python随机森林实现反欺诈案例
近年来,国内的电信诈骗案件呈愈演愈烈之势,本文以某省电信公司简化版本的防诈骗模型为案例,利用python机器学习工具,使用随机森林算法,从数据处理、特征工程、到反诈骗模型的模型的构建及评估等完整流程进行一个简单的记录和介绍。
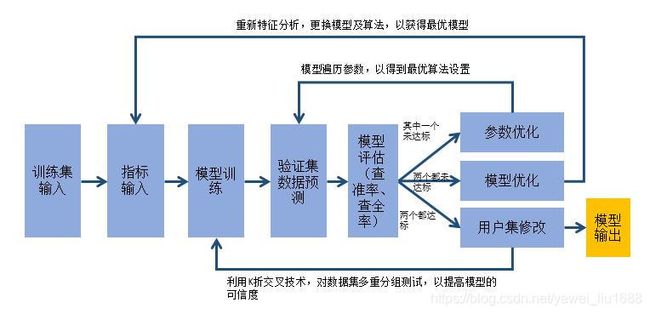
流程图
环境设置、模块加载
# coding: utf-8
import os
import numpy as np
import pandas as pd
from sklearn.ensemble import IsolationForest
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.externals import joblib
from sklearn import metrics
from scipy import stats
import time
from datetime import datetime
import warnings
warnings.filterwarnings("ignore")
os.chdir('home//zj//python//python3.6.9//bin//python3')
数据加载
自定义工作目录,并加载样本数据
def read_file(filepath):
os.chdir(os.path.dirname(filepath))
return pd.read_csv(os.path.basename(filepath),encoding='utf-8')
file_pos = "E:\\工作文件\\***\\防诈骗识别\\data_train.csv"
data_pos = read_file(file_pos)
特征重命名
data_pos.columns = ['BIL_ACCS_NBR','ASSET_ROW_ID','CCUST_ROW_ID','LATN_ID','TOTAL_CNT',
'TOTAL_DURATION','ZJ_CNT','ZJ_TOTAL_DURATION','TOTAL_ROAM_CNT','ZJ_ROAM_CNT','ZJ_LOCAL_CNT','ZJ_ROAM_DURATION','ZJ_LOCAL_DURATION','ZJ_LONG_CNT','BJ_LOCAL_CNT','WORK_TIME_TH_TT_CNT','FREE_TIME_TH_TT_CNT','NIGHT_TIME_TH_TT_CNT','DURATION_TP_1','DURATION_TP_2','DURATION_TP_3','DURATION_TP_4','DURATION_TP_5','DURATION_TP_6','DURATION_TP_7','DURATION_TP_8',
'DURATION_TP_9','TOTAL_DIS_BJ_NUM','DIS_BJ_NUM','DIS_OPP_HOME_NUM','OPP_HOME_NUM','MSC_NUM','DIS_MSC_NUM','ZJ_AVG_DURATION','TOTAL_ROAM_CNT_RATE','ZJ_DURATION_RATE','ZJ_CNT_RATE','ZJ_ROAM_DURATION_RATE','ZJ_ROAM_CNT_RATE','DURATION_RATIO_0_15','DURATION_RATIO_15_30',
'DURATION_RATIO_30_45','DURATION_RATIO_45_60','DURATION_RATIO_60_300','DUR_30_CNT_RATE',
'DUR_60_CNT_RATE','DUR_90_CNT_RATE','DUR_120_CNT_RATE','DUR_180_CNT_RATE','DUR_BIGGER_180_CNT_RATE','DIS_BJ_NUM_RATE','TOTAL_DIS_BJ_NUM_RATE','CALLING_REGION_DISTRI_LEVEL','ACT_DAY','ACT_DAY_RATE','WEEK_DIS_BJ_NUM','YY_WORK_DAY_OIDD_23_NUM','IS_GJMY','ZJ_DURATION_0_15_CNT','ZJ_DURATION_15_30_CNT','ZJ_DURATION_30_60_CNT','ZJ_DURATION_RATIO_0_15','ZJ_DURATION_RATIO_15_30','ZJ_DURATION_RATIO_30_60','H_MAX_CNT','H_MAX_CIRCLE','INNER_MONTH','MIX_CDSC_FLG','CPRD_NAME','AMT','CUST_ASSET_CNT','CUST_TELE_CNT','CUST_C_CNT','ALL_LL_USE',
'MY_LL_USE','MY_LL_ZB','ALL_LL_DUR','MY_LL_DUR','MY_DUR_ZB','AGE','GENDER','CUST_TYPE_GRADE_NAME','ISP','TERM_PRICE','SALES_CHANNEL_LVL2_NAME','CORP_USER_NAME','TOTOL_7_CNT',
'TOTOL_7_DUR','TOTOL_7_ZJ_DUR','TOTOL_7_ZJ_CNT','TOTOL_7_ZJ_D_CNT','TOTOL_7_BJ_D_DUR',
'TOTOL_7_JZGS_CNT','WEEK_CNT','WEEK_DUR','ZB_WS','COUPLE_NUMBER','TIME_COUPLE_NUMBER','ZJ_0912','HB_0912','ZJ_1417','HB_1417','CHG_CELLS','ZHANBI','ETL_DT','IS_HARASS']
数据查看
数据表行/列
data_pos.shape
![]()
可以看出,正样本数据只有3436,负样本较多,属于极度不平衡样本数据
