谷歌colab“几键”运行图像超分辨率模型-ESRGAN,操作详解
文章目录
- 1. 准备工作(前提)
- 2.Colab常用操作
- 3. git clone 从github 克隆代码
- 4. 下载数据集(DIV2K)
- 5. 解压数据
- 6. 查看代码,运行改名rename.py代码
- 7. 剪切图片
- 8. 保存为tfrecord格式文件
- 9 . 预训练psnr_pretrain
- 10.模型存云盘与返复制回Google 服务器
-
- 10.1 模型保存
- 10.2 模型返复制到代码
- 11. 测试
- 12. 小结
1. 准备工作(前提)
-
特别声明:以下每一段代码:单独放在Google drive 每一个代码框。复制到框内,按照步骤,每步点击按钮即可跑通代码。
-
科学上网;
-
下载谷歌浏览器,打开google drive。详见笔者先前写的一个“菜”博客;
-
科学上网并登录Google drive ,界面如下:

-
挂载谷歌drive:简言之,挂载drive,有利于所有涉及到文件路径时,正常输入,代码运行不出错,【菜博客】有提及较详细的原因。
-
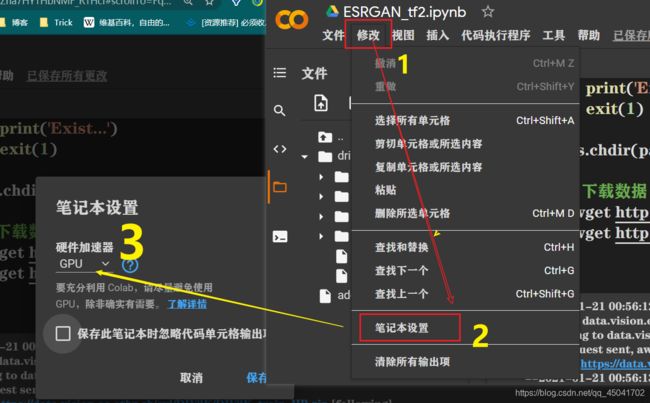
进入colab,设置为GPU状态(如图)(每天六个小时GPU时长)
-
打开Google drive,创建ipynb文件(如下图)后,代码:贴入
挂载代码如下:

!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={
creds.client_id} -secret={
creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {
vcode} | google-drive-ocamlfuse -headless -id={
creds.client_id} -secret={
creds.client_secret}
!mkdir -p drive
!google-drive-ocamlfuse -o nonempty drive
!rm -rf /content/sample_data
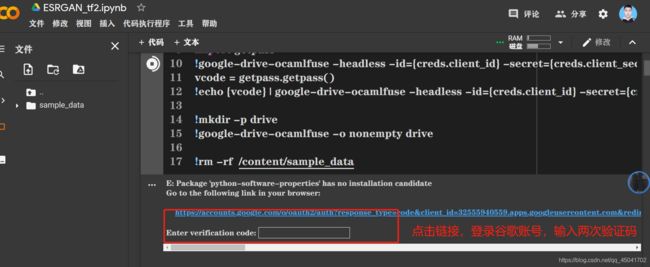
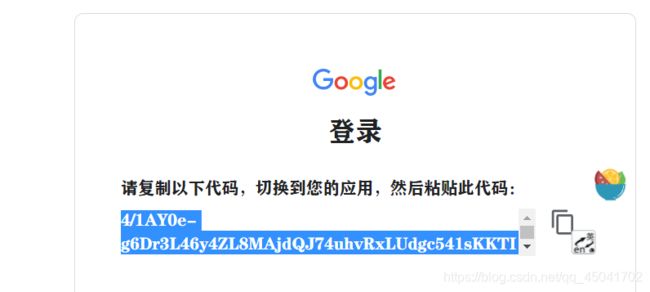
- 输入代码运行,弹出两次链接,分别点击进入,登录谷歌账号,获取验证号码,复制填入框中。
- 出现下图便正确:

挂载成功

2.Colab常用操作
- colab中没有切换路径的cd + path
- 只有: os.chdir()
import os
os.chdir('path')
其中的path,可以右点击鼠标挂载后的 Google drive 文件夹(如图)

drive下方很多文件是自己Google 15G云盘的文件。
- 举栗子:正确复制路径path。

- 凡是,在运行之前,需要添加(英文的惊叹号!)
3. git clone 从github 克隆代码
- 这里使用ESRGAN的代码来源。
- colab克隆并加载代码;
- TensorFlow2.X版本;
- 创建ESRGAN_tf2文件夹;
- 切记! os.chidir() 相当于cd ./切换路径。
- 切记! 上文提到的复制路径的方式:切换路径需要。
import os
# #in
path = '/content/ESRGAN_tf2' #在刚搭建搭载的Google drive 创建一个ESRGAN_tf2文件夹
if not os.path.exists(path):
os.makedirs(path)
else:
print('Exist...')
exit(1)
os.chdir(path)
path1 = '/content/ESRGAN_tf2/esrgan-tf2'
if not os.path.exists(path1):
!git clone https://github.com/peteryuX/esrgan-tf2.git
os.chdir(path1)
# os.chdir('/content/temp/esrgan-tf2')
#建立环境
# !pip install -r requirements.txt
#colab默认是tensorflow2.X框架,不用安装环境
4. 下载数据集(DIV2K)
- 电脑端导入数据,下载太慢,导入过程常断开;
- 以下方法,若不存在特定的文件夹,先创建一个文件夹,直接链接数据集网站,下载数据。
import os
path=('/content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K')
if not os.path.exists(path):
os.makedirs(path)
else:
print('Exist...')
exit(1)
os.chdir(path)
# 下载数据
!wget http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_HR.zip
!wget http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_LR_bicubic_X4.zip
5. 解压数据
- os.chdir()操作进入进入已经下载好的数据集文件夹内。
- 解压: !unzip xx.zip
- 解压文件完毕,前面压缩文件没有用处,删除以释放内存。
- 删除操作:!rm -rf path(路径)
import os
os.chdir('/content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K')
!unzip DIV2K_train_HR.zip
!unzip DIV2K_train_LR_bicubic_X4.zip
#删除下载的压缩包数据
os.chdir('/content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K')
!rm -rf /content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K/DIV2K_train_HR.zip
!rm -rf /content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K/DIV2K_train_LR_bicubic_X4.zip
6. 查看代码,运行改名rename.py代码
- 打开文件路径为:/content/ESRGAN_tf2/esrgan-tf2/data/rename.py;
- 如图:通常py文件需要双击文件,就能显示其中内容;

- rename.py:修改LR文件夹中的文件名与HR的一致

7. 剪切图片
- 由于DIV2K数据集中的每张图片都比较大,并且尺寸不一,需要对其切割。将其降切为480*120,一共有三万多张子图片。
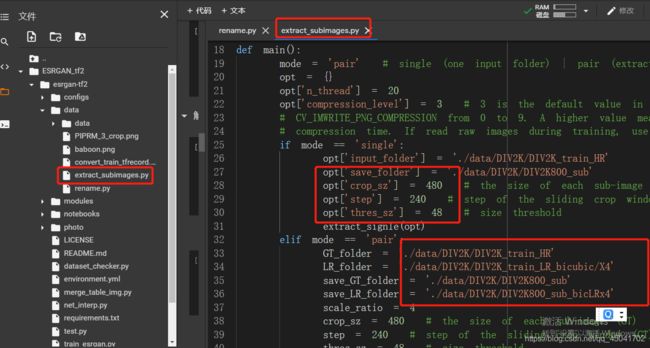
- 打开/content/ESRGAN_tf2/esrgan-tf2/data/extract_subimages.py
- 如下图:切割的参数。
- 运行文件的代码:
import os
#os.environ['CUDA_VISIBLE_DEVICES']='0'
os.chdir('/content/ESRGAN_tf2/esrgan-tf2/data')
!python extract_subimages.py
- 可以看到,切成32208对数据。
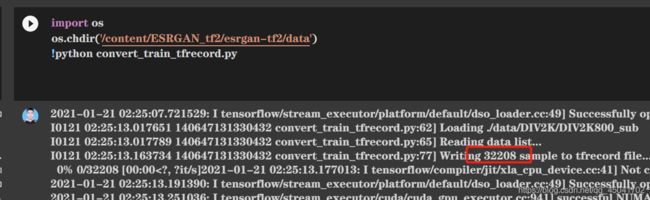
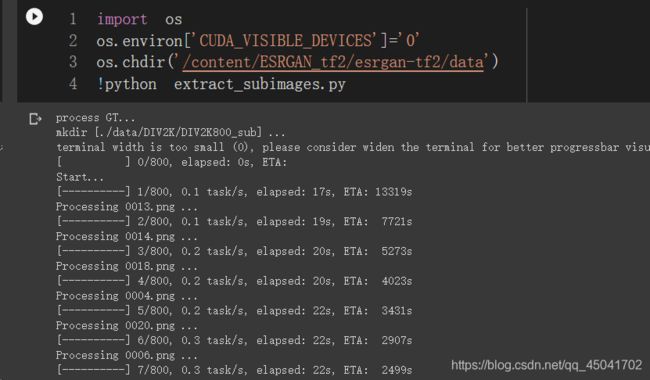
- 剪切完毕,为保持一定的容量,删除原始解压的文件
!rm -rf /content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K/DIV2K_train_HR
!rm -rf /content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K/DIV2K_train_LR_bicubic
8. 保存为tfrecord格式文件
- 改格式是TensorFlow框架中常用保存大型数据集的方式,加速数据的读取与运行,提高实验的效率。
- 运行data文件夹下的有关tfrecord的文件。
import os
os.chdir('/content/ESRGAN_tf2/esrgan-tf2/data')
!python convert_train_tfrecord.py

