本文模型效果优于第一篇paper。
两篇paper都是seq2seq在sentence-level abstractive summarization任务中早期的尝试,给文本摘要方法带来了新鲜血液,第一篇paper中encoder和decoder都用了比较简单的模型,但已经得到了优于传统方法的结果,再一次地证明了deep learning在解决问题上的优势,第二篇paper升级了encoder和decoder,考虑了更复杂的细节,得到了更好的效果,相信后面会有大量的paper套用seq2seq+attention,再配合一些其他的技术来提升模型的效果,但整体的思路基本已固定下来,如果想要更大的突破,可能还需要提出另外一种框架来解决问题。
Related Work
这部分内容是初入门径的研究者最喜欢的工作,尤其是这个领域中最新研究的paper还没有出survey的情况下,大家想最快地了解这个领域中新技术的应用情况,读高水平paper中的相关工作是最有效的。
Paper 1
文本摘要任务在sentence这个level可以等同于headlines generation,某种程度上与paraphrase相近。seq2seq于2014年在机器翻译领域中提出并流行开来,之前的研究大多都是基于extractive的思路,借助一些人工features来提升效果。seq2seq的意义在于完全基于数据本身,从数据中学习feature出来,并且得到了更好的效果。本文的方法比较简单,decoder也只用了NNLM(2003年由Bengio提出),而seq2seq在机器翻译中应用时都采用的是RNNLM,所以在Future Work中作者会用RNNLM,于是就有了第二篇paper。
Paper 2
由于都是一个组出的paper,还有共同的作者,这个部分写的差不多,只是多提了第一篇paper做的工作。
都说 读书破万卷,下笔如有神。在做一个领域的研究之前,免不了读大量相关的paper来做一些积累,related work这个部分就是大家写的小型survey,经常会提到一些该领域最经典的paper。感觉Rush他们组应该是比较新的NLP研究力量,将一个新的技术用在了自动文摘领域中,攒了两篇paper,也是数量上的一种积累。不过他们share了paper相关的code,用Torch来写模型部分,用python作数据处理。组里也包括那位将CNN用在sentence classification中的Yoon Kim,相信他们日后会有更多更好的成果。
Background
本节是用数学语言定义句子摘要问题,两篇文章解决的问题相同。给定一个输入句子,目标是生成一个压缩版的摘要。句子级别的摘要问题可以定义如下:
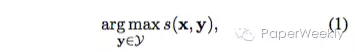
x表示输入句子,y表示生成的摘要句子集合,定义一个系统是abstractive的,就是从生成句子集合中找到score最大的那一个。而extractive摘要系统可以定义如下:
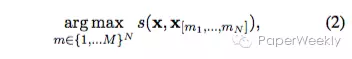
sentence compression系统可以定义如下:
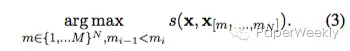
然而abstractive summarization存在一个更加困难的生成过程。
用了一个简单的数学公式将问题描述地非常清楚,包括一些细节,比如输入长度大于输出长度,输出长度为固定值,输入输出拥有相同的词汇表等等。从数学公式来看score函数的定义很重要,考虑的参数类型不同会有不同的score,也就是不同的模型,明显看得出abstractive要远难于extractive和sentence compression。
Model
模型部分是paper的重头戏,分为Objective,Encoder,Decoder,Generation,Training五个子部分来讨论。
Paper 1
