PaddleOCR数字仪表识别——4. pipeline
写给自己:服务器上启动时,jupyter notebook和streamlit都要切换到py37的环境下启动
1. 考虑pipeline
我现在是只弄好了一个文字识别模型,需要调用现有的 文字检测 模型,来确定文字区域,把区域图片输入到文字识别模型中。
其实文档写得很清楚了,看看就知道了,主要有两个。
PaddleOCR中文说明文档

4.1 方式1 直接使用PaddleOCR包
前提:
安装whl包
pip安装
pip install paddleocr
不进行这步就会导致4.1.1的报错
参考paddleocr package使用说明。重点是:
- 单独执行检测 这个部分
from paddleocr import PaddleOCR, draw_ocr ocr = PaddleOCR() # need to run only once to download and load model into memory img_path = 'PaddleOCR/doc/imgs/11.jpg' result = ocr.ocr(img_path, rec=False) for line in result: print(line) # 显示结果 from PIL import Image image = Image.open(img_path).convert('RGB') im_show = draw_ocr(image, result, txts=None, scores=None, font_path='/path/to/PaddleOCR/doc/simfang.ttf') im_show = Image.fromarray(im_show) im_show.save('result.jpg')
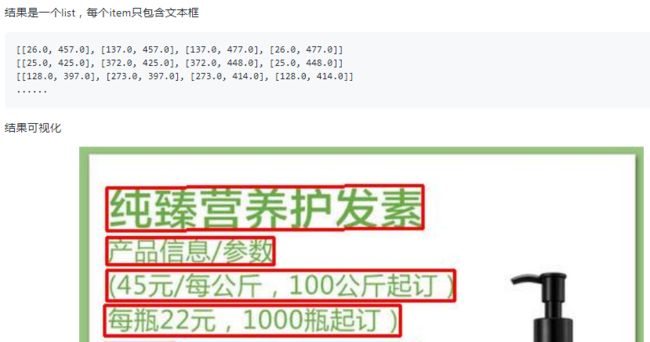
4.1.1 报错 cannot import name ‘draw_ocr’ from ‘paddleocr’
这是因为之前的安装都是安装配置paddlepaddle环境,以及直接git上clone了PaddleOCR这个目录,但是并没有直接
pip install paddleocr
![]()
但是安装后,streamlit中依然报错,(右侧菜单栏 选择 clear cache 没啥反应)
# 命令行输入
streamlit cache clear
![]()
显示已经清理完缓存了
切换到其他的jupyter文件中使用,显示 可以import。
搜索paddleOCR和谷歌都没有发现相关的问题,应该是streamlit缓存的问题。。。重启下服务器和浏览器好了
重启后依然报错,将引用方式改为
import paddleocr
ocr = paddleocr.PaddleOCR()
im_show = paddleocr.draw_ocr(image, result, txts=None, scores=None, font_path='/path/to/PaddleOCR/doc/simfang.ttf')
出现新的错误 如4.1.2 但是依然没有解决
查看 PaddleOCR文件夹下的 paddleocr.py文件,里面确实没有draw_ocr这个函数。
4.1.1.1 问题原因
问题所在
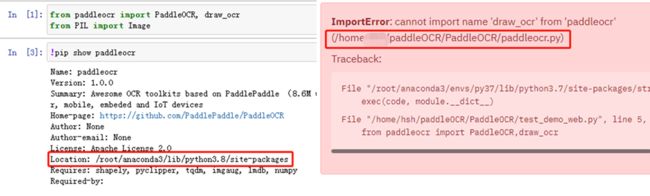
jupyter文件里可以正确引用是因为,在PaddleOCR文件夹外面,所以不会直接索引同级目录下的paddleocr,而负责streamlit的python脚本为了方便调用放在了PaddleOCR文件夹下,存在一个同名的paddleocr.py文件,所以需要明确修改引用的paddleocr的位置。
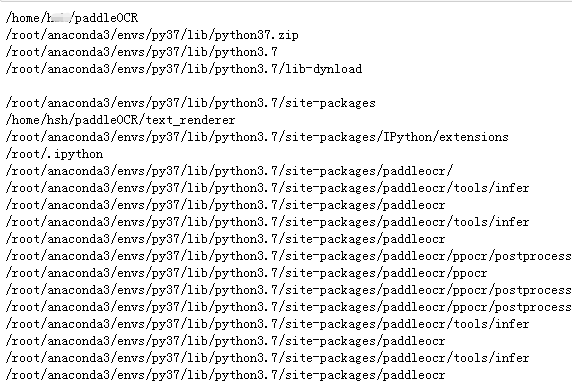
打印sys.path看一下(可以看到,第一个就是paddleOCR这个文件夹,也就是最先索引到的就是 PaddleOC文件夹下那个paddleocr.py文件(没有draw_ocr函数的))
4.1.1.2 解决问题
这里就涉及到python导入模块搜索路径的优先级问题,参考:
- 关于Python导入模块的搜索路径以及优先级问题(Search path for python import module )
- Python引用自定义模块优先级
修改python搜索路径优先级有些复杂,考虑使用别的方式来实现。
直接把python脚本从PaddleOCR目录中移出去,就好了,记得把模型推理代码的路径也改了就好了。
4.1.1.3 隐患
我记得在进行checkpoint模型推理的时候,我就曾经把文件放在PaddleOCR文件夹外面,同时修改了代码里的模型推理执行路径,但是会报错。
但是很奇怪,在进行inference模型推理时,把文件放在外面修改路径就不会报错。
checkpoint模型报错(想要不报错就得把python脚本放到PaddleOCR文件夹里):
os.system("python3 ./PaddleOCR/tools/infer_rec.py -c ./PaddleOCR/configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./PaddleOCR/output/rec_CRNN/best_accuracy Global.infer_img=test.jpg 2>&1 | tee result.log")