!rm -rf /content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K/DIV2K800_sub
!rm -rf /content/ESRGAN_tf2/esrgan-tf2/data/data/DIV2K/DIV2K800_sub_bicLRx4
- 生成tfrecord格式数据集之后,就可以删除掉之前的子文件。

9 . 预训练psnr_pretrain
- 预训练的目的:先生成精度较高的预训练模型,防止判别器训练初就能辨认出生成的图片。
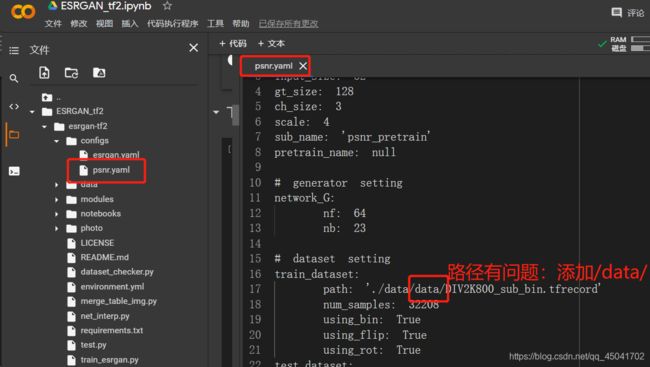
- 在预训练之前,在前面所有代码运行完毕,可以打开data文件夹中观看,因为前面代码在保存数据集前,路径不太一致,在data文件夹内,又创建一个data文件夹,如果直接运行psnr_pretrian.py文件,就会出错。
- 需要修改文件路径:打开configs文件夹下的psnr.yaml文件, 在训练路径添加:‘/data/’,添加之处,具体如图。后面的正式esrgan训练亦如是。
- 以上的工作准备好之后,开始预训练。
import os
os.chdir('/content/ESRGAN_tf2/esrgan-tf2')
!python train_psnr.py

- 以下都是分段(psnr训预训练)截图:
- 开端显示的是:GPU的信息。
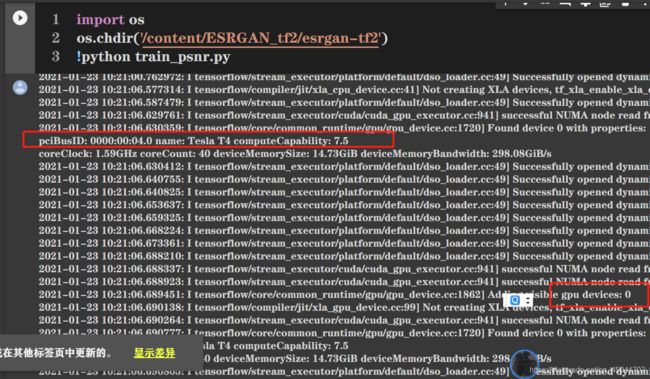
- 其次:ESRGAN模型中的密集残差连接模块(RRDB)的参数:

