python+selenium 爬取微博(网页版)并解决账号密码登录、短信验证
使用python+selenium 爬取微博
- 前言
-
- 为什么爬网页版微博
- 为什么使用selenium
- 怎么模拟微博登录
- 一、事前准备
- 二、Selenium安装
-
- 关于selenium
- 安装步骤
- 三、selenium定位网页元素
-
- 基本方法
- 详细使用
- 最后、代码部分
-
- 首先,导入/安装包。
- 预处理
- 模拟登陆
- 短信验证
- 登录成功后开始爬取
- 运行结果
- 结语
前言
为什么爬网页版微博
网页端的微博比移动端的难爬一点,但是来网页端是因为这里可以使用高级搜索功能,它不同于普通搜索的是它可以选定发布时间和发布地点,把博文和这些爬下来可以用来做更多更全面的数据分析。
为什么使用selenium
去微博搜索某个关键词,会发现第一页的内容下拉到底后,微博会提示登录才能看到之后的页面的内容,点击登录之后它就会分页显示,最多显示到50页。
我一开始想着,那我只要分析微博的网址构造,然后用requests去打开后面页数的网址不就可以了?比如去用高级搜索功能搜索:
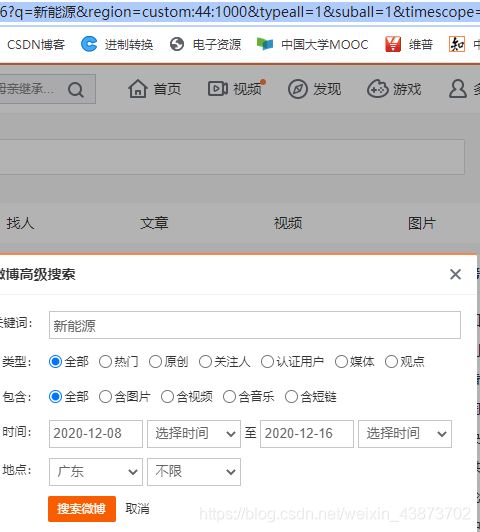
https://s.weibo.com/weibo/%25E6%2596%25B0%25E8%2583%25BD%25E6%25BA%2590%25E6%25B1%25BD%25E8%25BD%25A6%25E6%2594%25BF%25E7%25AD%2596?q=%E6%96%B0%E8%83%BD%E6%BA%90®ion=custom:44:1000&typeall=1&suball=1×cope=custom:2020-12-08:2020-12-16&Refer=g
这是上图的搜索结果的网址,不难发现:
q后面的是关键词(经过二次编码后变成了一长串的东西);
region=custom:XX:1000,这里的XX是省份的代码;
typeall=1&suball=1 ,这两是“类型”和“包含”选项;
timescope=custom:2020-12-08:2020-12-16就是时间段。
登录后查看第二页的网址:
https://s.weibo.com/weibo/%25E6%2596%25B0%25E8%2583%25BD%25E6%25BA%2590%25E6%25B1%25BD%25E8%25BD%25A6%25E6%2594%25BF%25E7%25AD%2596?q=%E6%96%B0%E8%83%BD%E6%BA%90®ion=custom:44:1000&typeall=1&suball=1×cope=custom:2020-12-08:2020-12-16&Refer=g&page=2
其他都相同,就最后多了个&page=2。然后看第三页也是&page=3。再然后再第一页的最后面页加个&page=1,也能正常打开。
至此,我们就找到了网址的构造规律了。
接下来,设置变量分别代表:搜索关键词、省份对应的数字(这个得自己打开微博一个个去试)、起始年、起始月、起始日、终点年、终点月、终点日、页码。
然后通过改变变量就可以访问所有相应的网页了。
(ps:因为怕50页显示不了太多,这里起始终止的年和月变量我就用同一个了)
index="小姐姐"
sheng=34
year=2020
month=1
day1=1
day2=30
page=1
url = "https://s.weibo.com/weibo?q={}®ion=custom:{}:1000&typeall=1&suball=1×cope=custom:{}-{}-{}:{}-{}-{}&Refer=g&page={}".format(index, sheng, year, month, day1, year, month, day2, page)
但是问题来了,发现爬虫只能爬下第一页的数据,第二页开始的都爬不了,为什么呢?这时你退出登录,然后再复制上面的第二页的网址去打开,你就发现打开不了,跳到了登录页面,微博还是要你登录才能访问之后的内容。