数据预处理
无意义字段删除
data_pos_1 = data_pos.drop([
'BIL_ACCS_NBR',
'ASSET_ROW_ID',
'CCUST_ROW_ID',
'LATN_ID',
'CPRD_NAME',
'ISP',
'AGE',
'CUST_TYPE_GRADE_NAME',
'ETL_DT',
'WEEK_DIS_BJ_NUM',
'TOTOL_7_ZJ_D_CNT',
'TOTOL_7_JZGS_CNT',
'INNER_MONTH'
],axis = 1)
正负样本规模
data_pos.IS_HARASS.value_counts()

TERM_PRICE 进行分箱处理
data_pos_1['TERM_PRICE'] = data_pos_1['TERM_PRICE'].apply(lambda x: np.where(x > 5000, '>5000',
np.where(x>3000, '(3000,5000]',
np.where(x>2000, '(2000,3000]',
np.where(x>1000, '(1000,2000]',
np.where(x>0, '(0,1000]', '未识别'))))))
字段填充及转化
将类别型变量空值及极小规模类别做替换
data_pos_1.TERM_PRICE.value_counts()
data_pos_1.MIX_CDSC_FLG.value_counts()
data_pos_1.CORP_USER_NAME.value_counts()
data_pos_1.SALES_CHANNEL_LVL2_NAME.value_counts()
#依次处理TERM_PRICE、MIX_CDSC_FLG、CORP_USER_NAME、SALES_CHANNEL_LVL2_NAME
def CHANGE_SALES_CHANNEL_LVL2_NAME(data):
if data in ['社会渠道','实体渠道','电子渠道','直销渠道']:
return data
else:
return '未识别'
data_pos_1['SALES_CHANNEL_LVL2_NAME'] = data_pos_1.SALES_CHANNEL_LVL2_NAME.apply(CHANGE_SALES_CHANNEL_LVL2_NAME)
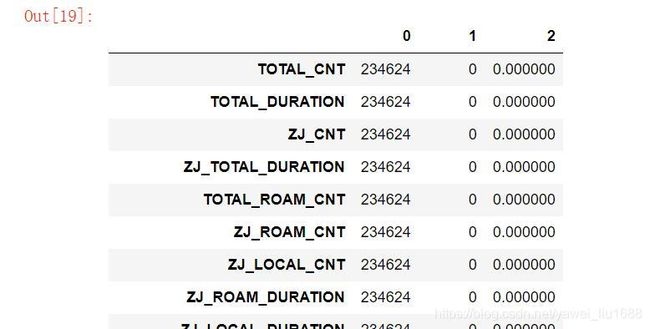
缺失值处理
##缺失值统计
def na_count(data):
data_count = data.count()
na_count = len(data) - data_count
na_rate = na_count/len(data)
na_result = pd.concat([data_count,na_count,na_rate],axis = 1)
return na_result
na_count = na_count(data_pos_1)
na_count
拆分字段
字段按照连续、类别拆分
def category_continuous_resolution(data,variable_category):
for key in list(data.columns):
if key not in variable_category:
variable_continuous.append(key)
else:
continue
return variable_continuous
#字段按照类型拆分
variable_category = ['MIX_CDSC_FLG','GENDER','TERM_PRICE','SALES_CHANNEL_LVL2_NAME','CORP_USER_NAME']
variable_continuous = []
variable_continuous = category_continuous_resolution(data_pos_1,variable_category)
字段类型转化
def feture_type_change(data,variable_category):
'''
字段类型转化
'''
for col_key in list(data.columns):
if col_key in variable_category:
data[col_key] = data[col_key].astype(eval('object'), copy=False)
else:
data[col_key] = data[col_key].astype(eval('float'), copy=False)
return data
data_pos_2 = feture_type_change(data_pos_1,variable_category)
缺失值填充
def na_fill(data,col_name_1,col_name_2):
'''
缺失值填充
'''
for col_key in list(data.columns):
if col_key in col_name_1:
data[col_key] = data[col_key].fillna(value = '未识别')
elif col_key in col_name_2:
data[col_key] = data[col_key].fillna(data[col_key].mean())
else:
data[col_key] = data[col_key].fillna(value = 0)
return data
#缺失值填充
col_name_1 = variable_category
col_name_2 = []
data_pos_3 = na_fill(data_pos_2,col_name_1,col_name_2)
类别变量one_hot处理
##one_hot
def data_deliver(data,variable_category):
'''
ont_hot衍生
'''
