初识JAVA
初识JAVA
# 基本DOS命令
目前的阶段所编写的JAVA代码是通过DOS命令进行编译运行的,因此一些基本的DOS命令需要记住
1、mkdir : 创建目录;
2、cls : 清屏;
3、dir : 打开当前文件的子目录;
4、cd : 切换目录 (cd …返回上一级目录, cd 在当前目录下切换)
5、rd : 删除目录:rd 目录名;
6、del : 删除文件:del 目录名;
7、tab : 命令自动补全;
8、方向键翻阅历史指令记录;
9、del* .class : 用于删除当前文件下的所有以 . class 结尾的文件;
# JAVA的编译与运行
JAVA的编译与运行首先需要一个类名 + .java 的文件,然后通过 javac 来编译源代码,java 来执行编译好的程序;
具体流程如下 :

— 编写后保存后缀名为 . java 的源文件
— 该源程序文件经过 javac . exe 的编译生成后缀名为 . class的字节码文件(该字节码文件并不是纯粹的二进制文件)
— java . exe 命令启动JAVA虚拟机(JVM),JVM会启动类加载器ClassLoader
— ClassLoader 在硬盘上搜索指定类名的类文件,找到后将该字节码文件(. class文件)加载到JVM中
— JVM 再将 . class字节码文件完全解释称二进制文件
— 操作系统再与底层硬件进行交互
至于javac . exe 和 java . exe 则是在下载JDK的时候就已经一起下载了的,打开你的安装JDK文件的 bin 目录就能找到
![]()
# JAVA的特点以及JDK、JRE、JVM的关系
先看一下C语言:
就C语言而言,32位机器下,char * p 所占内存空间大小为4Byte,而64位机器下,char * p 所占内存空间为8Byte,32位机器下编译的C程序可以在64位机器上运行,反之则不能;
原理:
1Byte = 8bit,1bit能存放高低电频,0或1,,32位机器意味着内存寻址范围为32个0到32个1,高低 电频靠电线来传输,因此一定有32根传送高低电频的线;
00000000 00000000 00000000 00000000
11111111 11111111 11111111 11111111
32个0到32个1都是内存物理地址的编排顺序,要找到其中的地址需要32根地址线来找;
由此可知,64位机器中的内存物理地址编排顺序为64个0到64个1,要找到其中的地址,需要64根地址线来找,若是转至32位机器上未发生地址丢失;
而相对于C语言而言,JAVA所体现出最明显的优势就是极强的可移植性,即:一处编译,处处运行;同一份JAVA代码在编译之后可以在任意环境上执行。这里就涉及到JDK、JRE、JVM的关系了
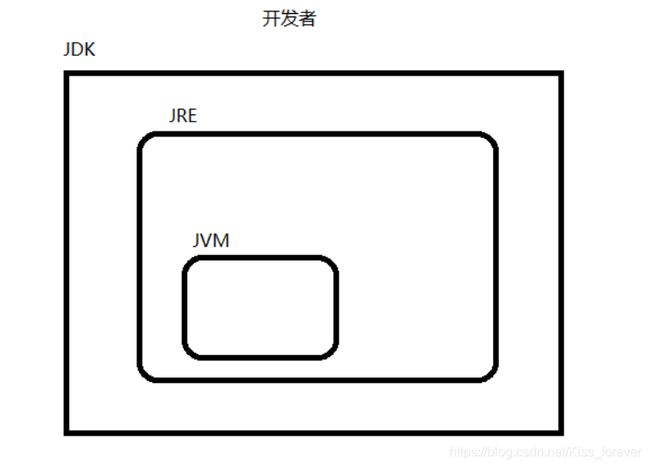
如上图所示便是三者的关系。JDK为开发工具包,JRE为运行时环境,JVM则是虚拟机了。
与C语言直接与系统硬件打交道不同,JAVA并不在Windows操作系统上运行,而是在JVM虚拟机上运行,需要多少内存则由虚拟机向操作系统申请,然后再由操作系统与底层硬件打交道。
理解的话就相当于不同学校的学生会,我们所编写的JAVA代码就相当于学生会的任务,当需要一些资源的时候学生会先向院里面申请,院里面再与学校进行交流分配资源下来完成任务。并不会说该任务换成不同学校的学生会就不能做了。
另外一点就是在移植到另一个环境时并不需要安装JDK,JDK为开发工具包,是开发者所需要的,而用户则只需要JAVA代码能够在其终端上运行就够了。因此只需要安装JRE。由于JAVA代码只是在JVM上运行,其实只安装JVM也是可以的,但JVM没有独立的软件能够安装,而JRE有;
# JAVA基础
知道以上的基础概念后就进入到JAVA的编写阶段了
在editplus中,蓝色的字体是关键字,黑色的是标识符,粉色的字面量;
字面量:数据;
标识符:变量名,函数名,类名,函数的参数名等这些由程序员自己定义的名字都叫做标识符。只能包含数字字母下划线$,不能以数字开头;