哦,所以现在我们需要去模拟微博登录。
怎么模拟微博登录
用selenium模拟浏览器操作。
网上的方法大多推荐用http请求、获取cookie这些,但说实话这些对新手不太友好。
selenium可能存在有一些缺点,但它也有它的优点,selenium做爬虫的好处就是简单直接(只需要知道简单的HTML和xpath的知识就够了),而且可以通过浏览器直接看到爬取的过程,出现错误很容易发现(这不比看pycharm下面一大串的报错信息强?)。
怎么操作详情往下看。
一、事前准备
谷歌浏览器、python3.7、pycharm(这些就先自己安装吧,这里就不给教程了)
二、Selenium安装
关于selenium
selenium是一个用于Web应用程序测试的工具,selenium测试直接运行再浏览器上,就像真正的用户在操作一样。(百度百科)
简单来说,selenium就是用来模拟用户操作浏览器。
安装步骤
- win+r,输入cmd,输入pip install selenium
- 下载ChromeDriver。
找到对应的浏览器、版本下载。
怎么查看谷歌浏览器的版本:打开谷歌浏览器,关闭按钮下面的三个点》帮助》关于Google Chrome,可以看到自己的版本。记下那串数字(比如我的是版本 87.0.4280.88)然后去下面的驱动下载网址找对应的就行。
Chrome驱动下载地址:http://npm.taobao.org/mirrors/chromedriver/


windows系统(不管你是32还是64位)就是这个win32的。

-
下载完成后,需要做两件事:
(1).将驱动放复制到浏览器根目录下;
找到谷歌浏览器快捷方式,右键,打开文件位置,把下载的文件夹里面的那个东西粘贴进来(注意不能直接把下载的文件夹放进来,要放里面的chromedriver,下面的第二步也一样)

(2).将驱动复制到Python根目录下。
可以打开pycharm,左边Project里面可以看到你的项目的路径,放那就行。

-
测试环境是否搭建成功
from selenium import webdriver
browser = webdriver.Chrome()
browser.set_window_size(1000,800)
browser.get('https://www.baidu.com/')
运行后可以看到新开一个浏览器窗口并在几秒内打开了百度
三、selenium定位网页元素
先学一下selenium的基本操作吧。(可以先简单看看)
基本方法
定位的方法有很多,这里主要用以下两种方式:
find_element_by_id 使用id定位元素
find_element_by_xpath 使用xpath定位元素
以上方法可以定位到网页的第一个符合该定位条件的元素,但我们写爬虫有时候需要定位这类的所有元素(比如爬取当前页面所以微博的文本内容),所以需要用下面的find_elements方法(加个s就行)。具体加不加s根据实际情况决定。
find_elements_by_id 使用id定位所有元素
find_elements_by_xpath 使用xpath定位所有元素
插一下我的启蒙教程:(up猪打钱!)
(1)https://www.bilibili.com/video/BV1Jx411Z7mX
(2)https://www.bilibili.com/video/BV1px411d7XY
观看建议:
上面的(1)是关于“Selenium安装及使用”,(2)是“登录效果实现”。
建议开1.5倍速看,里面还会介绍一下原理性的东西和一些废话,不喜欢的可以快进直到正式内容。
如果没看懂我上面的selenium安装和使用的可以去这里看看。
时间是第一个视频的第3分钟开始到第二个视频的第28分钟。
详细使用
from selenium import webdriver
browser = webdriver.Chrome()
browser.set_window_size(1000,800)
browser.get('https://www.baidu.com/')
运行上面的代码会打开百度的页面。这里一定要成功才能做后面的内容!