Objective
目标函数是Negative Log-Likelihood(NLL),decoder中生成摘要单词的条件是encoder的输出和当前生成词的窗口词向量,具体如下:
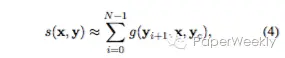
这里当前生成词的窗口词向量由下式表示:
![]()
其实也就是NNLM中的N-gram,用来预测下一个词。目标函数表示为:
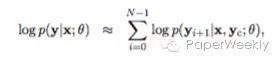
对于i<1的情况,在句子前padding几个开始符号。接下来建模的部分就是研究如何表达条件概率。
目标函数用生成词的条件概率的对数来表示是NLP中非常常用的做法。不同的模型都在研究如何表示条件,比如encoder的表示,encoder输出的表示,decoder中当前词前序词的表示等等。
Encoder
本文一共提出了三种encoder模型。
Bag-of-Words Encoder
词袋模型是最简单的一个模型,将输入的句子用词袋模型降维到H,生成一个word embedding层。模型如下:
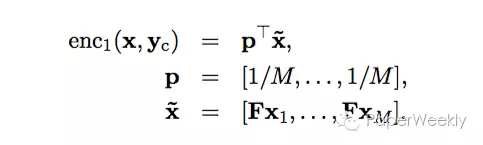
词袋模型并不会考虑词序的关系,效果并不会太好,但是作为paper中的一个baseline模型会有很好的对比结果。
Convolutional Encoder
卷积模型是一个深度网络模型,可以很好地捕捉输入的特征。模型如下:
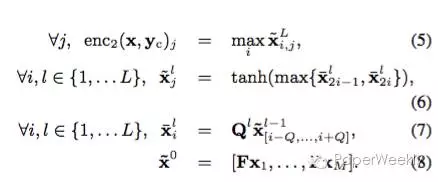
其中矩阵F是输入句子的word embedding矩阵,Q包括了一系列过滤层,并且采用了最大池化技术来处理。
CNN通过结合word embedding将句子表示成一个matrix,通过不同尺寸的卷积核来filter出句子中的feature,本质上和N-gram一样,N-gram的N就是卷积核的尺寸,构建出多种feature maps,然后max pooling,然后filter,然后pooling,最终采用一个MLP得出结果。
Attention-Based Encoder
虽然卷积模型比词袋模型更能捕捉句子的特征,却同样需要对整个句子做表示,机器翻译领域在解决相同问题时采用了注意力模型来构建context,然后基于生成的context来构建representation。本文采用一种类似于词袋模型的注意力模型,模型如下:
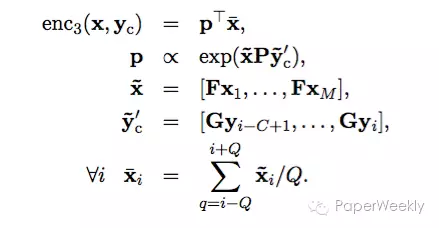
其中矩阵G是context的word embedding矩阵,P是一个权重矩阵,权重连接着输入word embedding和context embedding,Q是一个光滑窗口,流程如下图:

本文的注意力模型可以视作将词袋模型中的P向量用一个待学习的soft alignment来替换了。
三种encoder模型给出了input sentence的表示,第三种还给出了summary和input之间的关系,encoder的输出将作为decoder的输入,来生成summary。
Decoder
decoder的本质就是一个神经网络语言模型,本文用了2003年Bengio提出的NNLM,模型如下:
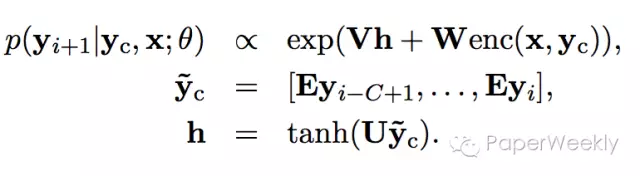
Bengio的模型是一个FNN(Feed-Forward Neural Network),通过上文(当前词的前N个词)来预测当前词,流程如下图:
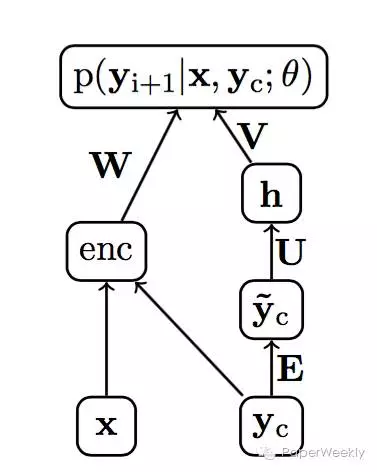
待求的参数是word embedding矩阵E,输入层到隐藏层的权重矩阵U,隐藏层到decoder输出层的权重矩阵V,encoder输出层到decoder输出层的权重矩阵W。
NNLM是一个经典的语言模型,本质上就是一个神经网络多分类器,文中也提到可以考虑用RNNLM来作decoder,也就有了第二篇paper的模型。
