ZooKeeper原理及编程应用
一、ZooKeeper概述
1.1 什么是zookeeper?**
zookeeper是一个开源的、分布式的,为分布式系统提供协调管理服务的开源软件。
1、CAP原则
CAP原则包括:一致性、可用性、分区容错性。
1) 一致性:强一致性(如银行取钱,要么成功,要么失败),最终一致性。
2) 可用性:合理的时间内得到合理的结果。
3) 分区容错性:每个区域依然能够对外提供可用性以及一致性的服务。
图1 分布式系统示例

上图示为一个分布式系统,其中A、B为访问节点;CDE为上海区域对外提供服务的节点,FG为深圳区域对外提供服务的节点。
图1 CAP原则体现如下:
1)一致性:B在C点修改了密码,然后再F使用新的密码可以登陆成功。
2)A在C连接,C宕机了,A再次连接分布式系统时可以连接上(G),即一个节点宕机不影响系统的正常功能提供。
3)分区容错性:上海机房和深圳机房的网络不通,依然可以给AB提供一致性和容错性。
CAP原则:保二弃一,一般分区容错性会保留,其他两者二选一。
1) 对于redis,满足AP,主要解决的问题是:单点故障,高可用。
2) 对于zookeeper,满足CP。
2、base理论
核心思想:分布式系统中即使无法做到强一致性,采用适当的方式让分布式系统达到最终一致性。
base:基本可用(ba)、弱状态(s)、最终一致性(e)。
1)基本可用:响应时间&功能。
2)弱状态:允许同步的延迟。
3)最终一致性:数据最终一致。
1.2 为什么需要zookeeper?
在分布式系统中,有大量的微服务协同对外提供服务,这时需一个稳定的安全的协调管理工具,负责管理和协调这些微服务。
二、ZooKeeper工作机制
2.1 数据存储+监听通知
ZooKeeper的工作机制为:数据存储+监听通知机制。
其中,数据存储采用类似Unix文件系统形式以及KV方式进行存储;监听通知机制是指zookeeper通过存储和管理关键数据,接受分布式系统中的节点来注册监听关键数据的变化,当关键数据发生变化,zookeeper将会通知那些注册了数据变化的节点。
图2 zookeeper数据存储结构

图3 zookeeper集群示图

图3监听机制举例:
node1启动的时候往zk集群里创建节点 /node/node1,值为gate1.
node2启动的时候往zk集群里创建节点 /node/node2,值为gate2.
Node3监听节点,假设node2宕机掉线了,node3就可以接收到node2宕机的数据。
2.2 节点类型
zookeeper中节点类型包括:持久节点,持久顺序节点,临时节点和临时顺序节点。
1、持久节点
该数据节点被创建后,就会一直存在zookeeper上,直到删除操作主动清除这个节点。
2、持久顺序节点
每个父节点都为它的第一级子节点维护一份顺序,用于记录每个子节点创建的先后顺序(为给定节点名加上一个数字的后缀,这个数字后缀最大值为整形的最大值)。
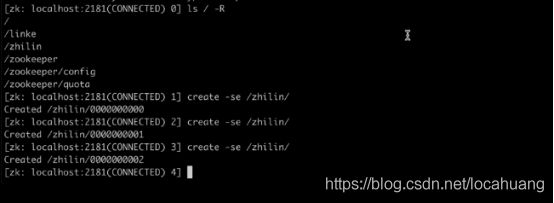
3、临时节点
临时节点的生命周期和客户端的会话绑定在一起,如果客户端会话失效,这个节点会被自动清除;临时节点不能创建子节点,只能作为叶子节点。
4、临时顺序节点
在临时节点的基础上添加顺序特性。
2.3 节点的stat属性
- czxid 节点被创建时的事务id
- mzxid 节点最后一次被更新时的事务id
- ctime 节点被创建的时间
- mtime 节点最后⼀次被更新的时间
- version 节点的版本号
- cversion 子节点的版本号
- aversion 节点acl版本号
- ephemeralOwner 创建该临时节点的会话的sessionID,如果是持久节点该值为0
- dataLength 数据内容的长度
- numChildren 当前节点的子节点个数
- pzxid 该节点的⼦节点列表最后一次被修改时的事务id。子节点列表变更才会修改该值,子节点内容变更不会修改该值
三、ZooKeeper原理
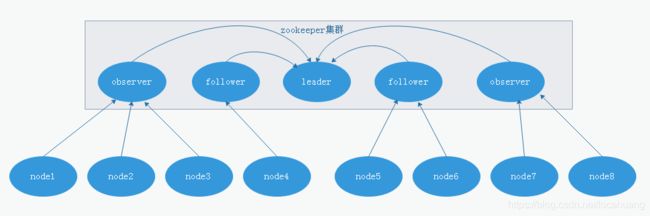
3.1 角色介绍
1、leader
事务请求的唯一调度和处理者,保证集群事务处理的顺序性。
集群内部各节点的调度者。
2、follower
处理客户端非事务请求,转发事务请求给leader服务器。
参数事务请求proposal(提案)投票。
参与leader选举投票。
3、observer
只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
3.2 数据存储
数据存储包括内存数据存储和磁盘数据存储;磁盘数据包括事务日志和快照数据。
3.3 更新同步流程

