数据结构c++版_你应该了解的数据结构与算法
本文将要介绍的内容如下:

阅读小贴士:
阅读本文,请先掌握javascript基础知识。
推荐算法与数据结构入门书籍:《小灰算法》
推荐算法刷题网站:LeetCode
全文地图总览:
数据结构与算法简介、时间复杂度、空间复杂度
1. 数据结构:
栈
队列
链表
集合
字典
树
图
堆
2. 算法:
搜索排序
分而治之
动态规划
贪心算法
回溯算法
(*^_^*)与数据结构 和算法的邂逅(*^_^*)
和算法的邂逅(*^_^*)
1.数据结构、算法的自我介绍
数据结构:计算机存储、组织数据的方式
算法:一系列解决问题的清晰指令
程序 = 数据结构 + 算法
数据结构为算法提供服务,算法围绕数据结构操作。
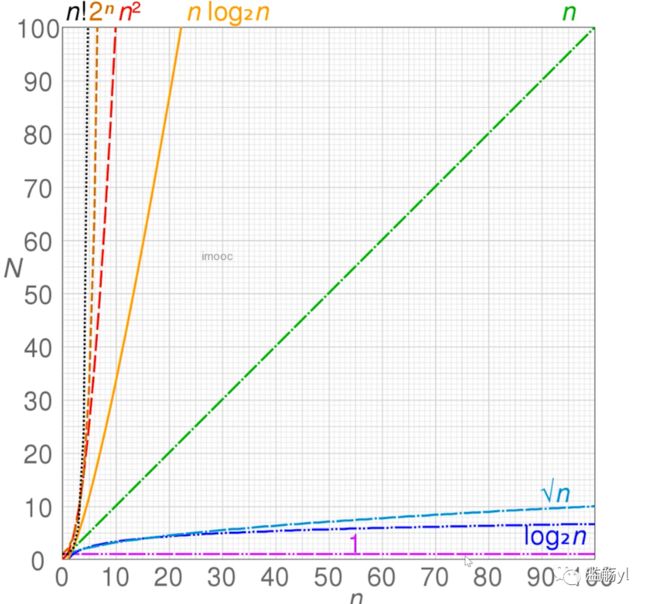
2. 时间复杂度、空间复杂度
关于时间复杂度和空间复杂度的详细介绍和计算可以查阅:《小灰算法》书籍
时间复杂度:一个函数,用大O表示,如O(1)、O(n)等,用来定性描述该算法的运行时间。
空间复杂度:一个函数,用大O表示,如O(1)、O(n)等。用来表示算法在运行过程中临时占用存储空间大小的度量。
常见的时间复杂度如下图:
(*^_^*)打开”数据结构“的大门(*^_^*)
1. 栈:
一个后进先出的数据结构。
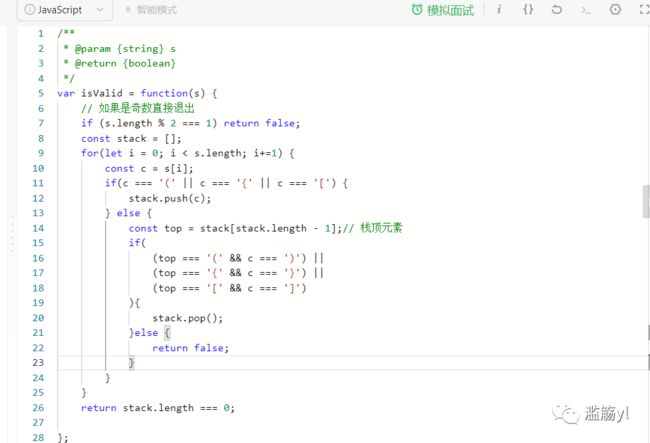
应用场景:需要后进先出的场景。如:10进制转2进制、判断字符串的括号是否有效、函数调用堆栈等……
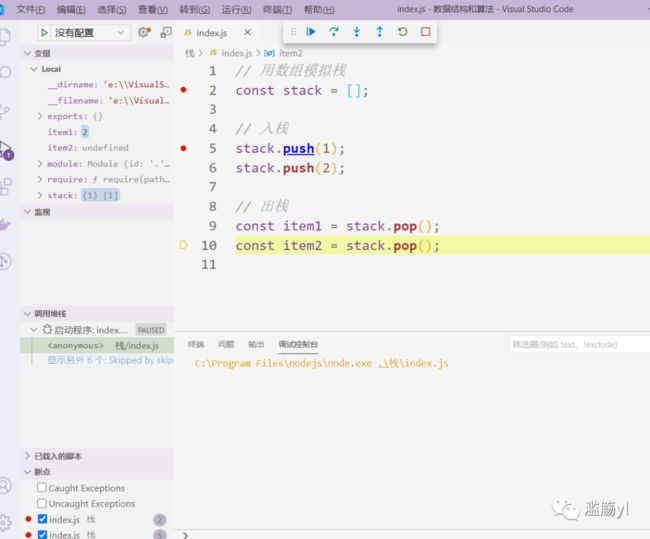
JS中的函数调用堆栈:

注:javascript没有栈,但可以用Array实现栈的所有功能。
LeetCode上对应的题目:
20. 有效的括号
扩展:VSCode调试通过Node方式调试,而不用初始化为Node项目
[打断点-》F5-》进入了调试状态如下图]
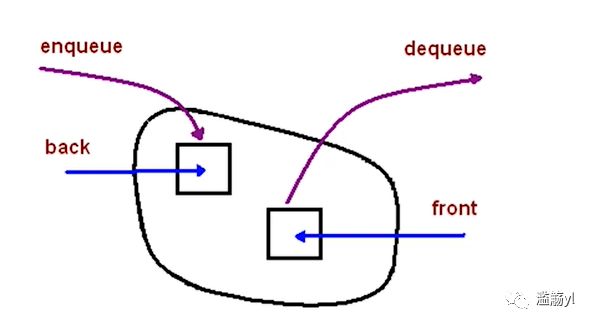
2. 队列:
一个先进先出的数据结构。
JS同样没有队列,但是可以用Array实现队列的所有功能。
应用场景:需要先进先出的场景。如:JS异步任务中的任务队列、计算最近请求次数。
JS中主要考察的是JS的事件循环和任务队列(宏任务队列、微任务队列)。
可以了解下JS和DOM的事件模型。
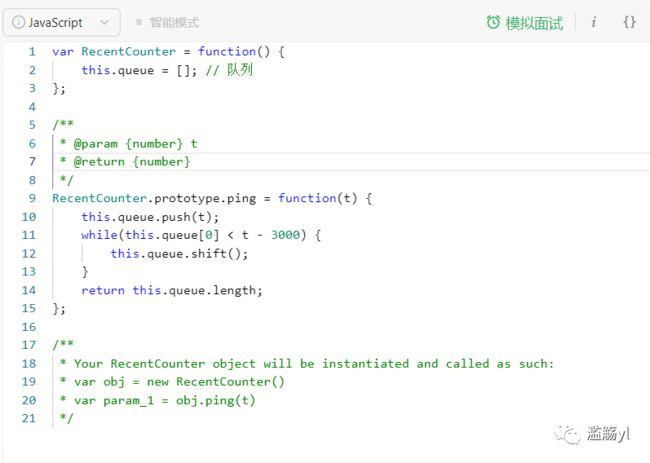
LeetCode上对应的题目:
933. 最近的请求次数
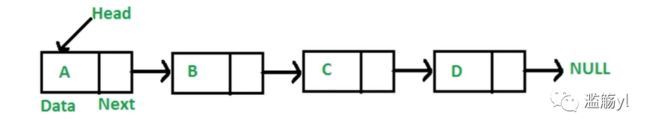
3. 链表:
多个元素组成的列表。
但是元素的存储不连续,用next指针连在一起。
JS中还是没有链表,但是可以用Object模拟链表。
const a = {val: 'a'}const b = {val: 'b'}const c = {val: 'c'}const d = {val: 'd'}a.next = b;b.next = c;c.next = d;// 遍历链表let p = a;while(p){
console.log(p.val); p = p.next;}// 插入const e = {val: 'e'}c.next = e;e.next = d;// 删除c.next = d;
注意数组和链表的区别:
数组:增删非首尾元素时往往需要移动元素
链表:增删非首尾元素,不需要移动元素,只需要更改next的指针即可
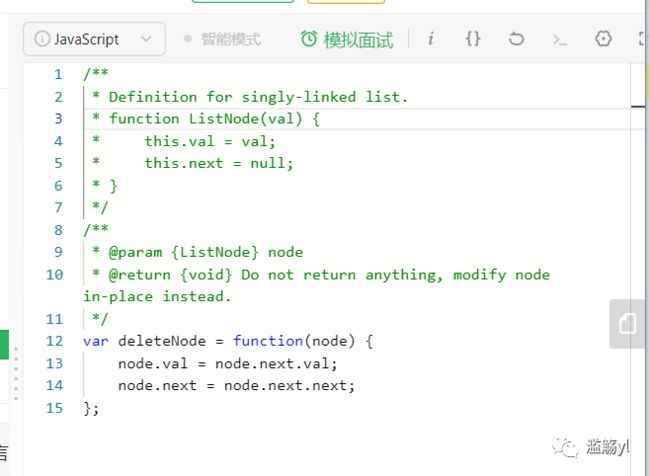
LeetCode上对应的题目:
237. 删除链表中的节点
206. 反转链表