Generation
一般的语言模型都是基于上下文生成概率最高的一个词,但对于生成摘要句子来说还不够。通常的做法是用一种搜索算法在一定的可行域之内找到几组可行的解。本文采用beam search,也是之前机器翻译领域生成翻译结果时常用的算法,算法描述如下:

给定一个beam size K,在生成每一个summary word时,都保留概率最大的K个词,从生成第二个词开始,计算所有路径的概率,只保留概率最大的前K个分枝,裁剪掉剩余的分枝,继续生成第三个词,依次进行下去,直到生成的词是EOS或者达到最大句子长度限制。最后得到的结果是K个最好的sentence summary。
Training
本文采用mini batch SGD算法对训练集进行训练,使得NLL最小。
因为在生成summary时并没有什么约束条件,所以本方法可以拓展到任意input-output pairs中使用。
ABS+
作者提出了一个纯数据驱动的模型之后,又提出了一个abstractive与extractive融合的模型,在ABS模型的基础上增加了feature function,修改了score function,也就是结果对比中的ABS+模型。
Paper 2
本文模型简称为RAS(Recurrent Attentive Summarizer)
Objective
目标函数如下:
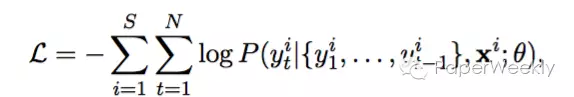
两篇paper都是采用NLL,但不同的是第二篇paper目标函数条件概率中的条件与第一篇不同,本文采用decoder的所有上文,而不是一个窗口内的上文。
Encoder
encoder的输出是decoder的输入,对于每一个time step,encoder都需要给出一个context vector,本文encoder的重点在于如何计算时间相关的context。
输入句子每个词最终的embedding是各词的embedding与各词位置的embedding之和,经过一层卷积处理得到aggregate vector:
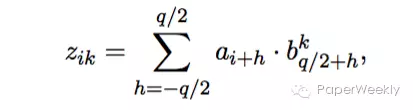
根据aggregate vector计算context(encoder的输出):

其中权重由下式计算:

Rush组的paper有一个特点,喜欢用CNN多一些,包括那位用CNN做句子分类的童鞋。可能的原因是,Rush是Facebook AI Research的研究人员,Lecun是Leader,所以他们对CNN的理解也更深一些,在model中使用的也就更多一些。
Decoder
decoder的部分是一个RNNLM,这里的RNN Hidden Layer使用的是LSTM单元。decoder的输出由下式计算:
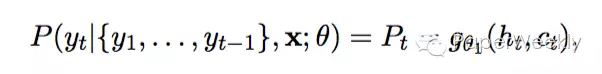
其中c(t)是encoder的输出,h(t)是RNN隐藏层,由下式计算:
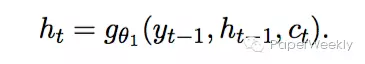
这里隐藏层的单元有两种思路,一种是常规的Elman RNN,一种是LSTM。
RNNLM的Hidden Unit可以不用LSTM或者GRU这么复杂,普通的隐藏层Elman RNN可以解决问题,采用Truncate-BPTT对RNN进行训练(详见Tomas Mikolov的PhD Thesis)。况且LSTM和GRU会带来更多的参数,造成overfit。
Generation
生成过程中也采用beam search算法进行summary生成。
Training
给定一个训练集,包括大量的sentence-summary pairs,用SGD将NLL函数最小化得到最优的参数集,参数包含encoder和decoder两个部分的参数。
SGD是一种常用的优化算法,在解决NLP问题中非常有效,其中最常见的mini batch训练方法。
