trt-yolov3:Jetson Nano上的yolov3-tiny识别(已完结)
trt-yolov3:Jetson Nano上的yolov3-tiny识别
-
- 下载github项目
- 环境配置
-
-
-
- 环境要求
- 安装系统固件
- 环境安装
-
- 安装pip
- 交换空间
- 安装软件包、模块包
- 安装protobuf
- Docker Support
- Run the container
-
-
- 识别前的处理
- 开始识别
- trt-yolov3-tiny调用摄像头实现识别
-
-
- 先介绍怎么使用摄像头,这一步可看可不看
- 修改detector.py
- 运行结果
-
由于我使用的是搭载了jetson nano的亚博智能小车jetbot,所以下面都以小车为例。
下载github项目
首先将trt-yolov3的github项目下载下来,地址为:https://github.com/yqlbu/TRT-yolov3
环境配置
环境要求
项目环境要求:

在我多次的系统重装测试后,发现只有jetpack4.3版本是可用的。
首先尽管说明中cuda>=10就可以,但是在使用cuda10.2时报错,只有cuda10.0才能运行。符合cuda10.0的有jetpack4.3和jetpack4.2,而jetpack4.2往前的版本中tensorrt版本是低于6.0.1版本的,所以jetpack4.3才是最合适的版本。
所以现在开始安装系统固件。
安装系统固件
小车自带的系统固件中,环境包版本都比预期的版本要低,所以需要重新下载Jetpack固件。
Nvidia官方Jetpack固件下载地址:https://developer.nvidia.com/embedded/jetpack-archive

我们选择Jetpack 4.3进行下载就可以了。
安装时先把内存卡原有的系统的分区删除,格式化,然后使用etcher进行固件烧写,烧录过程与小车烧写固件一致,具体流程我已写在:https://blog.csdn.net/qq_36780295/article/details/108449150
烧完固件以后,连接显示器进入系统需要对系统进行设置,除了一开始选择中文,其他都默认。
进入系统以后,设置中文系统和中文输入法,很简单,写在了:https://blog.csdn.net/qq_36780295/article/details/108452586
( 语言支持[更新]——>重启——>文本输入[添加pinyin输入法] )
准备工作做完以后,开始配置环境。
环境安装
将常用的环境变量配置上:(以下是我配置完以后添加的环境变量)
vim ~/.bashrc

protoc等装完protobuf再配置($PATH: 和 $LD_LIBRARY_PATH:相当于连接的一个冒号,统一写在开头或统一写结尾,如果两个路径之间出现两个冒号会报错 )
安装pip
终端执行以下命令
安装pip:sudo apt-get install python3-pip python3-dev
升级pip:python3 -m pip install --upgrade pip
查看pip版本:pip3 -V
交换空间
增加4G交换空间:
sudo fallocate -l 4G /var/swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /var/swapfile
sudo swapon /var/swapfile
sudo bash -c 'echo "/var/swapfile swap swap defaults 0 0" >> /etc/fstab'
安装软件包、模块包
在系统中已装好的有:
python 3.6.9
CUDA 10.0
opencv 4.11
Tensorrt 6.0.1
cudnn 7.6.3
剩下的需要安装:
onnx 1.4.1
numpy 1.16.0
pycuda 2019.1.2
protobuf 3.8.0
安装这些前,先执行:sudo pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple protobuf==3.8.0(如果已有请先卸载低版本)(必须先安装protobuf,其他包安装时需要用到)
接着依次执行以下指令进行安装:
sudo pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy==1.16.0
sudo pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx==1.4.1
sudo pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pycuda==2019.1.2
安装pycuda和onnx时如果报错,可以参考我提供的两个方法(未安装protobuf也会报错):https://blog.csdn.net/qq_36780295/article/details/108489483
安装完以后,一定要进入python3环境以后挨个导入看看是否报错,如果import报错,可能是protobuf版本与pycuda和onnx的版本不匹配,所以一定要先安装protobuf。
安装protobuf
刚刚在python模块中安装了protobuf,但是我不放心,因为protobuf在很多地方会用到,我不满足于只装一个python版本,所以还要再安装一下。安装方法我写在了:https://blog.csdn.net/qq_36780295/article/details/108486308
(装这个也是一个大坑,网上很多给出的方法都安装不起来)
按照github项目下的说明进行:
Docker Support
在终端执行:
$ sudo apt install -y nvidia-docker2
$ sudo nano /etc/docker/daemon.json
在daemon.json中,把原来的内容备份以后删除,并粘贴以下内容:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
接着,终端执行:
$ sudo systemctl daemon-reload
$ sudo systemctl restart docker
Run the container
终端执行:
$ export DISPLAY=:0
$ sudo xhost +si:localuser:root
$ sudo docker run --runtime nvidia --network host --rm -it -e DISPLAY=$DISPLAY -v /tmp/.X11-unix/:/tmp/.X11-unix hikariai/l4t-trt-yolov3:
(我在执行第二步的时候就报错了,不知道是不是因为没有连接网络相机,这里报错暂且先不管)
到此,环境配置结束。
识别前的处理
把github的压缩文件拷贝到jetson nano中,解压缩目录,进入到TRT-yolov3-master/yolov3_onnx目录,双击打开download.sh,因为在jetson nano上只带的动yolov3-tiny,所以将download.sh里面的yolov3部分删除:(下图这段全部删掉)
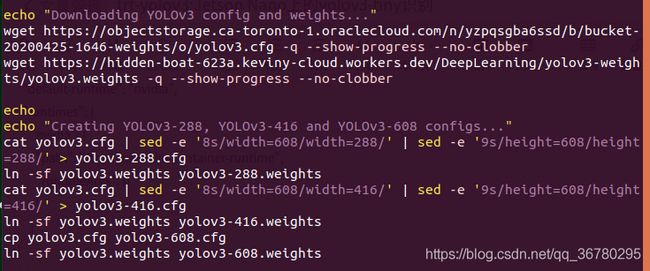
接着,由于下载速度太慢,所以,把如下这段下载yolov3-tiny.cfg和yolov3-tiny.weights的代码删掉,把下载地址复制出来,粘贴到Chromium浏览器下载,速度快多了。