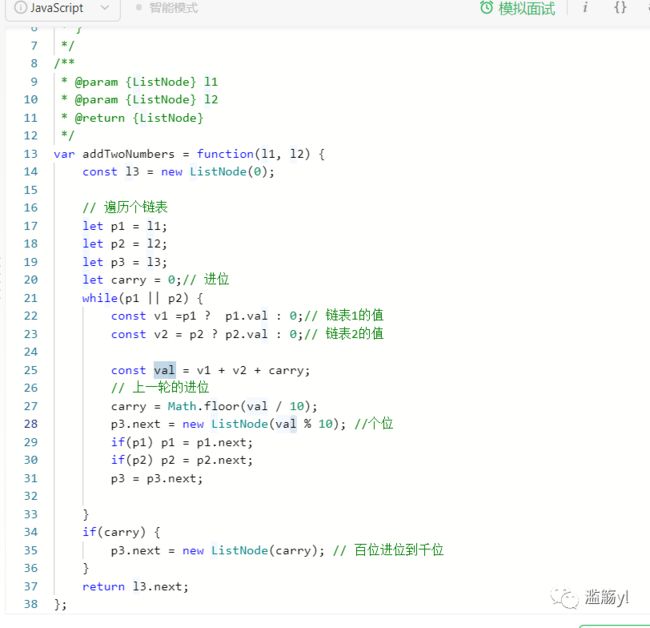
2. 两数相加
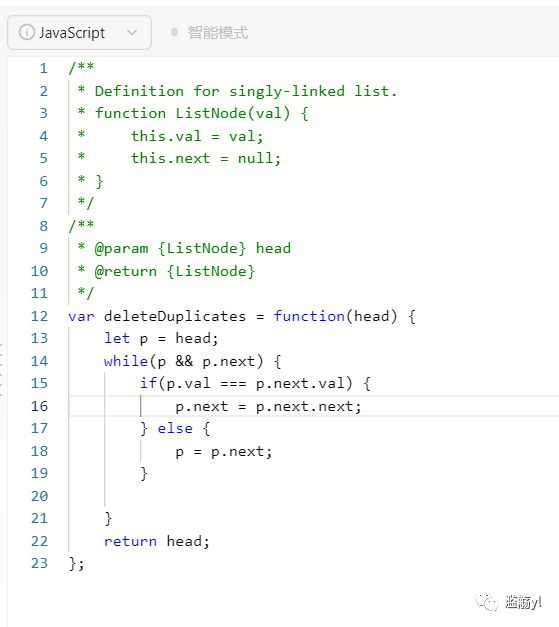
83.删除排序链表中的重复元素
141. 环形链表

扩展:前端与链表的结合点——原型链
原型链本质是链表。
原型链上的节点是各种原型对象,如Object.prototype
所谓的原型对象就是这些类的prototype属性值。
原型链通过__proto__属性连接各种原型对象。
如果A沿着原型链能找到B.prototype,那么A instanceof B为true.
如果A对象上没找到x属性,那么会沿着原型链向上攀升继续找x属性。
4. 集合:
一种无序且唯一的数据结构。
ES6中有集合:Set。
应用场景:去重、判断某元素是否在集合中、求交集等
LeetCode上对应的题目:
349. 两个数组的交集

5. 字典
存储唯一值的数据结构,但它以键值对的形式来存储
ES6中添加了字典Map
Map的操作时间复杂度都是O(1)
LeetCode上对应的题目:
349. 两个数组的交集

20.有效的括号
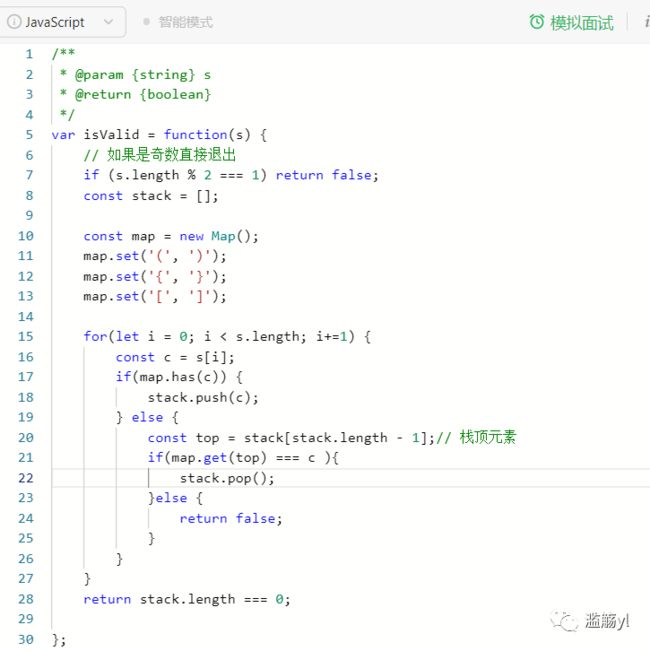
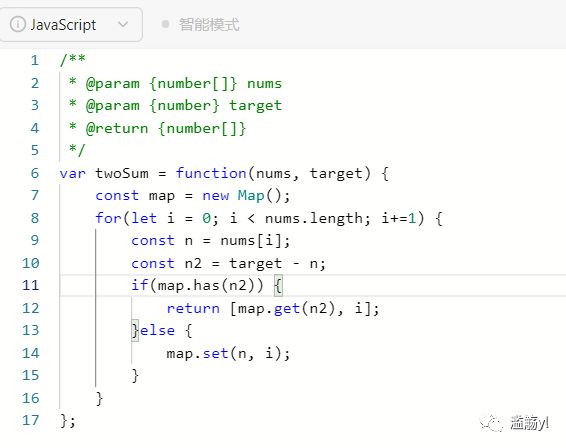
1. 两数之和
3. 无重复字符的最长子串
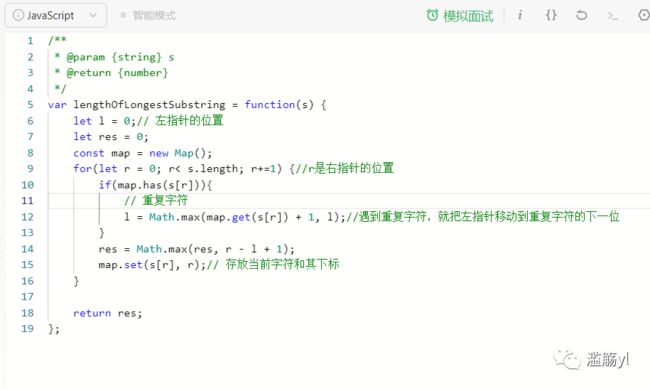
76.最小覆盖子串