X 4.1.2 ‘Namespace’ object has no attribute ‘use_pdserving’
根据相关的issue
- Github-issue AttributeError: ‘Namespace’ object has no attribute ‘use_pdserving’
- /home/PaddleOCR/ppocr/utils/ppocr_keys_v1.txt读取出错
之前安装的是 paddleOCR1.0.0版本,现在已经是1.1.0了。。。。
4.2 方式2 基于Python预测引擎推理
4.2.1 识别模型转inference模型
参考基于Python预测引擎推理可知:
- inference 模型(fluid.io.save_inference_model保存的模型) 一般是模型训练完成后保存的固化模型,多用于预测部署。
- 训练过程中保存的模型是checkpoints模型,保存的是模型的参数,多用于恢复训练等。
- 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合与实际系统集成
- 所以最好把模型转成inference比较好。
与上面的一致,使用的模型是rec_mv3_none_bilstm_ctc,配置文件是rec_icdar15_train.yml,所以转换
识别模型转inference模型与检测的方式(直接从模型评估/推理的部分把命令行的config部分和checkpoint部分复制过来就好了)相同,如下:
# -c后面设置训练算法的yml配置文件
# -o配置可选参数
# Global.checkpoints参数设置待转换的训练模型地址,不用添加文件后缀.pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=output/rec_CRNN/best_accuracy Global.save_inference_dir=./inference/rec_crnn/
# 默认PaddleOCR文件夹下没有inference的,./就是当前执行目录啊
运行结果如下:

转换成功后,在目录下有两个文件:
/inference/rec_crnn/
└─ model 识别inference模型的program文件
└─ params 识别inference模型的参数文件
4.2.2 基于CTC损失的识别模型推理
使用的模型是rec_mv3_none_bilstm_ctc,所以可以确定使用的ctc损失。。。 或者翻翻上面的内容,确定是这个

参考 基于CTC损失的识别模型推理部分,第一步也是执行转换为inference模型(这步如果上面已经执行过则可以跳过,和上面一样的)
注意:如果训练时修改了文本的字典,在使用inference模型预测时,需要通过–rec_char_dict_path指定使用的字典路径
# 第一步
# -c后面设置训练算法的yml配置文件
# Global.checkpoints参数设置待转换的训练模型地址,不用添加文件后缀.pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=output/rec_CRNN/best_accuracy Global.save_inference_dir=./inference/rec_crnn/
# 第二步
python3 tools/infer/predict_rec.py
--image_dir="./test.jpg"
--rec_model_dir="./inference/rec_crnn/" #上一步转换后inference模型保存的地方
--rec_image_shape="3, 32, 200" # 配置文件里也有
--rec_char_type="ch" #这个要和自己配置文件里写得一样
--rec_char_dict_path="./ppocr/utils/num_dict.txt" # 配置文件里也有 都一致就好了
python3 tools/infer/predict_rec.py --image_dir="./test.jpg" --rec_model_dir="./inference/rec_crnn/" --rec_image_shape="3, 32, 200" --rec_char_type="ch" --rec_char_dict_path="./ppocr/utils/num_dict.txt"
执行结果(确实快了很多):