for col_key in list(data.columns):
if col_key in variable_category:
temp_one_hot_code = pd.get_dummies(data[col_key],prefix = col_key)
data = pd.concat([data,temp_one_hot_code],axis = 1)
del data[col_key]
else:
continue
return data
data_pos_4 = data_deliver(data_pos_3,variable_category)
特征工程
相关性分析
def max_corr_feture_droped(train_data,variable_continuous,k):
'''
相关性分析
'''
table_col = train_data.columns
table_col_list = table_col.values.tolist()
all_lines = len(train_data)
train_data_number = train_data[variable_continuous]
###连续型变量的处理过程:数据的标准化
from numpy import array
from sklearn import preprocessing
def normalization(data,method,feature_range=(0,1)):
if method=='MaxMin':
train_data_scale=data.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
return train_data_scale
if method=='z_score':
train_data_scale=data.apply(lambda x: (x - np.mean(x)) / (np.std(x)))
return train_data_scale
train_data_scale = normalization(train_data_number,method=scale_method)
# 输出各个变量之间的相关性报告
def data_corr_analysis(raw_data, sigmod = k):
corr_data = raw_data.corr()
for i in range(len(corr_data)):
for j in range(len(corr_data)):
if j == i:
corr_data.iloc[i, j] = 0
x, y, corr_xishu = [], [], []
for i in list(corr_data.index):
for j in list(corr_data.columns):
if abs(corr_data.loc[i, j]) > sigmod: # 保留相关性系数绝对值大于阈值的属性
x.append(i)
y.append(j)
corr_xishu.append(corr_data.loc[i, j])
z = [[x[i], y[i], corr_xishu[i]] for i in range(len(x))]
high_corr = pd.DataFrame(z, columns=['VAR1','VAR2','CORR_XISHU'])
return high_corr
high_corr_data = data_corr_analysis(train_data_number, sigmod=k)
def data_corr_choice(data,train_data_scale,high_corr_data):
high_corr_data_1=[]
target_var=pd.DataFrame(data.loc[:,target_col])
for i in range(high_corr_data.shape[0]):
for j in range(high_corr_data.shape[1]-1):
d1=pd.DataFrame(train_data_scale.loc[:,high_corr_data.iloc[i,j]])
data1=pd.concat([d1, data.loc[:,target_col]], axis=1, join='inner')
corr_data = data1.corr()
high_corr_data_1.append(corr_data.iloc[0,-1]) #输出的为各个变量与目标变量之间的相关关系
high_corr_data_2=np.array(high_corr_data_1).reshape(high_corr_data.shape[0],high_corr_data.shape[1]-1)
high_corr_data_2=pd.DataFrame(high_corr_data_2,columns=high_corr_data.columns[:-1])
del_var_cor=[]
for i in range(high_corr_data_2.shape[0]):
if abs(high_corr_data_2.iloc[i,0])>=abs(high_corr_data_2.iloc[i,1]):
del_var_cor.append(high_corr_data.iloc[i,1])
else:
del_var_cor.append(high_corr_data.iloc[i,0])
train_data_number_2.drop(del_var_cor,axis=1,inplace = True) #将强相关的变量直接剔除
return set(high_corr_data_1),set(del_var_cor),train_data_number_2
train_data_number_2 = pd.concat([train_data[variable_continuous],train_data[target_col]],axis=1)