Experiment
Paper 1
Dataset
本文采用经过处理的约400万Gigaword数据集作为训练集和验证集,在DUC2004数据集上进行评测,评测使用ROUGE方法。
DUC的比赛经常会包括文本摘要,所以常常用来比较每个模型或系统的优劣。
Baselines
1、PREFIX,这个baseline是取输入的前75个字符作为headline。
2、TOPIARY。
3、COMPRESS。
4、IR。
5、W&L。
6、MOSES+。
baselines选择了几组非常有代表性的系统。
Implementation
本文的程序用Torch实现,并且开源在Github上,处理1000个mini batch大概用时160s,最好的验证集参数出现在第15个epoch。
Torch是一个使用率非常高的开源工具,尤其是在研究领域。相比于Theano的难以调试,Torch具有非常简单、易用、灵活、易调试的特点。
Paper 2
Dataset
与第一篇相同的训练集和处理方法,同样使用DUC2004作为评测数据,ROUGE作为评测方法。
Baselines
1、ABS(第一篇paper中的方法)
2、ABS+(第一篇paper中的方法)
Implementation
同样使用Torch开发,在训练时用摘要的混乱度(perplexity)作为评价指标控制训练过程。
Result
Paper 1
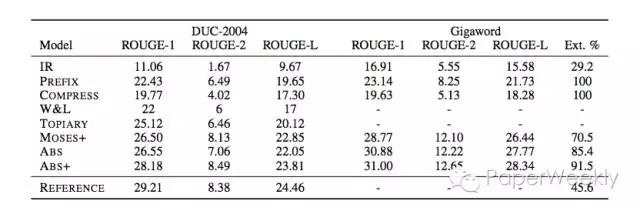
分别在DUC2004和Gigaword数据集上进行了对比,本文的ABS模型在DUC2004上评测结果相比于最好的baseline MOSES+并不如意,MOSES+是一个基于短语的统计机器翻译系统(Koehn,2007),在Gigaword训练集上比MOSES+好一些。但增加了人工feature的ABS+模型比ABS模型和MOSES+系统表现好了非常多。
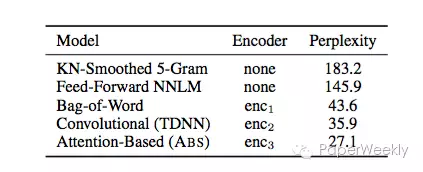
5种不同的模型在混乱度这个指标上比较,ABS具有明显的优势。
ABS模型实际上的效果并不理想,所以本文作者又提出了一种所谓的ABS+模型,将人工feature融合到了ABS模型中,得到了不错的效果。如果只看这一篇paper,可能会觉得不理想的原因是seq2seq在自动文摘中的效果一般,但看过第二篇paper之后,就会明白是因为本文的模型太过简单,第二篇paper也就有了意义。从另一个角度来看,纯粹的data-driven方法如果配合上一些extractive的方法会得到更好的结果,这点对于实际系统的开发非常有意义。
Paper 2

在Gigaword数据集上对比各个模型,RAS-Elman模型表现最好,说明了seq2seq相比于传统的文摘系统和算法,可以更好地解决问题,又一次证明了deep learning的强大。同时也验证了普通的RNN不见得比LSTM活着GRU表现差,尤其是当序列长度不是特别长的情况。
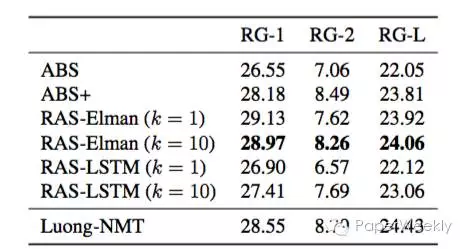
在DUC2004数据集上对比各个模型,得到了相同的结论。
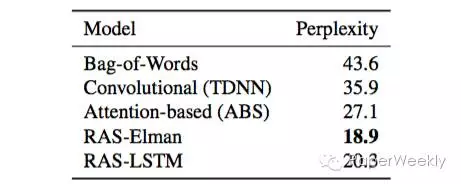
5种不同的模型在混乱度这个指标上比较,本文算法RAS-Elman具有明显的优势。
Links
[1] A Neural Attention Model for Abstractive Sentence Summarization Proceedings of EMNLP 2015
[2] Abstractive Sentence Summarization with Attentive Recurrent Neural Networks Proceedings of NAACL 2016
[3] ABS Torch Code
[4] Seq2Seq Torch Code
来源:paperweekly
原文链接