然后也在streamlit上把这个模型执行命令换一下,确实执行的快了很多。
4.3 paddle保存模型的方式
关于Paddle保存模型方式的介绍,详细参见:分类预测框架
Paddle 的模型保存有多种不同的形式,大体可分为两类:
- persistable 模型(fluid.save_persistabels保存的模型) 一般做为模型的 checkpoint,可以加载后重新训练。persistable 模型保存的是零散的权重文件,每个文件代表模型中的一个 Variable,这些零散的文件不包含结构信息,需要结合模型的结构一起使用。
resnet50-vd-persistable/ ├── bn2a_branch1_mean ├── bn2a_branch1_offset ├── bn2a_branch1_scale ├── bn2a_branch1_variance ├── bn2a_branch2a_mean ├── bn2a_branch2a_offset ├── bn2a_branch2a_scale ├── ... └── res5c_branch2c_weights - inference 模型(fluid.io.save_inference_model保存的模型) 一般是模型训练完成后保存的固化模型,用于预测部署。与 persistable 模型相比,inference 模型会额外保存模型的结构信息,用于配合权重文件构成完整的模型。如下所示,model 中保存的即为模型的结构信息。
resnet50-vd-persistable/ ├── bn2a_branch1_mean ├── bn2a_branch1_offset ├── bn2a_branch1_scale ├── bn2a_branch1_variance ├── bn2a_branch2a_mean ├── bn2a_branch2a_offset ├── bn2a_branch2a_scale ├── ... ├── res5c_branch2c_weights └── model
为了方便起见,paddle 在保存 inference 模型的时候也可以将所有的权重文件保存成一个params文件,如下所示:
resnet50-vd
├── model
└── params
4.4 调整输出结果
4.4.1输入汉字区域,依然匹配到数字输出的问题
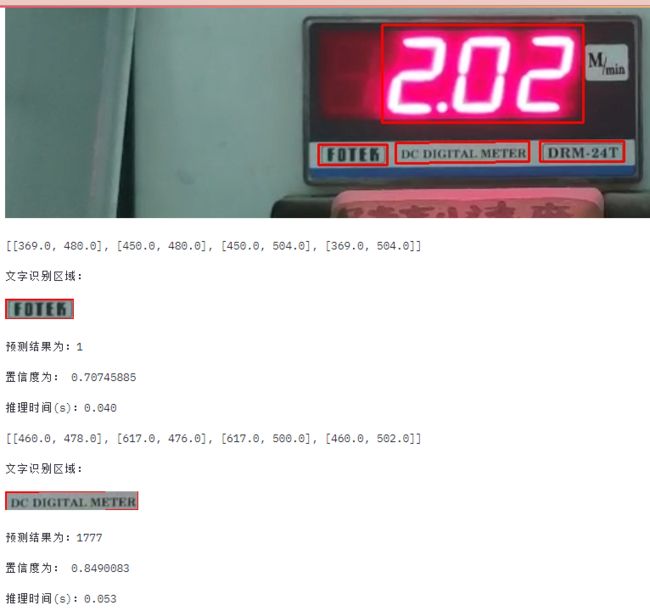
存在问题:
- 直接使用paddleocr这个wheel的文字检测模型,得到文字框范围很大。
- 检测模型会把所有的文字区域检测出来,但是识别模型只有10个数字,而且这个置信度还很高???所以有些英文都会被分配到中文
看一下,./PaddleOCR/tools/infer_rec.py看一下执行推理的文件是怎么写的,前面都是配置文件,后面有if else的地方是关键,我是用的ctc损失。
有一行代码:score = np.mean(probs[valid_ind, ind[valid_ind]])
4.5 小数点和非数字字符识别问题
4.5.1 小数点干扰
小数点会造成一定的干扰

