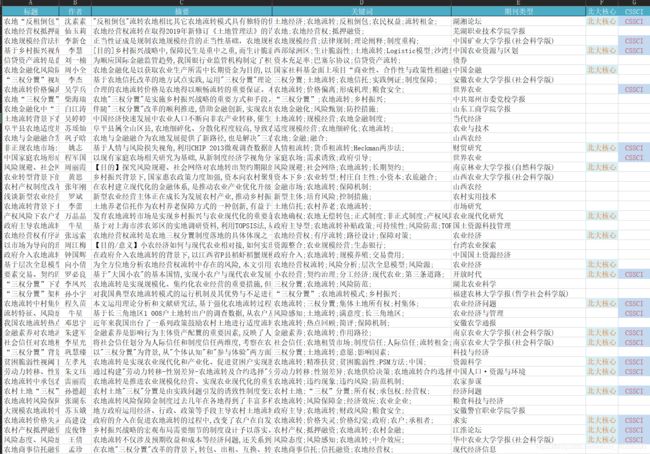
知网关键词搜索爬取摘要信息
知网关键词搜索爬取摘要信息
由于技术不成熟,代码冗余度较高。同时代码也可能会存在错误,也请各路高人指正。
本篇文章应用范围为期刊搜索(不包括外文文献),其他内容,没有进行测试!!!
本次爬虫所采用到的技术:
- selenium自动化
- 正则表达式匹配文本字符串
- xpath查询标签位置
- pandas导出excel
- requests发起请求
第一部分,获取详情页内容链接,并存入本地文件。
第一步,分析知网搜索页。本次我们以两个关键词为例(‘农地流转’,风险),通过selenium模拟浏览器动作进行列表页的访问。
- 我们找到知网高级检索页面(我用的是旧版入口)
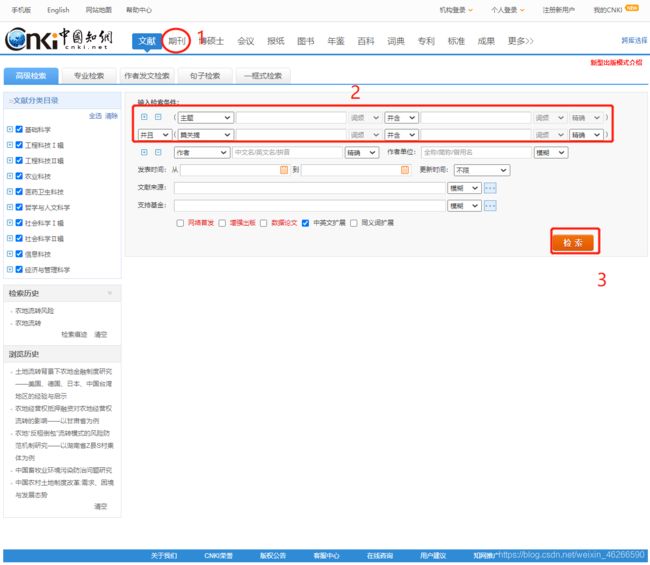
- 我们通过selenium完成输入点击的过程。有关xpath内容不详细展开。
# 选择期刊板块
qikan = tb.find_elements_by_xpath('//*[@id="CJFQ"]/a')[0] # 寻找
qikan.click() # 点击期刊
sleep(1.5)
# 输入关键词
keywords1 = tb.find_element_by_id('txt_1_value1') # 寻找第一个关键词输入框
keywords2 = tb.find_element_by_id("txt_1_value2") # 寻找第二个关键词输入框
keywords1.send_keys("农地流转") # 传值
keywords2.send_keys("风险") # 传值
btn1 = tb.find_element_by_id("btnSearch") # 寻找检索按钮
btn1.click() # 点击检索
sleep(1.5)
- 完成检索之后,我们可以看到这样的页面

- 接下来我们需要点击使一页能够显示50条项目。
需要注意选择展示项目数量的代码在iframe标签中,因此需要重新进行定位。

# 我们发现知网的列表内容是嵌入在iframe标签下的,因此要将目标定位到iframe标签内
tb.switch_to.frame('iframeResult') # iframe的id
page_text = tb.page_source # 获取页面内容
tree1 = etree.HTML(page_text) # etree对象
sleep(1.5)
# 设置每页显示五十页,跳转到新的url
fifty_url=tree1.xpath('//*[@id="id_grid_display_num"]/a[3]/@href')[0] # 我们设置每页显示50个,有利于快速获取
new_url = 'https://kns.cnki.net'+fifty_url # 在selenium中,访问50页会跳往新的页面(因为这里我们是get一个新的url,正常访问知网是不会跳页面的)
tb.get(new_url) # 跳转
sleep(1.5)
page_text = tb.page_source # 获取当前页面所有内容
第二步,然后你就会看到这样一个页面,我们所有的爬取操作都是基于这一页面而进行的。

点击标题能够进入到最终的详情页,因此我们只需要获得每个标题的a链接并多次翻页就可以喽!
