2019独角兽企业重金招聘Python工程师标准>>> 
项目githup地址
项目的目的
- 爬取链家楼盘数据
- 数据可视化分析
工具
- python3
- scrapy
创建项目
scrapy安装及使用可以参考教程scrapy,在pycharm软件的Terminal上操作:scrapy startproject scrapys 生成的目录如下: 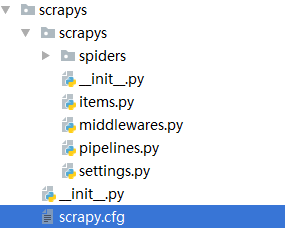
项目创建好了,下一步分析网页数据
爬取数据
- 打开主网页
打开链家官网,设定城市,以广州新楼盘为例‘https://gz.fang.lianjia.com/loupan/’ 网站类似如下:

当然可以爬取更多城市的数据,url中gz改为城市代码即可,可以设置城市列表自动来爬取各个城市数据。
- 需求字段
网页中我们能看到楼盘列表,并且含有很多页,每页大概10个楼盘,每个楼盘包含的信息有(名称、房屋类型、地点、面积、均价、总价、标签等),我们选定爬取的字段有: 楼盘名称、房屋类型、面积、均价、总价、标签,6个字段数据。
在项目items.py文件中添加字段类:
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
type = scrapy.Field()
area_range = scrapy.Field()
start_price = scrapy.Field()
mean_price = scrapy.Field()
tags = scrapy.Field()
- 网页分析
按F12进入页面代码分析,点击元素选择图标->在选择左边需要的字段信息,在代码区就能看到所在的位置,如下图:
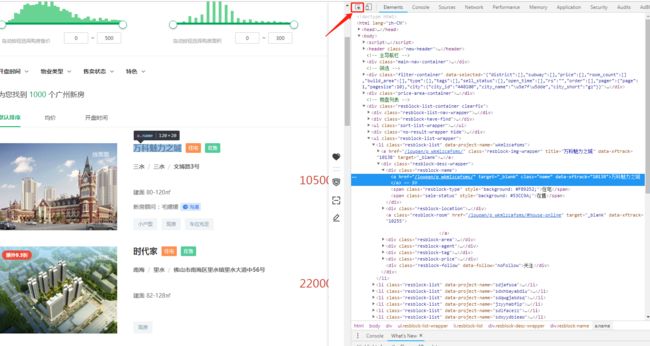
也可以ctrl+f在输入框中搜索,或用xpath获取需要的信息,框中用输入//div[@class="resblock-name"]也能看到有10条信息。
各个字段的位置信息如下:
总路径:'//ul[@class="resblock-list-wrapper"]/li'
name :'div/div[@class="resblock-name"]/a[@class="name"]/text()'
type :'div/div[@class="resblock-name"]/span[@class="resblock-type"]/text()'
area_range :'div/div[@class="resblock-area"]/span/text()'
mean_price :'div/div[@class="resblock-price"]/div[@class="main-price"]/span[@class="number"]/text()'
mean_unit :'div/div[@class="resblock-price"]/div[@class="main-price"]/span[@class="desc"]/text()'
start_price :'div/div[@class="resblock-price"]/div[@class="second"]/text()'
tags :'div/div[@class="resblock-tag"]/span/text()'
- 数据爬取程序
分析好了数据获取路径,我们开始构建爬虫程序。 我们在spiders文件夹下新建一个爬虫脚本lianjia_spider.py:
import re
import scrapy
from scrapy.http import Request
from scrapys.items import LianjiaItem
# scrapy用yield异步处理网页,想顺序处理网页,可以参考https://stackoverflow.com/questions/6566322/scrapy-crawl-urls-in-order
class LJ_houseSpider(scrapy.Spider):
name = "lianjia"
allowed_domains = ["gz.fang.lianjia.com"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
"http://gz.fang.lianjia.com/loupan/"
]
def start_requests(self):
"""
这是一个重载函数,它的作用是发出第一个Request请求
:return:
"""
# 请求self.start_urls[0],返回的response会被送到回调函数parse中
yield Request(self.start_urls[0])
def parse(self, response):
max_page_text = response.xpath('//div[@class="page-box"]/@data-total-count').extract()
nums = re.findall(r'(\d+)',max_page_text[0])
max_num = int(nums[0])
max_num //= 10
print('max page>>>>>>>>>>>',max_num)
for i in range(max_num):
print(i)
url = self.start_urls[0]+'pg'+str(i+1)
yield Request(url, callback=self.extract_content, priority=max_num-i) #该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象
def extract_content(self, response):
paths = response.xpath('//ul[@class="resblock-list-wrapper"]/li')
items = []
for sel in paths:
item = LianjiaItem()
name = sel.xpath('div/div[@class="resblock-name"]/a[@class="name"]/text()').extract()
type = sel.xpath('div/div[@class="resblock-name"]/span[@class="resblock-type"]/text()').extract()
area_range = sel.xpath('div/div[@class="resblock-area"]/span/text()').extract()
mean_price = sel.xpath('div/div[@class="resblock-price"]/div[@class="main-price"]/span[@class="number"]/text()').extract()
mean_unit = sel.xpath('div/div[@class="resblock-price"]/div[@class="main-price"]/span[@class="desc"]/text()').extract()
start_price = sel.xpath('div/div[@class="resblock-price"]/div[@class="second"]/text()').extract()
tags = sel.xpath('div/div[@class="resblock-tag"]/span/text()').extract()
item['name'] = name[0] if name else 'NAN'
item['type'] = type[0] if type else 'NAN'
item['area_range'] = re.findall(r'\d+',area_range[0])+re.findall(r'-[\d+](.)+',area_range[0]) if area_range else []
item['mean_price'] = mean_price[0] +' '+ ' '.join(re.findall(r'\w[/]\w',mean_unit[0])) if mean_price and mean_unit else 'NAN'
item['start_price'] = re.findall(r'\d+',start_price[0])+re.findall(r'[\d+](.)+[/]',start_price[0]) if start_price else []
item['tags'] = tags
items.append(item)
return items
- 数据存储到excel
将数据存储于excel文件中,在主目录下新建一个存数据的文件夹results;修改pipelines.py如下
import xlwt
class ScrapysPipeline(object):
def process_item(self, item, spider):
return item
class LianJiaPipeline(object):
def __init__(self):
self.filename = 'results/tianjing_houses.xls'
self.outputbook = xlwt.Workbook()
self.table = self.outputbook.add_sheet('sheet1', cell_overwrite_ok=True)
self.nrow = 0
def process_item(self, item, spider):
self.table.write(self.nrow, 0, item['name'])
self.table.write(self.nrow, 1, item['type'])
self.table.write(self.nrow, 2, ' '.join(item['area_range']))
self.table.write(self.nrow, 3, item['mean_price'])
self.table.write(self.nrow, 4, ' '.join(item['start_price']))
self.table.write(self.nrow, 5, ' '.join(item['tags']))
self.nrow += 1
def close_spider(self, spider):
self.outputbook.save(self.filename)
- 运行爬虫
在命令行输入scrapy crawl lianjia 或者通过pycharm来运行,在主目录建文件main.py:
#coding=utf8
from scrapy import cmdline
cmdline.execute("scrapy crawl lianjia".split())
点击运行,结果如下: 
数据可视化
(待续...)