【Task04】前沿学术数据分析AcademicTrends-论文种类分类
一、任务
- 任务主题:论文分类(数据建模任务),利用已有数据建模,对新论文进行类别分类
- 任务内容:使用论文标题完成类别分类
- 任务成果:学会文本分类的基本方法、TF-IDF等
二、读取数据并简单查看
读取到第20万行数据,这里需要注意的是,由于先存后判断,所以是第20万行可以取到:
data = []
with open("arxiv-metadata-oai-snapshot.json", 'r') as f:
for idx, line in enumerate(f):
d = json.loads(line)
d = {
'title': d['title'], 'categories': d['categories'], 'abstract': d['abstract']}
data.append(d)
# 选择前20万条数据
if idx > 199999:
break
df = pd.DataFrame(data)
df

处理title和abstract列:
df['text'] = df['title'] + df['abstract']
df['text'] = df['text'].apply(lambda x: x.replace('\n',' '))
df['text'] = df['text'].apply(lambda x: x.lower())
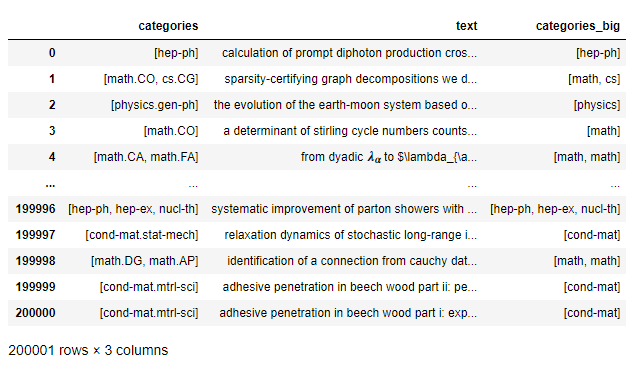
df_demo = df[['categories','text']]
df_demo

处理categories列
# 多个类别,包含子分类
df_demo['categories'] = df_demo['categories'].apply(lambda x : x.split(' '))
# 单个类别,不包含子分类
df_demo['categories_big'] = df_demo['categories'].apply(lambda x : [xx.split('.')[0] for xx in x])
df_demo
三、文本分类的基本方法
使用pip install scikit-learn下载sklearn库
将类别进行编码
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
df_label = mlb.fit_transform(df_demo['categories_big'].iloc[:])
df_label
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 1, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 0]])
df_label.shape
(200001, 19)
1.使用TFIDF提取特征
#2021年1月23日00:01:06 开始
#2021年1月23日00:01:24 结束
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.multioutput import MultiOutputClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
vectorizer = TfidfVectorizer(max_features=4000)
df_tfidf = vectorizer.fit_transform(df_demo['text'].iloc[:])
# 划分训练集和验证集
x_train, x_test, y_train, y_test = train_test_split(df_tfidf, df_label,test_size = 0.2,random_state = 1)
# 构建多标签分类模型
clf = MultiOutputClassifier(MultinomialNB()).fit(x_train, y_train)
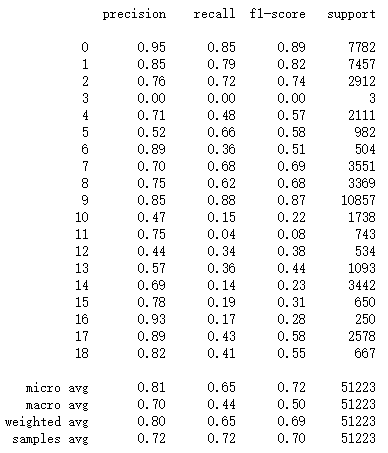
print(classification_report(y_test, clf.predict(x_test)))
2.深度学习
使用pip install keras下载sklearn库:

同时需要使用pip install tensorflow安装tensorflow环境以支撑keras的使用:

from sklearn.model_selection import train_test_split
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.layers import Dense,Input,LSTM,Bidirectional,Activation,Conv1D,GRU
from keras.layers import Dropout,Embedding,GlobalMaxPooling1D, MaxPooling1D, Add, Flatten
from keras.layers import GlobalAveragePooling1D, GlobalMaxPooling1D, concatenate, SpatialDropout1D# Keras Callback Functions:
from keras.callbacks import Callback
from keras.callbacks import EarlyStopping,ModelCheckpoint
from keras import initializers, regularizers, constraints, optimizers, layers, callbacks
from keras.models import Model
from keras.optimizers import Adam
#划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(df_demo['text'].iloc[:], df_label,test_size = 0.2,random_state = 1)
#设置参数
max_features= 500
max_len= 150
embed_size=100
batch_size = 128
epochs = 5
tokens = Tokenizer(num_words = max_features)
tokens.fit_on_texts(list(x_train)+list(x_test))
x_sub_train = tokens.texts_to_sequences(x_train)
x_sub_test = tokens.texts_to_sequences(x_test)
x_sub_train=sequence.pad_sequences(x_sub_train, maxlen=max_len)
x_sub_test=sequence.pad_sequences(x_sub_test, maxlen=max_len)
sequence_input = Input(shape=(max_len, ))
x = Embedding(max_features, embed_size,trainable = False)(sequence_input)
x = SpatialDropout1D(0.2)(x)
x = Bidirectional(GRU(128, return_sequences=True,dropout=0.1,recurrent_dropout=0.1))(x)
x = Conv1D(64, kernel_size = 3, padding = "valid", kernel_initializer = "glorot_uniform")(x)
avg_pool = GlobalAveragePooling1D()(x)
max_pool = GlobalMaxPooling1D()(x)
x = concatenate([avg_pool, max_pool])
preds = Dense(19, activation="sigmoid")(x)
model = Model(sequence_input, preds)
model.compile(loss='binary_crossentropy',optimizer=Adam(lr=1e-3),metrics=['accuracy'])
model.fit(x_sub_train, y_train, batch_size=batch_size, epochs=epochs)
本次任务完。