- 下图为模型的参数量,加载的tfrecord数据名称为:DIV2K;低分图片尺寸为3232,SR图片经过超分辨率重建为:128128,与HR原始剪切的图片尺寸一致。

- 训练过程显示:

10.模型存云盘与返复制回Google 服务器
- 先验知识:复制文件
import shutil
shutil.copytree('original_path' , 'destination_path')
- 通常,目的地文件夹路径不用事先建立,代码模块已经包含建立文件夹命令。,如果不行,自己根据自己的15G网盘,建立一个文件夹以保存即可。
10.1 模型保存
- 原因:目前所有的运行模型,数据都是在Google 云服务器上,如果重新加载,Google 服务器端就会清空,所有数据都会消失。
- 从configs文件夹中的yaml文件,可以看出,5000 steps = 1个epoch,设置steps=1000000,即预训练需要跑200个epochs.
- 囿于Google drive每天只有六个小时的gpu时长,不可能一次run 完毕。
- 解决方法:通常运行4个epochs(20000steps),就断开运行保存模型到自己的Google 云盘(15G)上,等下次有GPU时长,再复制回来,继续运行模型(模型代码中有断点继续训练的命令)。并且,在除了第一次复制保存模型以外,在往后复制模型到云盘前,先删除前一次存储的模型,相当于删除覆盖此外,这样操作的原因,是云盘本身内存有限。(详见代码)
import shutil, os
os.chdir('/content/ESRGAN_tf2/esrgan-tf2/checkpoints')
!rm -rf /content/drive/Experiment/ESRGAN_tf2/pre_checkpoint
shutil.copytree('/content/ESRGAN_tf2/esrgan-tf2/checkpoints','/content/drive/Experiment/ESRGAN_tf2/pre_checkpoint') #pre_checkpoint 复制的目的文件,可以不用事先建立,命令可以自动建立。
os.chdir('/content/ESRGAN_tf2/esrgan-tf2/logs')
!rm -rf /content/drive/Experiment/ESRGAN_tf2/tf2_logs
shutil.copytree('/content/ESRGAN_tf2/esrgan-tf2/logs','/content/drive/Experiment/ESRGAN_tf2/tf2_logs')
- !!再次强调上述代码:有‘!rm -rf ’ 行要先注释掉,第一次复制保存,下次运行代码,产生新的模型,再取消有!rm -rf 行,这样在当次模型的时候,会事先删除前一次的模型。

10.2 模型返复制到代码
- 前提:已有保存部分模型,次日有充足GPU时长。
- 首先,预先已经运行1-8步骤的过程(数据准备);
- 其次,从上次保存的模型文件夹,返复制模型到1-8过程已经下载好的代码中去,返复制代码,和10.1过程相反,如下。
import os,shutil
os.chdir('/content/drive/Experiment/ESRGAN_tf2/pre_checkpoint')
shutil.copytree('/content/drive/Experiment/ESRGAN_tf2/pre_checkpoint','/content/ESRGAN_tf2/esrgan-tf2/checkpoints')
os.chdir('/content/drive/Experiment/ESRGAN_tf2/tf2_logs')
shutil.copytree('/content/drive/Experiment/ESRGAN_tf2/tf2_logs','/content/ESRGAN_tf2/esrgan-tf2/logs')
11. 测试
- 运行代码中的test.py
- test.py可以运行psnr预训练过程ckpt,也可以运行正式训练的ESRGAN过程生成的模型ckpt。生成图片,查看效果图,以及相应的评判标准PSNR,SSIM。
- 只需要修改test.py中的yaml路径,预训练时,改为psnr.yaml,测试正式训练的模型,就改为:esrgan.yaml
os.chdir('/content/ESRGAN_tf2/esrgan-tf2')
!python test.py
12. 小结
- 登录谷歌、云盘,创建自己的ipynb文件
- 分步骤,复制以上代码。
- 注意在configs文件夹中的yaml文件,更改路径(在路径处的代码,再添加 '/data/ ')
- 如果是第一次,就直接保存模型到云盘,如果非首次,就先返复制到代码中,运行即可。GPU时长有限的举动。