按F12打开开发者工具。点击那个小鼠标箭头,再点击百度的输入框,会定位到这个输入框的html元素。可以看到百度的输入框是一个input表单。
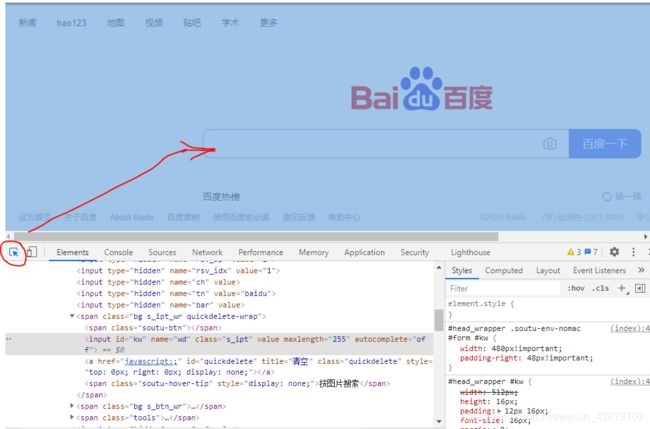
因为id属性一般是唯一性的(至少绝大部分网站是这样),所以我们找元素优先考虑find_elements_by_id。(如果没有id属性,再用find_elements_by_xpath)
同理,你也可以定位到百度一下的提交按钮。
下面分别是百度的输入框和百度一下按钮的html代码。
可以看到输入框的id属性是kw,按钮的id属性是su。
![]()
![]()
定位到了元素,然后需要对它进行操作,这里有两种:
(1)点击。 .click()方法
(2)写入。 .send_keys(str)方法
browser.find_element_by_id('kw').send_keys("小姐姐")
browser.find_element_by_id('su').click()
上面两行代码加上去,运行,发现打开浏览器后会自动输入内容并点击搜索按钮,之后我们就可以看到搜索内容了。
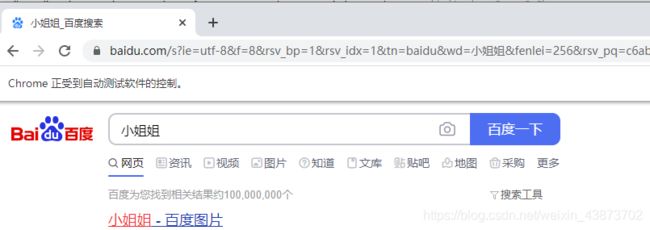
ps: xpath方法。以百度一下按钮为例。

input上一级是一个span标签,再上一级是form标签。
browser.find_element_by_xpath('//span[@class="bg s_btn_wr"]/input').click()
# browser.find_element_by_xpath('//form[@id="form"]/span[@class="bg s_btn_wr"]/input').click()
主要以下几种:
//元素名[@class=“xxxx”]/元素名
//元素名[@class=“xxxx”]/元素名[i] //第i个元素,从1开始
//元素名[@id=“xxxx”]/元素名
如果没指定元素的选择条件则是选择第一个同名的元素。
xpath的知识这不讲太多,实在不懂还可以去学习别的教程。比如:
Xpath教程
好,现在你已经学会selenium的基本操作了,接下来开始爬取微博吧。
最后、代码部分
ps:你只要把下面的代码按顺序合在一起就是完整的代码。
首先,导入/安装包。
import requests
from lxml import etree
import time
import socket
import csv
from selenium import webdriver
from configparser import ConfigParser
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
# coding=utf-8
一行一行的输入,看到有下划的曲线就说明该包未安装。
安装方法主要两种,一是打开命令行,输入pip install 包名。
二是直接在pycharm,左上角file菜单》setting》Project》Python Interpreter,可以看到已经安装的包,然后点击右边的小加号,输入包名,选中并点击install即可。
(虽然里面有些包可能这里用不到,但做爬虫的话很多以后都会用到的,现在装上也好)
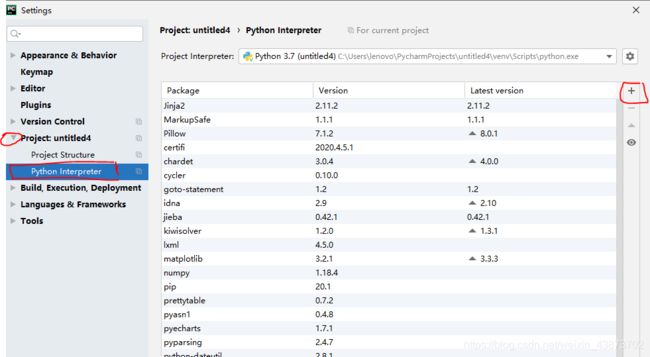
上面搜索框输入包名,之后点击install package,等它下载好会自动安装,安装好后会有提示,等一会或者不行就重启pycharm,如果看到下划的曲线消失就说明安装成功了。

预处理
首先我们只需要爬取文字,所以可以不加载图片加快本身偏慢的selenium的爬取速度。禁止图片和css加载会有警告信息,忽略即可。
如果有看不懂的也不怕,因为可以不用知道是什么意思,复制粘贴就行。(因为我也不知道hhhhh)
#禁止图片和css加载
chrome_options = webdriver.ChromeOptions()
prefs = {
"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 如果想加载图片,就把下面第二句话改第一句话,删掉上面的“禁止图片和css加载”部分
# wb = Chrome(options=option)
wb=webdriver.Chrome(options=chrome_options)
#最大化窗口、输入网址、等待至网页加载完成(防止元素还没加载出来就开始爬了这样自然爬不到数据。如果一直加载不出就等10秒,加载好了就立刻结束等待)
wb.maximize_window()