6. 树
一种分层数据的抽象模型。
类似于生活中倒立 的树。
例如前端中的DOM树、级联选择(城市地区选择器等)、树形控件等
JS也是没有树的,但可以用Object和Array构建树
树常见的遍历方式是:深度/广度优先遍历、先序遍历、中序遍历、后序遍历
树的深度与广度优先遍历:
6.1 深度优先遍历:尽可能深的搜索树的分支
访问根节点
对根节点的children挨个进行深度优先遍历
const tree = {
val: 'a', children: [ {
val: 'b', children: [ {
val: 'd', children: [], }, {
val: 'e', children: [], }, ] }, {
val: 'c', children: [ {
val: 'f', children: [], }, {
val: 'g', children: [], }, ] } ]};const dfs = (root) => {
console.log(root.val); root.children.forEach((child) => {dfs(child)});};dfs(tree);
6.2 广度优先遍历:先访问离根节点最近的节点
新建一个队列,把根节点入队
把队头出队并访问
把队头的children挨个入队
重复上面的第2、3步,直到队列为空
const tree = {
val: 'a', children: [ {
val: 'b', children: [ {
val: 'd', children: [], }, {
val: 'e', children: [], }, ] }, {
val: 'c', children: [ {
val: 'f', children: [], }, {
val: 'g', children: [], }, ] } ]};const bfs = (root) => {
const q = [root];// 入队队头 while(q.length > 0) {
const n = q.shift(); // 队头出队 console.log(n.val); //访问队头 n.children.forEach(child => {
// 队头的children挨个入队 q.push(child); }) }};bfs(tree);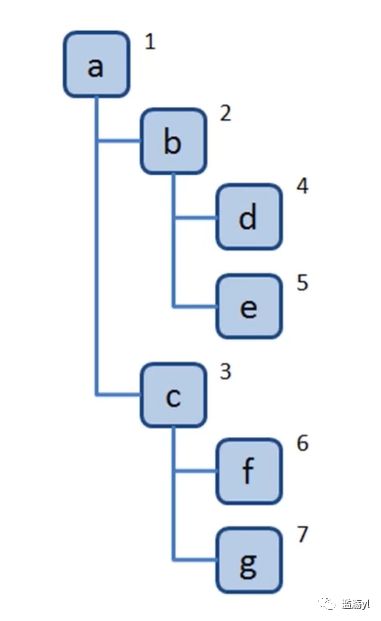
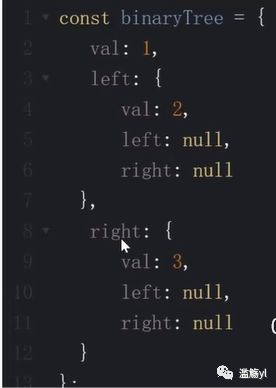
6.3 二叉树
树 分为二叉树和多叉树等。
二叉树中每个节点最多只能有2个子节点。
JS中常用Object来模拟二叉树(val代表当前节点的值):

其实,先序、中序、后序不难理解。明白”序“是相对于根节点来说的进行理解即可。且这些遍历可以用递归实现,也可以用非递归实现。
6.3.1 二叉树的先序遍历:
访问根节点
对根节点的左子树进行先序遍历
对根节点的右子树进行先序遍历
const bt = {
val: 1, left: {
val: 2, left: {
val: 4, left: null, right: null, }, right: {
val: 5, left: null, right: null, } }, right: {
val: 3, left: {
val: 6, left: null, right: null, }, right: {
val: 7, left: null, right: null, } }}// 先序遍历const preorder = (root) => {
if(!root) {
return; } console.log(root.val); preorder(root.left); preorder(root.right);};preorder(bt)非递归版:
const bt = {
val: 1, left: {
val: 2, left: {
val: 4, left: null, right: null, }, right: {
val: 5, left: null, right: null, } }, right: {
val: 3, left: {
val: 6, left: null, right: null, }, right: {
val: 7, left: null, right: null, } }}/// 先序遍历的非递归版[函数调用堆栈来模拟]const preorder = (root) => {
if(!root) {
return; } const stack = [root]; // 根节点入栈[后进先出] while(stack.length) {
const n = stack.pop(); console.log(n.val); // 访问根节点的值 if(n.right) stack.push(n.right); if(n.left) stack.push(n.left); }};preorder(bt)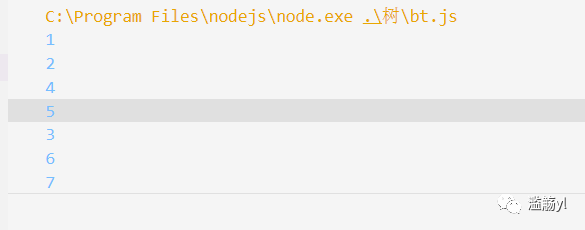
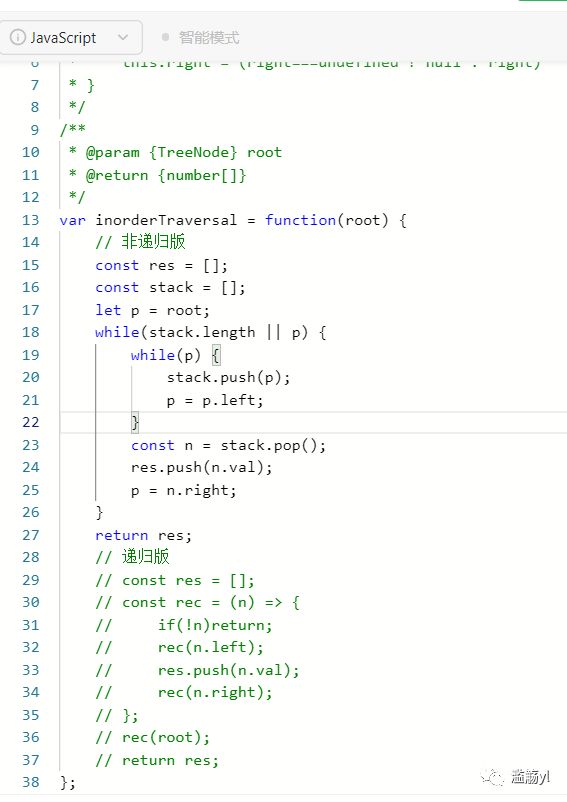
6.3.2 二叉树的中序遍历:
对根节点的左子树进行中序遍历
访问根节点
对根节点的右子树进行中序遍历
const bt = {
val: 1, left: {
val: 2, left: {
val: 4, left: null, right: null, }, right: {
val: 5, left: null, right: null, } }, right: {
val: 3, left: {
val: 6, left: null, right: null, }, right: {
val: 7, left: null, right: null, } }}// 中序遍历const inorder = (root) => {
if(!root) {
return; } inorder(root.left); console.log(root.val); inorder(root.right);}inorder(bt);非递归版:
const bt = {
val: 1, left: {
val: 2, left: {
val: 4, left: null, right: null, }, right: {
val: 5, left: null, right: null, } }, right: {
val: 3, left: {
val: 6, left: null, right: null, }, right: {
val: 7, left: null, right: null, } }}// 中序遍历非递归遍历const inorder = (root) => {
if(!root) {
return; } const stack = []; let p = root; while(stack.length || p){
while(p) {
stack.push(p); p = p.left; } const n = stack.pop(); console.log(n.val); p = n.right; }}inorder(bt);
6.3.3 二叉树的后序遍历:
对根节点的左子树进行后序遍历
对根节点的右子树进行后序遍历
访问根节点
const bt = {
val: 1, left: {
val: 2, left: {
val: 4, left: null, right: null, }, right: {
val: 5, left: null, right: null, } }, right: {
val: 3, left: {
val: 6, left: null, right: null, }, right: {
val: 7, left: null, right: null, } }}// 后序遍历const postorder = (root) => {
if(!root){
return; } postorder(root.left); postorder(root.right); console.log(root.val)};postorder(bt);非递归版:
const bt = {
val: 1, left: {
val: 2, left: {
val: 4, left: null, right: null, }, right: {
val: 5, left: null, right: null, } }, right: {
val: 3, left: {
val: 6, left: null, right: null, }, right: {
val: 7, left: null, right: null, } }}//后序遍历 非递归版const postorder = (root) => {
if(!root){
return; } const outputStack = []; const stack = [root]; while(stack.length) {
const n = stack.pop(); outputStack.push(n); if(n.left) stack.push(n.left); if(n.right) stack.push(n.right); } while(outputStack.length) {
const n = outputStack.pop(); console.log(n.val); }};postorder(bt);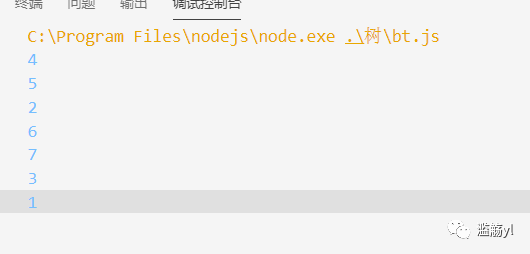
LeetCode上对应的题目:
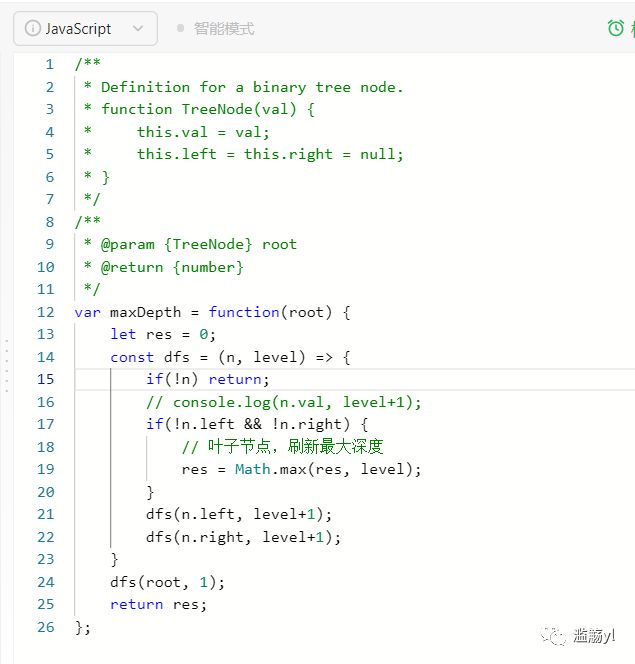
104. 二叉树的最大深度
111.二叉树的最小深度
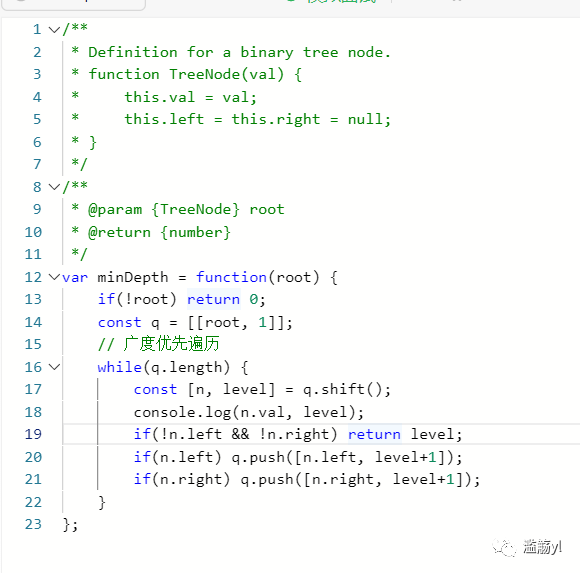
102.二叉树的层序遍历

