Flink SQL 中动态修改 DDL 的属性
Flink 支持使用 HiveCatalog 来管理 Flink 的元数据信息, HiveCatalog 通过授权用户仅创建一次表和其他元数据对象,这样就避免了重复创建 kafka 流表,节省了大量的时间, 对于不同的用户来说,可以直接使用表而不需要再去创建.
就拿消费 kafka 来说,经常会有下面的需求:
•用户需要指定特性的消费时间戳,即修改 scan.startup.timestamp-millis 属性.•用户想忽略掉解析错误,需要将 format.ignore-parse-errors 改为 true.•不同用户想要设置不同的 group.id 去消费数据.•用户想要改变消费 kafka 的策略比如从最早的 offset 开始消费数据.
类似于这样的需求很常见,有的时候只是临时修改一下属性,难道需要把表删了,再重新创建新的表吗 ? 显然不是的,下面就介绍两种方式去修改表的属性.
1, ALTER TABLE
•重命名表
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
将给定的表名重命名为另一个新的表名。
•设置或更改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
在指定的表中设置一个或多个属性。如果表中已经设置了特定属性,会用新属性覆盖旧值。
2, Dynamic Table Options
从 1.11 开始,用户可以通过动态参数的形式灵活地设置表的属性参数,覆盖或者追加原表的 WITH (...) 语句内定义的 table options。
基本语法为:
table_path /*+ OPTIONS(key=val [, key=val]*) */
动态参数的使用没有语境限制,只要是引用表的地方都可以追加定义。在指定的表后面追加的动态参数会自动追加到原表定义中,是不是很方便呢
由于可能对查询结果有影响,动态参数功能默认是关闭的, 使用下面的方式开启该功能:
set table.dynamic-table-options.enabled=true;
下面就来分别演示一下这两种方法的具体操作
3, 建表
DROP TABLE IF EXISTS KafkaTable;
CREATE TABLE KafkaTable (
`age` BIGINT,
`name` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
`topic` STRING METADATA VIRTUAL,
WATERMARK FOR ts AS ts - INTERVAL '0' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'new_flink_topic',
'properties.bootstrap.servers' = 'master:9092,storm1:9092,storm2:9092',
'properties.group.id' = 'flink_jason',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false', -- 字段丢失任务不失败
'json.ignore-parse-errors' = 'true' -- 解析失败跳过
);
DROP TABLE IF EXISTS print_table;
CREATE TABLE print_table
(
name string,
pv BIGINT,
uv BIGINT
)
WITH ('connector' = 'print');
insert into print_table
SELECT name,
count(*) as pv,
count(distinct name) as uv
from KafkaTable
group by name;
上面把 3 条语句放在一块执行了,然后先在 Flink SQL 里面查一下刚才建的 kafka 流表和打印数据的结果表

然后再到 hive 里面查一下这两个表是否存在

可以看到这两个表在 hive 里面也是存在的,因为已经配置了 HiveCatalog 后面就不用再重复建表了,可以直接使用这两个表.
再来看一下 hive 里面的表结构信息.
hive> show create table kafkatable ;
OK
CREATE TABLE `kafkatable`(
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION
'hdfs://master:9000/hive/warehouse/mydatabase.db/kafkatable'
TBLPROPERTIES (
'flink.connector'='kafka',
'flink.format'='json',
'flink.json.fail-on-missing-field'='false',
'flink.json.ignore-parse-errors'='true',
'flink.properties.bootstrap.servers'='master:9092,storm1:9092,storm2:9092',
'flink.properties.group.id'='flink_jason',
'flink.scan.startup.mode'='latest-offset',
'flink.schema.0.data-type'='BIGINT',
'flink.schema.0.name'='age',
'flink.schema.1.data-type'='VARCHAR(2147483647)',
'flink.schema.1.name'='name',
'flink.schema.2.data-type'='TIMESTAMP(3)',
'flink.schema.2.metadata'='timestamp',
'flink.schema.2.name'='ts',
'flink.schema.2.virtual'='false',
'flink.schema.3.data-type'='BIGINT',
'flink.schema.3.metadata'='partition',
'flink.schema.3.name'='partition',
'flink.schema.3.virtual'='true',
'flink.schema.4.data-type'='BIGINT',
'flink.schema.4.metadata'='offset',
'flink.schema.4.name'='offset',
'flink.schema.4.virtual'='true',
'flink.schema.5.data-type'='VARCHAR(2147483647)',
'flink.schema.5.metadata'='topic',
'flink.schema.5.name'='topic',
'flink.schema.5.virtual'='true',
'flink.schema.watermark.0.rowtime'='ts',
'flink.schema.watermark.0.strategy.data-type'='TIMESTAMP(3)',
'flink.schema.watermark.0.strategy.expr'='`ts` - INTERVAL \'0\' SECOND',
'flink.topic'='new_flink_topic',
'is_generic'='true',
'transient_lastDdlTime'='1608409788')
Time taken: 0.046 seconds, Fetched: 44 row(s)
可以看到 'flink.scan.startup.mode'='latest-offset' 这个属性是从最新的位置开始消费数据的.然后我们来看一下 Flink 的 UI
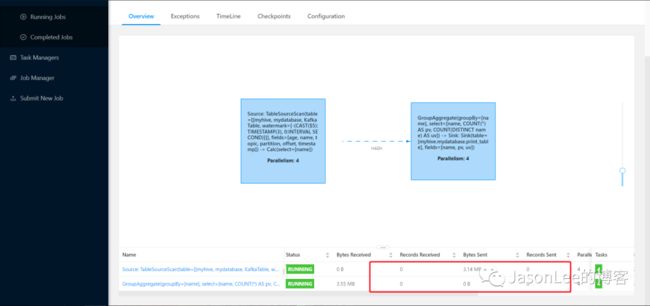
因为是从最新的 offset 位置开始消费的,我没有写入新数据,所以消费到的数据是 0 条.然后我把任务停掉, 加上动态表选项,修改为从头开始消费,然后再提交任务.
insert into print_table
SELECT name,
count(*) as pv,
count(distinct name) as uv
from KafkaTable /*+ OPTIONS('scan.startup.mode'='earliest-offset') */
group by name;