wb.get("https://s.weibo.com/weibo?q=小姐姐®ion=custom:44:1000&typeall=1&suball=1×cope=custom:2020-12-1:2020-12-7&Refer=g&page=1")
wb.implicitly_wait(10)
模拟登陆
思路很简单,定位到登录按钮、点击登录、定位到账号密码输入框、输入、定位到确认登录按钮并点击…下面都是这个做法。
再复习下怎么定位和操作:
(1)看这个元素有没有id属性,有就用 find_element_by_id
(2)没有id属性就用 find_element_by_xpath (看情况要不要在element后加s)
(3)定位到元素之后,点击,click()
(4)键盘输入内容,send_keys(xxxx)
最后要记得改一下下面代码前两行的账号和密码!
yonghu = '你的账号'
pwd = '你的密码'
# 点击登录、输入账号密码、点击确认登录
wb.find_element_by_xpath('//div[@class="gn_login"]/ul/li[last()]/a').click()
wb.find_element_by_xpath('//div[@class="item username input_wrap"]/input').send_keys(yonghu)
wb.find_element_by_xpath('//div[@class="item password input_wrap"]/input').send_keys(pwd)
wb.find_element_by_xpath('//div[@class="item_btn"]/a').click()
# 点击发送短信验证
wb.find_element_by_id('messageCheck').click()
短信验证
短信验证无非两种,方式一是点击,往你的手机发送六位验证码,然后你在pycharm里面输入,填入到页面,再点确定。(我因为试验的时候发了太多次验证码被限制了。。后面就只能用第二种了)
方式二,点击其他号码登录、填入你的号码(可以跟方式一里的同一个手机号),然后出现提示,要你发送指定内容到指定号码,你拿起手机去发送短信,发送完后在pycharm输入任意内容再按回车,表示你发完短信了,继续模拟提交。至此,登录成功。
# 方式一:输入六位验证码
# pycharm里输入6位验证码,并填入。 方式一我就做到这,感兴趣的可以补充完整
# 点击发送验证码、pycharm里输入验证码、填入六位验证码
# wb.find_element_by_id('message_sms_login').click()
# yanzheng=input("输入六位验证码:")
# for i in range(0,6):
# wb.find_element_by_xpath('//div[@class="num clearfix"]/input[{}]'.format(i+1)).send_keys("yanzheng[i]")
# 方式二:其他号码登录、填号码、下一步、提交
wb.find_element_by_id('toAddPhoneNum').click()
wb.find_element_by_id('AphoneNumber').send_keys(yonghu)
wb.find_element_by_id('addPhoneNext').click()
qqqqq=input("发送短信后任意输入:")
wb.find_element_by_id('mobileLogin').click()
#登录成功
登录成功后开始爬取
初始化变量。里面输出文件的路径可能需要改成你电脑的某个路径。
index="小姐姐"
sheng=44
year=2020
month=1
day1=1
day2=30
page=1
url = "https://s.weibo.com/weibo?q={}®ion=custom:{}:1000&typeall=1&suball=1×cope=custom:{}-{}-{}:{}-{}-{}&Refer=g&page={}".format(index, sheng, year, month, day1, year, month, day2, page)
wb.get(url)
#输入为csv文件的路径
outputExcel = r'C:\Users\lenovo\Desktop' + '\\' + 'python'
最后用循环语句开始爬内容吧。每爬完50页网csv文件写入一次(防止意外)
while循环是爬取某一年内每个月的内容。
for yeshu in range(1,51) 循环是爬取当前时间段50页的内容。
当然,循环条件你可以自己改。
在for循环里加入了try except语句处理异常。