94.二叉树的中序遍历
112.路径总和
7. 图
图是网络结构的抽象模型,是一组由边连接的节点。
图可以表示任何二元关系,如:道路、航班
一条边只能连接2个节点,所以表示的是2元关系。
JS中还是没有图,依然用Object和Array构建图。
图的表示法:邻接矩阵、邻接表、关联矩阵等等
图的常见操作:深度优先遍历、广度优先遍历
7.1 图的表示法1——邻接矩阵
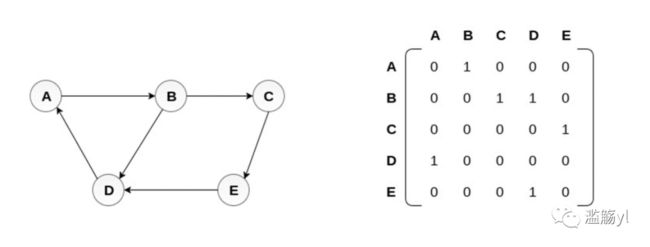
有如上图左边那个”图“,A连接到B,B连接到C,C连接到E……
JS中可以用二维数组来表示这个图,如A能连接到B,那么
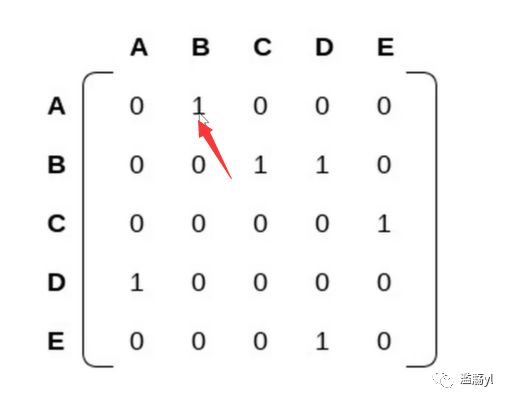
箭头所指处第一行代表A这个节点,第2列代表B这个节点。
依此类推,如果我们想表示某个节点能连接到另外一个节点,那么就设置2个节点的交叉位置为1. 这就是常说的邻接矩阵。
7.2 图的表示法2——邻接表
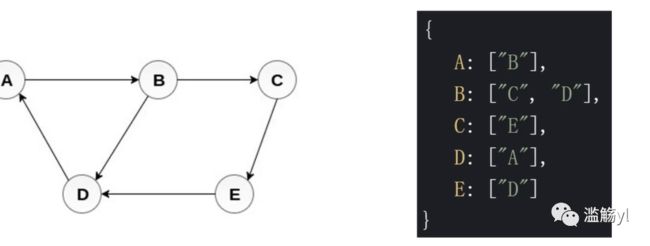
可以构建一个对象,对象的Key就是各个节点,value就是各个节点可连接到的节点。如上图的 B: ['c', 'D’] 代表B可以连接到C和D。当然邻接表不只是这种表现形式,但只要能表示连接关系即可。
7.3 图的深度优先遍历
尽可能深的搜索图的分支。
访问根节点
对根节点的没访问过的相邻节点挨个进行深度优先遍历。【如果访问已访问过的节点就会陷入死循环】
所以正确做法是下图中的右图。
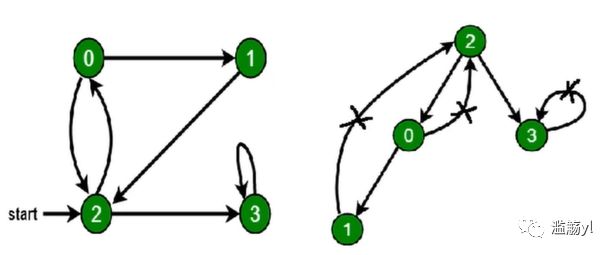
// 图const graph = {
0: [1, 2], 1: [2], 2: [0, 3], 3: [3]}// 图的深度优先遍历const visited = new Set();const dfs =(n) => {
console.log(n);// 访问节点 // 对没访问过的相邻节点进行深度优先遍历 visited.add(n); graph[n].forEach(c => { //graph[n]是指相邻节点 if(!visited.has(c)) {
dfs(c); } })};dfs(2);
7.4 图的广度优先遍历
先访问离根节点最近的节点。
新建一个队列,把根节点入队
把队头出队并访问
把队头的没访问过的相邻节点入队
重复第2、3步知道队列为空
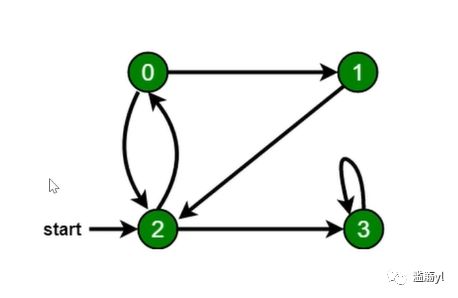
// 图const graph = {
0: [1, 2], 1: [2], 2: [0, 3], 3: [3]}// 图的广度优先遍历const visited = new Set();visited.add(2);const q = [2];while(q.length) {
const n = q.shift(); console.log(n); graph[n].forEach(c => {
if(!visited.has(c)) {
q.push(c); visited.add(c); } })}
LeetCode上对应的题目:
65.有效数字