4.5.2 非数字字符

这里采取了一个比较歪门邪道/很死的一个方法,只看最大的框
- 因为在实际现场放置摄像头的时候,肯定是设置一个框(就好像支付宝那些软件拍身份证一样,让实物靠近程序设置的那个框),争取让要识别的部分占摄像头画面的最大部分,所以这里只识别检测出的最大的框。
- 面积最大(最开始考虑的是宽最大。。。)
4.5.2.1 np.argpartition()函数
参考:
- 1.How do I get indices of N maximum values in a NumPy array?
- 2.A fast way to find the largest N elements in an numpy array
numpy从1.8开始,除了有找到最大值的值和索引的 max/argmax之外,还提供了找到前n大的值和索引 partition/argpartition ,函数说明
alist=[10,7,20,19,8,20]
nplist=np.array(alist)
ind = np.argpartition(nplist, -4)
# ind的值为:
> array([1, 4, 0, 3, 2, 5])
# 按照值从小到大的顺序返回 对应索引 7,8,10,19,20,20
ind = np.argpartition(nplist, -4)[-4:]
# 这样就返回了最大的四个数的索引
函数参数说明:
numpy.argpartition(a, kth, axis=-1, kind='introselect', order=None)[source]
a 要排序的array
kth 整数或者整数序列
分区依据的元素索引。 第k个元素将处于其最终排序位置,所有较小的元素将在其之前移动,而所有较大的元素将在其后面移动。 分区中所有元素的顺序是不确定的。 如果提供了第k个序列,它将立即将它们全部划分到其排序位置。
kind{
‘introselect’}, 可选参数
选择算法。 默认值为“ introselect”
此外,根据参考2中的一个回答,

argpartition进行的是部分排序,花费的时间是 O(n)而不是O(n)*log(n)

此外,还有另一个人给出了numpy和其他库相比,完成同样功能所花费时间的比较
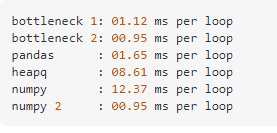
所以,以后再遇到这个问题,就直接用numpy的argpartition就好了
4.5.2.2 返回列表中top n值对应索引
这里涉及到一个找到top n大元素索引的问题,大致代码:
def findMaxBox(rsList,num):
"""
rsList 文字检测的结果 列表形式返回的每个框的四个点的坐标
[[37.0, 2.0], [102.0, 2.0], [102.0, 32.0], [37.0, 32.0]]
num top几大的框
只比较高度(长度没有什么比较的价值 说明不了问题)
可以自己改为面积最大
"""
height=[]
for i in rsList:
oneHeight=i[2][1]-i[0][1]
height.append(oneHeight)
# height列表里的索引序号和 rsList的索引序号一致
nplist=np.array(height)
ind = np.argpartition(nplist, num*(-1))[num*(-1):]
return rsList[ind]
4.6 改进方向
4.6.1 预处理
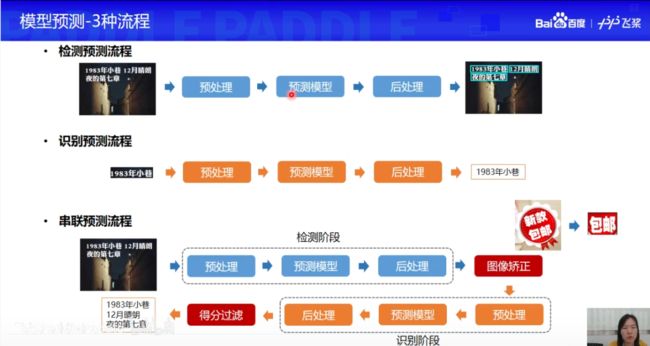
根据PaddleOCR课程直播视频中的讲解,对于模型的使用其实有预处理后处理这些步骤的,所以可以看看相关代码中是怎么处理的