(上面这些代码全都删掉,把下载链接:
1、https://objectstorage.ca-toronto-1.oraclecloud.com/n/yzpqsgba6ssd/b/bucket-20200425-1646-weights/o/yolov3-tiny.cfg
2、https://hidden-boat-623a.keviny-cloud.workers.dev/DeepLearning/yolov3-weights/yolov3-tiny.weights
复制到浏览器下载
)
下载,把下载好的yolov3-tiny的配置文件和权重文件放到 TRT-yolov3-master/yolov3_onnx文件夹中。
再次确认下,download.sh中是否只剩下这段代码了:

然后在 TRT-yolov3-master/yolov3_onnx 文件夹中右击从终端打开,执行sudo ./download.sh,接着文件夹中便会生成好多类型的yolov3-tiny文件,下面我会选择416版本进行使用。(这里我把yolov3的也给生成了)
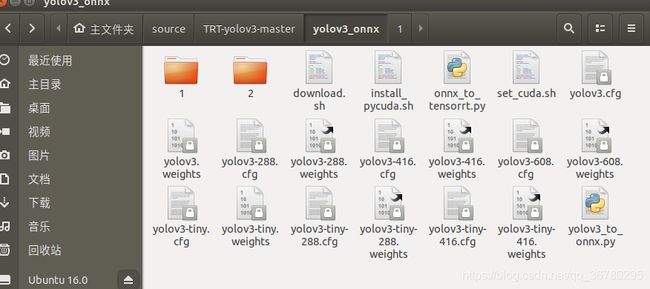
接着右击,选择在终端打开,执行:
$ python3 yolov3_to_onnx.py --model yolov3-tiny-416
接着就会生成一个onnx模型。
再在终端执行:
python3 onnx_to_tensorrt.py --model yolov3-tiny-416

