【小白做科研( 八 )】关于Experiment
文章目录
-
- 前言
- 关于Pytorch
-
- Mask
- 一些学习笔记
- 关于画图
- 关于脚本
- 关于可视化
-
- 理解可视化的参数
- 最后
前言
之前在忙考试周, 这个项目就搁置了一段时间, 最近考完试重新捡起来, 继续学习! 目前我们已经做完了数据处理, 复现了多篇论文的代码, 实验结果都和原论文一致, 接下来可以试一试提出自己的Idea并且做出一些实验啦~
做实验时有各种收获, 也学了几个新东西, 这一篇就打算分享一下
关于Pytorch
Mask
之前经常听到Mask这个词, 看了bert论文后知道原来是“遮住”一些词。那么除了作为预测任务外, 我们什么时候需要mask呢?
我目前遇到的情况就只有一种:即当我们不想让模型计算和padding相关的某些值时, 需要将padding的0或者是由这些0计算得到的结果mask掉
- 比如
KRNM中就会mask掉doc中padding的单词和query中任何单词交互后kernel过滤的结果, 也会mask掉query中padding的单词和doc中的任何词交互kernel过滤的结果
PyTorch中有很方便的接口tensor.masked_fill(), 具体可以参考文档, 注意可以方便地讲只包含0,1的tensor转化为布尔类型, 只需要tensor.bool()
一些学习笔记
自己一直在总结PyTorch中的一些好用的api之类的, 都在仓库里, 大家可以自行查看
关于画图
不得不说, latex是真的牛逼, tikz好好看啊, 放出来给大家康康
图片的源码2月会公开在github上~
关于脚本
之前一直看很多人的代码里有add_argument('--xxx')什么的, 昨天才发现原来有这么方便的命令行参数解析包----argparse!
之前我竟然是依靠sys.args来接受参数, 又蠢又不方便, 感到后悔.jpg。 这个包真的太帅了哈哈哈哈, 目前我的训练脚本都已经用这个包来解析了, 比如
![]()
原码在这里, 参见load_hparams函数
关于可视化
之前已经讲了用tensorboard可视化loss, 但是之前我学会了可以向里面添加模型的参数, 虽然看那个我个人认为是没什么用的, 但就很帅, 把下面的语句添加进train的循环里就可以了:
for name, param in model.named_parameters():
writer.add_histogram(name, param, epoch * len(dataloader) + step)
来张图康康
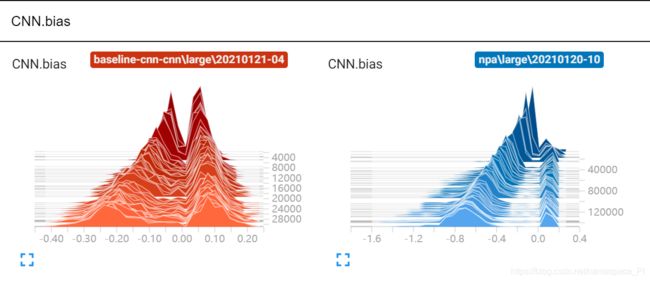
理解可视化的参数
首先需要明确, 所有模型的参数都是张量(tensor), 而任何张量都可以被.view(-1)拉成一维, 这个可视化参数图其实就是参数的张量拉成一维后在不同时间点(训练步数)上的分布
纵轴我默认的是训练的step数, 相当于数字越大是训练的次数越多的; 横轴就是张量的值, 有颜色的高度就代表了当前参数张量在这个值上的分布情况, 我认为tensorboard肯定是做了平滑处理的。
理解这是一种分布后, 我们就可以顺着纵轴数值增大的方向观察模型的学习情况, 可以发现这些分布再顺着某个趋势调整, 因此模型是在学习的。
最后
这是一个关于【新闻推荐】的仓库, 包括论文整理、笔记、复现的代码等, 之后有写成框架的打算, 欢迎大家标星~