参考:百度AI社区帖子——LED 显示屏数字识别
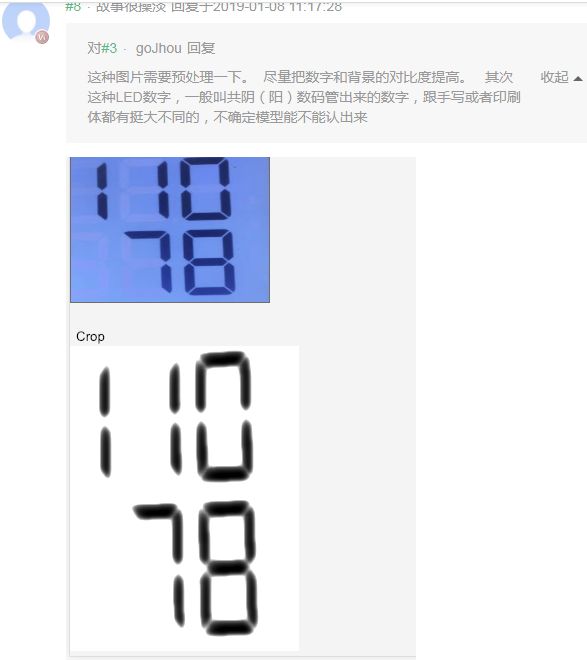
所以之前担心的本来底图就有数字的问题其实可以直接通过预处理处理掉,不会输入模型对模型造成干扰。
4.6.1.1 边缘提取提取文字
大致的代码
# 训练时模型接受的数据size是 [3,32,200]
import cv2
image = cv2.imread("2.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blurred, 50, 200, 255)
# 由于streamlit只接受RGB/BGR的图像,所以转完之后还要转回去
color=cv2.cvtColor(edged,cv2.COLOR_GRAY2BGR)
# 进行颜色反转,使前景色黑色 背景白色
reverse=cv2.bitwise_not(edged)
color=cv2.cvtColor(reverse,cv2.COLOR_GRAY2BGR)

使用的训练数据大部分是前景色(文字的颜色)比背景色要深,这里换一下,把背景换成白色,字换成黑色好了。
参考:OpenCV之bitwise_and、bitwise_not等图像基本运算及掩膜

颜色反转后,效果果然好了很多(果然模型是完全遵循你给的训练数据的,所以测试的时候,尽量把测试数据也要往训练数据的样子里靠啊)

但是对于有些图,效果就不好(所以边缘提取还是针对那种图片边缘很清晰的,这种有干扰的就不太好使)

4.6.1.2 不进行边缘提取

上面的图,文字都是边缘,里面是空心的。。。。但是输入模型训练的图都是上面这样的。
所以不能进行边缘提取,要把图中的文字区域变成实心的
参考的:
- Recognizing digits with OpenCV and Python
- 使用opencv进行数字识别
图片预处理部分的代码和说明,详见另一个博客 PaddleOCR数字仪表识别——图像预处理(python)
4.6.1.3 结论
所以PaddleOCR其实也就是直接训练,测试的时候也没有对图片进行预处理,所以还是要自己写预处理部分。
- 对于文字带背光,屏幕不发光的数字表,使用Osrtu效果会好

- 但是对于文字不发光,背景发光的数字表,直接输入原图的数字区域会更好

- 时刻牢记自己训练模型的数据长啥样。尽量让输入模型的测试数据和那个靠近就可以
4.6.2 数据
造出来的数据和实际检测的数据还是差的挺多的,还是要找一些不一样的数据。
虽然预处理之后输入模型的都是灰度图
关于数据部分的更新,已经更新到
OCR数字仪表识别——2.数据合成(制作假数据)及真实数据收集
这个博文里了
4.6.3 换模型
刚好发现有个数字表图片:上面都是宋体,第一次训练的时候没有训练到

重新产一次图片,重新训练,换个精度更高的模型。这个问题毕竟有小数点,比较复杂。
使用数码管字体和宋体查看小数点后,可以知道,数码管字体的小数点不会占一整格,而宋体字体的小数点会占一整格。 所以小数点占位是根据字体的,而不是随便放的