会在文件夹中生成一个trt模型:
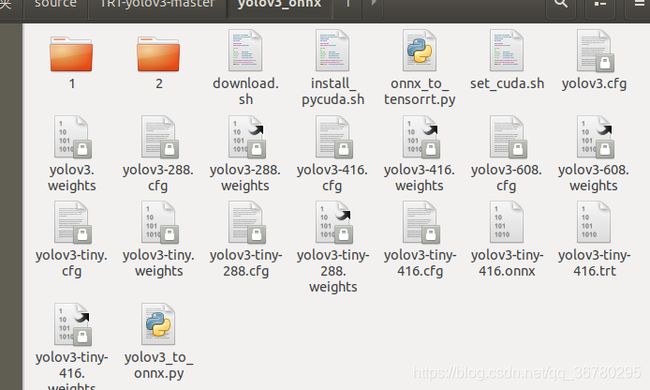
另外,github下的说明中说data中的videos文件夹中有四个mp4文件,但是我又去github上看了一下,确实没有,所以自己找个mp4测试文件放到 data/videos 目录下吧。
开始识别
进入到TRT-yolov3-master文件夹下,右击从终端打开,执行:
python3 detector.py --file --filename ./data/videos/1.mp4 --model yolov3-tiny-416 --runtime
开始视频流的识别:
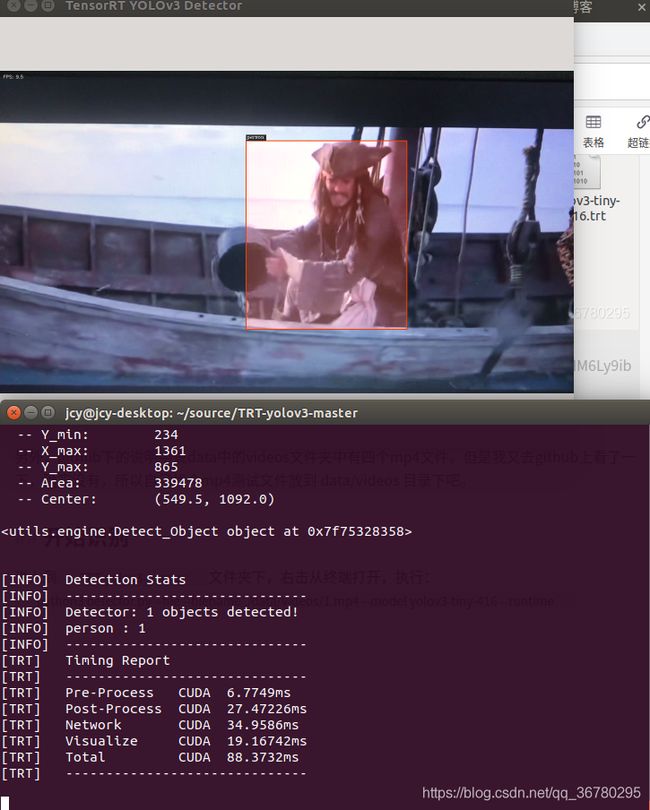
因为手机拍的,画面很模糊,所以识别的不太理想,但识别的速度快了不是一点半点。
附上图片识别和视频实施识别的指令:
摄像头:$ python3 detector.py --usb --vid 0 --runtime
图片:$ python3 detector.py --image --filename ./data/images/human.jpg
由于试过几次打开小车摄像头,但是都失败了,所以怀疑是小车的排线坏了,也没办法进行测试。
实施识别可能可以从三个方面来做:
1、opencv读取摄像头,并读取trt和onnx模型识别(网上有很多这种代码)。
2、使用小车的驱动文件来读取jetbot上的摄像头,并调用模型。
3、使用$ python3 detector.py --usb --vid 0 --runtime来读取视频+识别。
1、3两个读取画面似乎都可以通过usb连接相机实现,2可能需要安装jetbot的python包来运行驱动。
这部分我弄好了再补上来,附上我之前的长篇踩坑实录:https://blog.csdn.net/qq_36780295/article/details/108217578
另外,识别过程可能会出现死机现象,先检查是否申请交换空间。其次,拿着电风扇对着吹吧!
trt-yolov3-tiny调用摄像头实现识别
更新于2020.9.16:经历了好多好多的坑,加上中间跑去写了个Qt软件,好不容易把摄像头实时识别做出来了!
以下操作都是在上面的进度基础上往下进行的。
首先确认一下摄像头排线是否正确:


先介绍怎么使用摄像头,这一步可看可不看
由于我在安装jupyter时始终不成功,所以这里我们不使用yahboom官方给的调用相机的代码,驱动就也无需下载了。
那怎样使用摄像头呢?我们使用CSI来控制摄像头。这里需要下载CSI-Camera的github项目,下载地址为:https://github.com/JetsonHacksNano/CSI-Camera
下载完放到任意目录以后解压。然后进入到CSI-Camera-master,可以看到有三个python脚本,右击在终端打开,执行python3 simple_camera.py就可以调用相机了(有时候执行多次以后再执行会报错,重启就解决了)。同目录还有一个face_detect.py文件,功能是进行摄像头人脸识别,可以看一下。
我们打开simple_camera.py查看其使用方式,代码不长,核心代码为:
def gstreamer_pipeline(
capture_width=1280,
capture_height=720,
display_width=1280,
display_height=720,
framerate=60,
flip_method=0,
):
return (
"nvarguscamerasrc ! "
"video/x-raw(memory:NVMM), "
"width=(int)%d, height=(int)%d, "
"format=(string)NV12, framerate=(fraction)%d/1 ! "
"nvvidconv flip-method=%d ! "
"video/x-raw, width=(int)%d, height=(int)%d, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! appsink"
% (
capture_width,
capture_height,
framerate,
flip_method,
display_width,
display_height,
)
)
def show_camera():
cap = cv2.VideoCapture(gstreamer_pipeline(flip_method=0), cv2.CAP_GSTREAMER)
if cap.isOpened():
window_handle = cv2.namedWindow("CSI Camera", cv2.WINDOW_AUTOSIZE)
while cv2.getWindowProperty("CSI Camera", 0) >= 0:
ret_val, img = cap.read()
cv2.imshow("CSI Camera", img)
keyCode = cv2.waitKey(30) & 0xFF
if keyCode == 27:
break
cap.release()
cv2.destroyAllWindows()
其实就是opencv调用摄像头,只是跟平时的调用有些不同,所以我们要考虑的问题就是怎么把相机调用和trt-yolov3识别结合在一起。
修改detector.py
经过反复修改和改bug终于使用代码将相机和识别结合在了一起,不得不说一句:我太南了!
打开文件夹到TRT-yolov3-master,对detector.py进行编辑,将图片的输入接口替换成相机的读取就可以了。
由于改动的地方还挺多的,所以我就不细说了,改完的代码我放在下面,记得把原来的detector.py备份一下,然后把我给的代码贴上去,保存。
"""detector.py
This script demonstrates how to do real-time object detection with
TensorRT optimized Single-Shot Multibox Detector (SSD) engine.
"""
import sys
import argparse
import cv2
import pycuda.autoinit # This is needed for initializing CUDA driver
sys.path.append('/home/jcy/source/TRT-yolov3-master/utils') #这里改一下
import numpy as np
from yolo_classes import get_cls_dict
from yolov3 import TrtYOLOv3
#from camera import add_camera_args, Camera
from visualization import open_window, show_fps, record_time, show_runtime
from engine import BBoxVisualization
WINDOW_NAME = 'TensorRT YOLOv3 Detector'
INPUT_HW = (300, 300)
SUPPORTED_MODELS = [
'ssd_mobilenet_v2_coco'
]
def parse_args():
"""Parse input arguments."""
desc = ('Capture and display live camera video, while doing '
'real-time object detection with TensorRT optimized '
'YOLOv3 model on Jetson Family')
parser = argparse.ArgumentParser(description=desc)
parser = add_camera_args(parser)
parser.add_argument('--model', type=str, default='yolov3-416',
choices=['yolov3-288', 'yolov3-416', 'yolov3-608',
'yolov3-tiny-288', 'yolov3-tiny-416'])
parser.add_argument('--runtime', action='store_true',
help='display detailed runtime')
args = parser.parse_args()
return args
def loop_and_detect(img, runtime, trt_yolov3, conf_th, vis):
timer = cv2.getTickCount()
if img is not None:
if runtime:
boxes, confs, clss, _preprocess_time, _postprocess_time,_network_time = trt_yolov3.detect(img, conf_th)
img, _visualize_time = vis.draw_bboxes(img, boxes, confs, clss)
time_stamp = record_time(_preprocess_time, _postprocess_time, _network_time, _visualize_time)
#show_runtime(time_stamp)
else:
boxes, confs, clss, _, _, _ = trt_yolov3.detect(img, conf_th)
img, _ = vis.draw_bboxes(img, boxes, confs, clss)
fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer)
img = show_fps(img, fps)
cv2.imshow(WINDOW_NAME, img)
def gstreamer_pipeline(
capture_width=1280,
capture_height=720,
display_width=1280,
display_height=720,
framerate=60,
flip_method=0,
):
return (
"nvarguscamerasrc ! "
"video/x-raw(memory:NVMM), "
"width=(int)%d, height=(int)%d, "
"format=(string)NV12, framerate=(fraction)%d/1 ! "
"nvvidconv flip-method=%d ! "
"video/x-raw, width=(int)%d, height=(int)%d, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! appsink"
% (
capture_width,
capture_height,
framerate,
flip_method,
display_width,
display_height,
)
)
def main():
cls_dict = get_cls_dict('coco')
yolo_dim = 416 # 416 or 608
trt_yolov3 = TrtYOLOv3('yolov3-tiny-416', (yolo_dim, yolo_dim))
print('[INFO] Camera: starting')
cap = cv2.VideoCapture(gstreamer_pipeline(flip_method=0), cv2.CAP_GSTREAMER)
open_window(WINDOW_NAME, 1280, 720,'TensorRT YOLOv3 Detector')
vis = BBoxVisualization(cls_dict)
if cap.isOpened():
#window_handle = cv2.namedWindow("CSI Camera", cv2.WINDOW_AUTOSIZE)
while True:
ret_val, img = cap.read()
img=cv2.flip(img,1)
loop_and_detect(img, 20, trt_yolov3, conf_th=0.3, vis=vis)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
保存完以后,右击从终端打开,执行python detector.py就可以开始识别了(由于我把输入的接口都去掉了,所以不需要添加参数),程序中的sys.path.append后面的路径可能需要改一下。
注
如果报错:Failed to create CaptureSession
重启jetson nano就能解决。
运行结果
整体执行的帧数在13到25之间,执行的时候略有延迟,不过还是可以接受的,相比于直接调用,性能提高了很多倍。识别方面,感觉识别的不是特别准,屏幕占比比较大的物体只能偶尔识别出来,但是还算看的过去。下面放下检测结果,就不放自己了,拿自己手机里的照片实验一下,截了几张图,识别的还是可以的。
至此结束!
转载请标明出处。