python案例分析之电商销售数据分析
数据:https://pan.baidu.com/s/1BId0_x14AKhUxRo6xCL7iA
提取码:t0ch
import pandas as pd
#读取文件
data= pd.read_csv('./dataset.csv')
########################### 查看数据概览 ###########################
data.head()
# data.info()
# data.shape
# #非空统计
# data.count()
# data.isnull().sum()
# # 拓展,获取含有空值的行
# data[data.isnull().T.any()]
########################### 查看数据概览 ###########################
####################################### 清洗数据 #######################################
# 将其转化成时间(ShipDate,OrderDate均为object,需要先转化成时间)
data['ShipDate'] = pd.to_datetime(data['ShipDate'])
data['OrderDate'] = pd.to_datetime(data['OrderDate'])
#data.info()
#找出发货时间早于下单日期的记录
data[data['ShipDate']<data['OrderDate']]
#删去发货时间早于下单日期的记录,且在原数据上进行修改
data.drop(index=data[data['ShipDate']<data['OrderDate']].index, inplace=True)
#data
#查看是否有销售额小于0的记录
data[data.Sales<0]
#RowID不重复的个数 (经过上面的数据处理后 data.shape#(51097, 24),不重复的为51094)
data.RowID.unique().size
#取出重复的记录
data[data.RowID.duplicated()]
#删去RowID重复的记录,且在原数据上进行修改
data.drop(index=data[data.RowID.duplicated()].index, inplace=True)
#data.info()
#1.查看ShipMode空值
# data[data.ShipMode.isnull()]
# data.ShipMode
#2.对空值进行修补
#从选择的某个轴 返回这个众数, 如果缺失就是用NaN填充, 然后 轴上可能会有多个众数,所以这个函数返回的类型是一个dateframe
# data.ShipMode.mode()[0]
#进行空值填充
data['ShipMode'].fillna(value=data.ShipMode.mode()[0], inplace=True)
data.info()
####################################### 清洗数据 #######################################
#分别取出订单日期的年、月、季
data['Order-year'] = data ['OrderDate'].dt.year
data ['Order-month'] = data ['OrderDate'].dt.month
data ['quarter'] = data ['OrderDate'].dt.to_period('Q')
# result = data [['OrderDate','Order-year','Order-month', 'quarter']].head()
# print(result)
sales_year = data.groupby(by='Order-year')['Sales'].sum()
print(sales_year)
# (本年的销售额-上年的销售额)/ 上年的销售额 -> 本年的销售额/上年的销售额 -1
sales_rate_12 = sales_year[2012] / sales_year[2011] - 1
sales_rate_13 = sales_year[2013] / sales_year[2012] - 1
sales_rate_14 = sales_year[2014] / sales_year[2013] - 1
print(sales_rate_12,sales_rate_13,sales_rate_14)
sales_rate_12_label = "%.2f%%" % (sales_rate_12 * 100)
sales_rate_13_label = "%.2f%%" % (sales_rate_13 * 100)
sales_rate_14_label = "%.2f%%" % (sales_rate_14 * 100)
print(sales_rate_12_label,sales_rate_13_label,sales_rate_14_label)
# sales_rate = pd.DataFrame(
# {'sales_all':sales_year,
# 'sales_rate':[0,sales_rate_12,sales_rate_13,sales_rate_14],
# 'sales_rate_label':['0.00%',sales_rate_12_label,sales_rate_13_label,sales_rate_14_label]
# })
# print(sales_rate)
import matplotlib.pyplot as plt
import matplotlib as mpl
# 设置字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 设置风格
plt.style.use('ggplot')
sales_rate = pd.DataFrame(
{
'sales_all':sales_year,
'sales_rate':[0,sales_rate_12,sales_rate_13,sales_rate_14],
'sales_rate_label':['0.00%',sales_rate_12_label,sales_rate_13_label,sales_rate_14_label]
})
y1 = sales_rate['sales_all']
y2 = sales_rate['sales_rate']
x = [str(value) for value in sales_rate.index.tolist()]
# 新建figure对象
fig=plt.figure()
# 新建子图1
ax1=fig.add_subplot(1,1,1)
# ax2与ax1共享X轴
ax2 = ax1.twinx()
ax1.bar(x,y1,color = 'blue')
ax2.plot(x,y2,marker='*',color = 'r')
ax1.set_xlabel('年份')
ax1.set_ylabel('销售额')
ax2.set_ylabel('增长率')
ax1.set_title('销售额与增长率')
plt.show()

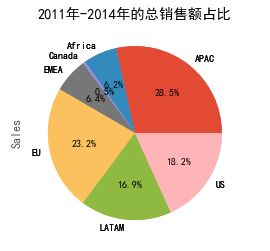
#2011-2014年之间各个区域的总销售额占比
sales_area = data.groupby(by='Market')['Sales'].sum()
sales_area.plot(kind='pie')
sales_area.plot(kind='pie',autopct="%1.1f%%",title='2011年-2014年的总销售额占比')
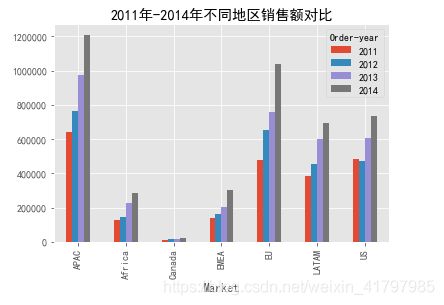
# 各地区每一年的销售额(不重新设置索引)
sales_area = data.groupby(by=['Market','Order-year'],as_index=False)['Sales'].sum()
sales_area
# 将分组后的多层索引设置成列数据(如果没有as_index=False,可以使用下面的方法再还原索引)
# reset_index可以还原索引,重新变为默认的整型索引
# sales_area = sales_area.reset_index(level=[0,1])
# sales_area
# # 使用数据透视表重新整理数据
sales_area = pd.pivot_table(sales_area,
index='Market',
columns='Order-year',
values='Sales')
sales_area
# # 绘制图形
sales_area.plot(kind = 'bar',title = '2011年-2014年不同地区销售额对比')
############################# RFM #######################
#取出订单日期为2014年的数据
data_14 = data [data ['Order-year']==2014]
#取出三列
data_14 = data_14[['CustomerID','OrderDate','Sales']]
#重新复制给customdf
customdf = data_14.copy()
#customdf
customdf.set_index('CustomerID',drop=True,inplace=True)
#增加一个辅助列,每一条订单都计数为1
customdf['orders'] = 1
#customdf
#透视图
rfmdf = customdf.pivot_table(index=['CustomerID'],
values=['OrderDate','orders','Sales'],
aggfunc={
'OrderDate':'max',
'orders':'sum',
'Sales':'sum'})
rfmdf
rfmdf['R'] = (rfmdf.OrderDate.max()-rfmdf.OrderDate).dt.days
#rfmdf
rfmdf.rename(columns={
'Sales':'M','orders':'F'},inplace=True)
#rfmdf
def show(df):
return df-df.mean()
result1= rfmdf[['R','F','M']].apply(lambda x: x-x.mean())
#result1
def rfm_func(x):
# -25.0 7.0 1969.12304
# 0 1 1
level = x.apply(lambda x: "1" if x >= 0 else '0')
# 0 1 1 -> 011
label = level.R + level.F + level.M
d = {
'011':'重要价值客户',
'111':'重要唤回客户',
'001':'重要深耕客户',
'101':'重要挽留客户',
'010':'潜力客户',
'110':'一般维持客户',
'000':'新客户',
'100':'流失客户'
}
result = d[label]
return result
result1= rfmdf[['R','F','M']].apply(lambda x:x-x.mean())
result2 = result1.apply(rfm_func,axis=1)
result2
rfmdf['lables'] = result2
rfmdf
############################# RFM #######################