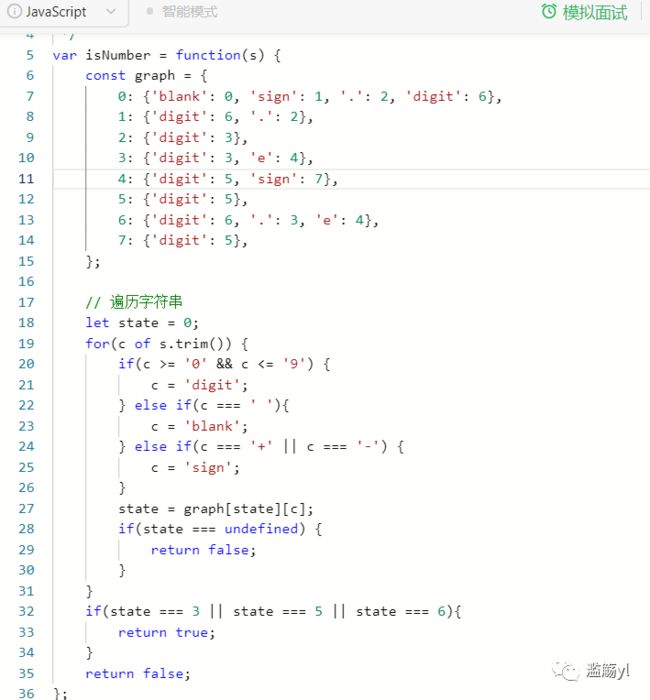
417. 太平洋大西洋水流问题

133.克隆图
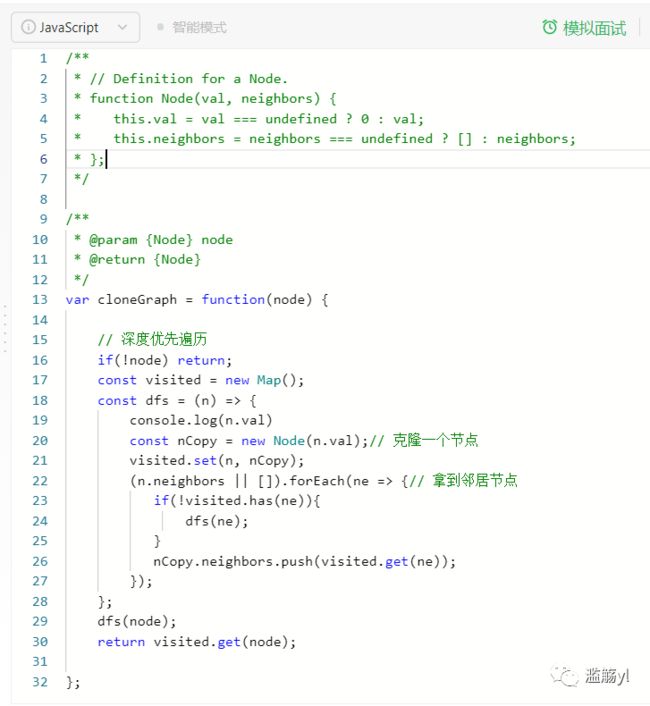

8. 堆
一种特殊的完全二叉树。
JS通常使用数组表示堆,
堆能快速找出最大值和最小值,其时间复杂度是O(1)。
堆还能找出第K个最大(小)元素
左侧的子节点的位置:2* index + 1
右侧的子节点的位置:2*index +2
父节点位置是(index-1)/2
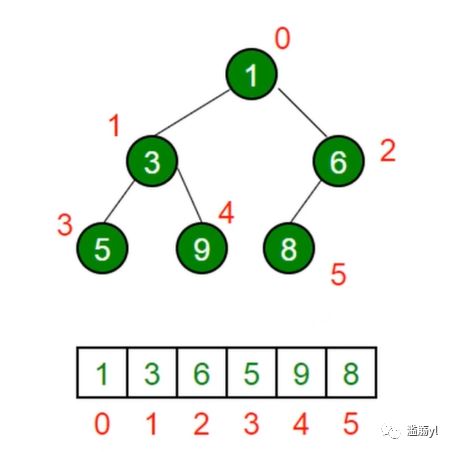
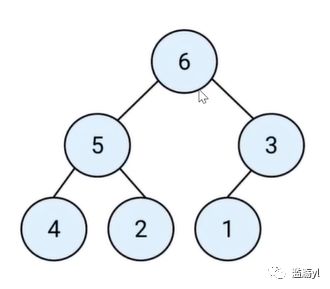
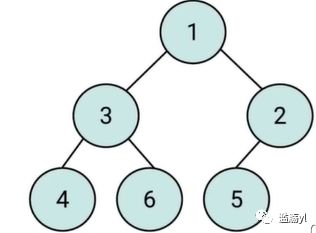
其所有节点都大于等于(最大堆)或小于等于(最小堆)它的子节点。
堆找出第K个最大元素:
构建一个最小堆,并将元素依次插入堆中
当堆的容量超过K时,就删除堆顶
插入结束后,堆顶就是第K个最大元素
// 最小堆类:// 1. 类中声明一个数组,来装元素// 2. 主要方法:插入、删除堆顶、获取堆顶、获取堆大小class MinHeap { constructor() {
this.heap = []; } // 插入: // 1. 将值插入堆的底部,即数组的尾部 // 2. 上移,将这个值和它的父节点进行交换,直到父节点小于等于这个插入的值 // 3. 大小为k的堆来说,插入元素的时间复杂度为O(logk) insert(value) {
this.heap.push(value); // 上移 this.shiftUp(this.heap.length - 1); } // 删除堆顶: // 1. 用数组尾部元素替换堆顶(直接删除堆顶会破坏堆的结构) // 2. 下移,将新的堆顶和它的子节点进行操作,直到子节点大于等于这个新堆顶 // 3. 大小为k的堆中,删除堆顶的时间复杂度为O(logk) pop() {
this.heap[0] = this.heap.pop(); this.shiftDown(0); } // 获取堆顶和堆的大小 // 1. 获取堆顶:返回数组的头部 // 2. 获取堆的大小:返回数组的长度 peek() {
return this.heap[0]; } size() {
return this.heap.length; } shiftDown(index) {
const leftIndex = this.getLeftIndex(index); const rightIndex = this.getRightIndex(index); if(this.heap[leftIndex] < this.heap[index]) {
this.swap(leftIndex, index); this.shiftDown(leftIndex); } if(this.heap[rightIndex] < this.heap[index]) {
this.swap(rightIndex, index); this.shiftDown(rightIndex); } } // 拿到该节点的左侧子节点 getLeftIndex(i) {
return i * 2 + 1; } // 拿到该节点的右侧子节点 getRightIndex(i) {
return i * 2 + 2; } // 拿到该节点的父节点 getParentIndex(i) {
// return Math.floor((i-1)/2); return (i - 1) >> 1; } // 交换 swap(i1, i2) {
const temp = this.heap[i1]; this.heap[i1] = this.heap[i2]; this.heap[i2] = temp; } shiftUp(index) {
if(index === 0) { // 堆顶 return; } const parentIndex = this.getParentIndex(index); if(this.heap[parentIndex] > this.heap[index]) {
// 父节点的值大于子节点的值那么就需要交换 this.swap(parentIndex, index); this.shiftUp(parentIndex); } }}const h = new MinHeap();h.insert(3);h.insert(2);h.insert(1);// result: 1 3 2h.pop();//result : 2, 3LeetCode对应题目:
215.数组中的第K个最大元素
// 最小堆类:// 1. 类中声明一个数组,来装元素// 2. 主要方法:插入、删除堆顶、获取堆顶、获取堆大小class MinHeap { constructor() {
this.heap = []; } // 插入: // 1. 将值插入堆的底部,即数组的尾部 // 2. 上移,将这个值和它的父节点进行交换,直到父节点小于等于这个插入的值 // 3. 大小为k的堆来说,插入元素的时间复杂度为O(logk) insert(value) {
this.heap.push(value); // 上移 this.shiftUp(this.heap.length - 1); } // 删除堆顶: // 1. 用数组尾部元素替换堆顶(直接删除堆顶会破坏堆的结构) // 2. 下移,将新的堆顶和它的子节点进行操作,直到子节点大于等于这个新堆顶 // 3. 大小为k的堆中,删除堆顶的时间复杂度为O(logk) pop() {
this.heap[0] = this.heap.pop(); this.shiftDown(0); } // 获取堆顶和堆的大小 // 1. 获取堆顶:返回数组的头部 // 2. 获取堆的大小:返回数组的长度 peek() {
return this.heap[0]; } size() {
return this.heap.length; } shiftDown(index) {
const leftIndex = this.getLeftIndex(index); const rightIndex = this.getRightIndex(index); if(this.heap[leftIndex] < this.heap[index]) {
this.swap(leftIndex, index); this.shiftDown(leftIndex); } if(this.heap[rightIndex] < this.heap[index]) {
this.swap(rightIndex, index); this.shiftDown(rightIndex); } } // 拿到该节点的左侧子节点 getLeftIndex(i) {
return i * 2 + 1; } // 拿到该节点的右侧子节点 getRightIndex(i) {
return i * 2 + 2; } // 拿到该节点的父节点 getParentIndex(i) {
// return Math.floor((i-1)/2); return (i - 1) >> 1; } // 交换 swap(i1, i2) {
const temp = this.heap[i1]; this.heap[i1] = this.heap[i2]; this.heap[i2] = temp; } shiftUp(index) {
if(index === 0) { // 堆顶 return; } const parentIndex = this.getParentIndex(index); if(this.heap[parentIndex] > this.heap[index]) {
// 父节点的值大于子节点的值那么就需要交换 this.swap(parentIndex, index); this.shiftUp(parentIndex); } }}/** * @param {number[]} nums * @param {number} k * @return {number} */var findKthLargest = function(nums, k) {
// 构建最小堆 const h = new MinHeap(); nums.forEach(n => {
// 插入元素 h.insert(n); // 裁员 if(h.size() > k ) {
h.pop();// 删除堆顶 } }); return h.peek();};347.前K个高频元素
/** * @param {number[]} nums * @param {number} k * @return {number[]} */var topKFrequent = function(nums, k) {
// 解法1: const map = new Map(); nums.forEach(n=> {
map.set(n, map.has(n)?map.get(n)+1 : 1); }); // console.log(map); // 统计元素频率 // console.log(Array.from(map));// 对频率进行排序 const list = Array.from(map).sort((a,b) => b[1] - a[1]); // console.log(list) return list.slice(0, k).map(n => n[0]);};// 最小堆类:// 1. 类中声明一个数组,来装元素// 2. 主要方法:插入、删除堆顶、获取堆顶、获取堆大小class MinHeap { constructor() {
this.heap = []; } // 插入: // 1. 将值插入堆的底部,即数组的尾部 // 2. 上移,将这个值和它的父节点进行交换,直到父节点小于等于这个插入的值 // 3. 大小为k的堆来说,插入元素的时间复杂度为O(logk) insert(value) {
this.heap.push(value); // 上移 this.shiftUp(this.heap.length - 1); } // 删除堆顶: // 1. 用数组尾部元素替换堆顶(直接删除堆顶会破坏堆的结构) // 2. 下移,将新的堆顶和它的子节点进行操作,直到子节点大于等于这个新堆顶 // 3. 大小为k的堆中,删除堆顶的时间复杂度为O(logk) pop() {
this.heap[0] = this.heap.pop(); this.shiftDown(0); } // 获取堆顶和堆的大小 // 1. 获取堆顶:返回数组的头部 // 2. 获取堆的大小:返回数组的长度 peek() {
return this.heap[0]; } size() {
return this.heap.length; } shiftDown(index) {
const leftIndex = this.getLeftIndex(index); const rightIndex = this.getRightIndex(index); if(this.heap[leftIndex] && this.heap[leftIndex].value < this.heap[index].value ) {
this.swap(leftIndex, index); this.shiftDown(leftIndex); } if(this.heap[rightIndex] && this.heap[rightIndex].value < this.heap[index].value ) {
this.swap(rightIndex, index); this.shiftDown(rightIndex); } } // 拿到该节点的左侧子节点 getLeftIndex(i) {
return i * 2 + 1; } // 拿到该节点的右侧子节点 getRightIndex(i) {
return i * 2 + 2; } // 拿到该节点的父节点 getParentIndex(i) {
// return Math.floor((i-1)/2); return (i - 1) >> 1; } // 交换 swap(i1, i2) {
const temp = this.heap[i1]; this.heap[i1] = this.heap[i2]; this.heap[i2] = temp; } shiftUp(index) {
if(index === 0) { // 堆顶 return; } const parentIndex = this.getParentIndex(index); if(this.heap[parentIndex] && this.heap[parentIndex].value > this.heap[index].value ) {
// 父节点的值大于子节点的值那么就需要交换 this.swap(parentIndex, index); this.shiftUp(parentIndex); } }}/** * @param {number[]} nums * @param {number} k * @return {number[]} */var topKFrequent = function(nums, k) {
// sort()的时间复杂度是O(nlogn) const map = new Map(); nums.forEach(n=> {
map.set(n, map.has(n)?map.get(n)+1 : 1); }); // console.log(map); // 统计元素频率 // console.log(Array.from(map));// 对频率进行排序 // const list = Array.from(map).sort((a,b) => b[1] - a[1]); // console.log(list) // return list.slice(0, k).map(n => n[0]); // 为了优化时间复杂度就没必要全排列,用堆即可。 // 构建前K个高频元素都在堆里面 const h = new MinHeap(); map.forEach((value, key) => {
