唐诗分析项目——诗词爬取模块
文章目录
- 1.准备阶段
-
- 1.1第三方依赖
- 1.2解释列表页和详情页
- 1.3如何从列表页获取详情页数据并得到诗集数据?
- 1.4如何进行分词?
- 2.实现阶段
-
- 2.1预研
-
- 2.1.1列表页获取
- 2.1.2详情页+诗集数据获取
- 2.1.3分词
- 2.1.4计算SGHA256
- 2.1.5入库
- 2.1实现流程
- 数据可视化模块
链接:JavaWeb——唐诗分析项目
1.准备阶段
1.1第三方依赖
1,数据库操作
mysql
mysql-connector-java
5.1.47
2,网页请求和解析
链接:HtmlUnit 官网
链接:HtmlUnit API 文档
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.36.0</version>
</dependency>
通过 HtmlUnit 库,可以很方便的加载一个完整的 Html 页面而且可以很轻易的模拟各种浏览器,然后就可以将其转换成我们常用的字串格式。用其他工具来获取其中的元素了。当然也可以直接在 HtmlUnit 提供的对象中获取网页元素(比如诗词的文本内容或详情页的链接)。
3,分词
链接:分词词性标注规范
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
通过ansj_seg,可以对获取到的诗内容进行分词,用于最终的页面展示。
1.2解释列表页和详情页
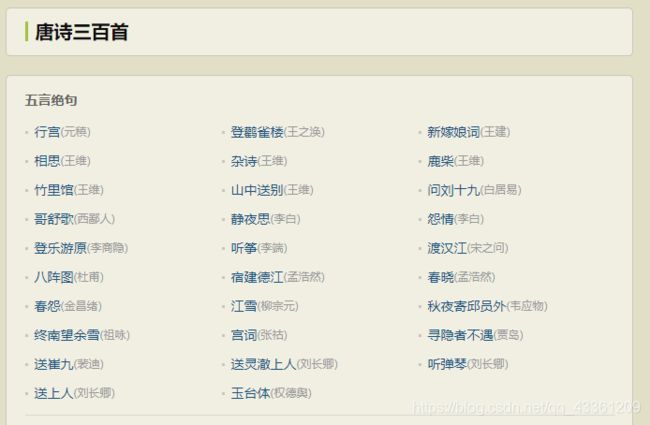
- 列表页:唐诗三百首
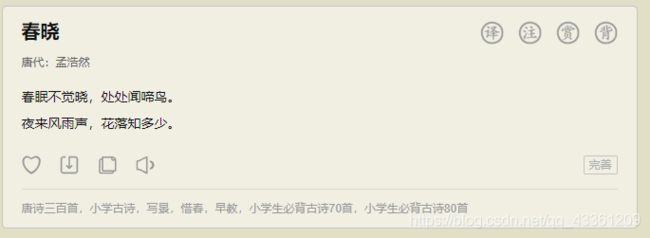
- 详情页:春晓(以春晓为例)
1.3如何从列表页获取详情页数据并得到诗集数据?
借助网页请求和解析工具——HtmlUnit。
- 观察获取到的列表页的数据
列表页.html,发现其中可获取所有古诗对应的子页面的path 。


链接:XPath 介绍 - 再根据每首诗对应的 path 获取详情页数据并提取数据(唐诗信息)。
eg:《春晓》url 是https://so.gushiwen.org/shiwenv_ccee5691ba93.aspx

1.4如何进行分词?
借助基于Java的中文分词工具——Ansj。
- 分词:本项目中使用的是
spark进行实时计算 。
常用的中文分词工具有两个:spark 和 Hadoop
- spark——大规模数据处理快速通用的计算引擎,特点:实时计算,保存在内存中,效率高。
- Hadoop——适用于分布式文件系统,为海量数据提供存储计算,特点:磁盘存储,离线处理
- 计数(词频)
由于分词之后的词语有可能会重复,所以要进行统计,存储的时候就是以key-value格式存储到Map集合(key是词,value是词频)。
2.实现阶段
2.1预研
2.1.1列表页获取
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class 列表页下载提取Demo {
public static void main(String[] args) throws IOException {
//无界面的浏览器(HTTP 客户端)
try (WebClient webClient = new WebClient(BrowserVersion.CHROME)) {
//关闭了浏览器的js执行引擎和css执行引擎
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
//请求页面(列表页)
String url = "https://so.gushiwen.org/gushi/tangshi.aspx";
HtmlPage page = webClient.getPage(url);
//保存到指定路径
File file = new File("唐诗三百首\\列表页.html");
page.save(file);
//获取html的body标签的内容
HtmlElement body = page.getBody();
List<HtmlElement> elements = body.getElementsByAttribute(
"div",
"class",
"typecont"
);
int count = 0;
for (HtmlElement element : elements) {
List<HtmlElement> aElements = element.getElementsByTagName("a");
for (HtmlElement a : aElements) {
System.out.println(a.getAttribute("href")); //打印唐诗子路径
count++;
}
}
System.out.println(count); //打印爬取诗集总数
}
}
}
解释:body.getElementsByAttribute(“div”,“class”,“typecont”);
获取 div 标签中 class为typecont 标签的 html 元素。由 html 的语法可以知道 Dom 树中可能不只这一个该元素(从上面的列表页图中也可以看出),所以
getElementsByAttribute方法返回值为一个集合类型。
2.1.2详情页+诗集数据获取
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomText;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.IOException;
public class 详情页下载提取Demo {
public static void main(String[] args) throws IOException {
try (WebClient webClient = new WebClient(BrowserVersion.CHROME)) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
String url = "https://so.gushiwen.org/shiwenv_45c396367f59.aspx";
HtmlPage page = webClient.getPage(url);
HtmlElement body = page.getBody();
// 标题
{
String xpath = "//div[@class='cont']/h1/text()";
Object o = body.getByXPath(xpath).get(0);DomText domText = (DomText)o;
System.out.println(domText.asText());
}
//朝代
{
String xpath = "//div[@class='cont']/p[@class='source']/a[1]/text()";
Object o = body.getByXPath(xpath).get(0);DomText domText = (DomText)o;
System.out.println(domText.asText());
}
//作者
{
String xpath = "//div[@class='cont']/p[@class='source']/a[2]/text()";
Object o = body.getByXPath(xpath).get(0);DomText domText = (DomText)o;
System.out.println(domText.asText());
}
//正文
{
String xpath = "//div[@class='cont']/div[@class='contson']";
Object o = body.getByXPath(xpath).get(0);
HtmlElement element = (HtmlElement)o;
System.out.println(element.getTextContent().trim());
}
}
}
}