关键字:是JAVA保留的一些有特殊用途的,关键字不能作标识符;
语法规则:
1、JAVA代码中只能有一个public 修饰的类名,当有一个public类时,源文件名必
须与之一致,否则无法编译,如果源文件中没有一个public类,则文件名与类中没有一致性要求;
2、JAVA代码中可以有多个class,且public类不一定要位于开头,每个class中可以有一个main方法;
3、当通过DOS中的 java 命令进行运行时,输入哪个类名则运行哪个类中的方法;
4、根据sun公司所定规则,主函数写法如下:
public static void main (String[] args){
}
哪怕有一点变动都会使编译阶段或者运行阶段发生错误;
例如:若是少了public或者static则编译能通过但运行时错误,若是少了void则编译错误;
5、类体中不可包含 java 语句;
public class Hello
{
int i;
i = 100;
public static void main (String [] args)
{
System.out.println (i);
}
}
以上这种写法是错误的,i = 100是一个JAVA语句;
学过C语言的同学应该都知道,在函数外部是不能有C语句的,这里是一个道理,i = 100虽然在类的作用域内但在函数的作用域外
# * JAVA基础数据类型(单位:byte):
整数型数据 byte 1,short 2,int 4,long 8;
小数型数据 float 4 double 8;
字符型数据 char 2;
布尔型数据 boolean 1;
与C语言相同,1byte = 8bit,各种数据在内存中以二进制形式存放,第一位表示符号位
在JAVA中,对于整数型数据若未加显式说明则默认为int型,对于小数型数据若未加显示说明则默认为double型,因此当出现:
long = 2147483648
或者
float = 3.14
时,前者编译错误,后者精度丢失;前者是因为超出了int型的数据范围,后者则是从默认的double转float损失了小数位;
# * 造成精度丢失的原理:
在计算机内存存储中的二进制都是以补码的形式进行存储的,在内存中第一位表示符号位,0为正,1为负;
原码:一个整数的二进制表示形式,第一位为符号位(正数的反码补码与原码一致);
反码:符号位不变,其他位取反;
补码:反码 + 1;
public class test
{
public static void main (String[] args)
{
byte b = -1;
System.out.println (b);
}
}

可以看到执行结果为-1
-1的原码:10000000 00000000 00000000 00000001;
取反后为:11111111 11111111 11111111 11111110;
再加一:11111111 11111111 11111111 11111111;
即为int 型 -1 在内存中的存储形式;
但由于b的类型为byte,只有一个字节,因此只取最后一个字节的内容即:11111111;
在输出的时候在从此基础上还原成原码,即先减一再取反,结果为10000001,因此输出结果为 -1;
由于这种存储机制,所以当高转低是会导致精度丢失的问题;
对于char型数据赋值则需要在char的内存范围之内且不能为负数;
另外不同类型数据间的赋值与C语言规则一样,即不能将内存大的赋值给内存小的:
public class test
{
public static void main (String args)
{
int c = 'a';
char cc = c;
System.out.println (cc);
}
}
像这样是不可以的,因为c已经是int型了,内存为4byte,而char内存为2byte,直接赋值会造成编译器无法识别;但可以通过强势类型转换来解决这个问题;
boolean型变量:
boolean型变量是C语言中没有的变量,其值没有具体的数据,只有真和假;