把时间和博文内容分别保存到time2和textAll两个列表中。
while (month < 13):
# 发布时间的列表time2 ,博文的列表 textAll
time2 = []
textAll = []
flag = 0
# 爬取当前时间段全部页的内容
for yeshu in range(1, 51):
page = yeshu
try:
url = "https://s.weibo.com/weibo?q={}®ion=custom:{}:1000&typeall=1&suball=1×cope=custom:{}-{}-{}:{}-{}-{}&Refer=g&page={}".format(
index, sheng, year, month, day1, year, month, day2, page)
wb.get(url)
wb.implicitly_wait(2)
# 错误检测
try:
errorTxt = ""
merror = wb.find_element_by_xpath('//div[@class="card card-no-result s-pt20b40"]/p')
errorTxt = merror.text
# print(errorTxt)
if (errorTxt[0] == '抱' and errorTxt[1] == '歉'):
flag += 1
if (flag > 4):
break;
continue
except:
pass
# 爬取时间
time1 = wb.find_elements_by_xpath(
'//div[@class="card-feed"]/div[@class="content"]/p[@class="from"]/a[last()-1]')
for i in time1:
time2.append(i.text)
# 先点击所有的展开原文
temp = wb.find_elements_by_xpath(
'//div[@class="card-feed"]/div[@class="content"]/p[@node-type="feed_list_content"]/a[@action-type="fl_unfold"]')
for i in temp:
if (i.text[0] == "展" and i.text[1] == "开" and i.text[2] == "全"):
i.click()
texttp = wb.find_elements_by_xpath(
'//div[@class="card-feed"]/div[@class="content"]/p[@node-type="feed_list_content_full"]')
for i in texttp:
temp1 = ""
temp = i.text
for j in temp:
temp1 = temp1 + j
textAll.append(temp1)
# 如果没有展开全文按钮,就去没有展开全文按钮的段落爬
texttp = wb.find_elements_by_xpath(
'//div[@class="card-feed"]/div[@class="content"]/p[@node-type="feed_list_content"]')
for i in texttp:
temp1 = ""
temp = i.text
for j in temp:
temp1 = temp1 + j
# print("leng=",len(temp1),temp1)
if (len(temp1) > 0):
textAll.append(temp1)
time.sleep(1.1)
except:
continue
# 爬取完50页
# 导出csv文件
for a, b in zip(textAll, time2):
try:
print(a)
with open(outputExcel + '.csv', 'a', newline='') as f:
csvwriter = csv.writer(f, dialect='excel')
csvwriter.writerow([a, b])
except:
continue
time.sleep(2)
month+=1
day2=30
if(month==2):
day2=28
elif(month==1 or month==3 or month==5 or month==7 or month==8 or month==10 or month==12):
day2=31
else:
day2=30
运行结果
运行后每次保存到csv前打印出来查看

我运行了爬取一个月的结果。

结语
对你有帮助的话就点个赞吧。
有问题评论或者私信吧,看到了会回复。