解释1:String xpath = "//div[@class='cont']/h1/text()"; //标题
表示获取 div 标签中 class 为 cont 的标签其下面的h1标签的内容。这是通过XPath路径获取信息,更为方便。
解释2:String xpath = "//div[@class='cont']/p[@class='source']/a[1]/text()"; //作者
a[1] 表示该路径下不止一个a标签此处取第一个 a 标签,
a[1]/text()表示获取第一个标签的内容。
解释3:Object o = body.getByXPath(xpath).get(0);DomText domText = (DomText)o;
DomText 为节点对象,asText() 为获取内容的文本形式。
2.1.3分词
import java.util.List;
public class 分词Demo {
public static void main(String[] args) {
String sentence = "用我三生烟火,换你一世迷离";
List<Term> termList = NlpAnalysis.parse(sentence).getTerms();
for (Term term : termList) {
//getNatureStr输出词性,getRealName输出词语
System.out.println(term.getNatureStr() + ":" + term.getRealName());
}
}
}

解释:NlpAnalysis.parse(sentence).getTerms();
调用静态方法将要解析的字符串传入并调用 getTerms 方法返回一个 Term 的集合。利用该方法可以对获取的诗的内容进行词语提取。
2.1.4计算SGHA256
2.1.5入库
import com.mysql.jdbc.jdbc2.optional.MysqlConnectionPoolDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class 插入诗词Demo {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
String 朝代 = "唐代";
String 作者 = "白居易";
String 标题 = "问刘十九";
String 正文 = "绿蚁新醅酒,红泥小火炉。晚来天欲雪,能饮一杯无?";
// 1. 注册 Driver
// 2. 获取 Connection 通过 DriverManager
/*
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1/tangshiProject?useSSL=false&characterEncoding=utf8";
Connection connection = DriverManager.getConnection(url, "root", "");
System.out.println(connection);
*/
// 通过 DataSource 获取 Connection
// 这个不带有连接池
//DataSource dataSource1 = new MysqlDataSource();
// 这个带有连接池,好处
MysqlConnectionPoolDataSource dataSource = new MysqlConnectionPoolDataSource();
dataSource.setServerName("127.0.0.1");
dataSource.setPort(3306);
dataSource.setUser("root");
dataSource.setPassword("123456");
dataSource.setDatabaseName("tangshiproject");
dataSource.setUseSSL(false);
dataSource.setCharacterEncoding("UTF8");
// System.out.println(dataSource); 链接正常
try (Connection connection = dataSource.getConnection()) {
String sql = "INSERT INTO tangshi " +
"(sha256, url, dynasty, author, title, " +
"content, words) " +
"VALUES (?, ?, ?, ?, ?, ?, ?)";
try (PreparedStatement statement = connection.prepareStatement(sql)) {
statement.setString(1, "sha256");
statement.setString(2, "url");
statement.setString(3, 朝代);
statement.setString(4, 作者);
statement.setString(5, 标题);
statement.setString(6, 正文);
statement.setString(7,"");
statement.executeUpdate();
}
}
}
}
![]()
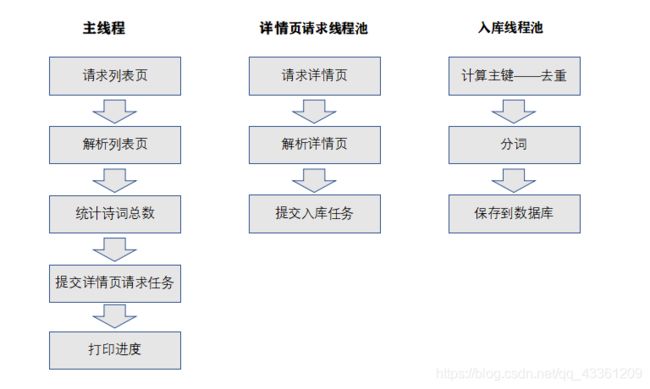
2.1实现流程
源码链接:
数据可视化模块
链接:唐诗分析项目——数据可视化模块