h.insert({value, key});// 插入的是js对象 if(h.size() > k) {
h.pop(); } }); return h.heap.map(a => a.key);};// 时间复杂度是O(nlogk)23.合并K个排序链表
/** * Definition for singly-linked list. * function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val) * this.next = (next===undefined ? null : next) * } *//** * @param {ListNode[]} lists * @return {ListNode} */var mergeKLists = function(lists) {
const res = new ListNode(0); // 输出链表 let p = res; const h = new MinHeap(); lists.forEach(l=> {
if(l) h.insert(l); }); while(h.size()) {
const n = h.pop(); p.next = n; p = p.next; if(n.next) h.insert(n.next); } return res.next;};// 最小堆类:// 1. 类中声明一个数组,来装元素// 2. 主要方法:插入、删除堆顶、获取堆顶、获取堆大小class MinHeap { constructor() {
this.heap = []; } // 插入: // 1. 将值插入堆的底部,即数组的尾部 // 2. 上移,将这个值和它的父节点进行交换,直到父节点小于等于这个插入的值 // 3. 大小为k的堆来说,插入元素的时间复杂度为O(logk) insert(value) {
this.heap.push(value); // 上移 this.shiftUp(this.heap.length - 1); } // 删除堆顶: // 1. 用数组尾部元素替换堆顶(直接删除堆顶会破坏堆的结构) // 2. 下移,将新的堆顶和它的子节点进行操作,直到子节点大于等于这个新堆顶 // 3. 大小为k的堆中,删除堆顶的时间复杂度为O(logk) pop() {
if(this.size() === 1) return this.heap.shift(); const top = this.heap[0]; this.heap[0] = this.heap.pop(); this.shiftDown(0); return top; } // 获取堆顶和堆的大小 // 1. 获取堆顶:返回数组的头部 // 2. 获取堆的大小:返回数组的长度 peek() {
return this.heap[0]; } size() {
return this.heap.length; } shiftDown(index) {
const leftIndex = this.getLeftIndex(index); const rightIndex = this.getRightIndex(index); if(this.heap[leftIndex] && this.heap[leftIndex].val < this.heap[index].val) {
this.swap(leftIndex, index); this.shiftDown(leftIndex); } if(this.heap[rightIndex] && this.heap[rightIndex].val < this.heap[index].val) {
this.swap(rightIndex, index); this.shiftDown(rightIndex); } } // 拿到该节点的左侧子节点 getLeftIndex(i) {
return i * 2 + 1; } // 拿到该节点的右侧子节点 getRightIndex(i) {
return i * 2 + 2; } // 拿到该节点的父节点 getParentIndex(i) {
// return Math.floor((i-1)/2); return (i - 1) >> 1; } // 交换 swap(i1, i2) {
const temp = this.heap[i1]; this.heap[i1] = this.heap[i2]; this.heap[i2] = temp; } shiftUp(index) {
if(index === 0) { // 堆顶 return; } const parentIndex = this.getParentIndex(index); if(this.heap[parentIndex] && this.heap[parentIndex].val > this.heap[index].val) {
// 父节点的值大于子节点的值那么就需要交换 this.swap(parentIndex, index); this.shiftUp(parentIndex); } }}(*^_^*)"算法"的成神之路(*^_^*)
1. 搜索排序,你知多少?
【提示: 可能有些算法过程太抽象难以理解,那么推荐算法可视化网站,可视化的结果结合https://visualgo.net/zh 这个网站和代码调试更加深刻的理解算法】
这里为了排版方便,将不会录制gif图展示,有疑问的可自行去网站查看可视化过程。
排序:把某个乱序的数组变成升序或降序的数组。
搜索:找出数组中某个元素的下标。
JS中,排序:数组的sort(),搜索:数组的indexOf()、includes()等
一个好的开发者不应该仅仅停留在API的使用阶段。
知其所以然,才能成为大牛!
接下来我将从0开始介绍排序和搜索算法有哪些,怎么实现。
1.1 常用的排序算法:
1.1.1 冒泡排序
冒泡排序是排序算法中最简单的一个,但性能较差。工作中几乎应该用不到的。
其思路:
比较所有相邻元素,如果第一个比第二个大,则交换他们
一轮下来,可以保证最后一个数是最大的
执行n-1轮,就可以完成排序
思考1下,传统的冒泡排序的相邻比较的时候是不是全部都要比。既然每次最大的都会到最右边,那么最右边的区域是不是会有序的了,还需要参与后面的比较吗?肯定不需要啊,提高了性能
时间复杂度:O(n^2) 因为2个嵌套循环
Array.prototype.bubbleSort = function() {
for(let i=0;i this[j+1]) {
const temp = this[j]; this[j] = this[j+1]; this[j+1] = temp; } } } };const arr = [5,4,3,2,1]arr.bubbleSort();console.log(arr) 
1.1.2 选择排序
性能也不太好。但和冒泡排序一样简单。
找到数组中的最小值,选中它并将其放置在第一位
接着找到第二小的值,选中它并将其放置在第2位
以此类推,执行n-1轮
注意,这里也优化了以下,不是每次都从0开始,应该每次放在前从而有序了。所以直接跳过位置对调。
时间复杂度:O(n^2) 因为2个嵌套循环
Array.prototype.selectionSort = function() {
for(let i=0;i1.1.3 插入排序
排序小型数组的时候,插入排序比选择排序、冒泡排序的性能都要好。
从第二个数开始往前比
比它大的就往后排
以此类推进行到最后一个数
时间复杂度:O(n^2)因为2个嵌套循环
Array.prototype.insertionSort = function() {
for(let i = 1; i 0) {
if(this[j - 1] > temp) {
// 前面的数比后面的大,后移 this[j] = this[j-1]; }else {
break; } j--; } this[j] = temp; }};const arr = [5,4,3,2,1]arr.insertionSort();console.log(arr) 1.1.4 归并排序:
在Code中常用这个。
分:把数组分为2半,再递归的对子数组进行“分”操作,直到分成一个个单独的数
合:把2个数合并为有序数组,再对有序数组进行合并,直到全部子数组都合并为一个完整的数组。
合并2个有序数组:新建一个空数组res,用于存放最终排序后的数组。比较2个有序数组的头部,较小者出队并推入res中。如果2个数组还有值,重复比较2个有序数组的头部,较小者出队并推入res中。
Array.prototype.mergeSort = function() {
// 分:递归时间复杂度是O(logN) const rec = (arr) => {
if(arr.length === 1) {
return arr; } const mid = Math.floor(arr.length / 2); const left = arr.slice(0, mid); const right = arr.slice(mid, arr.length); const orderLeft = rec(left); const orderRight = rec(right); // 合并:循环时间复杂度O(n) const res = []; while(orderLeft.length || orderRight.length){
if(orderLeft.length && orderRight.length) {
res.push(orderLeft[0] < orderRight[0] ? orderLeft.shift() : orderRight.shift()); } else if(orderLeft.length){
// 左边数组还有值,右边数组已经空了 res.push(orderLeft.shift()); }else if(orderRight.length){
// 左边数组还有值,右边数组已经空了 res.push(orderRight.shift()); } } return res; } const result = rec(this); result.forEach((n, i )=> this[i] = n);};const arr = [5,4,3,2,1]arr.mergeSort();console.log(arr)//总体时间复杂度:O(nlogN)1.1.4 快速排序
性能比冒泡排序、选择排序、插入排序的性能更好。
Chrome曾用快速排序作为sort()的排序方法
分区:从数组中任意选择一个基准元素,所有比基准小的元素放在基准前面,比基准大的元素放到基准后面
递归:递归的对基准前后的子数组进行分区
时间复杂度:因为递归的时间复杂度O(logN),分区的时间复杂度O(n),所以整体时间复杂度:O(n*logN)
Array.prototype.quickSort = function() {
const rec = (arr) => {
if(arr.length === 1){
return arr; } const left = []; const right = []; const mid = arr[0]; // 基准元素 // 分区 for(let i =1; i < arr.length; i ++) {
if(arr[i]< mid) {
left.push(arr[i]); }else {
right.push(arr[i]); } } //递归分区 return [...rec(left), mid, ...rec(right)]; }; const res = rec(this); res.forEach((n, i) => this[i] = n);};const arr = [2,4,5,3,1]arr.quickSort();console.log(arr)1.2 常用的搜索算法:
1.2.1 顺序搜索:
最基本的搜索算法,也最低效。
遍历数组
如果找到和目标值相等的元素,就返回该它的下标
遍历结束后, 如果没搜索到目标值就返回-1
时间复杂度:O(n)。因为循环
Array.prototype.sequentialSearch= function(target) {
for(let i =0;i1.2.2 二分搜索/折半搜索:
前提:数组是有序的。
比顺序搜索的效率高得多
从数组的中间元素开始,如果中间元素正好是目标值,则搜索结束
如果目标大于或小于中间元素,则在大于或小于中间元素的那一半数组中搜索
时间复杂度:O(logN) 因为每次比较都使搜索范围缩小一半。
Array.prototype.binarySearch= function(target) {
this.sort(); // 先排序,如果原数组不是有序的 let low = 0; // 搜索的数组的最小下标 let high = this.length - 1;//搜索的数组的最大下标 while(low <= high) {
const mid = Math.floor((low + high) / 2); // 求中间元素的下标 const element = this[mid]; // 中间值 if(element < target) { low = mid + 1; }else if(element > target){
high = mid - 1; } else {
return mid; } } return -1;}const res = [1,2,3,4,5].binarySearch(4); // 下标是3console.log(res)LeetCode对应题目:
21. 合并2个有序链表

