prometheus学习1:快速上手
安装运行
先把程序跑起来再说,不懂的概念后边再看。
官网:https://prometheus.io
首先下载并解压如下包:
prometheus-2.9.1.linux-amd64.tar.gz
进入解压后的目录,运行./prometheus即可,浏览器输入机器IP加9090端口查看页面,页面比较简单,自己瞎点点就知道啥是啥了。
prometheus服务端安装完毕,为了监控主机信息,安装node_exporter,下载并解压如下包:
node_exporter-0.17.0.linux-amd64.tar.gz
进入解压后的目录,执行:
cp node_exporter /usr/local/bin/
node_exporter
浏览器输入机器ip加9100端口查看页面,可以看到当前node exporter获取到的当前主机的所有监控数据。
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus目录下的prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
可以直接使用
./prometheus启动服务,这时使用目录下默认配置文件prometheus.yml。也可以./prometheus --config.file=filename指定配置文件。
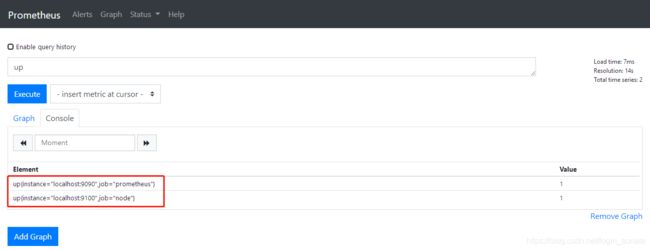
重新启动Prometheus Server,访问页面,输入“up”并且点击Excute按钮以后(使用“up”表达式查询当前所有Instance的状态),可以看到如下结果,说明Prometheus能够正常从node exporter获取数据:
整体架构与一些概念解释

Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporter
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
指标(metric)、样本
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。举例,大括号中为标签,这个例子就可以理解为3条时间序列(虽然指标名称相同,但标签不同):
node_disk_io_now{device="dm-0",instance="localhost:9100",job="node"}
node_disk_io_now{device="sda",instance="localhost:9100",job="node"}
node_disk_io_now{device="sr0",instance="localhost:9100",job="node"}
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):metric name和描述当前样本特征的label sets
- 时间戳(timestamp):一个精确到毫秒的时间戳
- 样本值(value): 一个folat64的浮点型数据表示当前样本的值
Job和Instance
当我们需要采集不同的监控指标(例如:主机、MySQL、Nginx)时,我们只需要运行相应的监控采集程序(exporter),并且让Prometheus Server知道这些Exporter实例的访问地址。
在Prometheus中,每一个暴露监控样本数据的HTTP服务称为一个实例(instance),它是被监控的具体目标。监控这些instances的任务叫做job。每个job负责一类任务,可以为一个job配置多个instance,job对自己的instance执行相同的动作。
隶属于job的instance可以直接在配置文件中写死。也可以让job自动从consul、kuberntes中动态获取,这个过程就是服务发现。
除了通过使用“up”表达式查询当前所有Instance的状态以外,还可以通过Prometheus UI中的Targets页面查看当前所有的监控采集任务。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
四种Metrics类型
以node exporter为例,查看机器ip:9100/metrics页面可以查看到当前抓取的数据,TYPE字段中包含有类型。
# HELP node_intr_total Total number of interrupts serviced.
# TYPE node_intr_total counter
node_intr_total 4.0709044e+07
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.18
Counter(计数器)
特点是只增不减,除非系统发生重置,常用来记录某些事件发生的次数。一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
Gauge(仪表盘)
侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。
Histogram(直方图)
用于统计和分析样本的分布情况。
Summary(摘要)
也用于统计和分析样本的分布情况。
参考学习资料:https://yunlzheng.gitbook.io/prometheus-book/