- 获取标题链接的xpath:
content = tree2.xpath('//*[@id="ctl00"]/table/tbody/tr[2]/td/table/tbody//tr/td[2]/a/@href')
- 找到下一页按钮,复制xpath路径。
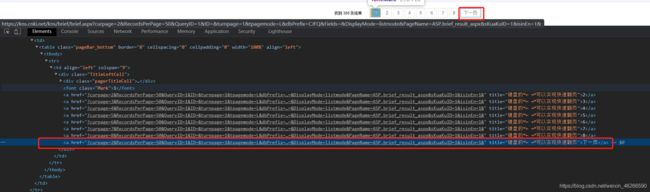
next_src = tree2.xpath('//*[@id="ctl00"]/table/tbody/tr[3]/td/table/tbody/tr/td/div/a[last()]/@href')[0]
next_url = "https://kns.cnki.net/kns/brief/brief.aspx"+next_src
tb.get(next_url) # 跳转到下一页
page_text = tb.page_source # 获取下一页的页面内容
第三步,这样以来,你的selenium会以很快的速度跳转页面并获取内容,最终把所有的链接存入本地文件当中。
- 全部代码:
from selenium import webdriver
from time import sleep
from lxml import etree
from 其他文件.知网url正则匹配 import get_detail
tb = webdriver.Chrome(executable_path="E:\Anaconda3\chromedriver.exe")
tb.get("https://kns.cnki.net/kns/brief/result.aspx?dbprefix=SCDB&crossDbcodes=CJFQ,CDFD,CMFD,CPFD,IPFD,CCND,CCJD")
# 选择期刊板块
qikan = tb.find_elements_by_xpath('//*[@id="CJFQ"]/a')[0] # 寻找
qikan.click() # 点击期刊
sleep(1.5)
# 输入关键词
keywords1 = tb.find_element_by_id('txt_1_value1') # 寻找第一个关键词输入框
keywords2 = tb.find_element_by_id("txt_1_value2") # 寻找第二个关键词输入框
keywords1.send_keys("农地流转") # 传值
keywords2.send_keys("风险") # 传值
btn1 = tb.find_element_by_id("btnSearch") # 寻找检索按钮
btn1.click() # 点击检索
sleep(1.5)
# 我们发现知网的列表内容是嵌入在iframe标签下的,因此要将目标定位到iframe标签内
tb.switch_to.frame('iframeResult') # iframe的id
page_text = tb.page_source # 获取页面内容
tree1 = etree.HTML(page_text) # etree对象
sleep(1.5)
# 设置每页显示五十页,跳转到新的url
fifty_url=tree1.xpath('//*[@id="id_grid_display_num"]/a[3]/@href')[0] # 我们设置每页显示50个,有利于快速获取
new_url = 'https://kns.cnki.net'+fifty_url # 在selenium中,访问50页会跳往新的页面(因为这里我们是get一个新的url,正常访问知网是不会跳页面的)
tb.get(new_url) # 跳转
sleep(1.5)
page_text = tb.page_source # 获取当前页面所有内容
fp = open("农地流转.txt",'a',encoding="utf8") # 打开存储文件
# 设置读取10页的内容
for i in range(10):
tree2= etree.HTML(page_text) # etree对象
# 使用xpath获取列表页链接信息(通过标题链接,我们能最终访问到详情页)并存入文件
content = tree2.xpath('//*[@id="ctl00"]/table/tbody/tr[2]/td/table/tbody//tr/td[2]/a/@href')
for index,j in enumerate(content,start=1):
print(index*(i+1),j) # 这里不用看,只是为了方便看爬下来的信息,使用时正常for循环就可以
# 这里是不是看不大懂,为什么要调用一个函数,嘿嘿,等会你就知道了
res = get_detail(j) # 调用正则表达式,本人正则极其没有天赋,不要嘲笑我。
fp.write(res+'\n') # 写入
# 换页(找到下一页按钮的位置,我们选择div下的最后一个a标签,获取其链接)
next_src = tree2.xpath('//*[@id="ctl00"]/table/tbody/tr[3]/td/table/tbody/tr/td/div/a[last()]/@href')[0]
next_url = "https://kns.cnki.net/kns/brief/brief.aspx"+next_src
tb.get(next_url) # 跳转到下一页
page_text = tb.page_source # 获取下一页的页面内容
sleep(2000) # 等待时间
fp.close() # 关闭文件
tb.quit() # 关闭selenium
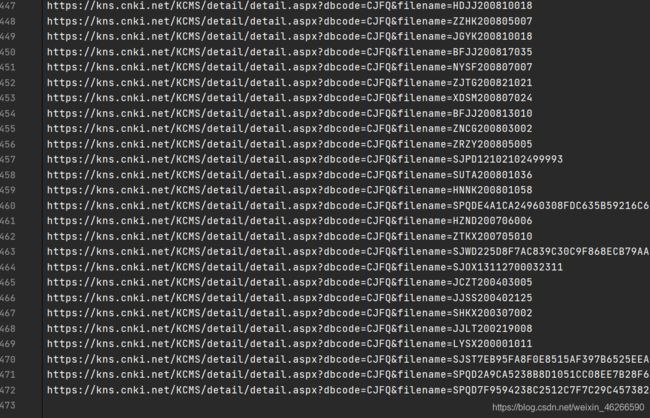
注意:第四步,我兴高采烈地打开文件,发现,爬取下来的链接根本进不去,我们比对一下原链接和我们爬取到的链接:
我们的:/kns/detail/detail.aspx?QueryID=0&CurRec=1&DbCode=CJFD&dbname=CJFDAUTO&filename=HXLT202101012&urlid=&yx=
