使用Python实现KMeans算法
简介
通过使用python语言实现KMeans算法,不使用sklearn标准库。
该实验中字母代表的含义如下:
- p:样本点维度
- n:样本点个数
- k:聚类中心个数
实验要求
使用KMeans算法根据5名同学的各项成绩将其分为3类。
数据集
数据存储格式为csv,本实验使用数据集如下:
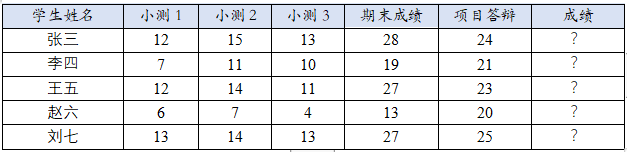
实验步骤
- 引入需要的包
本实验只需要numpy和pandas两个包, 其中numpy用于数值计算,pandas用于读取数据。
import numpy as np
import pandas as pd
- 定义函数计算欧氏距离
# 返回两点之间的欧氏距离,其中point1、point2为两个点的坐标,其维度为(p,)
def get_euclidean_distance(point1, point2):
return (np.sum((point1 - point2) ** 2)) ** 0.5
- 定义函数返回所有样本点到聚类中心的欧氏距离
# 返回所有样本点到所有聚类中心的欧氏距离,其维度为(k,n)
def get_distances(train_data, crowds):
all_distances = [] # 保存所有样本点到所有聚类中心的欧氏距离,其维度为(k,n)
for i in range(len(crowds)):
distances = [] # 保存所有样本点到一个聚类中心的欧氏距离,其维度为(n,)
for j in range(len(train_data)):
distances.append(get_euclidean_distance(train_data[j], crowds[i]))
all_distances.append(distances)
return all_distances
- 定义函数根据欧氏距离将样本点分类到最近的聚类中心,返回的list维度为(n,)
# 将样本点分类到最近的聚类中心,其维度为(n,)
def classify(train_data, crowds):
all_distances = get_distances(train_data, crowds)
clsy = np.argmin(all_distances, axis=0)
return clsy
- 定义函数比较两聚类结果
由于KMeans算法需要迭代知道聚类结果收敛,所以使用如下函数判断两个聚类结果是否相等。
# 返回一个bool值,表示分类结果是否改变
def clsy_change(new_clsy, clsy):
changed = False
for i in range(len(clsy)):
if clsy[i] != new_clsy[i]:
changed = True
break
return changed
- 定义聚类函数
该函数为最终的聚类函数,实现思路为根据KMeans算法的原理使用上述函数迭代获取新的聚类结果知道聚类结果收敛。
def final_classify(train_data, crowds):
p = train_data.shape[1]
n = len(train_data)
k = len(crowds)
new_crowds = crowds
clsy = np.ndarray((n,))
new_clsy = np.ndarray((n,))
while (clsy != new_clsy).any():
clsy = new_clsy
new_clsy = classify(train_data, new_crowds)
print('new_clsy:', new_clsy)
new_crowds = []
clusters = [] # 每一个聚类中的样本点的索引
for i in range(k):
clusters.append([])
for i in range(n):
clusters[new_clsy[i]].append(i)
for j in range(k):
if len(clusters[j]) == 0:
new_crowds.append(crowds[j])
else:
sums = np.zeros((p,))
for m in clusters[j]:
sums += train_data[m]
means = sums / len(clusters[j])
new_crowds.append(means)
return (new_crowds, new_clsy)
- 调用函数获取实验结果
# 初始聚类中心
crowds2 = np.array([[12, 15, 13, 28, 24], [7, 11, 10, 19, 21], [6, 7, 4, 13, 20]])
dataCsv2 = 'p2.csv'
data2 = pd.read_csv(dataCsv2)
train_data2 = data2.iloc[:, 1:].values
result2 = final_classify(train_data2, crowds2)
print('聚类中心:', np.array(result2[0]))
print('聚类结果:', np.array(result2[1]))
最终的聚类结果如下:

总结
KMeans算法是一种迭代求解的算法,在实验过程中要注意收敛的判定,同时也要注意数据与求解过程中分类结果的表示方法,而且要明白初始聚类中心的选择会对聚类结果产生直接的影响。