可以看到在我没有写入新数据的情况下,已经消费到 534 条数据.也可以到 tm 的 stdout 里面观察一下数据打印的变化情况,说明刚才修改的 'scan.startup.mode'='earliest-offset' 属性是起作用的,任务是从头开始消费数据.
然后我再用 alter table 来直接修改表里面的属性.
alter table myhive.mydatabase.KafkaTable set('scan.startup.mode'='earliest-offset');
先不提交任务,先到 hive 表里看下属性是否修改了.
> show create table kafkatable ;
OK
CREATE TABLE `kafkatable`(
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION
'hdfs://master:9000/hive/warehouse/mydatabase.db/kafkatable'
TBLPROPERTIES (
'flink.connector'='kafka',
'flink.format'='json',
'flink.json.fail-on-missing-field'='false',
'flink.json.ignore-parse-errors'='true',
'flink.properties.bootstrap.servers'='master:9092,storm1:9092,storm2:9092',
'flink.properties.group.id'='flink_jason',
'flink.scan.startup.mode'='earliest-offset',
'flink.schema.0.data-type'='BIGINT',
'flink.schema.0.name'='age',
'flink.schema.1.data-type'='VARCHAR(2147483647)',
'flink.schema.1.name'='name',
'flink.schema.2.data-type'='TIMESTAMP(3)',
'flink.schema.2.metadata'='timestamp',
'flink.schema.2.name'='ts',
'flink.schema.2.virtual'='false',
'flink.schema.3.data-type'='BIGINT',
'flink.schema.3.metadata'='partition',
'flink.schema.3.name'='partition',
'flink.schema.3.virtual'='true',
'flink.schema.4.data-type'='BIGINT',
'flink.schema.4.metadata'='offset',
'flink.schema.4.name'='offset',
'flink.schema.4.virtual'='true',
'flink.schema.5.data-type'='VARCHAR(2147483647)',
'flink.schema.5.metadata'='topic',
'flink.schema.5.name'='topic',
'flink.schema.5.virtual'='true',
'flink.schema.watermark.0.rowtime'='ts',
'flink.schema.watermark.0.strategy.data-type'='TIMESTAMP(3)',
'flink.schema.watermark.0.strategy.expr'='`ts` - INTERVAL \'0\' SECOND',
'flink.topic'='new_flink_topic',
'is_generic'='true',
'transient_lastDdlTime'='1608411139')
Time taken: 0.043 seconds, Fetched: 44 row(s)
'flink.scan.startup.mode'='earliest-offset' 可以看到这个属性已经被修改了.然后直接提交任务就可以了,不需要再加刚才的那个动态表属性.
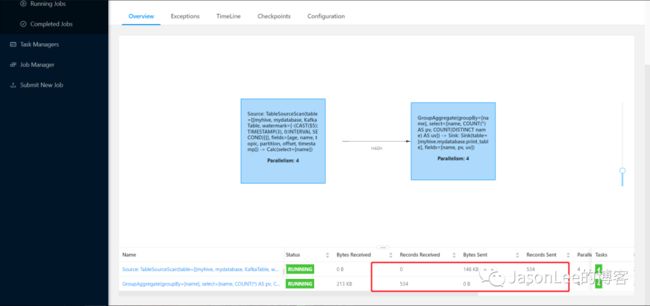
还是刚才的 534 条数据,这两种方式都可以解决上面的用户需求.
区别:
alter table 的方式是直接修改表的属性, 元数据信息也会被修改, Dynamic Table Options 的方式只是通过动态参数的形式追加或者覆盖原表的属性,但是不会修改元数据信息.建议在生产环境还是使用第二种方式比较好.