原链接:https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CJFD&dbname=CJFDAUTO&filename=HXLT202101012&v=MDE0MDdTN0RoMVQzcVRyV00xRnJDVVI3dWZadVJyRnl2a1Y3dk5MVFhIZXJHNEhORE1ybzlFWm9SOGVYMUx1eFk=
很奇怪,为什么标题点进去变成了另外一个链接。其实仔细对比这两个链接,好像都有dbcode,dbname参数,filename好像也有。于是我就在原链接试了试,发现去掉dbname,以及后面的v=…,好像也可以进去。
因此,我们可以将原链接转化为:
https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CJFQ&filename=HXLT202101012
这样以来,我们就只需要知道filename就可以了。至于dbcode,我试了试,好像没有什么影响。因此只需要用正则表达式把我们爬取到的链接的filename拿到就可以了。
- 附上代码(真的很low):
def get_detail(test_url):
t1 = re.search('filename',test_url,re.I)
t2 = test_url.split(t1.group(0))[-1]
c = re.match(r'\W(.*?)\W',t2,re.I)
filename = c.group(0).strip('&')
detail_url = base_url + filename
print(detail_url)
return detail_url
至此,我们已经获取到了所有的内容。如下:(链接较长的,应该为外文文献,无法访问)
第二部分,开始详情页内容爬取
1. 毋庸置疑,我们现在已经存储的链接是直接可以访问的,因此不用担心请求方式的问题。
所以,直接上代码。

import requests
import time
from lxml import etree
import pandas as pd
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0',
}
start_time = time.time() # 开始时间
def get_detail(url,df_all):
global count
print("正在尝试第%d篇......"%(count+1))
try: # 处理外文文献报错
# time.sleep(2)
response = requests.get(url=url,headers=headers) # 发起请求
tree = etree.HTML(response.content) # 获取二进制信息
title = tree.xpath('/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h1/text()')[0] # 标题
author = tree.xpath('//*[@id="authorpart"]//text()')[0] # 作者
abstract = tree.xpath('//*[@id="ChDivSummary"]/text()')[0] # 摘要
keywords = tree.xpath("/html/body/div[2]/div[1]/div[3]/div/div/div[5]/p//text()") # 关键词
journal = tree.xpath('/html/body/div[2]/div[1]/div[3]/div/div/div[1]/div[1]/span/a[1]/text()')[0] # 期刊
hasPeking = tree.xpath('/html/body/div[2]/div[1]/div[3]/div/div/div[1]/div[1]/a[1]/text()') # 是否北大核心
hasCSSCI = tree.xpath('/html/body/div[2]/div[1]/div[3]/div/div/div[1]/div[1]/a[2]/text()') # 是否CSSCI
# 由于某些原因,不大会写逻辑,因此判断是否是北大核心以及CSSCI有点复杂
isPeking_true = ""
isCSSCI_true = ""
if hasPeking and hasPeking[0] == "北大核心":
isPeking_true = hasPeking[0]
elif hasPeking and hasPeking[0] == "CSSCI":
isCSSCI_true = hasPeking[0]
hasPeking[0] = ""
else:
isPeking_true = " "
if isCSSCI_true == '' and hasCSSCI:
isCSSCI_true = hasCSSCI[0]
keyword = ""
for item in keywords:
keyword += item.strip()
df = pd.DataFrame({
'标题': title,
'作者': author,
'摘要': abstract,
'关键词': keyword,
'期刊类型': journal,
'北大核心': isPeking_true,
'CSSCI': isCSSCI_true,
}, index=[0])
df_all = df_all.append(df, ignore_index=True)
print("sucess")
# time.sleep(1)
count+=1
except:
print("无法访问!")
return df_all
with open("农地流转.txt",'r') as f:
url_list = f.readlines()
df_all = pd.DataFrame()
count = 0
for i in url_list[:150]:
df_all = get_detail(i,df_all)
df_all.to_excel('demo1.xlsx', index=False) # 导出excel
print("成功获取%d篇论文,耗时%ds"%(count,time.time()-start_time))
![]()
- 最终成果展示: