XGBoost4j多线程调用代码修改(Mac 环境)
XGBoost4jJava代码的底层是C++,计算效率很快,但是C++代码接口并不是线程安全的这是得其应用受限,在XGboost4j jar中直接在模型预估函数接口加了锁,所以这块工程效率低,很难满足快速计算的工程化需求。
private synchronized float[][] predict(DMatrix data,
boolean outputMargin,
int treeLimit,
boolean predLeaf,
boolean predContribs) throws XGBoostError {
int optionMask = 0;
if (outputMargin) {
optionMask = 1;
}
if (predLeaf) {
optionMask = 2;
}
if (predContribs) {
optionMask = 4;
}
float[][] rawPredicts = new float[1][];
XGBoostJNI.checkCall(XGBoostJNI.XGBoosterPredict(handle, data.getHandle(), optionMask,
treeLimit, rawPredicts));
int row = (int) data.rowNum();
int col = rawPredicts[0].length / row;
float[][] predicts = new float[row][col];
int r, c;
for (int i = 0; i < rawPredicts[0].length; i++) {
r = i / col;
c = i % col;
predicts[r][c] = rawPredicts[0][i];
}
return predicts;
}
若去掉锁,提高其效率,需要对C++代码重新编译;
运行环境——Mac,jdk1.8,cmake, GCC
(一)C++代码修改编译:
1. xgboost C++ 代码介绍
Booster ,对外接口都在c_api;DMatrix相关在data.h
预估函数都在predictor;其他的都可以通过文件名字看出来;
c_api.cc——主要是模型初始化,接口实现;
c_api_error.cc ——主要是错误提示
data.cc DMtrix,Metainfo,函数接口实现
DMatrix两个子类 simple_dmatrix和sparse_page
gbm,gbtree,以及gblinear都在gbm
learner.cc 模型刷新,模型预估,保存等函数实现
predictor对应有cpu和gpu,
2. 预估模块
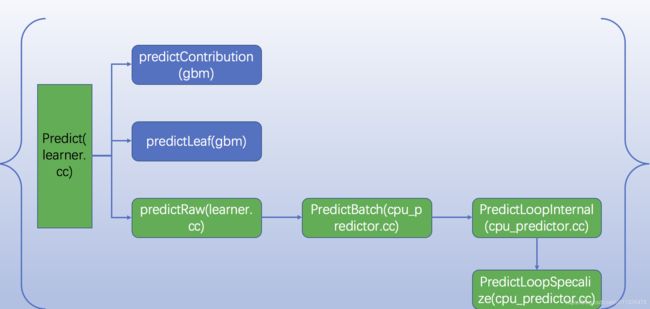
预估模块主要修改的就是上图绿色表示的类;
针对多线程不安全的地方主要是多线程写操作;在predictor存在变量为thread_temp来作为线程空间缓存;几个函数中都对其进行了内存分配;如果针对于预估模块则是在PredictLoopSpecalize函数中InitThreadTemp函数
inline void InitThreadTemp(int nthread, int num_feature) {
int prev_thread_temp_size = thread_temp.size();
if (prev_thread_temp_size < nthread) {
thread_temp.resize(nthread, RegTree::FVec());
for (int i = prev_thread_temp_size; i < nthread; ++i) {
thread_temp[i].Init(num_feature);
}
}
}这里我们的做法是将thread_temp替换为局部变量local_thread_temp
添加函数
inline void InitThreadTemp(int nthread, int num_feature,std::vector& local_thread_temp) {
int prev_thread_temp_size = thread_temp.size();
if (prev_thread_temp_size < nthread) {
local_thread_temp.resize(nthread, RegTree::FVec());
for (int i = prev_thread_temp_size; i < nthread; ++i) {
local_thread_temp[i].Init(num_feature);
}
} 修改后的PredictLoopSpecalize函数
inline void PredLoopSpecalize(DMatrix* p_fmat,
std::vector* out_preds,
const gbm::GBTreeModel& model, int num_group,
unsigned tree_begin, unsigned tree_end) {
const MetaInfo& info = p_fmat->Info();
const int nthread = omp_get_max_threads();
//InitThreadTemp(nthread, model.param.num_feature);
std::vector local_thread_temp;
InitThreadTemp(nthread, model.param.num_feature,local_thread_temp);
std::vector& preds = *out_preds;
CHECK_EQ(model.param.size_leaf_vector, 0)
<< "size_leaf_vector is enforced to 0 so far";
CHECK_EQ(preds.size(), p_fmat->Info().num_row_ * num_group);
// start collecting the prediction
for (const auto &batch : p_fmat->GetRowBatches()) {
// parallel over local batch
constexpr int kUnroll = 8;
const auto nsize = static_cast(batch.Size());
const bst_omp_uint rest = nsize % kUnroll;
#pragma omp parallel for schedule(static)
for (bst_omp_uint i = 0; i < nsize - rest; i += kUnroll) {
const int tid = omp_get_thread_num();
RegTree::FVec& feats = local_thread_temp[tid];
int64_t ridx[kUnroll];
SparsePage::Inst inst[kUnroll];
for (int k = 0; k < kUnroll; ++k) {
ridx[k] = static_cast(batch.base_rowid + i + k);
}
for (int k = 0; k < kUnroll; ++k) {
inst[k] = batch[i + k];
}
for (int k = 0; k < kUnroll; ++k) {
for (int gid = 0; gid < num_group; ++gid) {
const size_t offset = ridx[k] * num_group + gid;
preds[offset] += this->PredValue(
inst[k], model.trees, model.tree_info, gid,
info.GetRoot(ridx[k]), &feats, tree_begin, tree_end);
}
}
}
for (bst_omp_uint i = nsize - rest; i < nsize; ++i) {
RegTree::FVec& feats = local_thread_temp[0];
const auto ridx = static_cast(batch.base_rowid + i);
auto inst = batch[i];
for (int gid = 0; gid < num_group; ++gid) {
const size_t offset = ridx * num_group + gid;
preds[offset] +=
this->PredValue(inst, model.trees, model.tree_info, gid,
info.GetRoot(ridx), &feats, tree_begin, tree_end);
}
}
}
std::vector(local_thread_temp).swap(local_thread_temp);
if (local_thread_temp.size() > 0) {
for(int i=local_thread_temp.size();i>0;i--){
local_thread_temp.pop_back();
}
}
} 3. 线程初始化问题
c_api.cc
多线程启动初始化会有问题,主要是加锁处理
inline void LazyInit() {
if(!configured_ || !initialized_){
pthread_mutex_lock(&lock_);
if (!configured_) {
LoadSavedParamFromAttr();
learner_->Configure(cfg_);
configured_ = true;
}
if (!initialized_) {
learner_->InitModel();
initialized_ = true;
}
pthread_mutex_unlock(&lock_);
}
}不要忘记初始化pthread_mutex_t lock_= PTHREAD_MUTEX_INITIALIZER;
4. Java堆无法释放的内存问题
1)JNI接口内部数据调用都是直接去Java参数的地址,如DMatrix;DMatrix占用内存Java不能自己回收,只能手动自己释放(调用dispose());
2)返回的预测结果是传地址,Java能够自动回收;
(二)工程代码重新编译
1. 用eclipse编译的,首先Pom中parent报错项直接去除监测就好;
2. C++源码编译需要有cmake 和GCC
cd xgboost; cp make/minimum.mk ./config.mk; make -j4
编译so文件是mvn jvm;
3. java工程编译
参考官方步骤:https://xgboost.readthedocs.io/en/latest/jvm/index.html
1) create_jni.py不能够运行问题,pom中直接注释掉,然后手动启动即可(cd jvm_packages 终端直接运行create_jni.py)
2) mvn package;mvn install;或者mvn -DskipTests=true package等等;
3)运行环境如果是Linux,需要提前将so文件拷贝到相应的resources的lib文件夹中
4)运行中的各种坑之后复现再更新上来