- 检测模型:PaddleOCR自带的;识别模型:CRNN + ctc rec_mv3_none_bilstm_ctc 骨干网络 MobileNetV3
- 可以考虑使用其他模型,比如https://github.com/YCG09/chinese_ocr 文本检测:CTPN 文本识别:DenseNet + CTC
换个模型,步骤参考之前的博客PaddleOCR数字仪表识别——3.paddleocr迁移学习 步骤重新来一遍。 之前那个写的太乱了,重写了一个,参考
4.6.4 其他
4.6.4.1 模型转换
- inference模型比checkpoint模型快
4.6.4.2 PIL Image和Opencv转换
- 尽量减少图片写入磁盘的操作,很费时(我的代码是使用PIL操作了crop,然后save之后再使用opencv imread 修改后确实快了一些)
根据Python PIL | Image.crop() method

根据PIL.Image.open和cv2.imread的比较与相互转换# PIL Image转换成OpenCV格式 img = Image.open(imagePath) plt.imshow(img) img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR) # OpenCV图片转换为PIL image img = cv2.imread(imagePath) img2 = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
4.6.4.3 命令行输出重定向到变量
- 减少写入和读取日志的时间(由于调用推理语句是命令行完成的,所以导致结果也是直接打印在命令行中,前期是使用 输出重定向 > 把输出结果不仅输出到命令行,还输出到一个文本文件中,然后再去文本文件里读取内容)
一开始以为无法实现的,搜索了一波,感谢大佬 - python 调用系统命令,并将输出重定向,输出其结果至文件或者字符串变量
- python 将命令行执行的屏幕输出赋值到out变量
- Pipe subprocess standard output to a variable [duplicate]
- Store output of subprocess.Popen call in a string
所以是可以实现的,我的代码也从原来的读写文件log变成,弄到变量里。节省了读写磁盘的时间
# 以前
import os
os.system('''python3 ./PaddleOCR/tools/infer/predict_rec.py --image_dir="./recoginze.jpg" --rec_model_dir="./PaddleOCR/inference/rec_crnn/" --rec_image_shape="3, 32, 200" --rec_char_type="ch" --rec_char_dict_path="./PaddleOCR/ppocr/utils/num_dict.txt" 2>&1 | tee result.log''')
resultLines=[]
with open('result.log','r') as f:
resultLines=f.readlines()
rs=resultLines[1].split(':')[-1]
time=resultLines[2].split(':')[-1]
predict_rs=rs.split(',')[0][2:][:-1]
p=rs.split(',')[1][:-2]
st.text('预测结果为:'+str(predict_rs))
st.text("置信度为:"+str(p))
st.text("推理时间(s):"+str(time))
现在
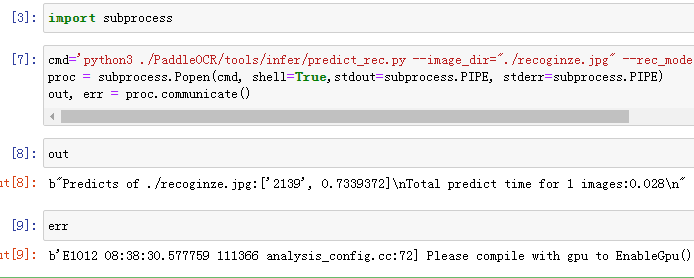
或者
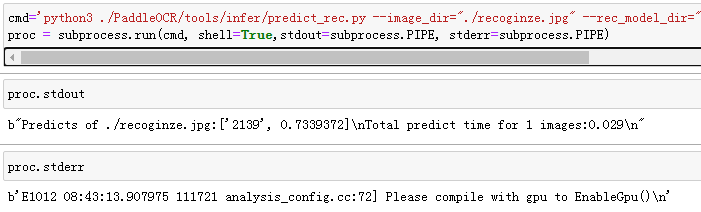
(run方法是 Popen和communicate二者的结合,参见4.6.4.4关于subprocess中三个方法的区别)
注意:一定要加如 shell=True,不然会报错传入的不是字符串或者是文件路径

这里 第一项 python3是命令 其余都是这个命令的参数
4.6.4.4 subprocess说明
关于subprocess,网上大多数都是转自Python模块整理(三):子进程模块subprocess

除了Popen方法,还有一个call方法,还有个run,三者区别:
- What is the difference between subprocess.popen and subprocess.run

- What’s the difference between Python’s subprocess.call and subprocess.run
- run方法返回了一个 CompletedProcess对象实例 https://docs.python.org/3/library/subprocess.html
