我的Python心路历程 第五期(5.1 csv读写基础)
我的Python心路历程 第五期(5.1 csv读写基础)
有空学习了一下csv文件操作,积累了一点实践。开门见山,上代码:
#!/usr/bin/env python2
# coding: utf-8
import csv
import os
import json
#创建csv文件
def create_csv():
csvpath = 'test.csv'
with open(csvpath, 'wb') as csvf:
csv_write = csv.writer(csvf)
csv_head = ['fname','id','attribute']
csv_write.writerow(csv_head)
#在csv中写入数据
def write_csv(data_row):
csvpath = 'test.csv'
with open(csvpath,'a+') as csvf:
csv_write = csv.writer(csvf)
csv_write.writerow(data_row)
#从csv中读取数据
def read_csv():
csvpath = 'test.csv'
with open(csvpath,'rb') as csvf:
csv_read = csv.reader(csvf)
for line in csv_read:
print line
#从json文件中读取attribute,并写入csv文件中
curpath = os.path.dirname(__file__)
fpath = os.path.join(curpath, 'jsonfiles')#json文件放在jsonfiles文件夹中
for files in os.listdir(fpath):
#print("files: " + files)
jsfile = os.path.join(fpath, files)
with open(jsfile) as f:
data = json.load(f)
for t in data['step_1']['result']:
#print(t['id'] + ': ' + t['attribute'])
data_row = [files, t['id'], t['attribute']]
write_csv(data_row)
read_csv()
上面代码运行有结果,但csv中有乱码,仔细一看是中文字符的原因,而且有编译错误。
![]()
可以通过如下方式设置编码方式来解决编译错误。
#解决python因中文处理而抛出异常"UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-9: ordinal not in range(128)"的处理
import sys
reload(sys)
sys.setdefaultencoding('utf8')
执行结果显示编译通过。

但是csv文件中中文显示依旧是乱码。
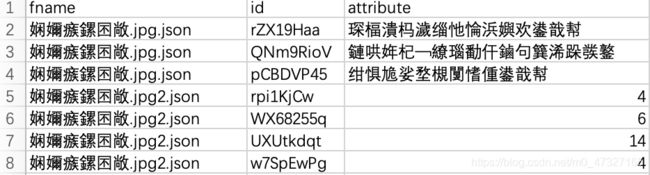
通过资料了解到是编码格式的事,尝试下面的代码修正
import codecs
#在csv中写入数据
def write_csv(data_row):
csvpath = 'test.csv'
with open(csvpath, 'a') as csvf:
csvf.write(codecs.BOM_UTF8)#csv文件中中文乱码问题,这句话可以指定编码格式来解决
csv_write = csv.writer(csvf)
csv_write.writerow(data_row)
如果不import codecs,那么会出现编译错误
NameError: global name 'codecs' is not defined
资料说如果是python3的话可以通过
with open(filename, 'a', newline='', encoding='utf-8-sig') as f: # 中文需要设置成utf-8格式
执行结果依然显示csv里的中文是乱码,要哭了,肿么办!
实在没辙了,就测试一下txt文本文件,代码如下:
#测试txt文件操作
def func_txt(data):
path = 'test.txt'
with open(path, 'w') as f:
for d in data:
f.write(d)
f.close()
with open(path, 'r') as f:
print(f.read())
f.close()
执行结果ok如下:
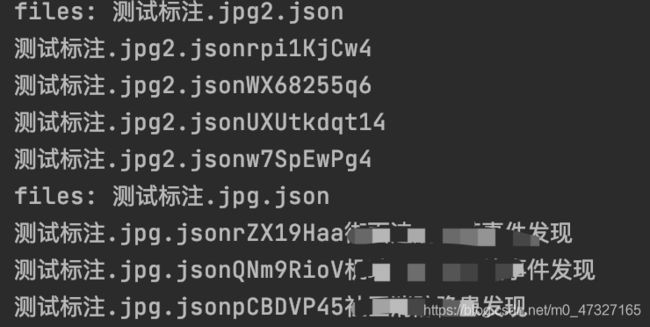
那到底是什么原因导致csv文件读取是乱码呢?有文章提到通过excel打开csv文件时可以通过设置编码方式为简体中文,试了一下依然不行。
突然想到,写操作时设置了编码格式,但创建csv文件时并没有设置,故此更高创建代码如下:
#创建csv文件
def create_csv():
csvpath = 'test.csv'
with open(csvpath, 'w') as csvf:
**csvf.write(codecs.BOM_UTF8) # csv文件中中文乱码问题,这句话可以指定编码格式来解决**
csv_write = csv.writer(csvf)
csv_head = ['fname', 'id', 'attribute']
csv_write.writerow(csv_head)
重新编译后问题解决,utf-8就可以读csv文件为中文了。
到此为止,问题并没有终结,发现控制台打印出来的依旧是乱码,因为txt文件读取正常,所以问题点应该是在rea操作环节。找了位小哥请教,通过各种方式尝试更改编码方式,最终搞定代码如下:
#从csv中读取数据
def read_csv():
csvpath = 'test.csv'
with open(csvpath, 'r') as csvf:
csv_read = csv.reader(csvf)
for line in csv_read:
str = ''
for l in line:
str += unicode(l, "utf-8");
str += ', '
print str
执行结果如下:
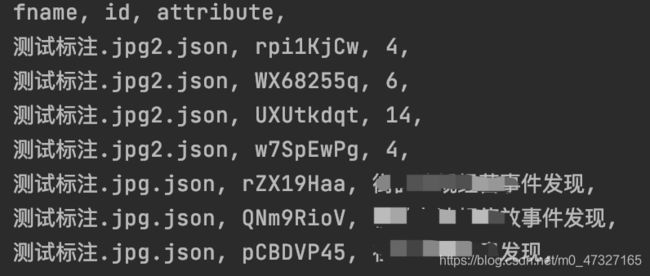
至此,终于可以暂时收工了。