high_corr_data_1,del_var_cor,train_data_scale = data_corr_choice(train_data_number_2,train_data_scale,high_corr_data)
train_data2 = train_data[:]
train_data2.drop(set(del_var_cor),axis=1,inplace = True)
return train_data2,del_var_cor
#相关性分析,去除高相关变量
scale_method = 'MaxMin'
target_col = 'IS_HARASS'
data_pos_5,del_var_cor = max_corr_feture_droped(data_pos_4,variable_continuous,k=0.8)
del_var_cor #删除的variable查看
特征重要性分析
def data_sample(data, target_col, smp):
'''
数据平衡
'''
data_1 = data[data[target_col] == 1].sample(frac=1)
data_0 = data[data[target_col] == 0].sample(n=len(data_1)*smp)
# data_1 = data_1.sample(len(data_2)*smp)
data = pd.concat([data_1, data_0]).reset_index()
return data
def train_test_spl(data):
'''
训练数据、测试数据切分
'''
X_train, X_test, y_train, y_test = train_test_split(
data[ipt_col], data[target_col], test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_test
定义特征重要性分析函数,并循环遍历获取最佳抽样比例
def feture_extracted(train_data, alpha):
'''
维度重要性判断
'''
global ipt_col
ipt_col= list(train_data.columns)
ipt_col.remove(target_col)
sample_present = [1,5] # 定义抽样比例
f1_score_list = []
model_dict = {
}
for i in sample_present:
try:
train_data = data_sample(train_data, target_col, smp=i)
except ValueError:
break
X_train, X_test, y_train, y_test = train_test_spl(train_data)
# 开始RF选取特征
model = RandomForestClassifier()
model = model.fit(X_train, y_train)
model_pred = model.predict(X_test)
f1_score = metrics.f1_score(y_test, model_pred)
f1_score_list.append(f1_score)
model_dict[i] = model
max_f1_index = f1_score_list.index(max(f1_score_list))
print('最优的抽样比例是:1:',sample_present[max_f1_index])
d = dict(zip(ipt_col, [float('%.3f' %i) for i in model_dict[sample_present[max_f1_index]].feature_importances_]))
f = zip(d.values(), d.keys())
importance_df = pd.DataFrame(sorted(f, reverse=True), columns=['importance', 'feture_name'])
list_imp = np.cumsum(importance_df['importance']).tolist()
for i, j in enumerate(list_imp):
if j >= alpha:
break
print('大于alpha的特征及重要性如下:\n',importance_df.iloc[0:i+1, :])
print('其特征如下:')
feture_selected = importance_df.iloc[0:i+1, 1].tolist()
print(feture_selected)
return feture_selected
#重要性检验,选择重要变量
data_pos_5_feture = feture_extracted(data_pos_5, alpha = 0.9)

模型训练
数据平衡
data_pos_6 = data_sample(data_pos_5, target_col, smp = 3)
正负样本拆分
def model_select(data, rf_feture, target_col ,test_size):
'''
正负样本拆分
'''
X_train, X_test, y_train, y_test = train_test_split(
data[rf_feture], data[target_col], test_size=test_size, random_state=42)
return X_train, X_test, y_train, y_test
#拆分比例7:3
X_train, X_test, y_train, y_test = model_select(data_pos_6,data_pos_5_feture,target_col,test_size=0.3)