- 分布式中的节点发起事务请求。
- a.如果是leader,将事务请求转化为事务提案,同时为每个提案生成全局的zxid;
b.如果是learner,先将事务请求转发给leader, leader再将事务请求转化为事务提案,同时为每个提案生成全局的zxid; - leader将需要⼴播的提案依次放到FIFO队列中,然后会按照顺序发送;
- follower接收到提案后,会将其以事务日志的方式写入本地磁盘,写入成功后,向leader发送一个ack回应包;
- leader收到超过半数以上follower的ack响应后,即认为发送成功,可以发送commit消息;
- leader向所有follower广播commit消息,同时自身也完成事务提交; follower接收到commit后,执行事务操作。
3.4 初始化同步流程
初始化同步包括两种情况,启动选举leader以及leader崩溃:
1、 投票选举出leader,根据两个要素来决定谁是leader
2、进行数据同步。有两种情况:
a. 事务在leader上提交了,过半的follower都响应ack了,但是在commit消息发出前挂了;
b. 事务在leader生成后, leader就挂了。
需要保证:
a. 新选举出来的leader不能包含未提交的提案;
b. 新选举的leader中含有最大的zxid;
问题 zookeeper集群采用的是奇数个节点,还是偶数个节点?为什么?
采用的是奇数个节点。因为zookeeper采用的是过半选举策略(n/2+1)。
如果采用偶数4,那么要满足4/2+1=3,这样只允许分布式系统4-3=1个节点出现问题。
如果采用奇数5,那么要满足5/2+1=3,这样允许分布式系统5-3=2个节点出现问题。
问题 为什么选择zxid越大要作为leader?
zxid越大说明数据是最新的,在操作的时候我们需要以最新的数据作为基础数据。
3.5 数据同步原理
zookeeper数据同步原理包含:差异化同步,回滚再差异化同步, 回滚同步, 全量同步等。
实际应用可以根据需要,选择同步类型。
3.6 客户端原理

1、创建两个线程, io线程负责网络事件的读写, completion线程处理异步回调函数和watcher调用;
2、io线程将数据序列化通过网络发送到zk节点;
3、zk节点返回数据,通过io线程反序列化,通过pipe异步发送给completion线程处理。
四、ZooKeeper实战示例
zookeeper的应用可以实现:统一命名服务、统一配置管理、分布式锁、分布式队列、负载均衡。
4.1 zookeeper安装
1、安装JDK,并配置环境变量
2、下载zookeeper
网址:https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.6.2/apache-zookeeper-3.6.2.tar.gz
3、安装
1)centos
yum install cppunit
yum install python-setuptools
yum install openssl openssl-devel
yum install cyrus-sasl-md5 cyrus-sasl-gssapi cyrus-sasl-devel
2)ubuntu
apt-get install libcppunit-dev
apt-get install python-setuptools python2.7-dev
apt-get install openssl libssl-dev
apt-get install libsasl2-modules-gssapi-mit libsasl2-modules libsasl2-dev
4、进入源码文件夹
mvn clean install -DskipTests
5、编译c驱动
mvn clean -pfull-build
mvn install -pfull-build -DskipTests
4.2 zookeeper配置
配置文件:./conf/zoo_sample.cfg
#心跳包间隔,在这里每2秒发送一次
tickTime=2000
#初始化同步时,最大允许10次延时,也就是2*10秒内同步成功就认为成功
initLimit=10
#更新同步时,最大允许5次延时,也就是2*5秒内同步成功就认为成功
syncLimit=5
#快照或持久化数据存储路径
dataDir=/tmp/zookeeper
#zk监听端口
clientPort=2181
4.3 示例源码
关键性示例源码:包含zookeeper初始化、节点创建、监听节点断开、业务逻辑、zookeeper关闭等。
#include