C++ Exercises(十六)---Ethernet帧包结构解析

图1是一个假想的帧包结构,
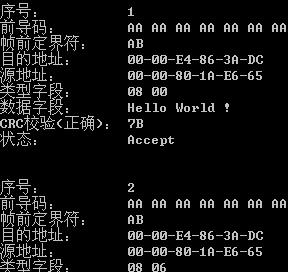
图2是解包后的结果。
///////////////////////////
//
/// 帧信息类
/////////////////////////// //
class CFrame
{
public :
CFrame( void );
~ CFrame( void );
void setSerialNumber( int nSN);
void setPreCode( const string & strPreCode);
void setPreBoundCode( const string & strBoundCode);
void setEtherType( const string & strEtherType);
void setData( char * strData, int len);
void setCRC( const string & strCRC);
void setFrameState( bool isValid);
void setDstAddress( const string & desAddress);
void setSrcAddress( const string & srcAddress);
private :
int nFrameSN; // 帧序号
string strPreCode; // 前导码
string strPreBoundCode; // 帧前定界符
string strDstAddress; // 目的地址
string strSrcAddress; // 源地址
string strEtherType; // 帧类型
string strData; // 数据域
string strCRC; // CRC校验码
bool bIsValid; // 是否正确的帧
friend ostream & operator << (ostream & out , const CFrame & frame);
};
CFrame::CFrame( void )
{
this -> nFrameSN = - 1 ;
this -> bIsValid = false ;
this -> strEtherType = "" ;
this -> strCRC = "" ;
this -> strData = "" ;
this -> strDstAddress = "" ;
this -> strPreBoundCode = "" ;
this -> strPreCode = "" ;
this -> strSrcAddress = "" ;
}
CFrame:: ~ CFrame( void )
{
}
void CFrame::setSerialNumber( int nSN)
{
this -> nFrameSN = nSN;
}
void CFrame::setPreCode( const string & strPreCode)
{
this -> strPreCode = strPreCode;
}
void CFrame::setPreBoundCode( const string & strBoundCode)
{
this -> strPreBoundCode = strBoundCode;
}
void CFrame::setEtherType( const string & strEtherType)
{
this -> strEtherType = strEtherType;
}
void CFrame::setData( char * strData, int len)
{
this -> strData = string (strData,len);
}
void CFrame::setCRC( const string & strCRC)
{
this -> strCRC = strCRC;
}
void CFrame::setFrameState( bool isValid)
{
this -> bIsValid = isValid;
}
void CFrame::setDstAddress( const string & desAddress)
{
this -> strDstAddress = desAddress;
}
void CFrame::setSrcAddress( const string & srcAddress)
{
this -> strSrcAddress = srcAddress;
}
/// 帧信息类
/////////////////////////// //
class CFrame
{
public :
CFrame( void );
~ CFrame( void );
void setSerialNumber( int nSN);
void setPreCode( const string & strPreCode);
void setPreBoundCode( const string & strBoundCode);
void setEtherType( const string & strEtherType);
void setData( char * strData, int len);
void setCRC( const string & strCRC);
void setFrameState( bool isValid);
void setDstAddress( const string & desAddress);
void setSrcAddress( const string & srcAddress);
private :
int nFrameSN; // 帧序号
string strPreCode; // 前导码
string strPreBoundCode; // 帧前定界符
string strDstAddress; // 目的地址
string strSrcAddress; // 源地址
string strEtherType; // 帧类型
string strData; // 数据域
string strCRC; // CRC校验码
bool bIsValid; // 是否正确的帧
friend ostream & operator << (ostream & out , const CFrame & frame);
};
CFrame::CFrame( void )
{
this -> nFrameSN = - 1 ;
this -> bIsValid = false ;
this -> strEtherType = "" ;
this -> strCRC = "" ;
this -> strData = "" ;
this -> strDstAddress = "" ;
this -> strPreBoundCode = "" ;
this -> strPreCode = "" ;
this -> strSrcAddress = "" ;
}
CFrame:: ~ CFrame( void )
{
}
void CFrame::setSerialNumber( int nSN)
{
this -> nFrameSN = nSN;
}
void CFrame::setPreCode( const string & strPreCode)
{
this -> strPreCode = strPreCode;
}
void CFrame::setPreBoundCode( const string & strBoundCode)
{
this -> strPreBoundCode = strBoundCode;
}
void CFrame::setEtherType( const string & strEtherType)
{
this -> strEtherType = strEtherType;
}
void CFrame::setData( char * strData, int len)
{
this -> strData = string (strData,len);
}
void CFrame::setCRC( const string & strCRC)
{
this -> strCRC = strCRC;
}
void CFrame::setFrameState( bool isValid)
{
this -> bIsValid = isValid;
}
void CFrame::setDstAddress( const string & desAddress)
{
this -> strDstAddress = desAddress;
}
void CFrame::setSrcAddress( const string & srcAddress)
{
this -> strSrcAddress = srcAddress;
}
/////////////////////////// //
/// 帧解析器类
///////////////////////////
class CFrameParser
{
public :
CFrameParser( void );
CFrameParser( const char * pFilePath);
CFrameParser( const string & strFilePath);
~ CFrameParser( void );
bool DoParser(); // 实际的解析动作
private :
string strInputFile; // 帧数据文件
vector < CFrame > vecFrames; // 帧包列表
};
CFrameParser::CFrameParser( void )
{
}
CFrameParser:: ~ CFrameParser( void )
{
}
CFrameParser::CFrameParser( const char * pFilePath):strInputFile(pFilePath)
{
}
CFrameParser::CFrameParser( const string & strFilePath):strInputFile(strFilePath)
{
}
bool CFrameParser::DoParser()
{ // 检测输入文件是否存在,并可以按所需的权限和方式打开
ifstream file( this -> strInputFile.c_str(), ios:: in | ios::binary | ios::_Nocreate);
if ( ! file.is_open())
{
cout << " 无法打开帧封装包文件,请检查文件是否存在并且未损坏 " << endl;
return false ;
}
// 变量声明及初始化
int nSN = 1 ; // 帧序号
int nCheck = 0 ; // 校验码
int nCurrDataOffset = 22 ; // 帧头偏移量
int nCurrDataLength = 0 ; // 数据字段长度
bool bParseCont = true ; // 是否继续对输入文件进行解析
int nFileEnd = 0 ; // 输入文件的长度
// 计算输入文件的长度
file.seekg( 0 , ios::end); // 把文件指针移到文件的末尾
nFileEnd = file.tellg(); // 取得输入文件的长度
file.seekg( 0 , ios::beg); // 文件指针位置初始化
cout.fill( ' 0 ' ); // 显示初始化
cout.setf(ios::uppercase); // 以大写字母输出
// 定位到输入文件中的第一个有效帧
// 从文件头开始,找到第一个连续的“AA-AA-AA-AA-AA-AA-AA-AB”
while ( true )
{
for ( int j = 0 ; j < 7 ; j ++ ) // 找个连续的xaa
{
if (file.tellg() >= nFileEnd) // 安全性检测
{
cout << " 没有找到合法的帧 " << endl;
file.close();
return false ;
}
// 看当前字符是不是xaa,如果不是,则重新寻找个连续的xaa
if (file. get () != 0xaa )
{
j = - 1 ;
}
}
if (file.tellg() >= nFileEnd) // 安全性检测
{
cout << " 没有找到合法的帧 " << endl;
file.close();
return false ;
}
if (file. get () == 0xab ) // 判断个连续的xaa之后是否为xab
{
break ;
}
}
// 将数据字段偏移量定位在上述二进制串之后字节处,并准备进入解析阶段
nCurrDataOffset = static_cast < int > (file.tellg()) + 14 ;
file.seekg( - 8 ,ios::cur);
// 主控循环
while ( bParseCont ) // 当仍然可以继续解析输入文件时,继续解析
{
// 检测剩余文件是否可能包含完整帧头
if (static_cast < int > (file.tellg()) + 14 > nFileEnd)// 从目的字段到类型字段总共14字节
{
cout << endl << " 没有找到完整帧头,解析终止 " << endl;
file.close();
return false ;
}
CFrame frame;
int c; // 读入字节
int i = 0 ; // 循环控制变量
int EtherType = 0 ; // 由帧中读出的类型字段
bool bAccept = true ; // 是否接受该帧
// 输出帧的序号
frame.setSerialNumber(nSN);
// 输出前导码,只输出,不校验
string tmpPreCode = "" ;
for (i = 0 ; i < 7 ; i ++ ) // 输出格式为:AA AA AA AA AA AA AA
{
c = file. get ();
string hexCode = util::ConvertToHex(c);
tmpPreCode.append(hexCode);
if (i != 6 )
{
tmpPreCode.append( 1 , ' ' );
}
}
frame.setPreCode(tmpPreCode);
// 输出帧前定界符,只输出,不校验
cout << endl << " 帧前定界符:\t " ;
cout.width( 2 ); // 输出格式为:AB
c = file. get ();
string tmpBoundCode = util::ConvertToHex(c);
frame.setPreBoundCode(tmpBoundCode);
string tmpDesAddress;
// 输出目的地址,并校验
for (i = 1 ; i <= 6 ; i ++ ) // 输出格式为:xx-xx-xx-xx-xx-xx
{
c = file. get ();
string desAddr = util::ConvertToHex(c);
tmpDesAddress.append(desAddr);
if (i != 6 )
{
tmpDesAddress.append( 1 , ' - ' );
}
if (i == 1 ) // 第一个字节,作为“余数”等待下一个bit
{
nCheck = c;
}
else // 开始校验
{
util::CRC::checkCRC(nCheck, c);
}
}
frame.setDstAddress(tmpDesAddress);
string tmpSrcAddress;
// 输出源地址,并校验
for (i = 1 ; i <= 6 ; i ++ ) // 输出格式为:xx-xx-xx-xx-xx-xx
{
c = file. get ();
string srcAddr = util::ConvertToHex(c);
tmpSrcAddress.append(srcAddr);
if (i != 6 )
{
tmpSrcAddress.append( 1 , ' - ' );
}
util::CRC::checkCRC(nCheck, c); // 继续校验
}
frame.setSrcAddress(tmpSrcAddress);
/// / 输出类型字段,并校验
// 输出类型字段的高位
c = file. get ();
util::CRC::checkCRC(nCheck, c); // CRC校验
EtherType = c;
// 输出类型字段的低位
c = file. get ();
util::CRC::checkCRC(nCheck,c); // CRC校验
EtherType <<= 8 ; // 转换成主机格式
EtherType |= c;
string tmpType = util::ConvertToType(EtherType);
frame.setEtherType(tmpType);
// 定位下一个帧,以确定当前帧的结束位置
while ( bParseCont )
{
for ( int i = 0 ; i < 7 ; i ++ ) // 找下一个连续的个xaa
{
if (file.tellg() >= nFileEnd) // 到文件末尾,退出循环
{
bParseCont = false ;
break ;
}
// 看当前字符是不是xaa,如果不是,则重新寻找个连续的xaa
if (file. get () != 0xaa )
{
i = - 1 ;
}
}
// 如果直到文件结束仍没找到上述比特串,将终止主控循环的标记bParseCont置为true
bParseCont = bParseCont && (file.tellg() < nFileEnd);
// 判断个连续的xaa之后是否为xab
if (bParseCont && file. get () == 0xab )
{
break ;
}
}
// 计算数据字段的长度
nCurrDataLength =
bParseCont ? // 是否到达文件末尾
(static_cast < int > (file.tellg()) - 8 - 1 - nCurrDataOffset) : // 没到文件末尾:下一帧头位置- 前导码和定界符长度- CRC校验码长度- 数据字段起始位置
(static_cast < int > (file.tellg()) - 1 - nCurrDataOffset); // 已到达文件末尾:文件末尾位置- CRC校验码长度- 数据字段起始位置
// 以文本格式数据字段,并校验
char * pData = new char [nCurrDataLength]; // 创建缓冲区
file.seekg(bParseCont ? ( - 8 - 1 - nCurrDataLength) : ( - 1 - nCurrDataLength), ios::cur);
file.read(pData, nCurrDataLength); // 读入数据字段
frame.setData(pData,nCurrDataLength);
int nCount = 50 ; // 每行的基本字符数量
for (i = 0 ; i < nCurrDataLength; i ++ ) // 输出数据字段文本
{
util::CRC::checkCRC(nCheck, ( int )pData[i]); // CRC校验
}
delete[] pData; // 释放缓冲区空间
// 输出CRC校验码,如果CRC校验有误,则输出正确的CRC校验码
cout << endl << " CRC校验 " ;
c = file. get (); // 读入CRC校验码
int nTmpCRC = nCheck;
util::CRC::checkCRC(nCheck, c); // 最后一步校验
string strCRC = util::ConvertToHex(c);
frame.setCRC(strCRC);
if ((nCheck & 0xff ) != 0 ) // CRC校验无误
{
bAccept = false ; // 将帧的接收标记置为false
}
// 如果数据字段长度不足字节或数据字段长度超过字节,则将帧的接收标记置为false
if (nCurrDataLength < 46 || nCurrDataLength > 1500 )
{
bAccept = false ;
}
frame.setFrameState(bAccept);
vecFrames.push_back(frame);
nSN ++ ; // 帧序号加
nCurrDataOffset = static_cast < int > (file.tellg()) + 22 ; // 将数据字段偏移量更新为下一帧的帧头结束位置
}
// 关闭输入文件
file.close();
return true ;
}
namespace
util
{ // 实用工具
class CRC
{
public :
////////////////////////////////////////////////////////////////////////////// //
// CRC校验,在上一轮校验的基础上继续作位CRC校验
//
// 输入参数:
// chCurrByte 低位数据有效,记录了上一次CRC校验的余数
// chNextByte 低位数据有效,记录了本次要继续校验的一个字节
//
// 传出参数:
// chCurrByte 低位数据有效,记录了本次CRC校验的余数
////////////////////////////////////////////////////////////////////////////// //
static void checkCRC( int & chCurrByte, int chNextByte)
{
// CRC循环:每次调用进行次循环,处理一个字节的数据。
for ( int nMask = 0x80 ; nMask > 0 ; nMask >>= 1 )
{
if ((chCurrByte & 0x80 ) != 0 ) // 首位为1:移位,并进行异或运算 {
chCurrByte <<= 1 ; // 移一位
if ( (chNextByte & nMask) != 0 ) // 补一位
{
chCurrByte |= 1 ;
}
chCurrByte ^= 7 ; // 首位已经移出,仅对低位进行异或运算,的二进制为,0111
}
else // 首位为0,只移位,不进行异或运算
{
chCurrByte <<= 1 ; // 移一位
if ( (chNextByte & nMask) != 0 ) // 补一位
{
chCurrByte |= 1 ;
}
}
}
}
};
char mappingTable[] = { ' 0 ' , ' 1 ' , ' 2 ' , ' 3 ' , ' 4 ' , ' 5 ' , ' 6 ' , ' 7 ' , ' 8 ' , ' 9 ' , ' A ' , ' B ' , ' C ' , ' D ' , ' E ' , ' F ' };
string ConvertToHex( int ch)
{
int high = ch / 16 ;
int low = ch % 16 ;
string result;
result.append( 1 ,mappingTable[high]);
result.append( 1 ,mappingTable[low]);
return result;
}
string ConvertToType( int ch)
{
string result;
int num,i;
for (i = 0 ;i < 4 ; ++ i)
{
num = ch & 0x000F ;
ch >>= 4 ;
result.append( 1 ,mappingTable[num]);
if (i == 1 )
{
result.append( 1 , ' ' );
}
}
for (i = 0 ;i <= 1 ; ++ i)
{
swap(result[i],result[ 4 - i]);
}
return result;
}
}
{ // 实用工具
class CRC
{
public :
////////////////////////////////////////////////////////////////////////////// //
// CRC校验,在上一轮校验的基础上继续作位CRC校验
//
// 输入参数:
// chCurrByte 低位数据有效,记录了上一次CRC校验的余数
// chNextByte 低位数据有效,记录了本次要继续校验的一个字节
//
// 传出参数:
// chCurrByte 低位数据有效,记录了本次CRC校验的余数
////////////////////////////////////////////////////////////////////////////// //
static void checkCRC( int & chCurrByte, int chNextByte)
{
// CRC循环:每次调用进行次循环,处理一个字节的数据。
for ( int nMask = 0x80 ; nMask > 0 ; nMask >>= 1 )
{
if ((chCurrByte & 0x80 ) != 0 ) // 首位为1:移位,并进行异或运算 {
chCurrByte <<= 1 ; // 移一位
if ( (chNextByte & nMask) != 0 ) // 补一位
{
chCurrByte |= 1 ;
}
chCurrByte ^= 7 ; // 首位已经移出,仅对低位进行异或运算,的二进制为,0111
}
else // 首位为0,只移位,不进行异或运算
{
chCurrByte <<= 1 ; // 移一位
if ( (chNextByte & nMask) != 0 ) // 补一位
{
chCurrByte |= 1 ;
}
}
}
}
};
char mappingTable[] = { ' 0 ' , ' 1 ' , ' 2 ' , ' 3 ' , ' 4 ' , ' 5 ' , ' 6 ' , ' 7 ' , ' 8 ' , ' 9 ' , ' A ' , ' B ' , ' C ' , ' D ' , ' E ' , ' F ' };
string ConvertToHex( int ch)
{
int high = ch / 16 ;
int low = ch % 16 ;
string result;
result.append( 1 ,mappingTable[high]);
result.append( 1 ,mappingTable[low]);
return result;
}
string ConvertToType( int ch)
{
string result;
int num,i;
for (i = 0 ;i < 4 ; ++ i)
{
num = ch & 0x000F ;
ch >>= 4 ;
result.append( 1 ,mappingTable[num]);
if (i == 1 )
{
result.append( 1 , ' ' );
}
}
for (i = 0 ;i <= 1 ; ++ i)
{
swap(result[i],result[ 4 - i]);
}
return result;
}
}