374.猜数字大小
2. 君王何以治天下——分而治之
分而治之是算法设计中的一种方法、思想。
将1个问题分为多个和原问题相似的小问题,递归解决小问题,然后将结果合并以解决原来的问题
2.1 归并排序
就是利用分而治之来设计的:
分:把数组从中间一分为二
解:递归的对2个子数组进行归并排序
合:合并有序子数组
2.2 快速排序:
也是利用分而治之来设计的:
分:选基准,按基准把数组分成2个子数组
解: 递归的对2个子数组进行快速排序
合:对2个子数组进行合并
LeetCode对应题目:
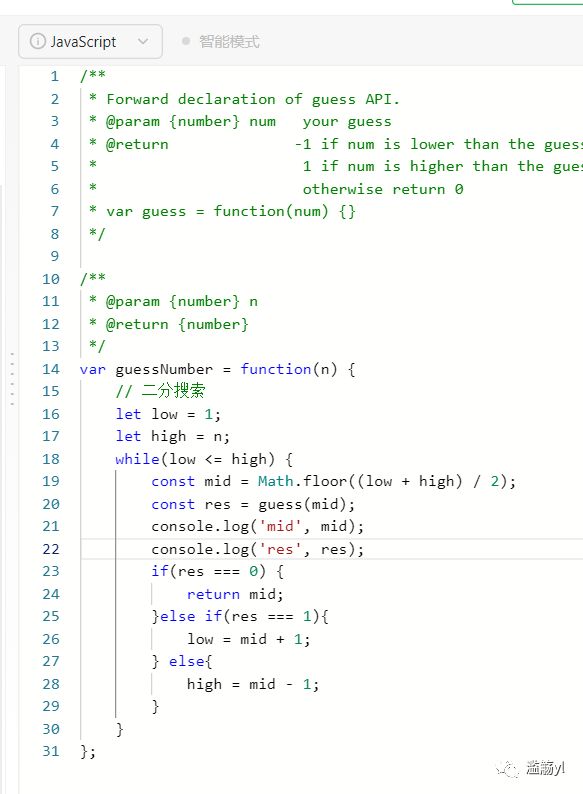
374. 猜数字大小
/** * Forward declaration of guess API. * @param {number} num your guess * @return -1 if num is lower than the guess number * 1 if num is higher than the guess number * otherwise return 0 * var guess = function(num) {} *//** * @param {number} n * @return {number} */var guessNumber = function(n) {
// 解法2:分而治之 const rec = (low, high) => {
if(low > high) {
return; } const mid = Math.floor((low + high) / 2); const res = guess(mid); if(res === 0) {
return mid; }else if(res === 1) {
return rec(mid + 1, high); }else {
return rec(1, mid-1); } }; return rec(1, n); // 二分搜索 // let low = 1; // let high = n; // while(low <= high) {
// const mid = Math.floor((low + high) / 2); // const res = guess(mid); // console.log('mid', mid); // console.log('res', res); // if(res === 0) {
// return mid; // }else if(res === 1){
// low = mid + 1; // } else{
// high = mid - 1; // } // }};226. 翻转二叉树
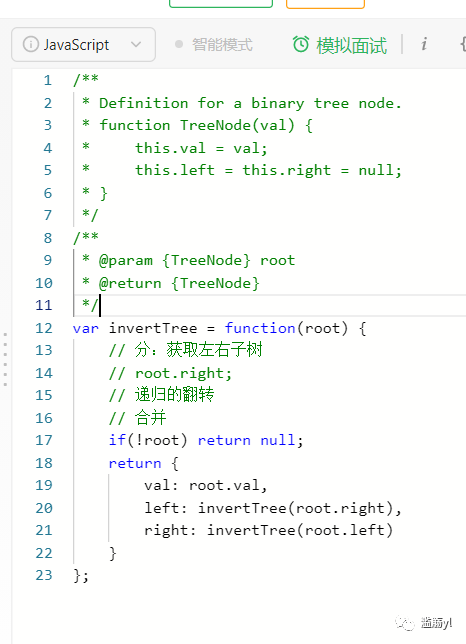
100. 相同的树