定义模型函数
RF两个主要参数说明:
- min_samples_split:当对一个内部结点划分时,要求该结点上的最小样本数,默认为2;
- min_samples_leaf:设置叶子结点上的最小样本数,默认为1。当尝试划分一个结点时,只有划分后其左右分支上的样本个数不小于该参数指定的值时,才考虑将该结点划分,换句话说,当叶子结点上的样本数小于该参数指定的值时,则该叶子节点及其兄弟节点将被剪枝。在样本数据量较大时,可以考虑增大该值,提前结束树的生长。
def model_train(x_train, y_train, model):
'''
算法模型,默认为RF
'''
if model == 'RF':
res_model = RandomForestClassifier(min_samples_split = 50,min_samples_leaf = 50)
res_model = res_model.fit(x_train, y_train)
feature_importances = res_model.feature_importances_[1]
if model == 'LR':
res_model = LogisticRegression()
res_model = res_model.fit(x_train, y_train)
list_feature_importances = [x for x in res_model.coef_[0]]
list_index = list(x_train.columns)
feature_importances = pd.DataFrame(list_feature_importances, list_index)
else:
pass
return res_model, feature_importances
#训练模型
rf_model, feature_importances = model_train(X_train, y_train, model='RF') #也可以选择使用LR
模型验证
def model_predict(res_model, input_data, alpha ):
# 模型预测
# input_data: 输入新的无目标变量的数据
data_proba = pd.DataFrame(res_model.predict_proba(input_data).round(4))
data_proba.columns = ['neg', 'pos']
data_proba['res'] = data_proba['pos'].apply(lambda x: np.where(x >= alpha, 1, 0)) #将>0.5输出为正调整为1
return data_proba
def model_evaluate(y_true, y_pred):
y_true = np.array(y_true)
y_true.shape = (len(y_true),)
y_pred = np.array(y_pred)
y_pred.shape = (len(y_pred),)
print(metrics.classification_report(y_true, y_pred))
data_pos_6 = data_sample(data_pos_5, target_col, smp = 50)
X_train, X_test, y_train, y_test = model_select(data_pos_6,data_pos_5_feture,target_col,test_size=0.5)
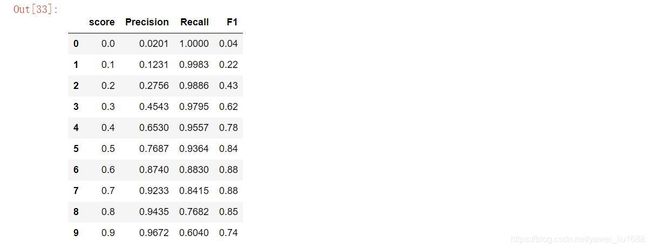
Precision = []
Recall = []
for alpha in np.arange(0, 1, 0.1):
y_pred_rf = model_predict(rf_model, X_test, alpha = alpha)
cnf_matrix = confusion_matrix(y_test, y_pred_rf['res'])
Precision.append((cnf_matrix[1,1]/(cnf_matrix[0,1] + cnf_matrix[1,1])).round(4))
Recall.append((cnf_matrix[1,1]/(cnf_matrix[1,0] + cnf_matrix[1,1])).round(4))
score = pd.DataFrame(np.arange(0, 1, 0.1),columns = ['score'])
Precision = pd.DataFrame(Precision,columns = ['Precision'])
Recall = pd.DataFrame(Recall,columns = ['Recall'])
Precision_Recall_F1 = pd.concat([score, Precision, Recall],axis = 1)
Precision_Recall_F1['F1'] = (2 * Precision_Recall_F1['Precision'] * Precision_Recall_F1['Recall'] / (Precision_Recall_F1['Precision'] + Precision_Recall_F1['Recall'])).round(2)
Precision_Recall_F1
模型封装保存
start = datetime.now()
joblib.dump(rf_model, 'model.dmp', compress=3)
print("模型保存所用时间: %s 秒" %(datetime.now() - start).seconds)
上述案例比较简单,没有过多涉及数据清洗及预处理,包括RF算法也只定义了两个参数,且没有参数的优化过程,感兴趣的可以在此基础上深入一下。