101. 对称二叉树

3. 你对你的职业规划是什么——动态规划
动态规划也是算法设计中的一种方法、思想。
将一个问题分解为相互重叠的子问题,通过反复求解子问题来解决原来的问题
例如,解决斐波那契数列问题:

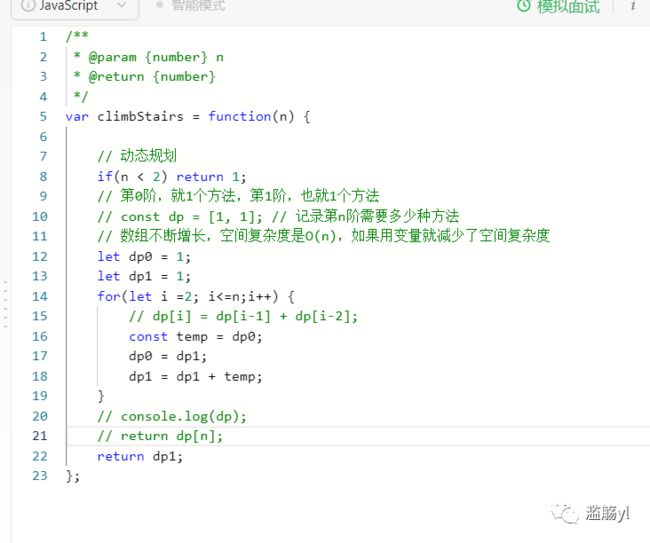
198. 打家劫舍
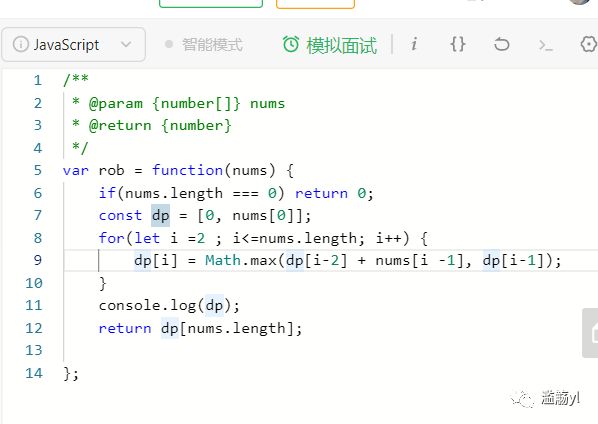
4. 你贪心了吗?——贪心算法
也是算法设计中的一种方法、思想。
期盼通过每个阶段的局部最优选择,达到全局的最优
结果不一定是最优的
贪心算法有时候能得到最优解,有时候又得不到:

LeetCode对应题目:
455. 分发饼干
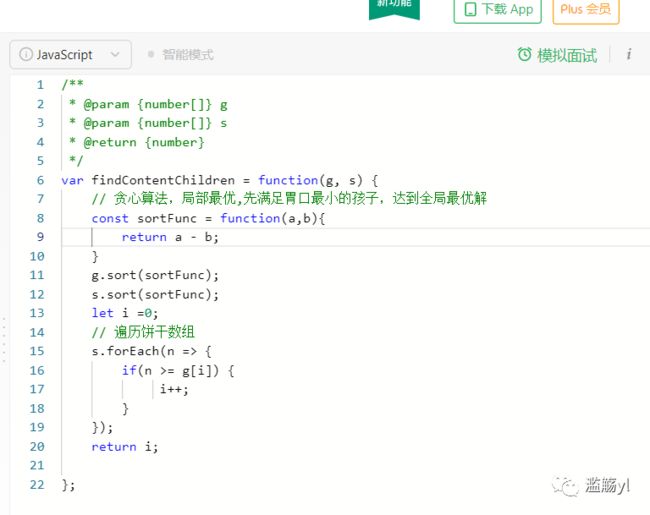
122. 买卖股票的最佳时机2
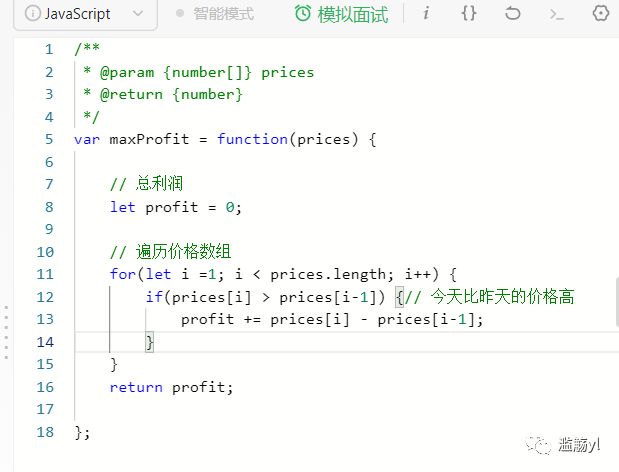
5. 回溯算法
它也是算法设计中的一种方法。
一种渐进式寻找并构建问题解决方式的策略
会先从一个可能的动作开始解决问题,如果不行就回溯并选择另一个动作,直到将问题解决。
适合回溯算法的问题:
有很多路
这里路里,有死路和出路
通常需要递归来模拟所有的路。
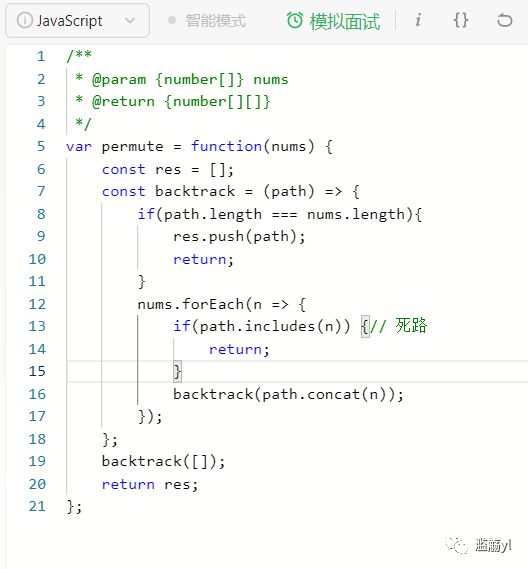
例如经典的全排列问题。

用递归模拟出所有的情况
遇到包含重复元素的情况,就回溯
收集所有到达递归终点的情况,并返回